



Donate a beverage to help me to keep Seq2SeqSharp up to date :) 
![]()
Seq2SeqSharp
Seq2SeqSharp is a tensor based fast & flexible deep neural network framework written by .NET (C#). It can be used for sequence-to-sequence task, sequence-labeling task, sequence-classification task and others for text and images. Seq2SeqSharp supports both CPUs and GPUs and is able to run cross-platforms, such as Windows and Linux (x86, x64 and ARM) without any modification and recompilation.
Features
Pure C# framework
Transformer encoder and decoder with pointer generator
Vision Transformer encoder for images
GPTDecoder
Attention based LSTM decoder with coverage model
Bi-directional LSTM encoder
Support multi-platforms, such as Windows, Linux, MacOS and others
Support multi-architecture, such as X86, X64 and ARM
Built-in several networks for sequence-to-sequence, sequence-classification, labeling and similarity tasks
Mixture of Experts network that could easily train huge model with less computing cost
Support Automatic Mixed Precesion (FP16)
Built-in SentencePiece supported
Rotary Positional Embeddings
Layer Norm and RMS Norm
Python package supported
Tags embeddings mechanism
Prompted Decoders
Include console tools and web apis for built-in networks
Graph based neural network
Automatic differentiation
Tensor based operations
Running on both CPUs (Supported by Intel MKL) and multi-GPUs (CUDA)
Optimized CUDA memory management for higher performance
Different Text Generation Strategy: ArgMax, Beam Search, Top-P Sampling
RMSProp and Adam optmization
Embedding & Pre-trained model
Built-in metrics and extendable, such as BLEU, Length ratio, F1 score and so on
Attention alignment generation between source side and target side
ProtoBuf serialized model
Visualize neural network
Architecture
Here is the architecture of Seq2SeqSharp
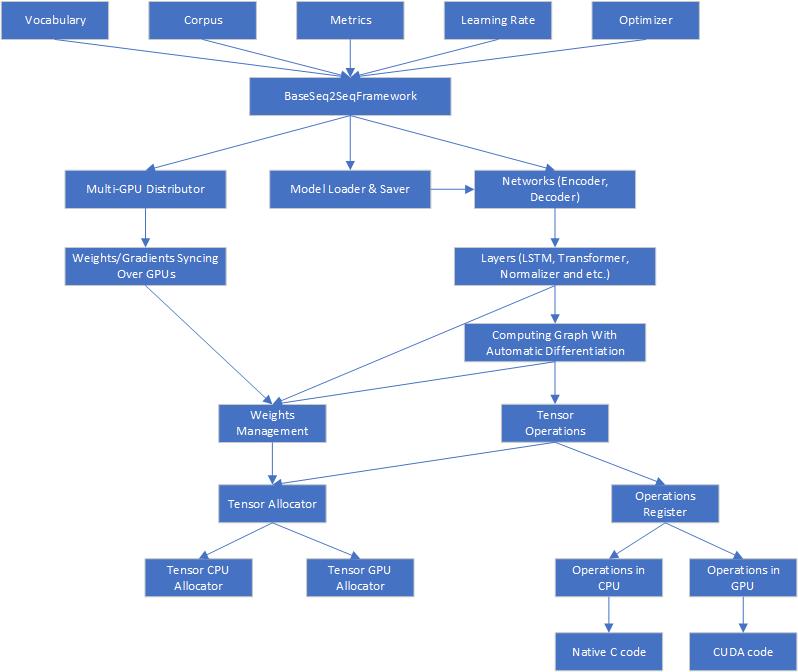
Seq2SeqSharp provides the unified tensor operations, which means all tensor operations running on CPUs and GPUs are completely same and they can get switched on different device types without any modification.
Seq2SeqSharp is also a framework that neural networks can run on multi-GPUs in parallel. It can automatically distribute/sync weights/gradients over devices, manage resources and models and so on, so developers are able to totally focus on how to design and implment networks for their tasks.
Seq2SeqSharp is built by (.NET core)[https://docs.microsoft.com/en-us/dotnet/core/], so it can run on both Windows and Linux without any modification and recompilation.
Usage
Seq2SeqSharp provides some command line tools that you can run for different types of tasks.
| Name | Comments |
|---|---|
| Seq2SeqConsole | Used for sequence-to-sequence tasks, such as machine translation, automatic summarization and so on |
