


A new version has been released, with performance boost. To update please run python -m pip install bota botasaurus botasaurus-api botasaurus-requests botasaurus-driver bota botasaurus-proxy-authentication botasaurus-server --upgrade.
🐿️ Botasaurus In a Nutshell
How wonderful that of all the web scraping tools out there, you chose to learn about Botasaurus. Congratulations!
And now that you are here, you are in for an exciting, unusual and rewarding journey that will make your web scraping life a lot, lot easier.
Now, let me tell you in bullet points about Botasaurus. (Because as per the marketing gurus, YOU as a member of Developer Tribe have a VERY short attention span.)
So, what is Botasaurus?
Botasaurus is an all-in-one web scraping framework that enables you to build awesome scrapers in less time, less code, and with more fun.
A Web Scraping Magician has put all his web scraping experience and best practices into Botasaurus to save you hundreds of hours of Development Time!
Now, for the magical powers awaiting you after learning Botasaurus:
- Convert any Web Scraper to a UI-based Scraper in minutes, which will make your Customer sing praises of you.
- In terms of humaneness, what Superman is to Man, Botasaurus is to Selenium and Playwright. Easily pass every (Yes E-V-E-R-Y) bot test, no need to spend time finding ways to access a website.
-
Save up to 97%, yes 97% on browser proxy costs by using browser-based fetch requests.
-
Easily save hours of Development Time with easy parallelization, profiles, extensions, and proxy configuration. Botasaurus makes asynchronous, parallel scraping a child's play.
-
Use Caching, Sitemap, Data cleaning, and other utilities to save hours of time spent in writing and debugging code.
-
Easily scale your scraper to multiple machines with Kubernetes, and get your data faster than ever.
And those are just the highlights. I Mean!
There is so much more to Botasaurus, that you will be amazed at how much time you will save with it.
🚀 Getting Started with Botasaurus
Let's dive right in with a straightforward example to understand Botasaurus.
In this example, we will go through the steps to scrape the heading text from https://www.omkar.cloud/.
Step 1: Install Botasaurus
First things first, you need to install Botasaurus. Run the following command in your terminal:
python -m pip install botasaurus
Step 2: Set Up Your Botasaurus Project
Next, let's set up the project:
- Create a directory for your Botasaurus project and navigate into it:
mkdir my-botasaurus-project cd my-botasaurus-project code . # This will open the project in VSCode if you have it installed
Step 3: Write the Scraping Code
Now, create a Python script named main.py in your project directory and paste the following code:
