


BGmi
BGmi 是一个用于追番的命令行程序。





待办事项
更新日志
v4
- 命令自动补全,使用
bgmi completion zsh/bash生成 - 添加
mikan_url配置,用于配置蜜柑计划镜像站 - 添加
proxy设置 - 新的 WEB 用户界面
- 将配置项
transmission.rpc_url重命名为transmission.rpc_host - 修复 Transmission 配置的默认值
v3
- 新增配置项
global_include_keywords,用于设置全局包含关键词 - 新增配置项
save_path_map,用于设置不同动画的下载路径 - 使用 TOML 作为配置文件格式
- 不再支持 Python 3.7
- 不再支持 Python 3.6
- 支持扩展下载方式
- 移除迅雷离线
- 支持 qbittorrent-webapi
- 停止支持 Python 2、3.4 和 3.5
- Transmission RPC 认证设置
- 支持 deluge-rpc
- 使用最大和最小集数筛选搜索结果
特性
- 多个数据源可选:bangumi_moe、mikan_project 或 dmhy
- 使用 aria2、transmission、qbittorrent 或 deluge 下载番剧
- 提供管理和观看订阅番剧的前端界面
- 弹幕支持
- 提供 uTorrent 支持的 RSS Feed 和移动设备支持的 ICS 格式日历
- Bangumi Script:添加自己的番剧解析器
- 番剧放送列表和剧集信息
- 下载番剧时的过滤器(支持关键词、字幕组和正则表达式)
- 多平台支持:Windows、*nux 以及路由器系统
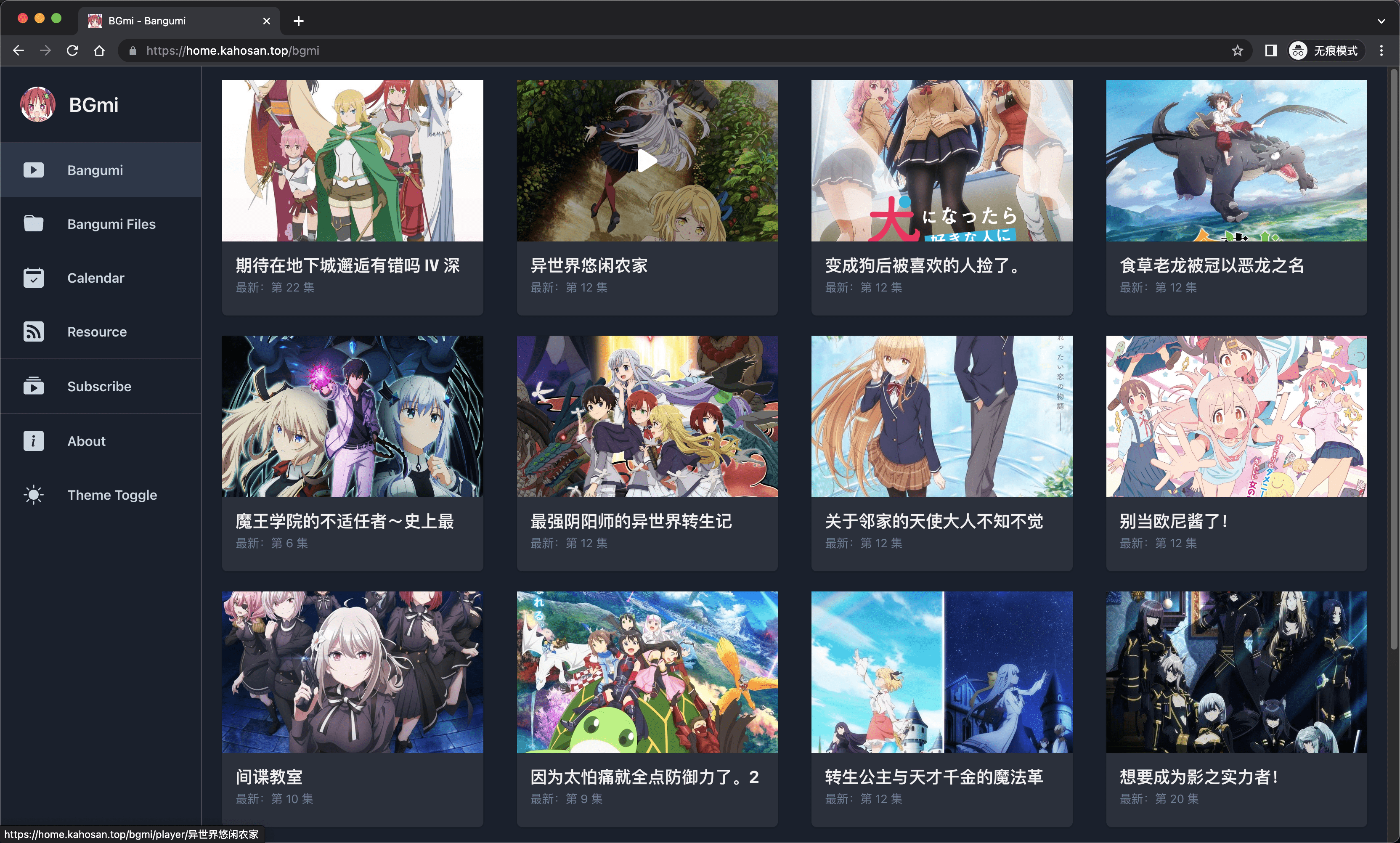
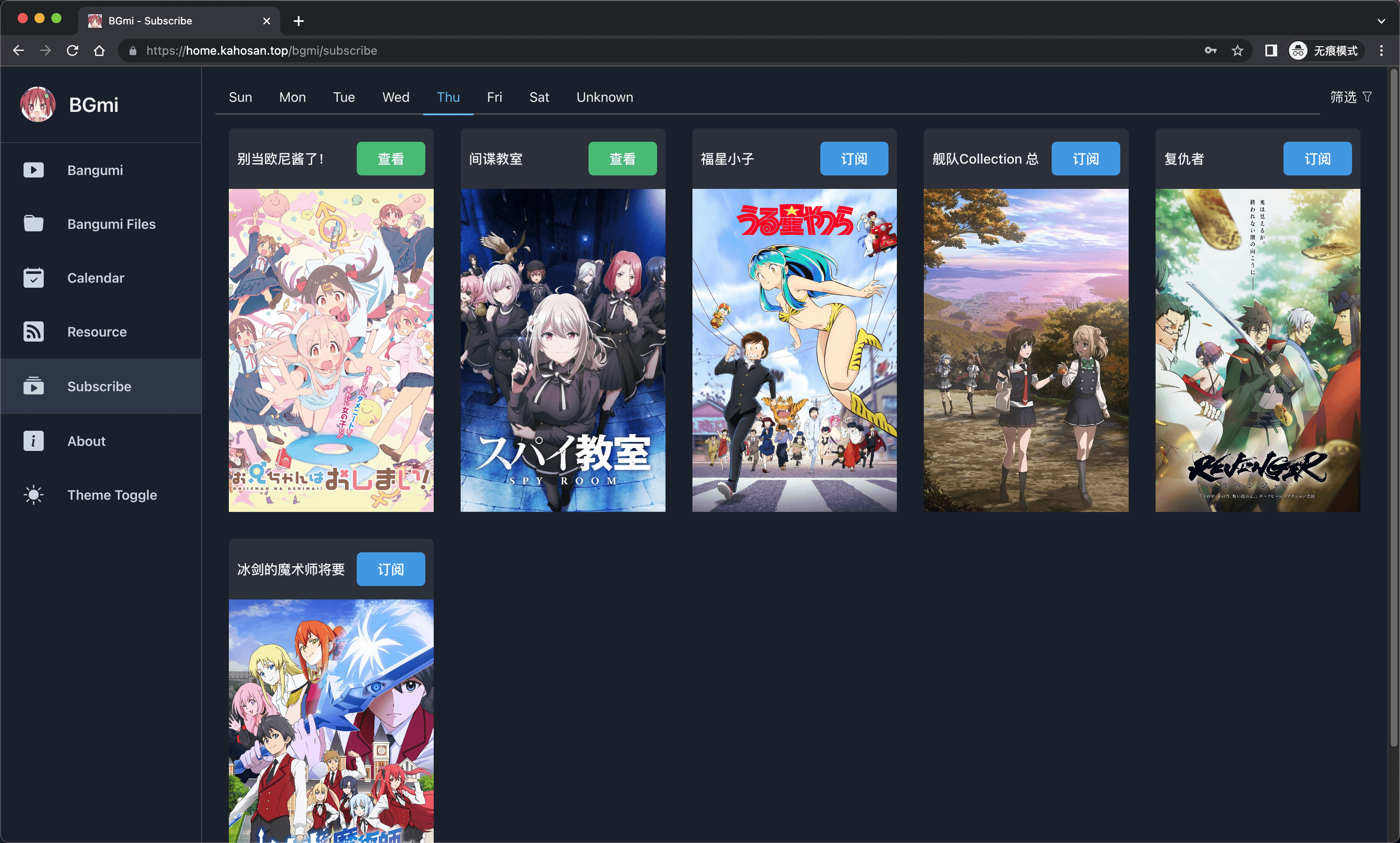
安装
使用 pipx 安装(推荐):
pipx install bgmi
使用 pip 安装稳定版本:
pip install bgmi
或者从源码安装(不推荐)
git clone https://github.com/BGmi/BGmi cd BGmi git checkout master python -m pip install -U pip pip install .
初始化 BGmi
bgmi install
升级(仅 pipx 安装)
pipx upgrade bgmi bgmi upgrade
升级(仅 pip 安装)
pip install bgmi -U bgmi upgrade
升级后请确保运行 bgmi upgrade
使用 Docker
参见 BGmi/bgmi-docker-all-in-one
使用
查看可用的命令
bgmi --help
--help 选项同样适用于所有的子命令,本文档仅介绍了一些基础用法。
命令自动补全
bash
bgmi completion bash > ~/.bash_completion.d/bgmi
zsh
oh-my-zsh
bgmi completion zsh > .oh-my-zsh/completions/_bgmi
我不使用其他的 zsh 插件管理器,具体的安装方法请查询你使用的插件管理器文档
配置 BGmi