| SeqClassificationConsole | Used for sequence classification tasks, such as intention detection. It supports multi-tasks, which means a single model can be trained or tested by multi-classification tasks |
| SeqLabelConsole | Used for sequence labeling tasks, such as named entity recongizer, postag and other |
| GPTConsole | Used to train and test GPT type models. It can be used for any text generation tasks. |
It also provides web service APIs for above tasks.
| Name | Comments |
|---|---|
| SeqWebAPIs | Web Service RESTful APIs for many kinds of sequence tasks. It hosts models trained by Seq2SeqSharp and infer online. |
| SeqWebApps | Web application for sequence-to-sequence or GPT models. |
Seq2SeqConsole for sequence-to-sequence task
Here is the graph that what the model looks like:
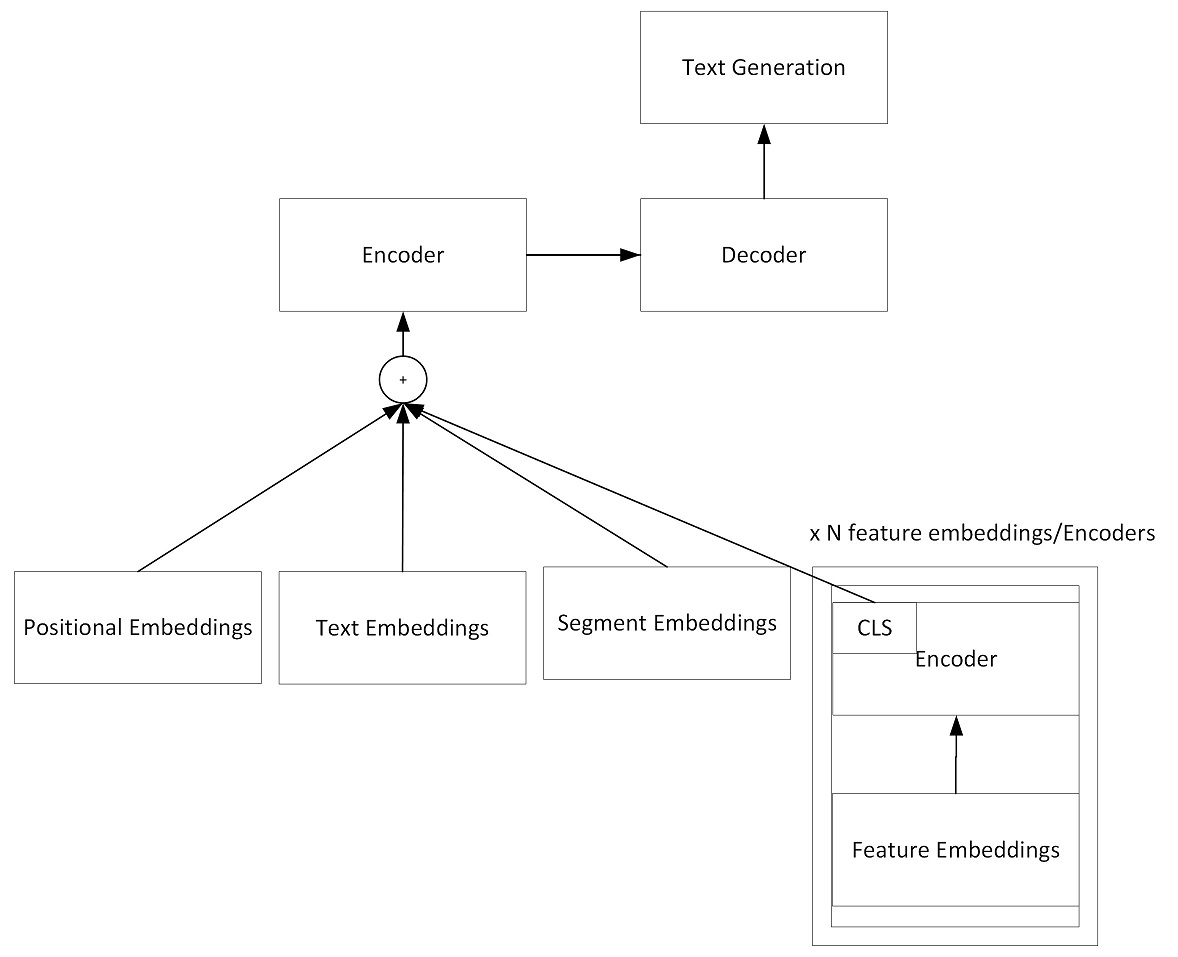
You can use Seq2SeqConsole tool to train, test and visualize models.
Here is the command line to train a model:
Seq2SeqConsole.exe -Task Train [parameters...]
Parameters:
-SrcEmbeddingDim: The embedding dim of source side. Default is 128
-TgtEmbeddingDim: The embedding dim of target side. Default is 128
-HiddenSize: The hidden layer dim of encoder and decoder. Default is 128
-LearningRate: Learning rate. Default is 0.001
-EncoderLayerDepth: The network depth in encoder. The default depth is 1.
-DecoderLayerDepth: The network depth in decoder. The default depth is 1.
-EncoderType: The type of encoder. It supports BiLSTM and Transformer.
-DecoderType: The type of decoder. It supports AttentionLSTM and Transformer.
-MultiHeadNum: The number of multi-heads in Transformer encoder and decoder.
-ModelFilePath: The model file path for training and testing.
-SrcVocab: The vocabulary file path for source side.
-TgtVocab: The vocabulary file path for target side.
-SrcLang: Source language name.
-TgtLang: Target language name.
-TrainCorpusPath: training corpus folder path
-ValidCorpusPath: valid corpus folder path
-GradClip: The clip gradients.
-BatchSize: Batch size for training. Default is 1.
-ValBatchSize: Batch size for testing. Default is 1.
-ExpertNum: The number of experts in MoE (Mixture of Expert) model. Default is 1.
-Dropout: Dropout ratio. Defaul is 0.1
-ProcessorType: Processor type: CPU or GPU(Cuda)
-DeviceIds: Device ids for training in GPU mode. Default is 0. For multi devices, ids are split by comma, for example: 0,1,2
-TaskParallelism: The max degress of parallelism in task. Default is 1
-MaxEpochNum: Maxmium epoch number during training. Default is 100
-MaxSrcSentLength: Maxmium source sentence length on training and test set. Default is 110 tokens
-MaxTgtSentLength: Maxmium target sentence length on training and test set. Default is 110 tokens