from botasaurus.browser import browser, Driver @browser def scrape_heading_task(driver: Driver, data): # Visit the Omkar Cloud website driver.get("https://www.omkar.cloud/") # Retrieve the heading element's text heading = driver.get_text("h1") # Save the data as a JSON file in output/scrape_heading_task.json return { "heading": heading } # Initiate the web scraping task scrape_heading_task()
Let's understand this code:
- We define a custom scraping task,
scrape_heading_task, decorated with@browser:
@browser def scrape_heading_task(driver: Driver, data):
- Botasaurus automatically provides an Humane Driver to our function:
def scrape_heading_task(driver: Driver, data):
- Inside the function, we:
- Visit Omkar Cloud
- Extract the heading text
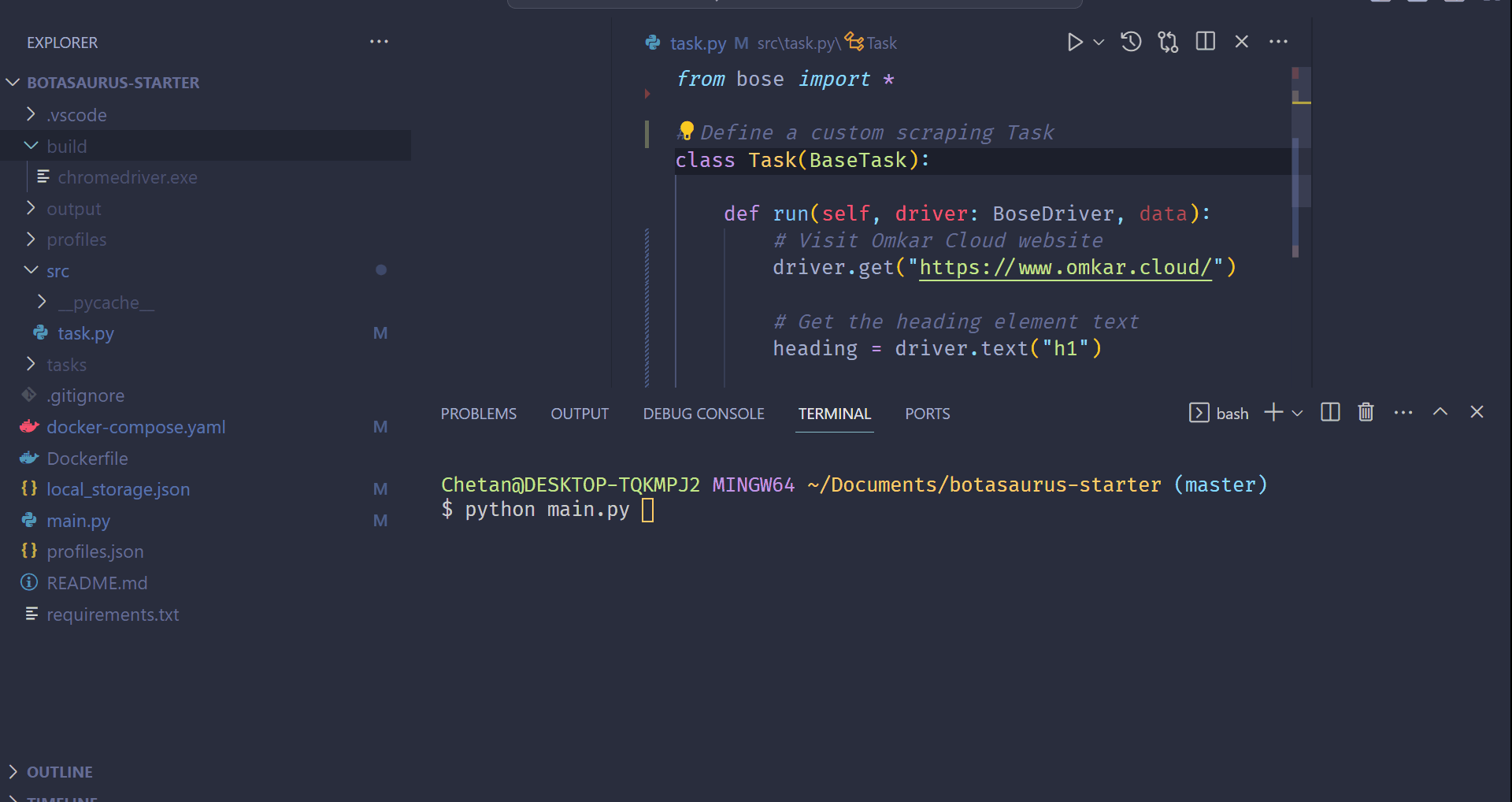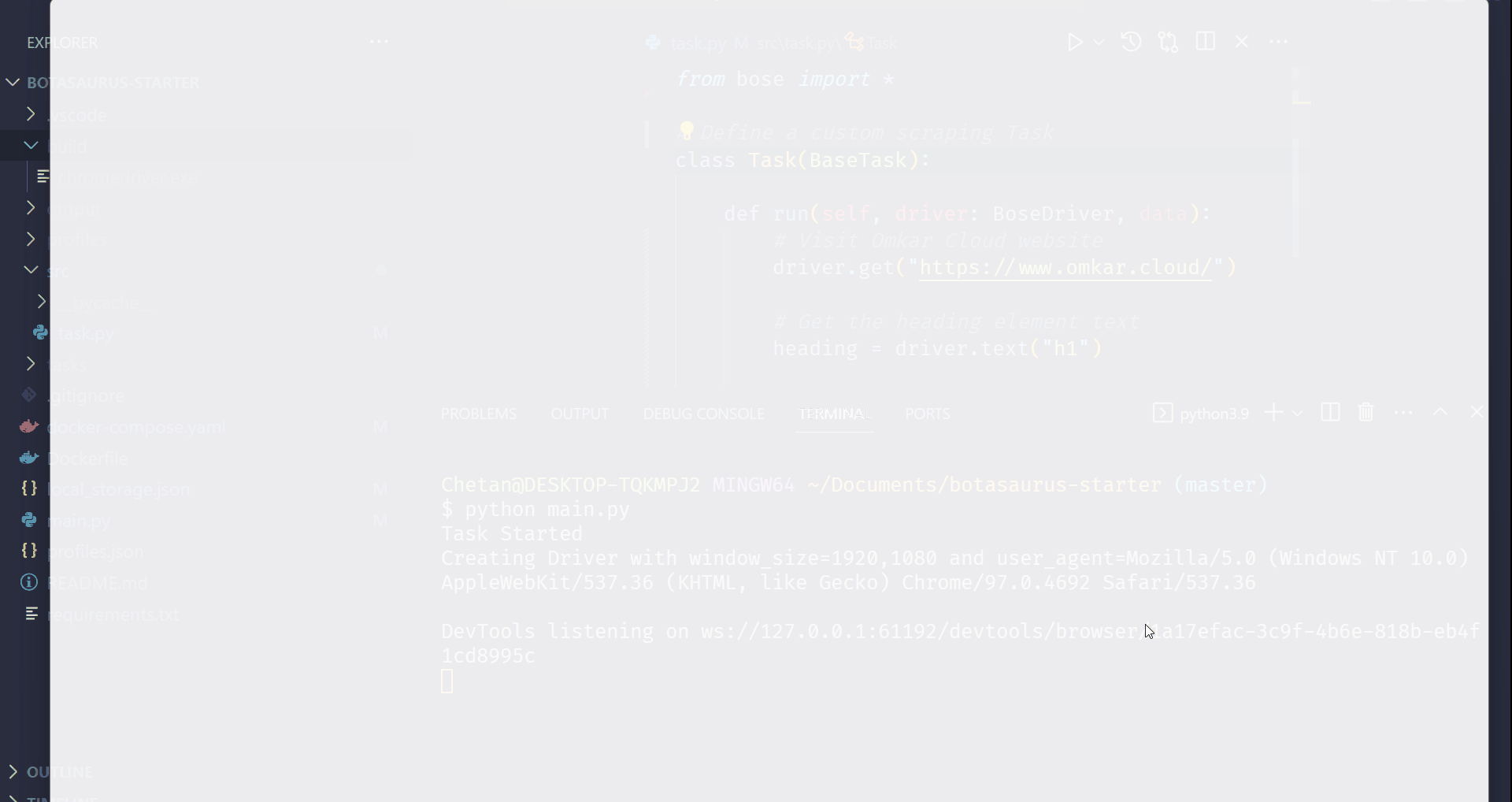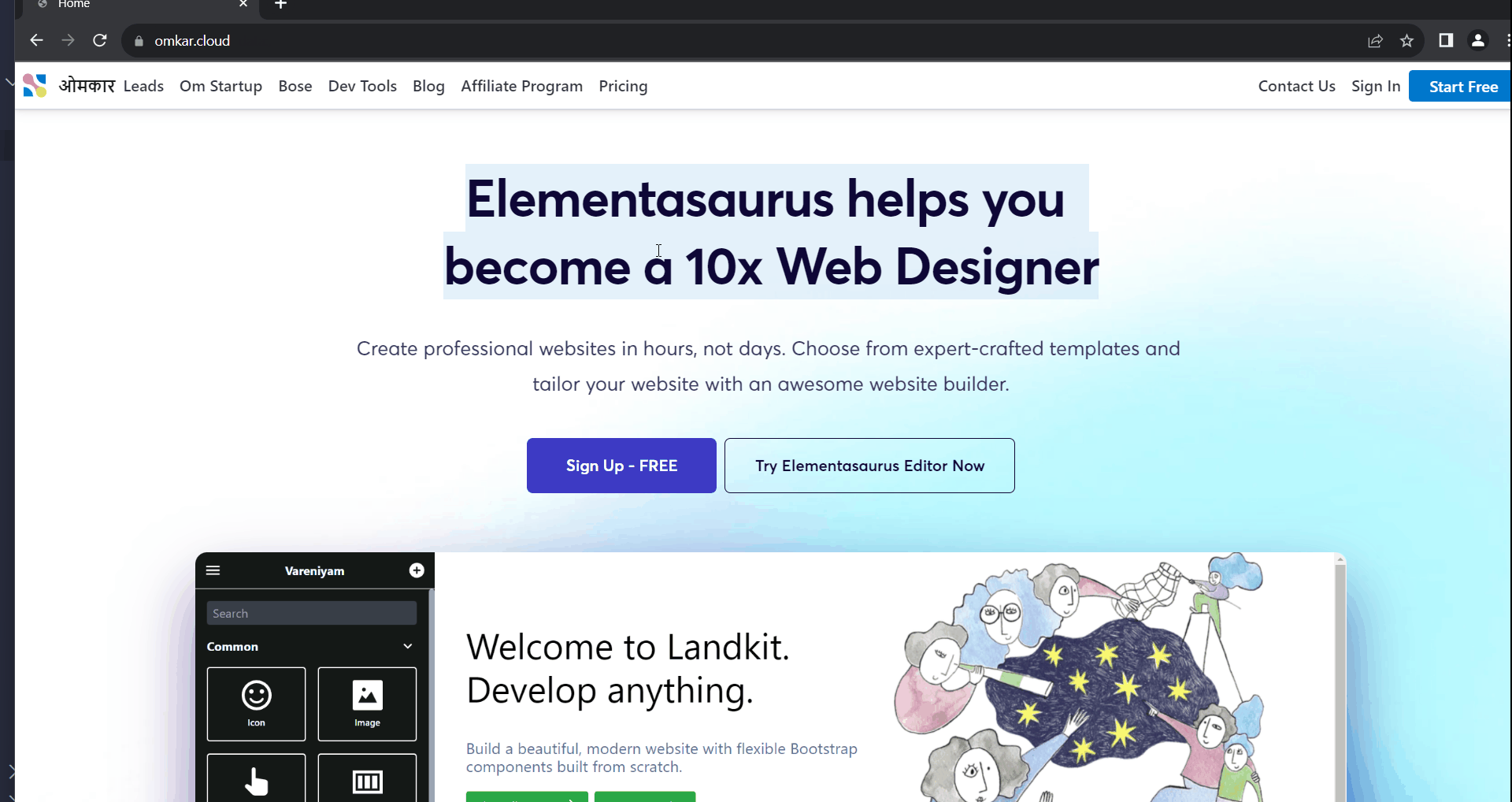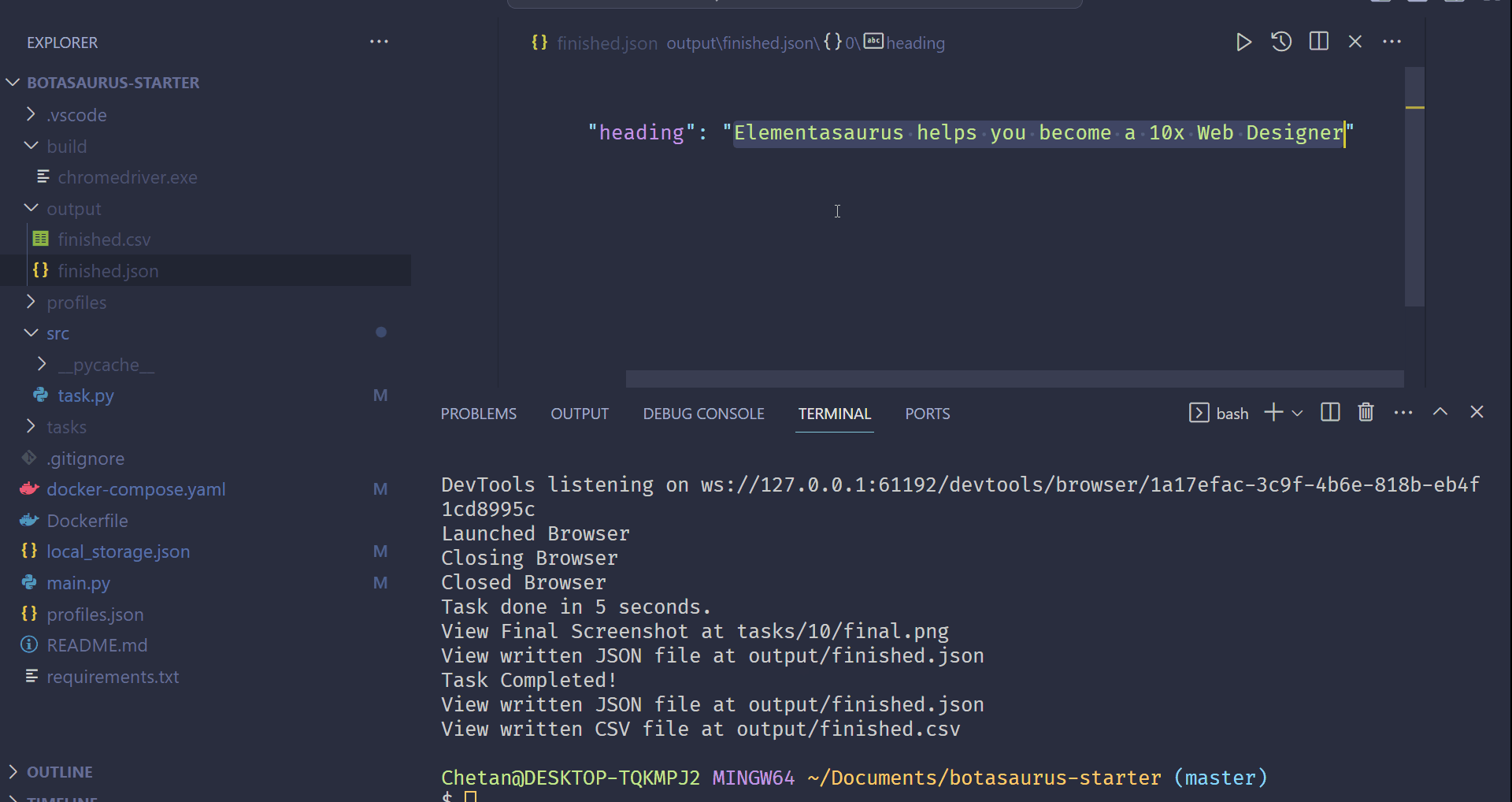
- Return the data to be automatically saved as
scrape_heading_task.jsonby Botasaurus:
driver.get("https://www.omkar.cloud/") heading = driver.get_text("h1") return {"heading": heading}
- Finally, we initiate the scraping task:
# Initiate the web scraping task scrape_heading_task()
Step 4: Run the Scraping Task
Time to run it:
python main.py
After executing the script, it will:
- Launch Google Chrome
- Visit omkar.cloud
- Extract the heading text
- Save it automatically as
output/scrape_heading_task.json.
Now, let's explore another way to scrape the heading using the request module. Replace the previous code in main.py with the following:
from botasaurus.request import request, Request from botasaurus.soupify import soupify @request def scrape_heading_task(request: Request, data): # Visit the Omkar Cloud website response = request.get("https://www.omkar.cloud/") # Create a BeautifulSoup object soup = soupify(response) # Retrieve the heading element's text heading = soup.find('h1').get_text() # Save the data as a JSON file in output/scrape_heading_task.json return { "heading": heading } # Initiate the web scraping task scrape_heading_task()
In this code:
- We scrape the HTML using
request, which is specifically designed for making browser-like humane requests. - Next, we parse the HTML into a
BeautifulSoupobject usingsoupify()and extract the heading.
Step 5: Run the Scraping Task (which makes Humane HTTP Requests)
Finally, run it again:
python main.py
This time, you will observe the exact same result as before, but instead of opening a whole Browser, we are making browser-like humane HTTP requests.
💡 Understanding Botasaurus
What is Botasaurus Driver, And Why should I use it over Selenium and Playwright?
Botasaurus Driver is a web automation driver like Selenium, and the single most important reason to use it is because it is truly humane, and you will not, and I repeat NOT, have any issues with accessing any website.
Plus, it is super fast to launch and use, and the API is designed by and for web scrapers, and you will love it.