BGmi提供两种方式配置BGmi的各项运行参数,分别为配置文件与环境变量。
配置文件
bgmi的配置文件位于${BGMI_PATH}/config.toml,在未设置BGMI_PATH环境变量时,${BGMI_PATH}默认为~/.bgmi/。
查看当前BGmi设置:
bgmi config # 查看当前各项设置默认值。
data_source = "bangumi_moe" # 番剧数据源,!!! 请不要手动修改此选项 !!! download_delegate = "aria2-rpc" # 番剧下载工具 (aria2-rpc, transmission-rpc, deluge-rpc, qbittorrent-webapi) tmp_path = "tmp/tmp" # 临时目录 save_path = "tmp/bangumi" # 下载番剧保存地址 max_path = 3 # 抓取数据时每个番剧最大抓取页数 bangumi_moe_url = "https://bangumi.moe" share_dmhy_url = "https://share.dmhy.org" mikan_url = "https://mikanani.me" mikan_username = "" # 蜜柑计划的用户名 mikan_password = "" # 蜜柑计划的密码 enable_global_filters = true global_filters = [ "Leopard-Raws", "hevc", "x265", "c-a Raws", "U3-Web", ] proxy = '' # http代理示例: http://127.0.0.1:1080 [save_path_map] # 针对每部番剧设置下载路径 '致不灭的你 第二季' = '/home/trim21/downloads/bangumi/致不灭的你/s2/' # 如果使用绝对路径,可能导致web-ui无法正确显示视频文件。 '致不灭的你 第三季' = './致不灭的你/s3/' # 以save_path为基础路径的相对路径 [http] admin_token = "dYMj-Z4bDRoQfd3x" # web ui的密码 danmaku_api_url = "" serve_static_files = false [aria2] rpc_url = "http://localhost:6800/rpc" # aria2c RPC URL (不是jsonrpc URL, 如果你的aria2c运行在localhost:6800, 对应的链接为`http://localhost:6800/rpc`) rpc_token = "token:" # aria2c RPC token (如果没有设置token, 留空或者设置为`token:`) [transmission] rpc_host = "127.0.0.1" rpc_port = 9091 rpc_username = "your_username" rpc_password = "your_password" rpc_path = "/transmission/rpc" # transmission http rpc的请求路径 [qbittorrent] rpc_host = "127.0.0.1" rpc_port = 8080 rpc_username = "admin" rpc_password = "adminadmin" category = "" [deluge] rpc_url = "http://127.0.0.1:8112/json" rpc_password = "deluge"