-MaxValidSrcSentLength: Maxmium source sentence length on valid set. Default is 110 tokens
-MaxValidTgtSentLength: Maxmium target sentence length on valid set. Default is 110 tokens
-WarmUpSteps: The number of steps for warming up. Default is 8,000
-EnableTagEmbeddings: Enable tag embeddings in encoder. The tag embeddings will be added to token embeddings. Default is false
-CompilerOptions: The options for CUDA NVRTC compiler. Options are split by space. For example: "--use_fast_math --gpu-architecture=compute_60" means to use fast math libs and run on Pascal and above GPUs
-Optimizer: The weights optimizer during training. It supports Adam and RMSProp. Adam is default
-CompilerOptions: The NVRTC compiler options for GPUs. --include-path is required to point to CUDA SDK include path.
Note that if "-SrcVocab" and "-TgtVocab" are empty, vocabulary will be built from training corpus.
Example: Seq2SeqConsole.exe -Task Train -SrcEmbeddingDim 512 -TgtEmbeddingDim 512 -HiddenSize 512 -LearningRate 0.002 -ModelFilePath seq2seq.model -TrainCorpusPath .\corpus -ValidCorpusPath .\corpus_valid -SrcLang ENU -TgtLang CHS -BatchSize 256 -ProcessorType GPU -EncoderType Transformer -EncoderLayerDepth 6 -DecoderLayerDepth 2 -MultiHeadNum 8 -DeviceIds 0,1,2,3,4,5,6,7
During training, the iteration information will be printed out and logged as follows:
info,9/26/2019 3:38:24 PM Update = '15600' Epoch = '0' LR = '0.002000', Current Cost = '2.817434', Avg Cost = '3.551963', SentInTotal = '31948800', SentPerMin = '52153.52', WordPerSec = '39515.27'
info,9/26/2019 3:42:28 PM Update = '15700' Epoch = '0' LR = '0.002000', Current Cost = '2.800056', Avg Cost = '3.546863', SentInTotal = '32153600', SentPerMin = '52141.86', WordPerSec = '39523.83'
Here is the command line to valid models
Seq2SeqConsole.exe -Task Valid [parameters...]
Parameters:
-ModelFilePath: The trained model file path.
-SrcLang: Source language name.
-TgtLang: Target language name.
-ValidCorpusPath: valid corpus folder path
Example: Seq2SeqConsole.exe -Task Valid -ModelFilePath seq2seq.model -SrcLang ENU -TgtLang CHS -ValidCorpusPath .\corpus_valid
Here is the command line to test models
Seq2SeqConsole.exe -Task Test [parameters...]
Parameters:
-InputTestFile: The input file for test.
-OutputFile: The test result file.
-OutputPromptFile: The prompt file for output. It is a input file along with input test file.
-OutputAlignmentsFile: The output file that contains alignments between target sequence and source sequence. It only works for pointer-generator enabled model.
-ModelFilePath: The trained model file path.
-ProcessorType: Architecture type: CPU or GPU
-DeviceIds: Device ids for training in GPU mode. Default is 0. For multi devices, ids are split by comma, for example: 0,1,2