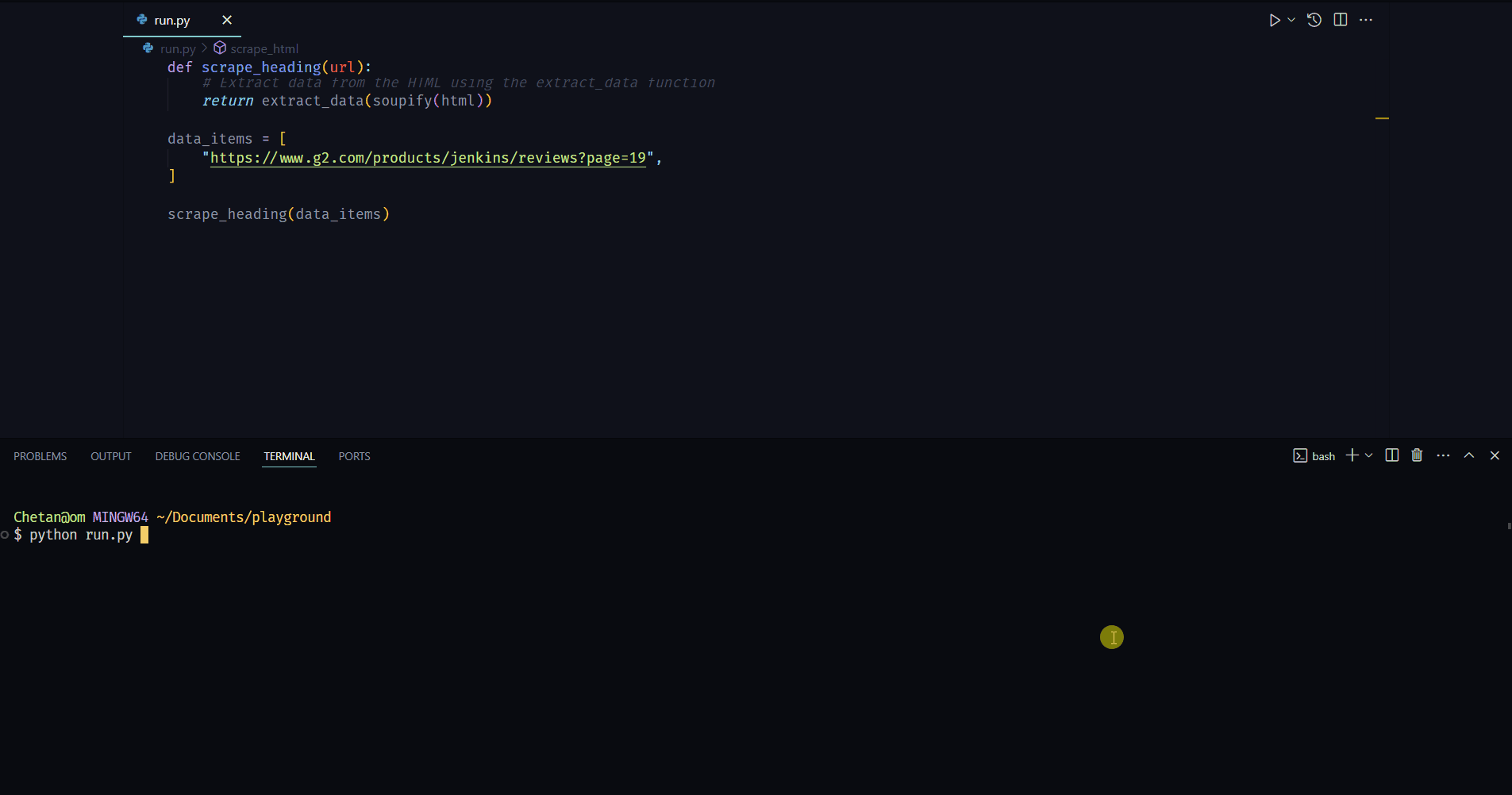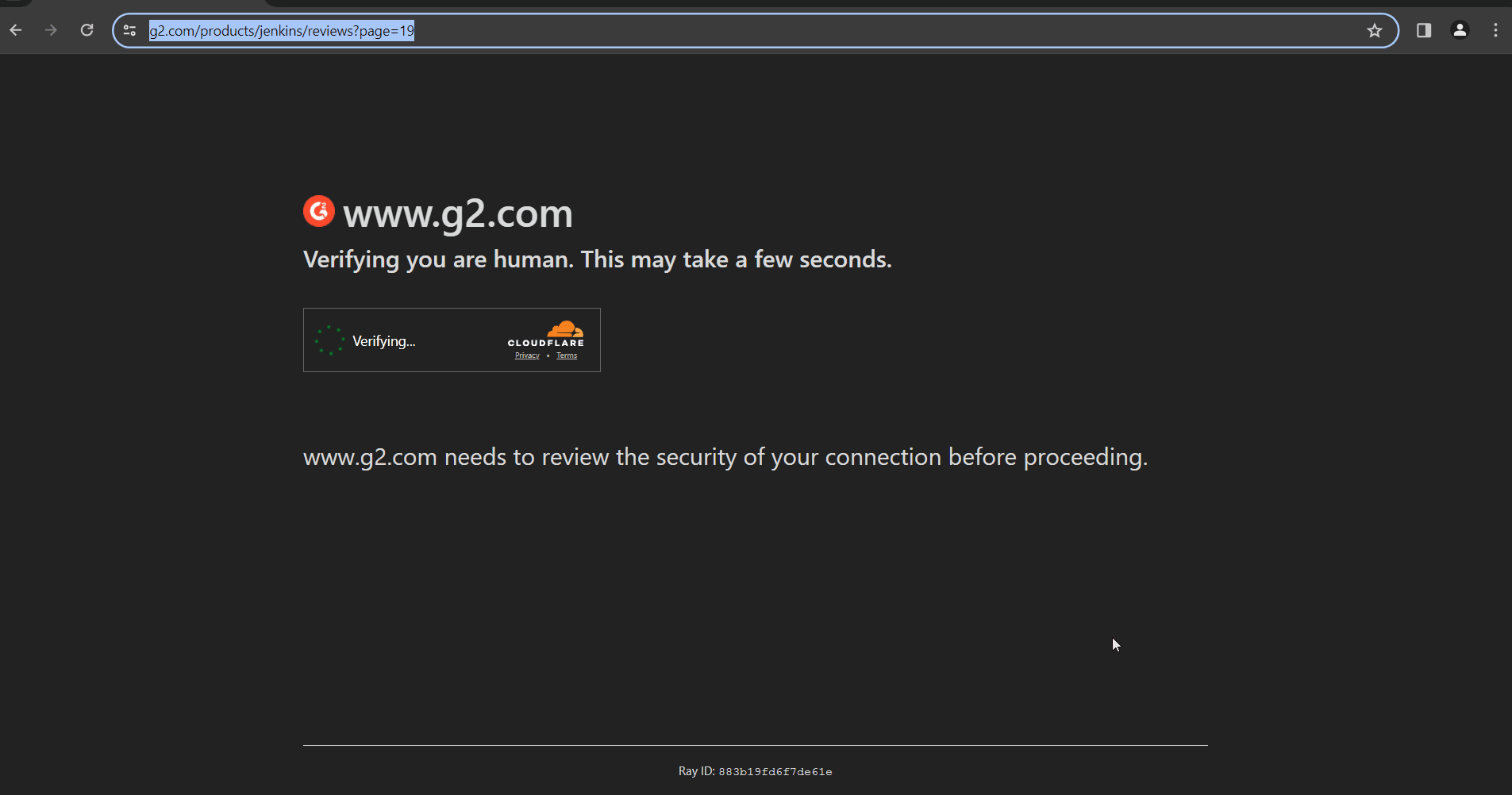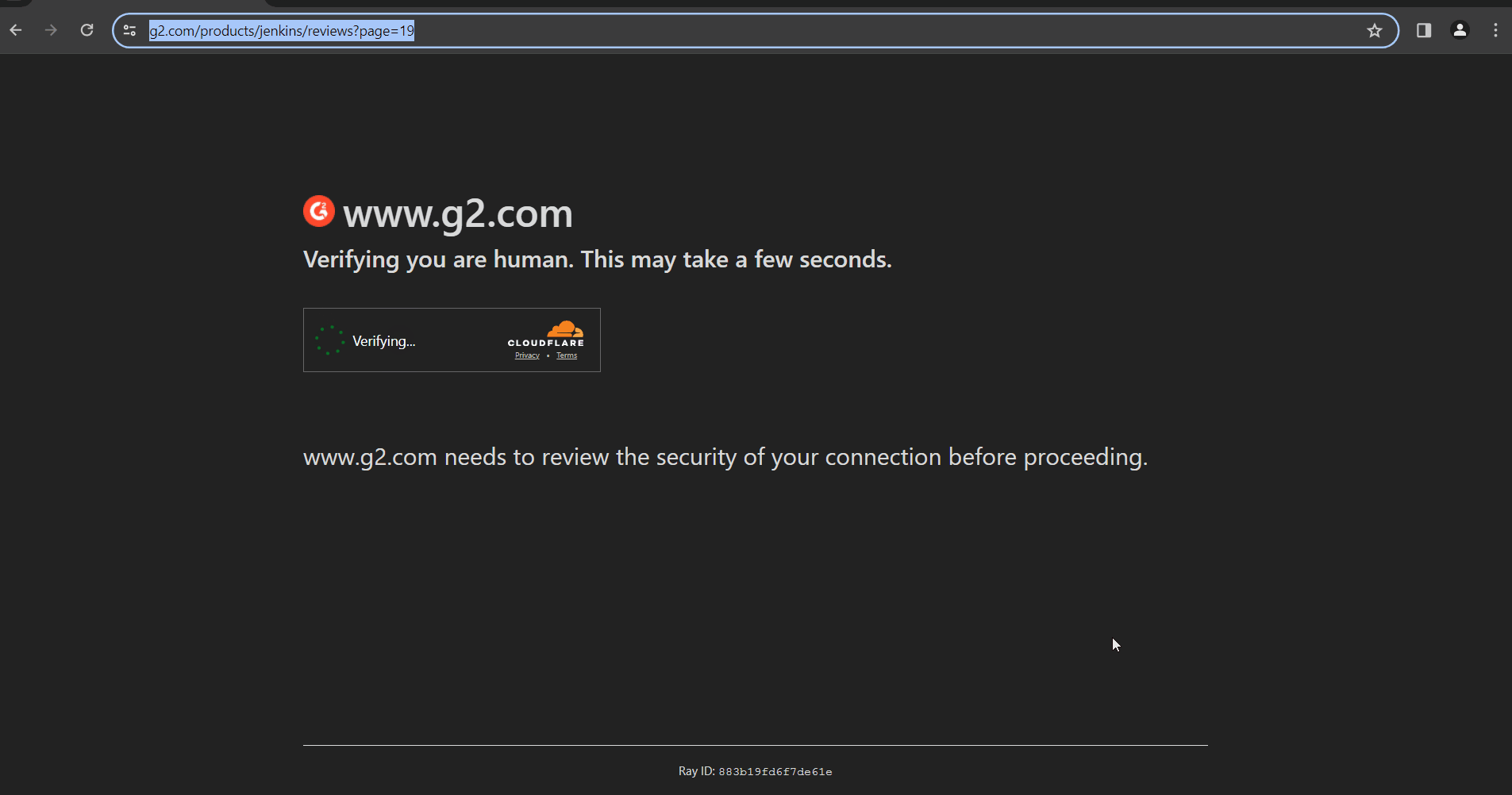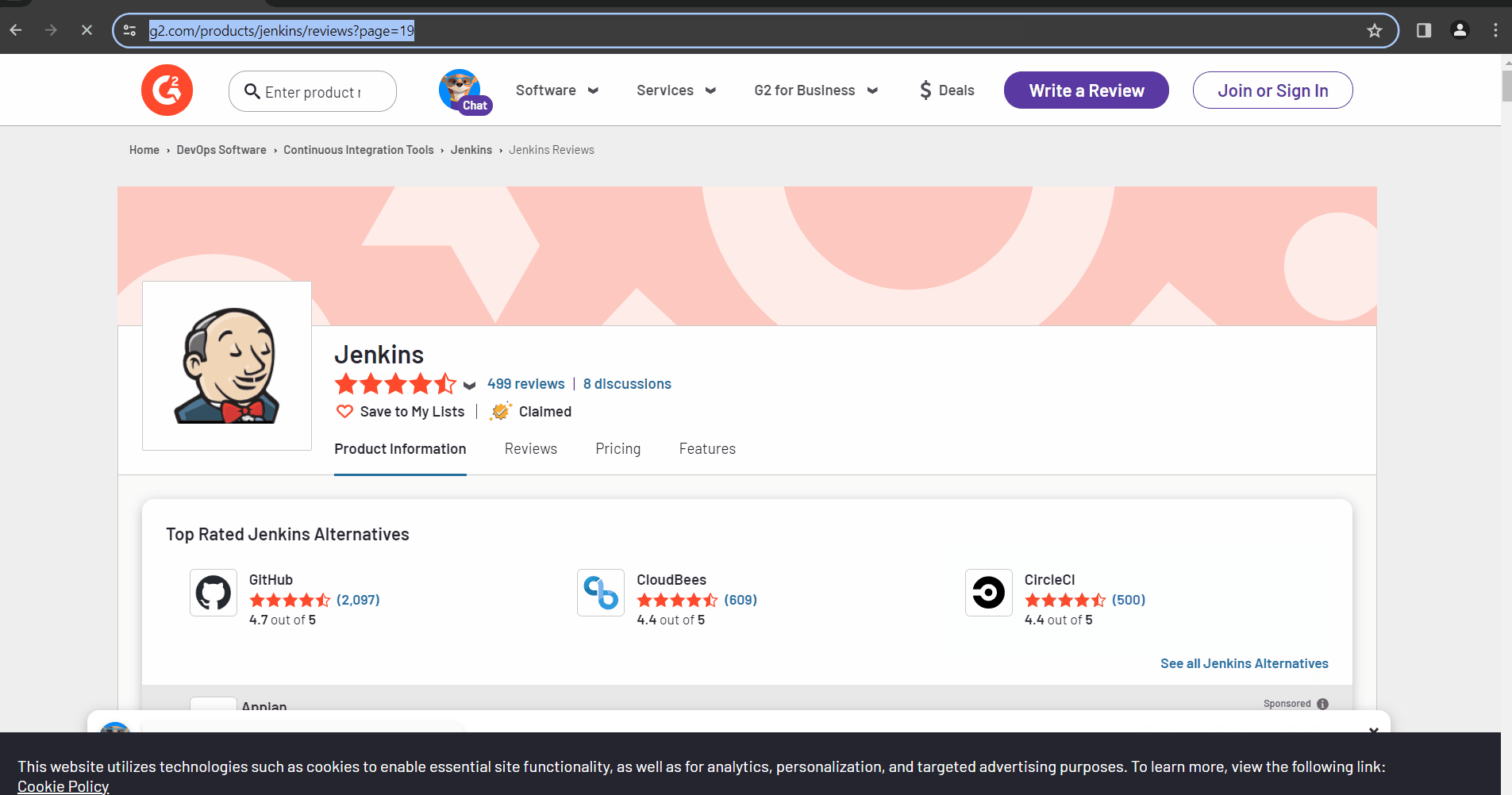
How do I access Cloudflare-protected pages using Botasaurus?