环境变量
当BGmi的配置文件还未初始化时,各项运行参数可由环境变量进行配置
环境变量以BGMI_开头,全大写命名,且各级配置以_进行分割,如:
BGMI_DATA_SOURCE=bangumi_moe # 对应配置文件中的data_source = "bangumi_moe"
BGMI_HTTP_ADMIN_TOKEN=dYMj-Z4bDRoQfd3x # 对应配置文件[http]分段中的admin_token = "dYMj-Z4bDRoQfd3x"
...
环境变量暂不支持配置以下项目
enable_global_include_keywords
enable_global_filters
global_include_keywords
global_filters
[save_path_map]
注: 当配置文件生成完毕后,运行配置将会以配置文件为准,环境变量仅用于生成第一份配置文件。
修改配置
使用bgmi config set ...keys --value '...'命令可以修改配置。
如:
bgmi config set http admin_token --value 'my super secret token'
或者
bgmi config set max_path --value '3'
不能用来修改复杂配置,如global_filters,请手动修改配置文件。
支持的数据源
更换数据源
**更换数据源会清空番剧数据库,但是bgmi script不受影响。**之前下载的视频文件不会删除,但是不会在前端显示
如果更换的源为mikan_project,请先配置MIKAN_USERNAME和MIKAN_PASSWORD,其它源不受影响
bgmi source mikan_project
切��换数据源必须使用bgmi source命令,不能手动修改配置文件。手动修改配置文件会导致bgmi报错
设置下载方式
修改配置文件和对应的配置项
download_delegate = "aria2-rpc" # 下载代理
内置可用的选项包括aria2-rpc、transmission-rpc、qbittorrent-webapi以及deluge-rpc。
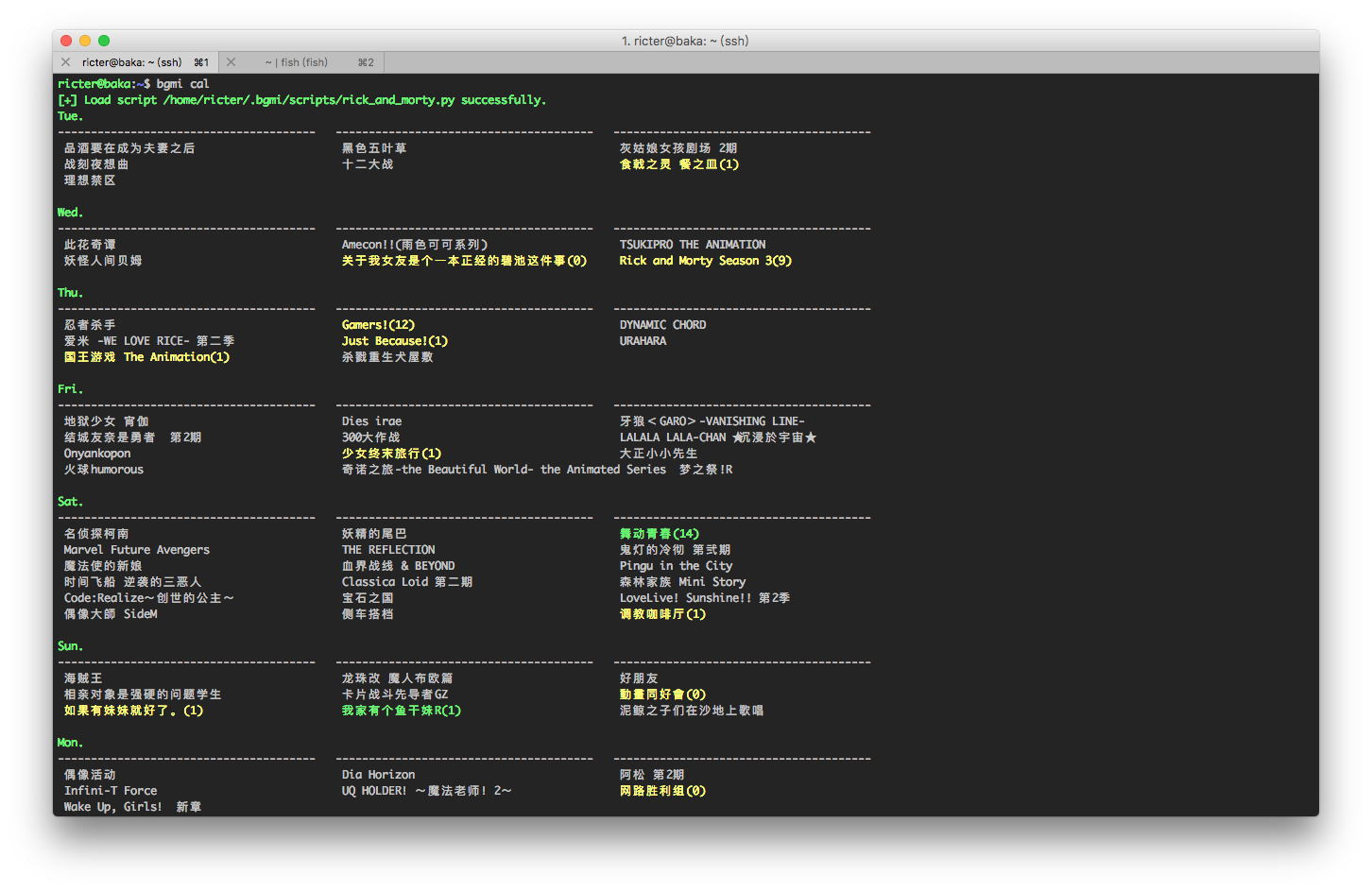
查看目前正在更新的新番
bgmi cal
订阅番剧:
bgmi add "进击的巨人 第三季" "刃牙" "哆啦A梦" bgmi add "高分少女" --episode 0
添加番剧的同时设置下载路径:
bgmi add "高分少女" --episode 0 --save-path './高分少女/S1/'
取消订阅:
bgmi delete "Re:CREATORS"
更新番剧列表并下载番剧:
bgmi update --download # 更新全部 bgmi update "从零开始的魔法书" --download
设置筛选条件:
bgmi list # 列出当前订阅的番剧 bgmi fetch "Re:CREATORS" # include和exclude会忽略大小写。`720p`和`720P`效果相同 bgmi filter "Re:CREATORS" --subtitle "DHR動研字幕組,豌豆字幕组" --include 720P --exclude BIG5 bgmi fetch "Re:CREATORS" # 删除subtitle,include和exclude,添加正则匹配 bgmi filter "Re:CREATORS" --subtitle "" --include "" --exclude "" --regex "..." bgmi filter "Re:CREATORS" --regex "(DHR動研字幕組|豌豆字幕组).*(720P)" bgmi fetch "Re:CREATORS"
设置全局过滤关键词
包含
默认不启用全局包含关键词,可以设置 enable_global_include_keywords = true 启用此功能。
enable_global_include_keywords = true global_include_keywords = ['1080']
排除
有一些预定义的全局过滤关键词,默认会排除标题包含以下关键词的种子。
可以使用 enable_global_filters = false 禁用全局关键词过滤,
enable_global_filters = true global_filters = [ "Leopard-Raws", "hevc", "x265", "c-a Raws", "U3-Web", ]
最后使用bgmi fetch查看筛选结果。
搜索番剧并下载:
bgmi search '为美好的世界献上祝福!' --regex-filter '.*动漫国字幕组.*为美好的世界献上祝福!].*720P.*'
使用--min-episode和--max-episode根据集数筛选下载结果
bgmi search 海贼王 --min-episode 800 --max-episode 820 # 下载 bgmi search 海贼王 --min-episode 800 --max-episode 820 --download
bgmi search命令默认不显示重复集数,如需显示重复集数以便筛选,在命令后添加--dupe显示所有搜索结果
手动修改最近下载的剧集
bgmi list bgmi mark "Re:CREATORS" 1
使用bgmi_http
1.首先下载所有更新中番剧的封面
bgmi cal --download-cover
2.根据是否使用 nginx,设置serve_static_files(使用 nginx 时保持默认设置false,不使用时设为true)
3.下载前端静态文件(可能在安装时已经下载过):
bgmi install
4.在8888端口启动 BGmi HTTP 服务器:
bgmi_http --port=8888 --address=0.0.0.0
在 Windows 上使用bgmi_http
参照上述步骤启动服务器,然后访问http://localhost:8888/。
在*nux 上使用 bgmi_http
可以让BGmi帮助生成相应的 nginx 配置文件