-BeamSearchSize: Beam search size. Default is 1
-MaxSrcSentLength: Maxmium source sentence length on valid/test set. Default is 110 tokens
-MaxTgtSentLength: Maxmium target sentence length on valid/test set. Default is 110 tokens
Example: Seq2SeqConsole.exe -Task Test -ModelFilePath seq2seq.model -InputTestFile test.txt -OutputFile result.txt -ProcessorType CPU -BeamSearchSize 5 -MaxSrcSentLength 100 -MaxTgtSentLength 100
You can also keep all parameters into a json file and run Seq2SeqConsole.exe -ConfigFilePath <config_file_path> Here is an example for training.
{ "DecoderLayerDepth": 6, "DecoderStartLearningRateFactor": 1.0, "DecoderType": "Transformer", "EnableCoverageModel": false, "IsDecoderTrainable": true, "IsSrcEmbeddingTrainable": true, "IsTgtEmbeddingTrainable": true, "MaxValidSrcSentLength": 110, "MaxValidTgtSentLength": 110, "MaxSrcSentLength": 110, "MaxTgtSentLength": 110, "SeqGenerationMetric": "BLEU", "SharedEmbeddings": true, "TgtEmbeddingDim": 512, "PointerGenerator": true, "BatchSize": 64, "MaxTokenSizePerBatch": 5120, "BeamSearchSize": 1, "Beta1": 0.9, "Beta2": 0.98, "CompilerOptions": "--use_fast_math --gpu-architecture=compute_70 --include-path=<CUDA SDK Include Path>", "ConfigFilePath": "", "DecodingStrategy": "GreedySearch", "DecodingRepeatPenalty": 2.0, "DeviceIds": "0", "DropoutRatio": 0.0, "EnableSegmentEmbeddings": false, "ExpertNum": 1, "ExpertsPerTokenFactor": 1, "MaxSegmentNum": 16, "EncoderLayerDepth": 6, "SrcEmbeddingDim": 512, "EncoderStartLearningRateFactor": 1.0, "EncoderType": "Transformer", "FocalLossGamma": 0.0, "GradClip": 5.0, "HiddenSize": 512, "IntermediateSize": 2048, "IsEncoderTrainable": true, "LossType": "CrossEntropy", "MaxEpochNum": 100, "MemoryUsageRatio": 0.99, "ModelFilePath": "mt_enu_chs.model", "MultiHeadNum": 8, "NotifyEmail": "", "Optimizer": "Adam", "ProcessorType": "GPU", "MKLInstructions": "AVX2", "SrcLang": "SRC", "StartLearningRate": 0.0006, "PaddingType": "NoPadding", "Task": "Train", "TooLongSequence": "Ignore", "ActivateFunc": "SiLU", "LearningRateType": "CosineDecay", "PEType": "RoPE", "NormType": "LayerNorm", "LogVerbose": "Normal", "TgtLang": "TGT", "TrainCorpusPath": ".\\data\\train", "ValidCorpusPaths": ".\\data\\valid", "SrcVocab": null, "TgtVocab": null, "TaskParallelism": 1, "UpdateFreq": 2, "ValMaxTokenSizePerBatch": 500, "StartValidAfterUpdates": 10000, "RunValidEveryUpdates": 10000, "WarmUpSteps": 8000, "WeightsUpdateCount": 0, "SrcVocabSize": 45000, "TgtVocabSize": 45000, "EnableTagEmbeddings": false }
Data Format for Seq2SeqConsole tool
The training/valid corpus contain each sentence per line. The file name pattern is "mainfilename.{source language name}.snt" and "mainfilename.{target language name}.snt".