Cloudflare is the most popular protection system on the web. So, let's see how Botasaurus can help you solve various Cloudflare challenges.
Connection Challenge
This is the single most popular challenge and requires making a browser-like connection with appropriate headers. It's commonly used for:
- Product Pages
- Blog Pages
- Search Result Pages
Example Page: https://www.g2.com/products/github/reviews
What Works?
- Visiting the website via Google Referrer (which makes is seems as if the user has arrived from google search).
from botasaurus.browser import browser, Driver @browser def scrape_heading_task(driver: Driver, data): # Visit the website via Google Referrer driver.google_get("https://www.g2.com/products/github/reviews") driver.prompt() heading = driver.get_text('.product-head__title [itemprop="name"]') return heading scrape_heading_task()
- Use the request module. The Request Object is smart and, by default, visits any link with a Google Referrer. Although it works, you will need to use retries.
from botasaurus.request import request, Request @request(max_retry=10) def scrape_heading_task(request: Request, data): response = request.get('https://www.g2.com/products/github/reviews') print(response.status_code) response.raise_for_status() return response.text scrape_heading_task()
JS with Captcha Challenge
This challenge requires performing JS computations that differentiate a Chrome controlled by Selenium/Puppeteer/Playwright from a real Chrome. It also involves solving a Captcha. It's used to for pages which are rarely but sometimes visited by people, like:
- 5th Review page
- Auth pages
Example Page: https://www.g2.com/products/github/reviews.html?page=5&product_id=github
What Does Not Work?
Using @request does not work because although it can make browser-like HTTP requests, it cannot run JavaScript to solve the challenge.
What Works?
Pass the bypass_cloudflare=True argument to the google_get method.
from botasaurus.browser import browser, Driver @browser def scrape_heading_task(driver: Driver, data): driver.google_get("https://www.g2.com/products/github/reviews.html?page=5&product_id=github", bypass_cloudflare=True) driver.prompt() heading = driver.get_text('.product-head__title [itemprop="name"]') return heading scrape_heading_task()
What are the benefits of a UI Scraper?
Here are some benefits of creating a scraper with a user interface:
- Simplify your scraper usage for customers, eliminating the need to teach them how to modify and run your code.
- Protect your code by hosting the scraper on the web and offering a monthly subscription, rather than providing full access to your code. This approach:
- Safeguards your Python code from being copied and reused, increasing your customer's lifetime value.