bgmi gen nginx.conf --server-name bgmi.whatever.com
也可以手动编写 nginx 配置,以满足更多需求(如启用 https),以下是一个示例
server { listen 80; server_name bgmi; autoindex on; charset utf-8; location /bangumi { # ~/.bgmi/bangumi # alias到你的`SAVE_PATH` 注意以/结尾 alias /path/to/bangumi/; } location /api { proxy_pass http://127.0.0.1:8888; } location /resource { proxy_pass http://127.0.0.1:8888; } location / { # alias到你的`BGMI_PATH/front_static/`注意以/结尾 alias /path/to/front_static/; } }
也可以添加 aria2c 前端等,具体方法网上有很多,此处不再赘述。
macOS launchctl 服务控制器
参考 issue #77自行设置
弹幕支持
BGmi 使用DPlayer作为前端播放器
如需添加弹幕支持,可在DPlayer#related-projects中选择一个后端自行搭建,或使用DPlayer提供的现成接口https://api.prprpr.me/dplayer/
然后修改配置文件:
[bgmi_http] danmaku_api_url = "https://api.prprpr.me/dplayer/" # 此API由dplayer官方提供
设置你的bgmi_http,享受弹幕支持吧。
调试
日志文件位于{BGMI_PATH}/tmp/
卸载
由于pip的限制,你需要手动清理BGmi在~/.bgmi生成的文件
同样,BGmi添加到你系统的定时任务也不会被自动删除,请手动删除。
*nix:
请手动清理crontab
Windows:
schtasks /Delete /TN 'bgmi updater'
如果你对Python有一些了解,并且觉得还不够的话,下面是为你准备的内容。
Bangumi脚本
你可以编写一个BGmi脚本来解析你自己想看的番剧或美剧。BGmi会加载你的脚本,将其视为一个番剧来处理。你所需要做的只��是继承ScriptBase类,然后实现特定的方法,再将你的脚本文件放到BGMI_PATH/script文件夹内。
get_download_url()返回一个dict,以对应集数为键,对应的下载链接为值
{ 1: 'http://example.com/Bangumi/1/1.mp4', 2: 'http://example.com/Bangumi/1/2.torrent', 3: 'http://example.com/Bangumi/1/3.mp4' }
下载钩子
你可以在下载完成前或下载完成后执行一些操作,比如移动文件、重命名文件等。将你的钩子文件放到BGMI_PATH/hooks文件夹内即可。