For example: Let's use three letters name CHS for Chinese and ENU for English in Chinese-English parallel corpus, so we could have these corpus files: train01.enu.snt, train01.chs.snt, train02.enu.snt and train02.chs.snt.
In train01.enu.snt, assume we have below two sentences:
the children huddled together for warmth .
the car business is constantly changing .
So, train01.chs.snt has the corresponding translated sentences:
孩子 们 挤 成 一 团 以 取暖 .
汽车 业 也 在 不断 地 变化 .
To apply contextual features, you can append features to the line of input text and split them by tab character.
Here is an example. Let's assume we have a translation model that can translate English to Chinese, Japanese and Korean, so given a English sentence, we need to apply a contextual feature to let the model know which language it should translate to.
In train01.enu.snt, the input will be changed to:
the children huddled together for warmth . \t CHS
the car business is constantly changing . \t CHS
But train01.cjk.snt is the same as train01.chs.snt in above.
孩子 们 挤 成 一 团 以 取暖 .
汽车 业 也 在 不断 地 变化 .
Prompt decoding
Beside decoding entire sequence from the scratch, Seq2SeqConsole also supports to decode sequence by given prompts.
Here is an example of machine translation model from English to CJK (Chinese, Japanese and Korean). This single model is able to translate sentence from English to any CJK language. The input sentence is normal English, and then you give the decoder a prompt for translation.
For example: given the input sentence "▁i ▁would ▁like ▁to ▁drink ▁with ▁you ." (Note that it has been tokenized by sentence piece model) and different prompt for decoder, the model will translate it to different languages.
| Prompt | Translated Sentence |
|---|---|
| <CHS> | <CHS> ▁我想 和你一起 喝酒 。 |
| <JPN> | <JPN> ▁ あなたと 飲み たい |
| <KOR> | <KOR> ▁나는 ▁당신과 ▁함께 ▁마시 길 ▁바랍니다 . |
GPTConsole for GPT decoder only model training and testing
GPTConsole is a command line tool for GPT style model training and testing. Given text in input file per line, the model will continue generating the rest of text.
This tool is pretty similiar to Seq2SeqConsole and most of parameters are reusable. The main difference is that GPTConsole does not have settings for source side and encoders. Its all settings are for target side and decoder only.
ImgSeqConsole is for image caption task
ImgSeqConsole is a command line tool for image caption task. Given a list of image file path, the model will generate descriptions of these images.
SeqClassification for sequence-classification task
SeqClassification is used to classify input sequence to a certain category. Given an input sequence, the tool will add a [CLS] tag at the beginning of sequence, and then send it to the encoder. At top layer
编辑推荐精选