- Generate monthly recurring revenue via subscription from your customers, surpassing a one-time payment.
- Enable sorting, filtering, and downloading of data in various formats (JSON, Excel, CSV, etc.).
- Provide access via a REST API for seamless integration.
- Create a polished frontend, backend, and API integration with minimal code.
How to run a UI-based scraper?
Let's run the Botasaurus Starter Template (the recommended template for greenfield Botasaurus projects), which scrapes the heading of the provided link by following these steps:
-
Clone the Starter Template:
git clone https://github.com/omkarcloud/botasaurus-starter my-botasaurus-project cd my-botasaurus-project -
Install dependencies (will take a few minutes):
python -m pip install -r requirements.txt python run.py install -
Run the scraper:
python run.py
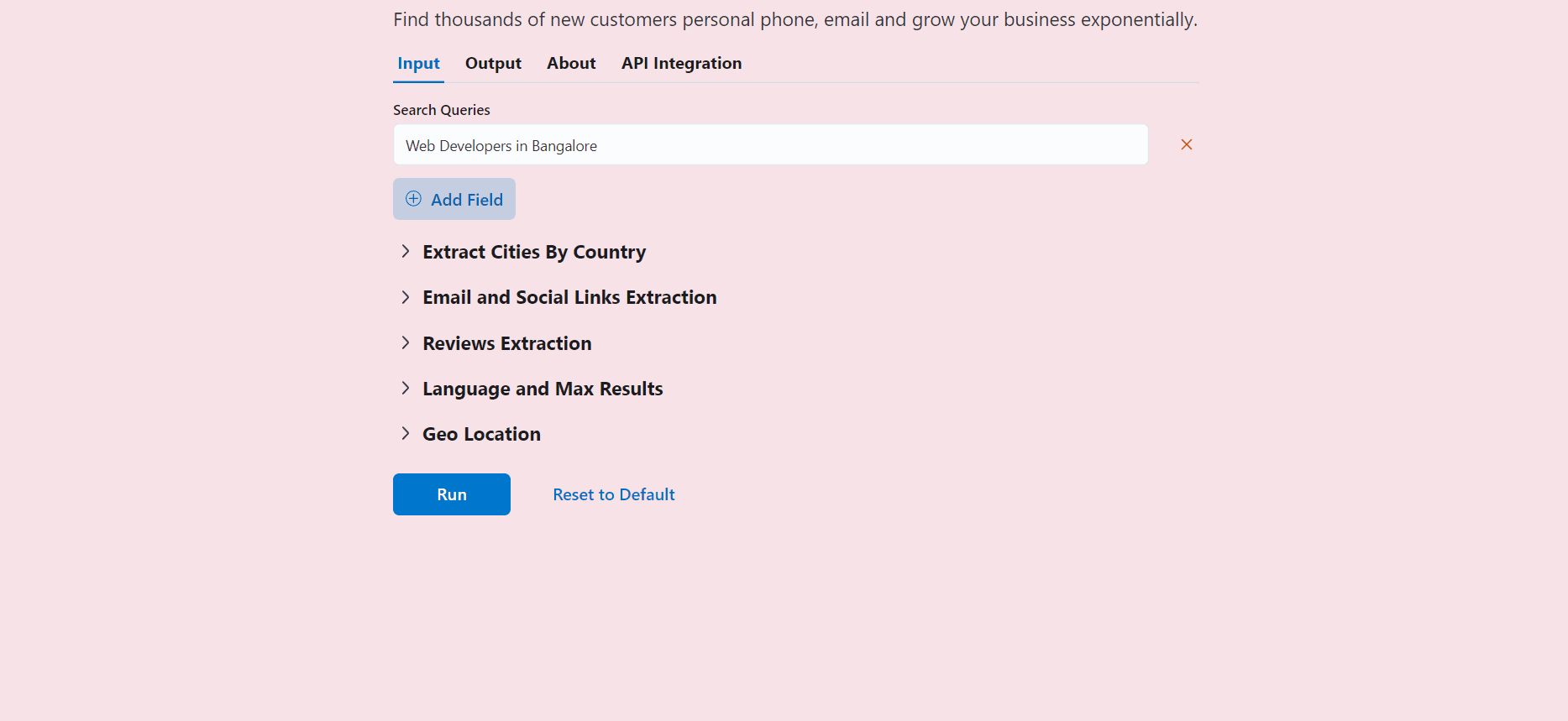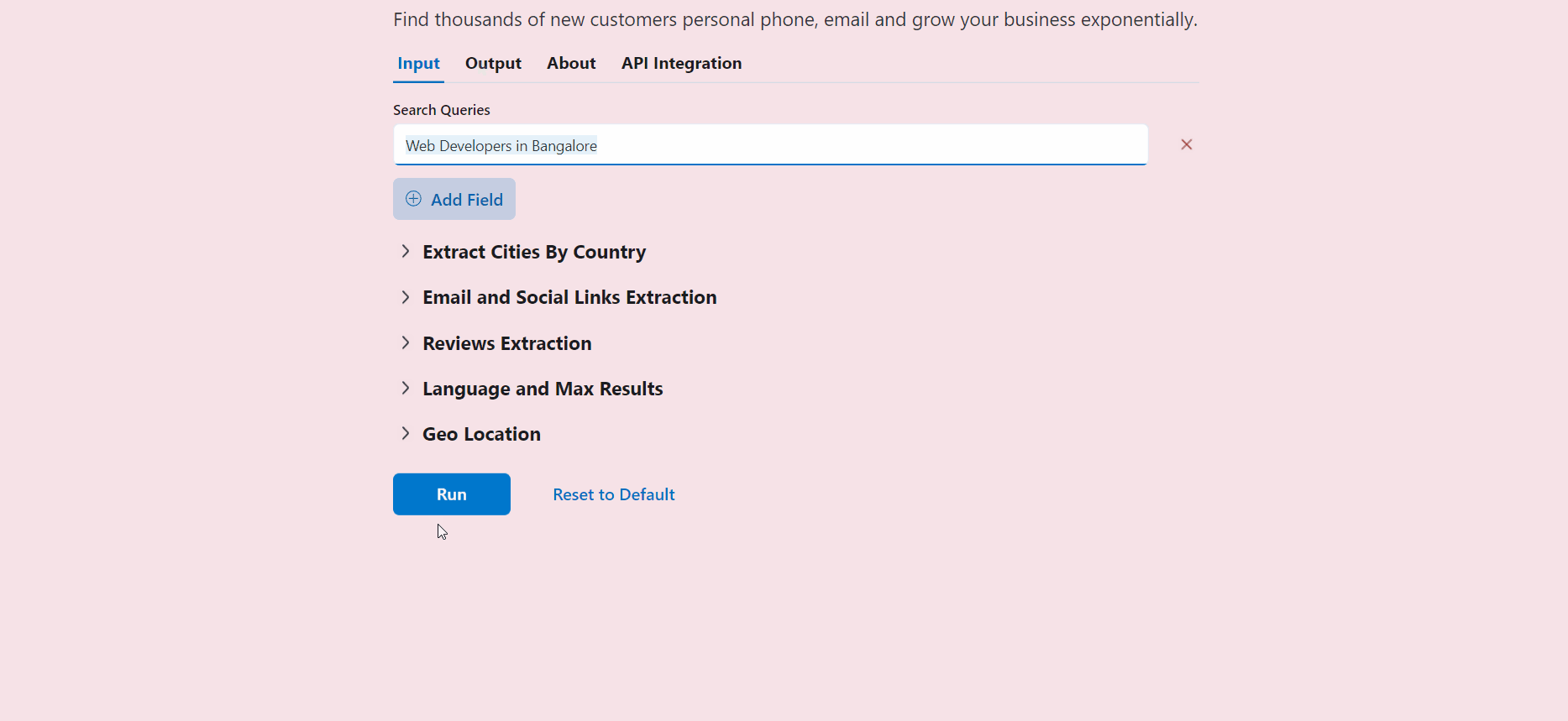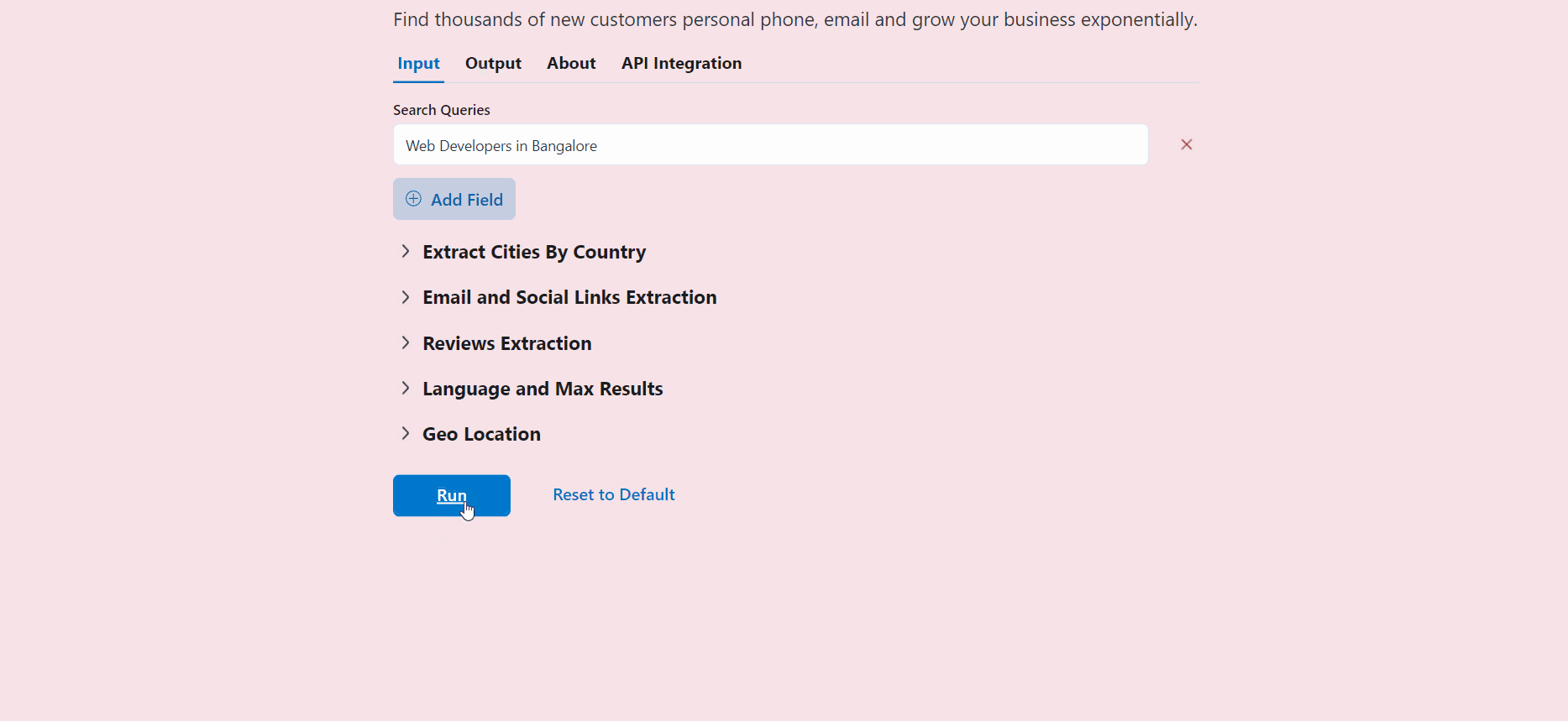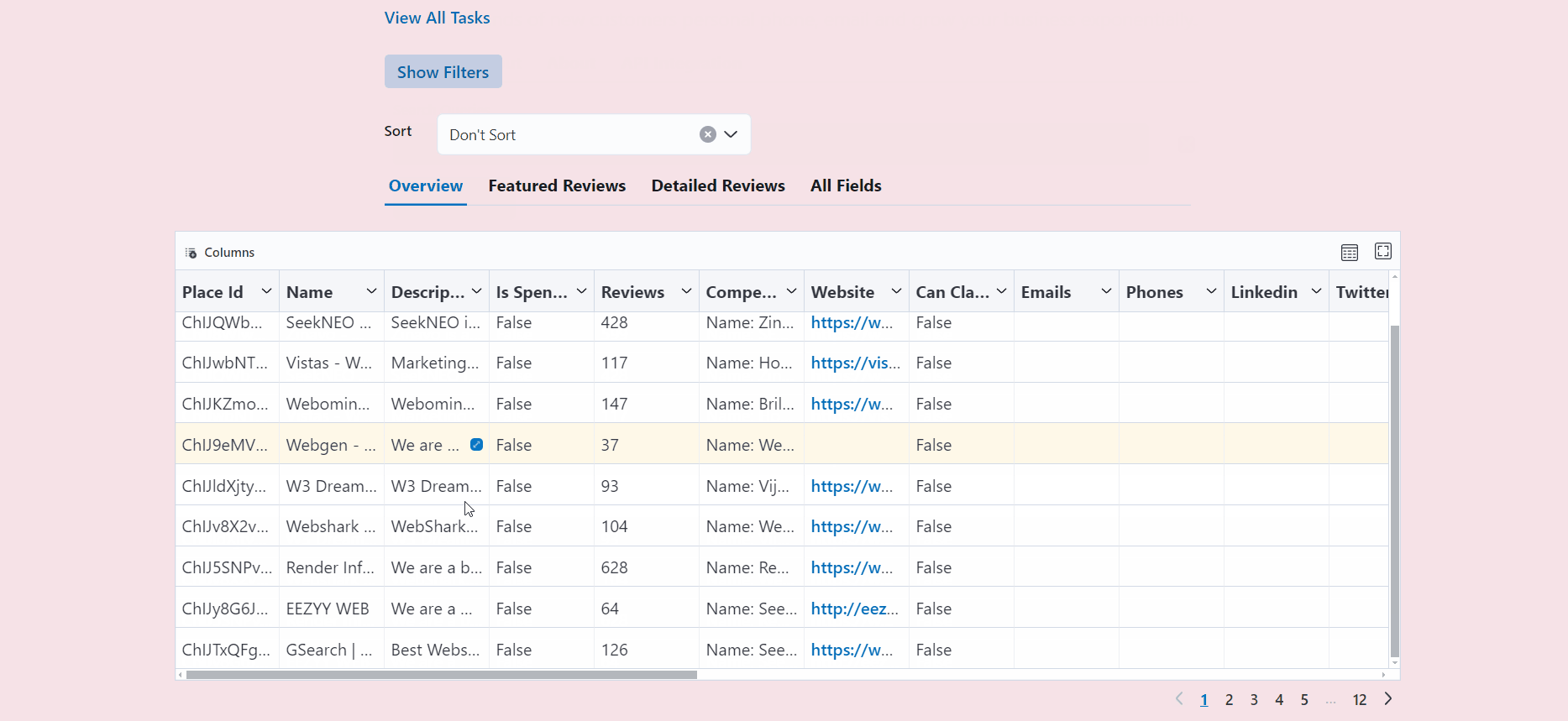
Your browser will automatically open up at http://localhost:3000/. Then, enter the link you want to scrape (e.g., https://www.omkar.cloud/) and click on the Run Button.
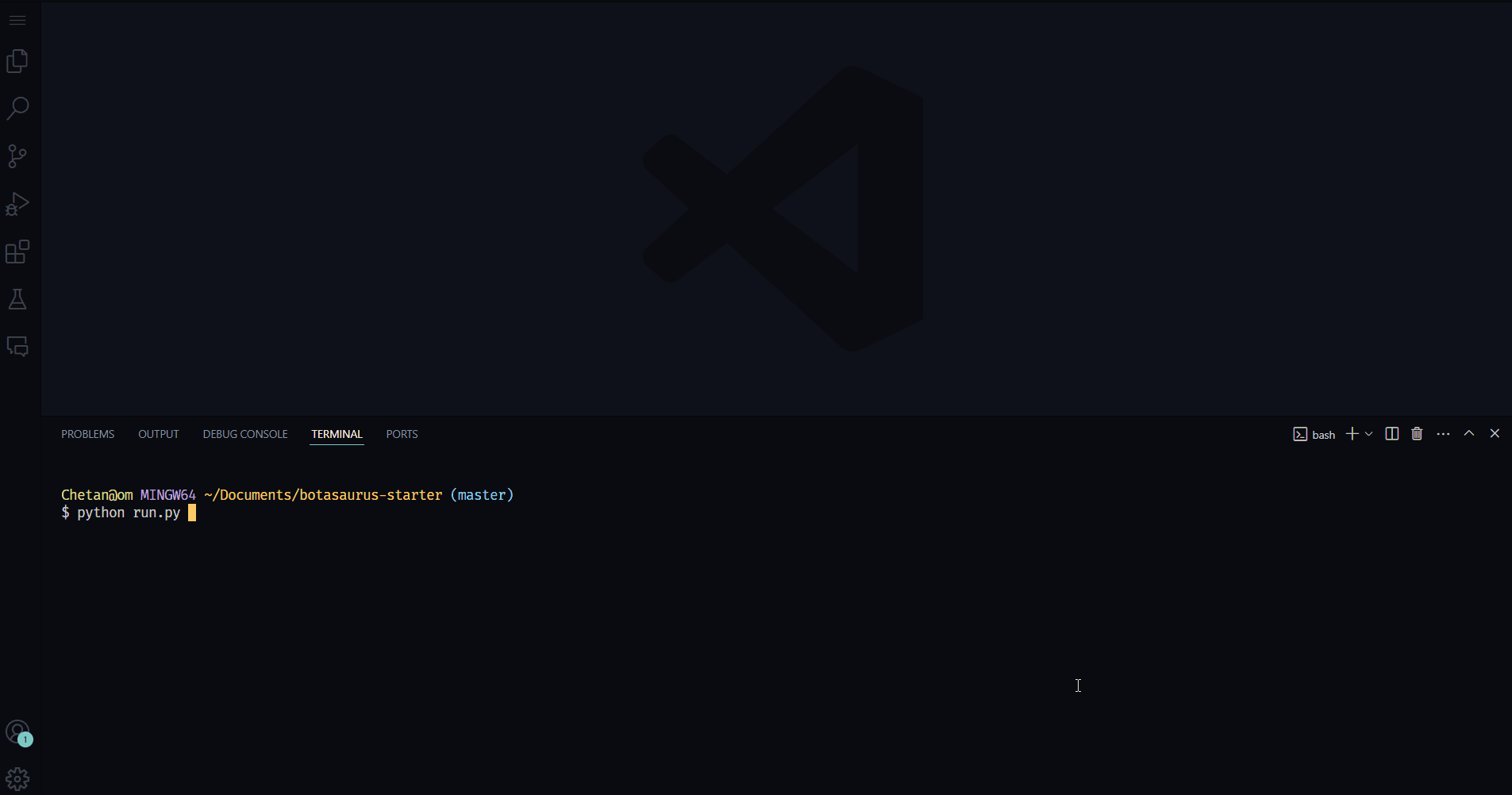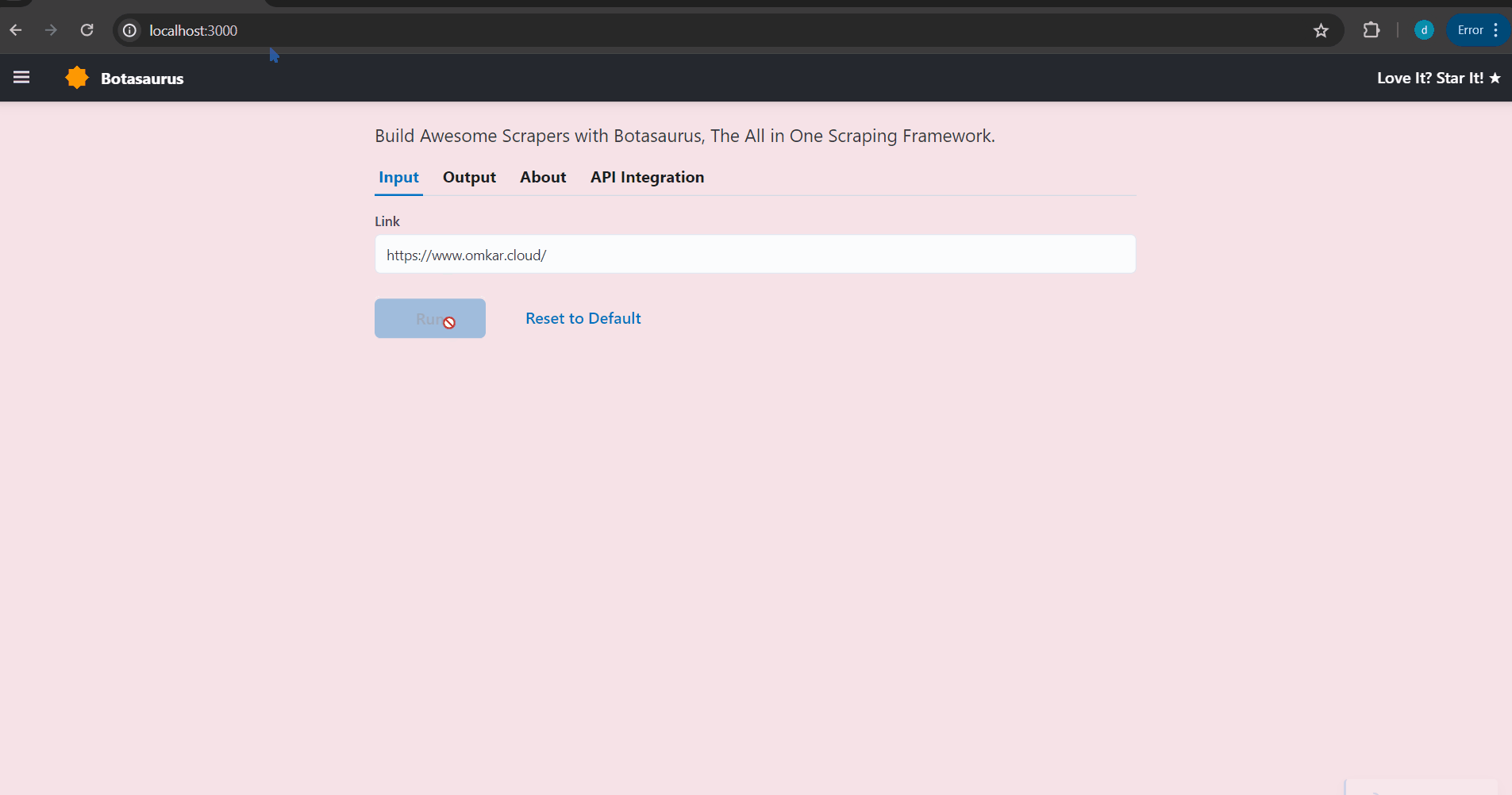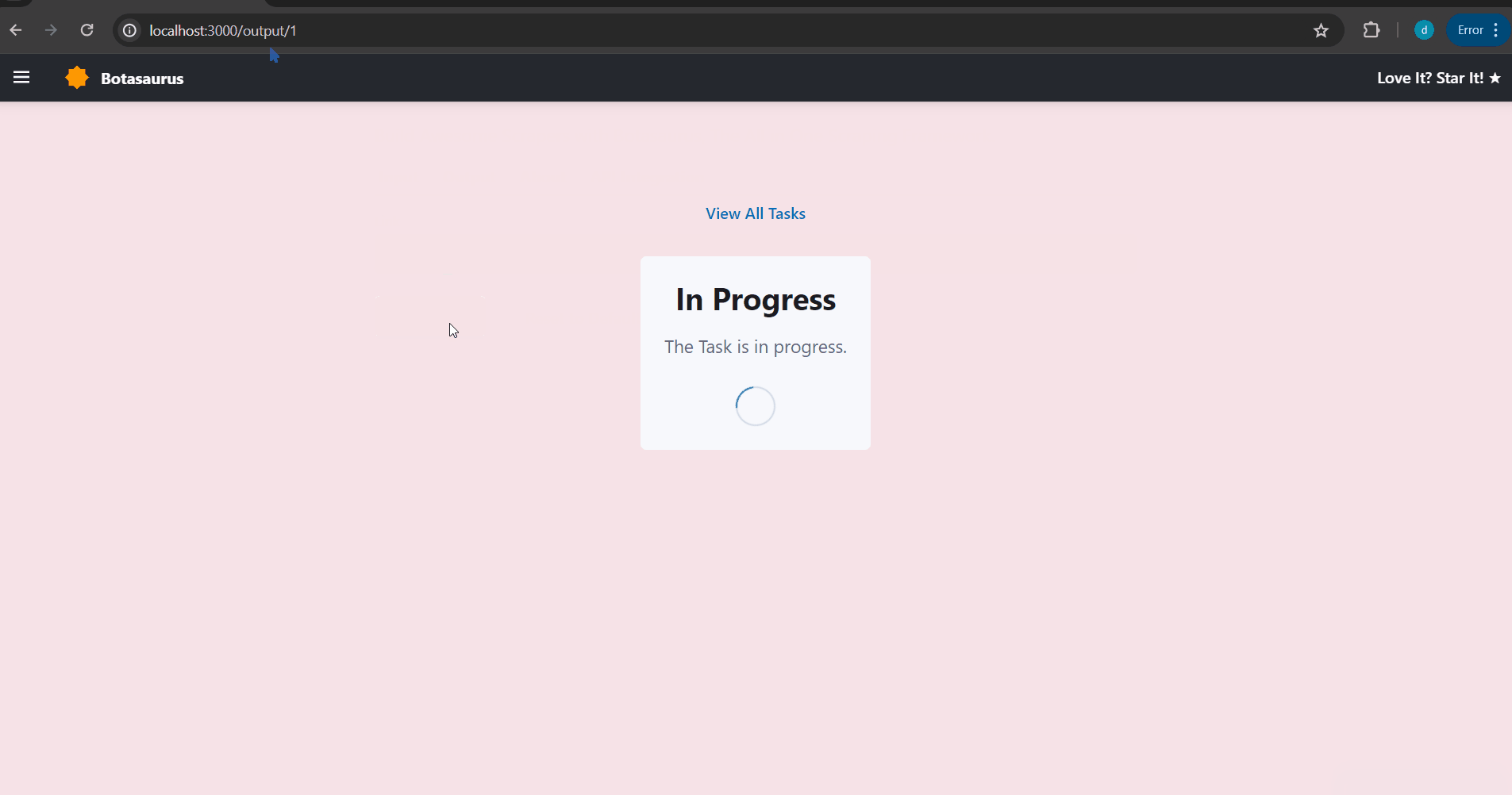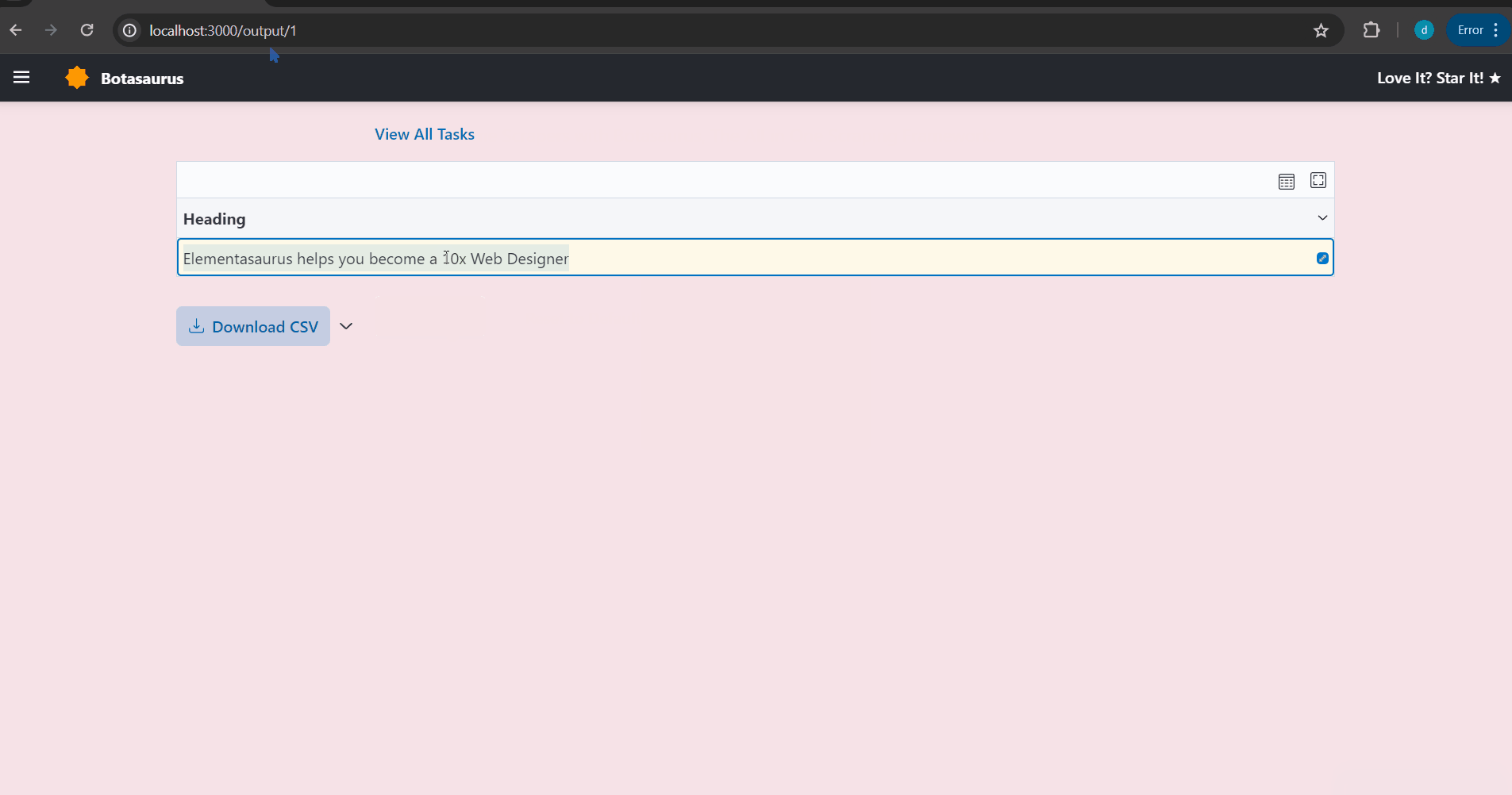
After some seconds, the data will be scraped.