from loguru import logger from bgmi.script import HookBase # 只需要继承HookBase类,实现里面的方法即可,类名可任意设置 class Hook(HookBase): # 在添加了下载任务之后执行 def post_add_download(self) -> None: logger.info('post add download') # 在更新了状态,下载之前执行 def pre_add_download(self) -> None: logger.info('pre add download')
BGmi数据源
通过扩展bgmi.website.base.BaseWebsite类并实现对应的三个方法,你也可以简单地添加一个数据源
每个方法具体的含义和返回值格式请参照每个方法对应的注释
from typing import List, Optional from bgmi.website.base import BaseWebsite from bgmi.website.model import Episode, WebsiteBangumi class DataSource(BaseWebsite): def search_by_keyword( self, keyword: str, count: int ) -> List[Episode]: # pragma: no cover """ :param keyword: 搜索关键词 :param count: 从网站获取多少页 :return: 集数搜索结果列表 """ raise NotImplementedError def fetch_bangumi_calendar(self,) -> List[WebsiteBangumi]: # pragma: no cover """ 返回所有番剧列表和所有字幕组列表 番剧字典列表: 更新时间应为['Sun', 'Mon', 'Tue', 'Wed', 'Thu', 'Fri', 'Sat', 'Unknown']中的一个 """ raise NotImplementedError def fetch_episode_of_bangumi( self, bangumi_id: str, max_page: int, subtitle_list: Optional[List[str]] = None ) -> List[Episode]: # pragma: no cover """ 通过番剧ID获取所有集数 :param bangumi_id: 番剧ID :param subtitle_list: 字幕组列表 :type subtitle_list: list :param max_page: 如果没有字幕组列表,你想爬取多少页 :type max_page: int :return: 番剧列表 """ raise NotImplementedError def fetch_single_bangumi(self, bangumi_id: str) -> WebsiteBangumi: """ 在更新时获取番剧信息 :param bangumi_id: 番剧ID,或bangumi['keyword'] :type bangumi_id: str :rtype: WebsiteBangumi """ # 如果网站没有包含集数和信息的页面,则返回WebsiteBangumi(keyword=bangumi_id)
许可证
编辑推荐精选