音述AI
全球首个AI音乐社区
音述AI是全球首个AI音乐社区,致力让每个人都能用音乐表达自我。音述AI提供零门槛AI创作工具,独创GETI法则帮助用户精准定义音乐风格,AI润色功能支持自动优化作品质感。音述AI支持交流讨论、二次创作与价值变现。针对中文用户的语言习惯与文化背景进行专门优化,支持国风融合、C-pop等本土音乐标签,让技术更好地承载人文表达。


QoderWork
阿里Qoder团队推出的桌面端AI智能体
QoderWork 是阿里推出的本地优先桌面 AI 智能体,适配 macOS14+/Windows10+,以自然语言交互实现文件管理、��数据分析、AI 视觉生成、浏览器自动化等办公任务,自主拆解执行复杂工作流,数据本地运行零上传,技能市场可无限扩展,是高效的 Agentic 生产力办公助手。


lynote.ai
一站式搞定所有学习需求
不再被海量信息淹没,开始真正理解知识。Lynote 可摘要 YouTube 视频、PDF、文章等内容。即时创建笔记,检测 AI 内容并下载资料,将您的学习效率提升 10 倍。


AniShort
为AI短剧协作而生
专为AI短剧协作而生的AniShort正式发布,深度重构AI短剧全流程生产模式,整合创意策划、制作执行、实时协作、在线审片、资产复用等全链路功能,独创无限画布、双轨并行工业化工作流与Ani智能体助手,集成多款主流AI大模型,破解素材零散、版本混乱、沟通低效等行业痛点,助力3人团队效率提升800%,打造标准化、可追溯的AI短剧量产体系,是AI短剧团队协同创作、提升制作效率的核心工具。


seedancetwo2.0
能听懂你表达的视频模型
Seedance two是基于seedance2.0的中国大模型,支持图像、视频、音频、文本四种模态输入,表达方式更丰富,生成也更可控。


nano-banana纳米香蕉中文站
国内直接访问,限时3折
输入简单文字,生成想要的图片,纳米香蕉中文站基于 Google 模型的 AI 图片生成网站,支持文字生图、图生图。官网价格限时3折活动


扣子-AI办公
职场AI,就用扣子
AI办公助手,复杂任务高效处理。办公效率低?扣子空间AI助手支持播客生成、PPT制作、网页开发及报告写作,覆盖科研、商业、舆情等领域的专家Agent 7x24小时响应,生活工作无缝切换,提升50%效率!


堆友
多风格AI绘画神器
堆友平台由阿里巴巴设计团队创建,作为一款AI驱动的设计工具,专为设计师提供一站式增长服务。功能覆盖海量3D素材、AI绘画、实时渲染以及专业抠图,显著提升设计品质和效率。平台不仅提供工具,还是一个促进创意交流和个人发展的空间,界面友好,适合所有级别的设计师和创意工作者。


码上飞
零代码AI应用开发平台
零代码AI应用开发平台,用户只需一句话简单描述需求,AI能自动生成小程序、APP或H5网页应用,无需编写代码。


Vora
免费创建高清无水印Sora视频
Vora是一个免费创建高清无水印Sora视频的AI工具
推荐工具精选





AI云服务特惠
懂AI专属折扣关注微信公众号
最新AI工具、AI资讯
独家AI资源、AI项目落地

微信扫一扫关注公众号