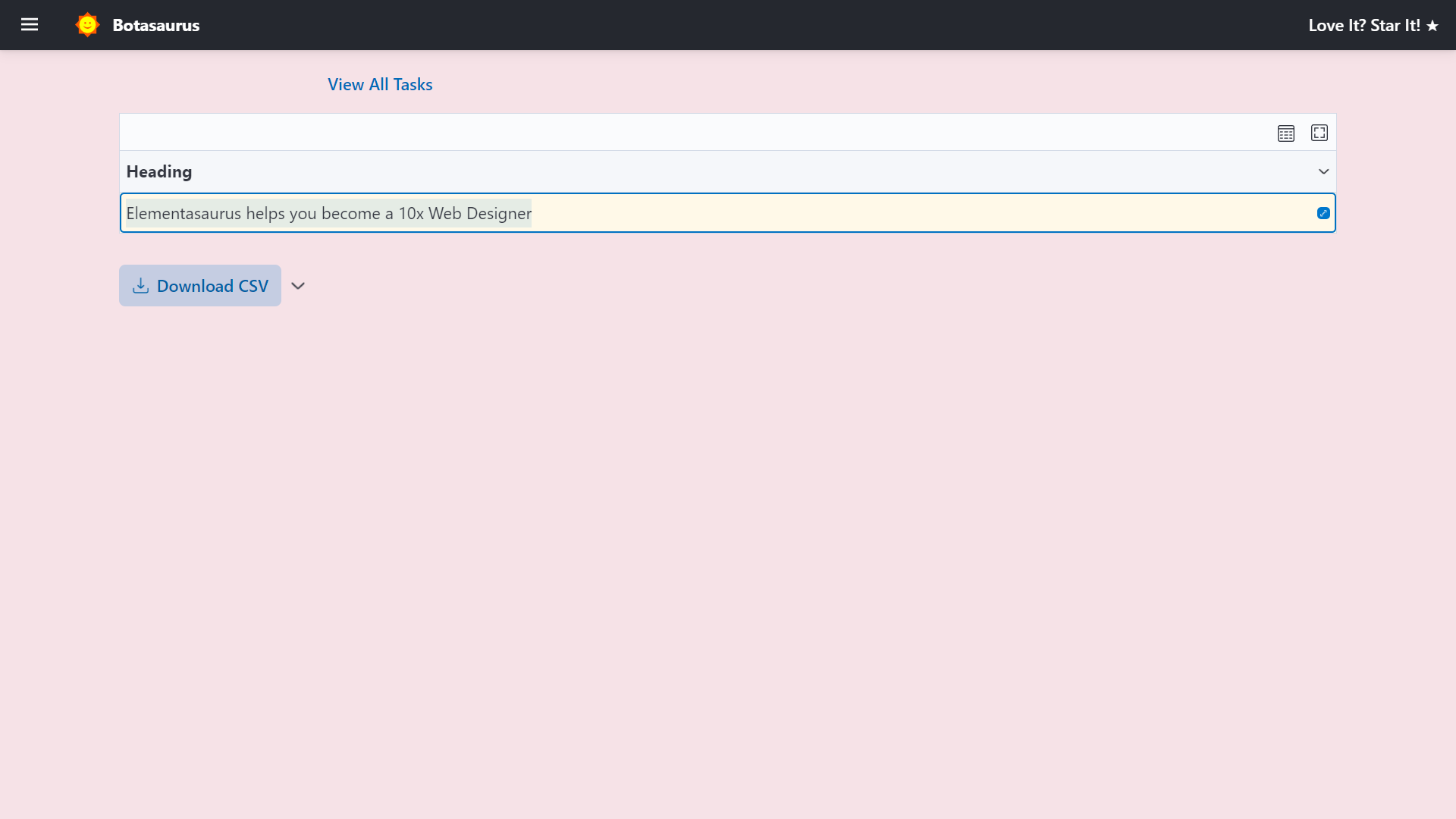
Visit http://localhost:3000/output to see all the tasks you have started.
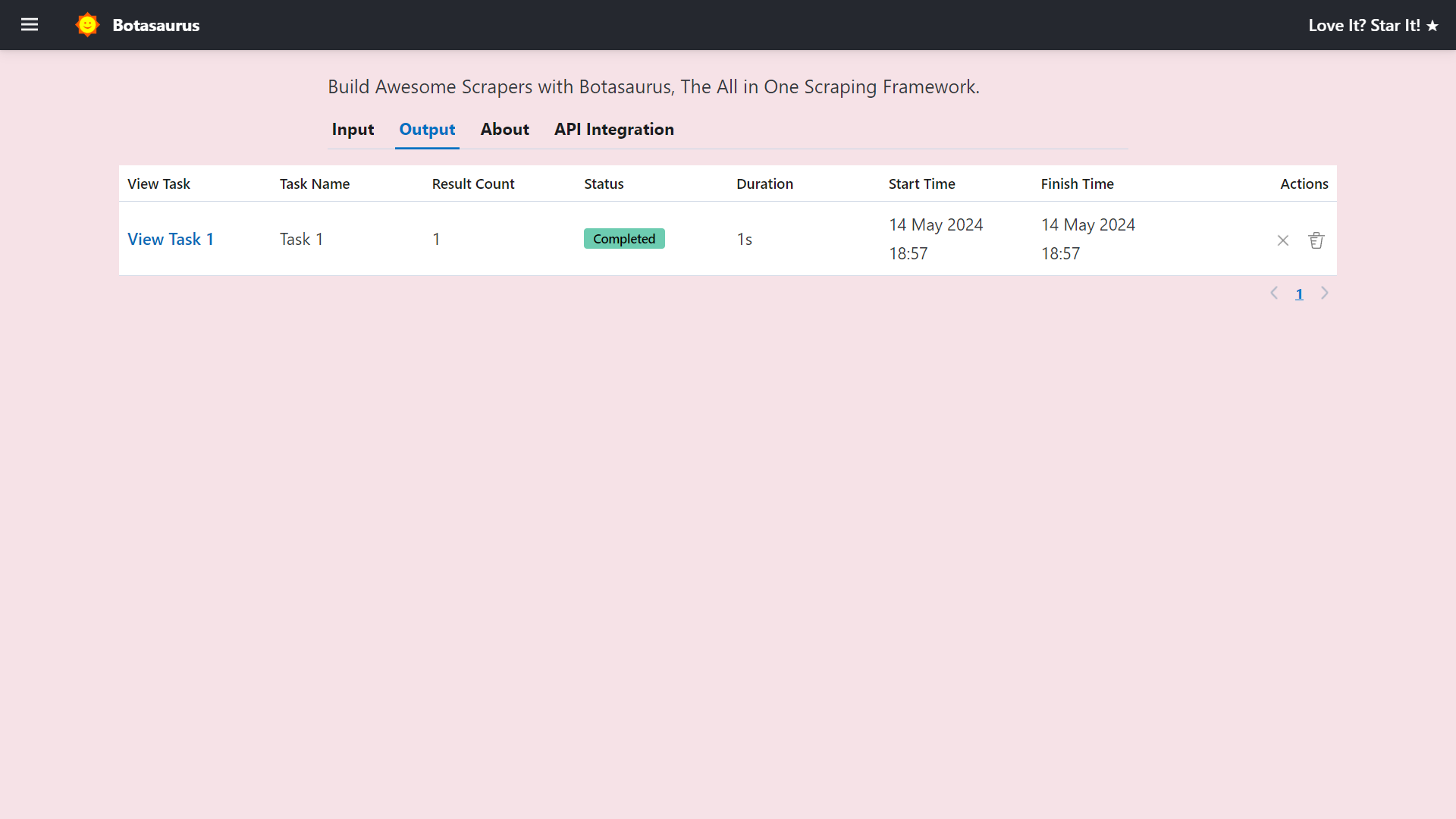
Go to http://localhost:3000/about to see the rendered README.md file of the project.
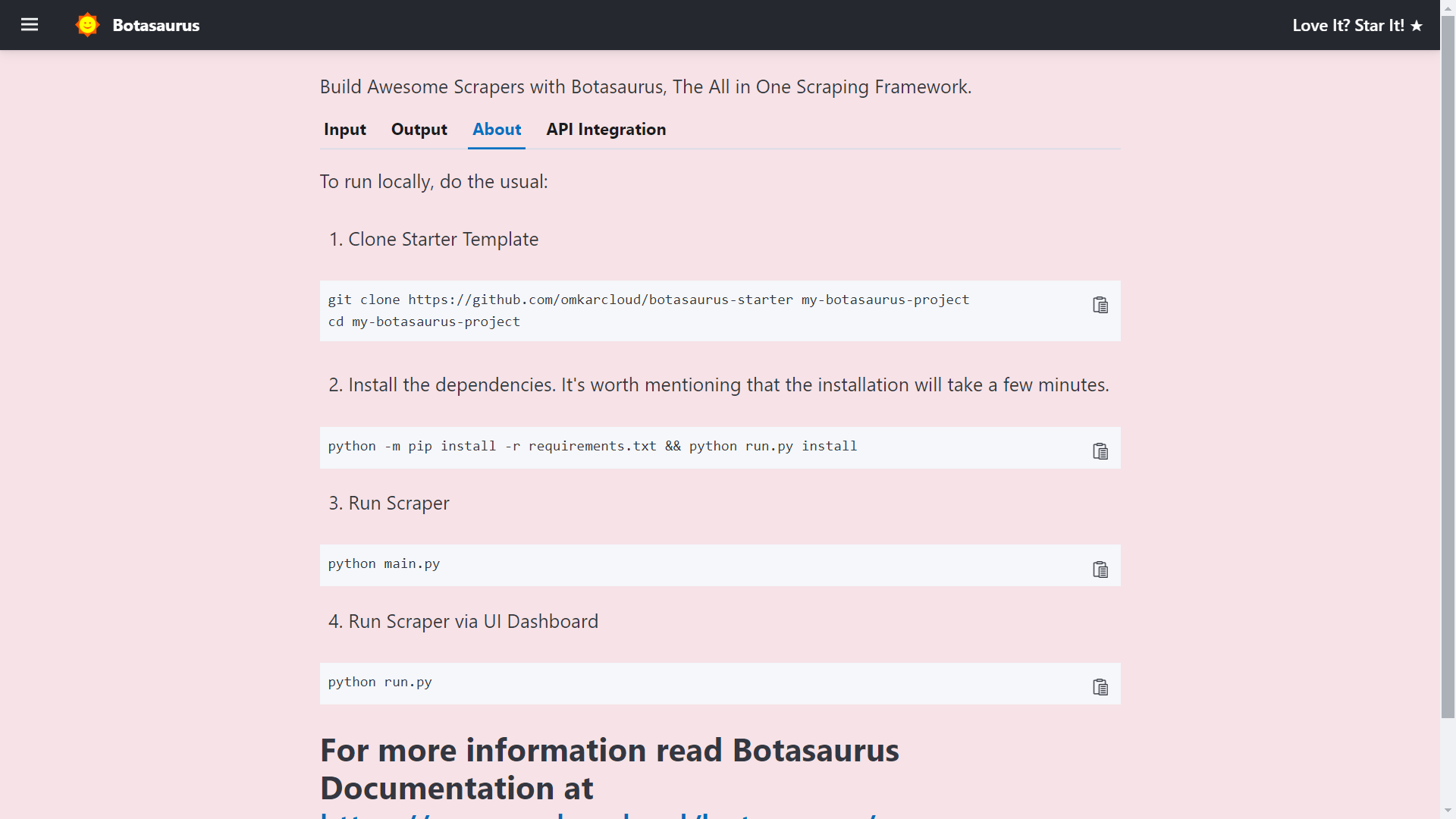
Finally, visit http://localhost:3000/api-integration to see how to access the Scraper via API.