扣子-AI办公
职场AI,就用扣子
AI办公助手,复杂任务高效处理。办公效率低?扣子空间AI助手支持播客生成、PPT制作、网页开发及报告写作,覆盖科研、商业、舆情等领域的专家Agent 7x24小时响应,生活工作无缝切换,提升50%效率!


堆友
多风格AI绘画神器
堆友平台由阿里巴巴设计团队创建,作为一款AI驱动的设计工具,专为设计师提供一站式增长服务。功能覆盖海量3D素材、AI绘画、实时渲染以及专业抠图,显著提升设计品质和效率。平台不仅提供工具,还是一个促进创意交流和个人发展的空间,界面友好,适合所有级别的设计师和创意工作者。


码上飞
零代码AI应用开发平台
零代码AI应用开发平台,用户只需一句话简单描述需求,AI能自动生成小程序、APP或H5网页应用,无需编写代码。


Vora
免费创建高清无水印Sora视频
Vora是一个免费创建高清无水印Sora视频的AI工具


Refly.AI
最适合小白的AI自动化工作流平台
无需编码,轻松生成可复用、可变现的AI自动化工作流


酷表ChatExcel
大模型驱动的Excel数据处理工具
基于大模型交互的表格处理系统,允许用户通过对话方式完成数据整理和可视化分析。系统采用机器学习算法解析用户指令,自动执行排序、公式计算和数据透视等操作,支持多种文件格式导入导出。数据处理响应速度保持在0.8秒以内,支持超过100万行数据的即时分析。


TRAE编程
AI辅助编程,代码自动修复
Trae是一种自适应的集成开发环境(IDE),通过自动化和多元协作改变开发流程。利用Trae,团队能够更快速、精确地编写和部署代码,从而提高编程效率和项目交付速度。Trae具备上下文感知和代码自动完成功能,是提升开发效率的理想工具。


AIWritePaper论文写作
AI论文写作指导平台
AIWritePaper论文写作是一站式AI论文写作辅助工具,简化了选题、文献检索至论文撰写的整个过程。通过简单设定,平台可快速生成高质量论文大纲和全文,配合图表、参考文献等一应俱全,同时提供开题报告和答辩PPT等增值服务,保障数据安全,有效提升写作效率和论文质量。


博思AIPPT
AI一键生成PPT,就用博思AIPPT!
博思AIPPT,新一代的AI生成PPT平台,支持智能生成PPT、AI美化PPT、文本&链接生成PPT、导入Word/PDF/Markdown文档生成PPT等,内置海量精美PPT模板,涵盖商务、教育、科技等不同风格,同时针对每个页面提供多种版式,一键自适应切换,完美适配各种办公场景。


潮�际好麦
AI赋能电商视觉革命,一站式智能商拍平台
潮际好麦深耕服装行业,是国内AI试衣效果最好的软件。使用先进AIGC能力为电商卖家批量提供优质的、低成本的商拍图。合作品牌有Shein、Lazada、安踏、百丽等65个国内外头部品牌,以及国内10万+淘宝、天猫、京东等主流平台的品牌商家,为卖家节省将近85%的出图成本,提升约3倍出图效率,让品牌能够快速上架。
推荐工具精选




AI云服务特惠
懂AI专属折扣关注微信公众号
最新AI工具、AI资讯
独家AI资源、AI项目落地

微信扫一扫关注公众号