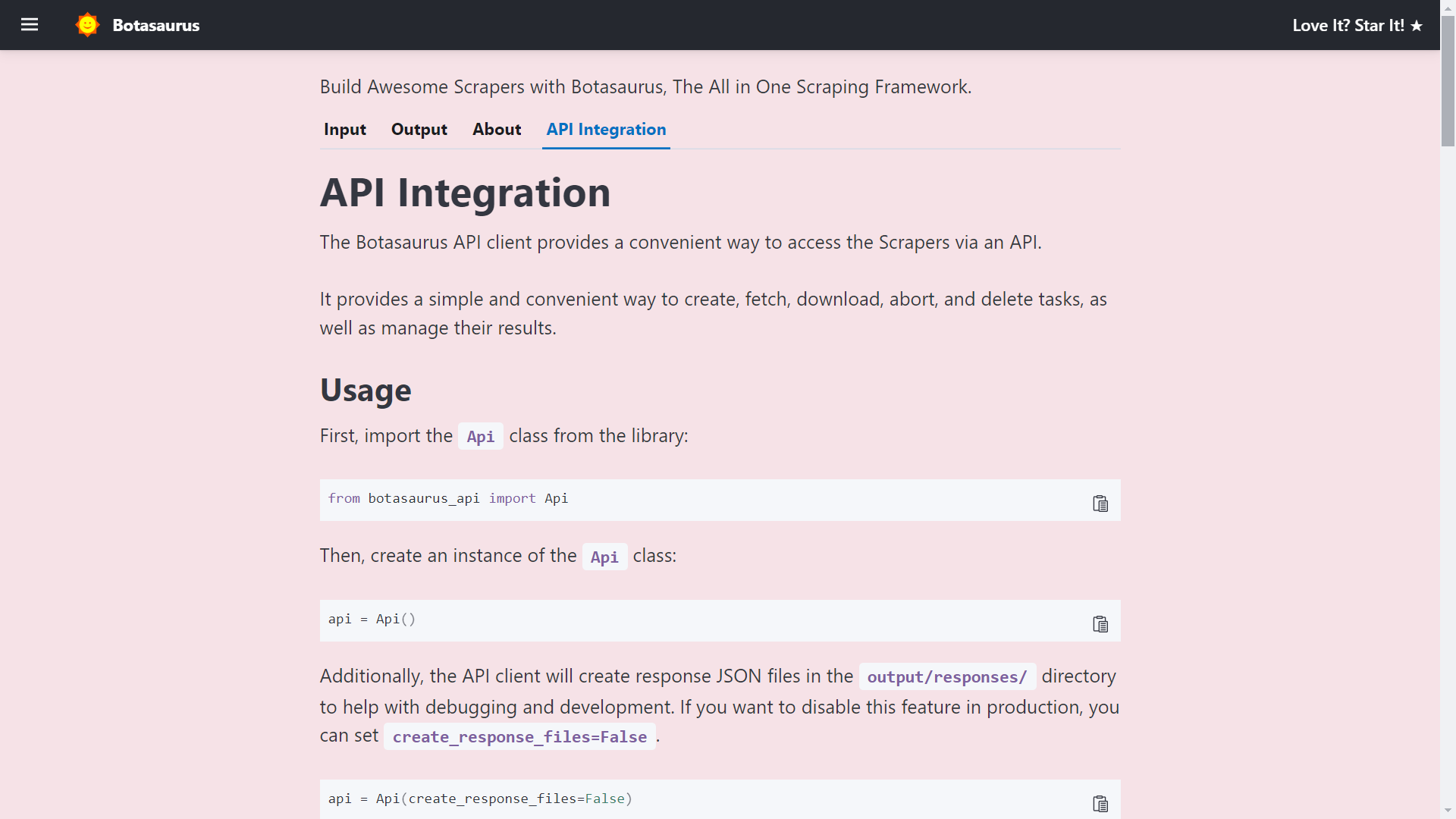
The API Documentation is generated dynamically based on your Scraper's Inputs, Sorts, Filters, etc., and is unique to your Scraper.
So, whenever you need to run the Scraper via API, visit this tab and copy the code specific to your Scraper.
How to create a UI Scraper using Botasaurus?
Creating a UI Scraper with Botasaurus is a simple 3-step process:
- Create your Scraper function
- Add the Scraper to the Server using 1 line of code
- Define the input controls for the Scraper
To understand these steps, let's go through the code of the Botasaurus Starter Template that you just ran.
Step 1: Create the Scraper Function
In src/scrape_heading_task.py, we define a scraping function which basically does the following:
- Receives a
dataobject and extracts the "link". - Retrieves the HTML content of the webpage using the "link".
- Converts the HTML into a BeautifulSoup object.
- Locates the heading element, extracts its text content and returns it.
from botasaurus.request import request, Request from botasaurus.soupify import soupify @request def scrape_heading_task(request: Request, data): # Visit the Link response = request.get(data["link"]) # Create a BeautifulSoup object soup = soupify(response) # Retrieve the heading element's text heading = soup.find('h1').get_text() # Save the data as a JSON file in output/scrape_heading_task.json return { "heading": heading }
Step 2: Add the Scraper to the Server
In backend/scrapers.py, we:
- Import our scraping function
- Use
Server.add_scraper()to register the scraper
from botasaurus_server.server import Server from src.scrape_heading_task import scrape_heading_task # Add the scraper to the server Server.add_scraper(scrape_heading_task)
Step 3: Define the Input Controls
In backend/inputs/scrape_heading_task.js we:
- Define a
getInputfunction that takes the controls parameter - Add a link input control to it
- Use comments to enable intellisense in VSCode (Very Very Important)
/** * @typedef {import('../../frontend/node_modules/botasaurus-controls/dist/index').Controls} Controls */ /** * @param {Controls} controls */ function getInput(controls) { controls // Render a Link Input, which is required, defaults to "https://www.omkar.cloud/". .link('link', { isRequired: true, defaultValue: "https://www.omkar.cloud/" }) }
Above was a simple example; below is a real-world example with multi-text, number, switch, select, section, and other controls.
/** * @typedef {import('../../frontend/node_modules/botasaurus-controls/dist/index').Controls} Controls */ /** * @param {Controls} controls */ function getInput(controls) { controls .listOfTexts('queries', { defaultValue: ["Web Developers in Bangalore"], placeholder: "Web Developers in Bangalore", label: 'Search Queries', isRequired: true }) .section("Email and Social Links Extraction", (section) => { section.text('api_key', { placeholder: "2e5d346ap4db8mce4fj7fc112s9h26s61e1192b6a526af51n9", label: 'Email and Social Links Extraction API Key', helpText: 'Enter your API key to extract email addresses and social media links.', }) }) .section("Reviews Extraction", (section) => { section .switch('enable_reviews_extraction', { label: "Enable Reviews Extraction" }) .numberGreaterThanOrEqualToZero('max_reviews', { label: 'Max Reviews per Place (Leave empty to extract all reviews)', placeholder: 20, isShown: (data) => data['enable_reviews_extraction'], defaultValue: 20, }) .choose('reviews_sort', { label: "Sort Reviews By", isRequired: true, isShown: (data) => data['enable_reviews_extraction'], defaultValue: 'newest', options: [{ value: 'newest', label: 'Newest' }, { value: 'most_relevant', label: 'Most Relevant' }, { value: 'highest_rating', label: 'Highest Rating' }, { value: 'lowest_rating', label: 'Lowest Rating' }] }) }) .section("Language and Max Results", (section) => { section .addLangSelect() .numberGreaterThanOrEqualToOne('max_results', { placeholder: 100, label: 'Max Results per Search Query (Leave empty to extract all places)' }) }) .section("Geo Location", (section) => { section .text('coordinates', { placeholder:
编辑推荐精选


音述AI
全球首个AI音乐社区
音述AI是全球首个AI音乐社区,致力让每个人都能用音乐表达自我。音述AI提供零门槛AI创作工具,独创GETI法则帮助用户精准定义音乐风格,AI润色功能支持自动优化作品质感。音述AI支持交流讨论、二次创作与价值变现。针对中文用户的语言习惯与文化背景进行专门优化,支持国风融合、C-pop等本土音乐标签,让技术更好地承载人文表达。


lynote.ai
一站式搞定所有学习需求
不再被海量信息淹没,开始真正理解知识。Lynote 可摘要 YouTube 视频、PDF、文章等内容。即时创建笔记,检测 AI 内容并下载资料,将您的学习效率提升 10 倍。


AniShort
为AI短剧协作而生
专为AI短剧协作而生的AniShort正式发布,深度重构AI短剧全流程生产模式,整合创意策划、制作执行、实时协作、在线审片、资产复用等全链路功能,独创无限画布、双轨并行工业化工作流与Ani智能体助手,集成多款主流AI大模型,破解素材零散、版本混乱、沟通低效等行业痛点,助力3人团队效率提升800%,打造标准化、可追溯的AI短剧量产体系,是AI短剧团队协同创作、提升制作效率的核心工具。


seedancetwo2.0
能听懂你表达的视频模型
Seedance two是基于seedance2.0的中国大模型,支持图像、视频、音频、文本四种模态输入,表达方式更丰富,生成也更可控。


nano-banana纳米香蕉中文站
国内直接访问,限时3折
输入简单文字,生成想要的图片,纳米香蕉中文站基于 Google 模型的 AI 图片生成网站,支持文字生图、图生图。官网价格限时3折活动


扣子-AI办公
职场AI,就用扣子
AI办公助手,复杂任务高效处理。办公效率低?扣子空间AI助手支持播客生成、PPT制作、网页开发及报告写作,覆盖科研、商业、舆情等领�域的专家Agent 7x24小时响应,生活工作无缝切换,提升50%效率!


堆友
多风格AI绘画神器
堆友平台由阿里巴巴设计团队创建,作为一款AI驱动的设计工具,专为设计师提供一站式增长服务。功能覆盖海量3D素材、AI绘画、实时渲染以及专业抠图,显著提升设计品质和效率。平台不仅提供工具,还是一个促进创意交流和个人发展的空间,界面友好,适合所有级别的设计师和创意工作者。


码上飞
零代码AI应用开发平台
零代码AI应用开发平台,用户只需一句话简单描述需求,AI能自动生成小程序、APP或H5网页应用,无需编写代码。


Vora
免费创建高清无水印Sora视频
Vora是一个免费创建高清无水印Sora视频的AI工具


Refly.AI
最适合小白的AI自动化工作流平台
无需编码,轻松生成可复用、可变现的AI自动化工作流
推荐工具精选





AI云服务特惠
懂AI专属折扣关注微信公众号
最新AI工具、AI资讯
独家AI资源、AI项目落地

微信扫一扫关注公众号