



递归泛化 Transformer 用于图像超分辨率
Zheng Chen、Yulun Zhang、Jinjin Gu、Linghe Kong和Xiaokang Yang,"用于图像超分辨率的递归泛化 Transformer",ICLR,2024
[论文] [arXiv] [补充材料] [可视化结果] [预训练模型]
🔥🔥🔥 新闻
- 2024-02-04: 代码和预训练模型已发布。🎊🎊🎊
- 2023-09-29: 本仓库已发布。
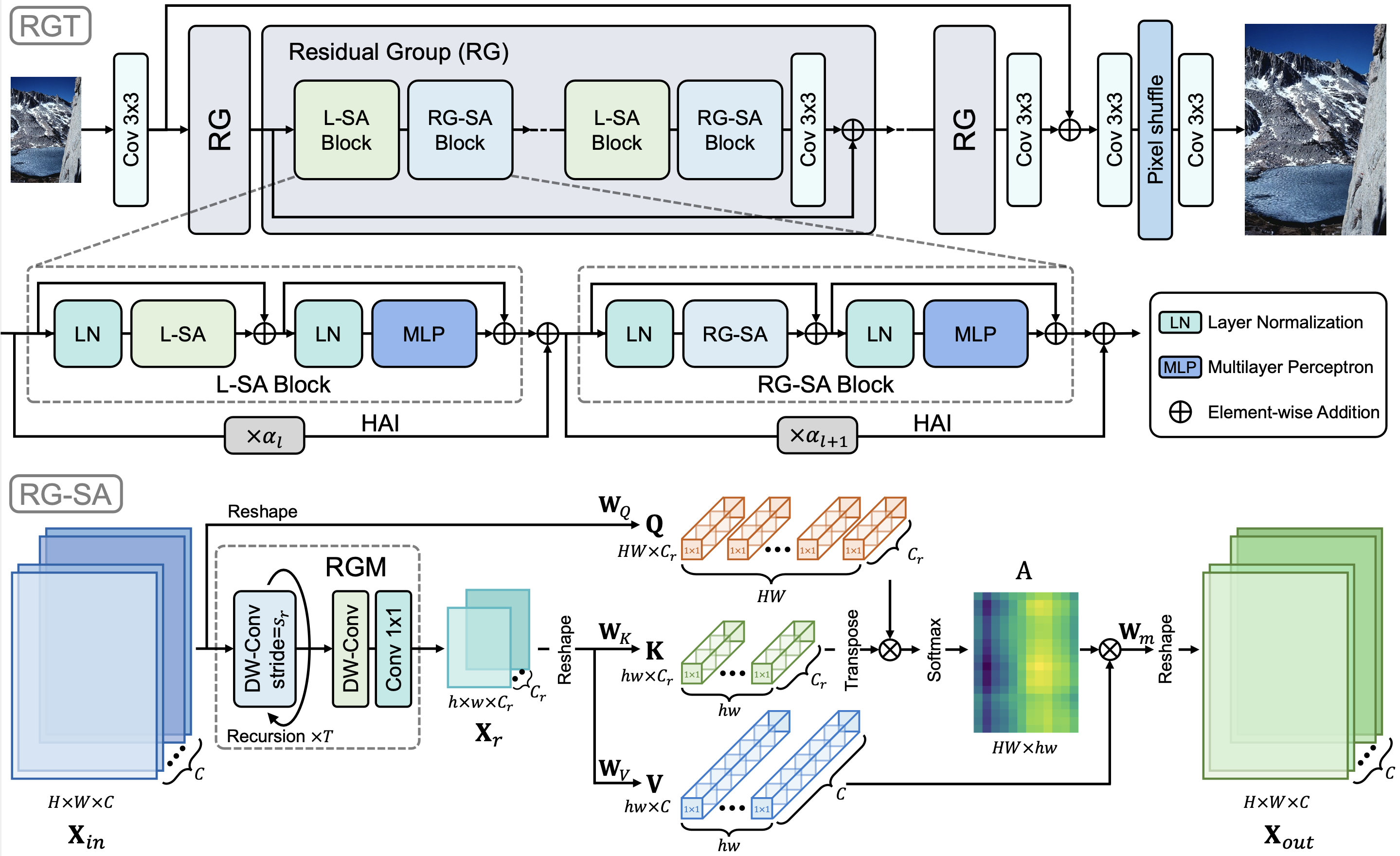
摘要: Transformer 架构在图像超分辨率(SR)任务中表现出了卓越的性能。由于 Transformer 中自注意力(SA)的二次计算复杂度,现有方法倾向于在局部区域采用 SA 以减少开销。然而,局部设计限制了全局上下文的利用,而这对于准确的图像重建至关重要。在本工作中,我们提出了用于图像 SR 的递归泛化 Transformer (RGT),它可以捕获全局空间信息并适用于高分辨率图像。具体来说,我们提出了递归泛化自注意力(RG-SA)。它递归地将输入特征聚合成具有代表性的特征图,然后利用交叉注意力提取全局信息。同时,注意力矩阵($query$、$key$ 和 $value$)的通道维度进一步缩放以减少通道域中的冗余。此外,我们将 RG-SA 与局部自注意力相结合以增强全局上下文的利用,并提出了混合自适应集�成(HAI)用于模块集成。HAI 允许不同层级(局部或全局)特征之间的直接有效融合。大量实验表明,我们的 RGT 在定量和定性方面都优于最近的最先进方法。
| HR | LR | SwinIR | CAT | RGT (ours) |
|---|---|---|---|---|
| <img src="https://yellow-cdn.veclightyear.com/835a84d5/9d5c7d1f-42df-47b9-9758-8a01fc1d564f.png" height=80> | <img src="https://yellow-cdn.veclightyear.com/835a84d5/f8594954-7520-4d05-a9f9-7eb3d0d464d0.png" height=80> | <img src="https://yellow-cdn.veclightyear.com/835a84d5/41fa2589-2c8c-40ea-93de-5df3a9ede165.png" height=80> | <img src="https://yellow-cdn.veclightyear.com/835a84d5/caff6cc6-f842-4d69-8254-18ec4729f565.png" height=80> | <img src="https://yellow-cdn.veclightyear.com/835a84d5/e6289a42-4e16-43fc-b4cf-74d4f6ccbbdc.png" height=80> |
| <img src="https://yellow-cdn.veclightyear.com/835a84d5/820b95ea-e801-4e69-ae7b-d33ef5467295.png" height=80> | <img src="https://yellow-cdn.veclightyear.com/835a84d5/eefd1349-2641-4f71-9a23-3d7c1bde0547.png" height=80> | <img src="https://yellow-cdn.veclightyear.com/835a84d5/369ce38e-05e2-491f-8243-49aa91645de6.png" height=80> | <img src="https://yellow-cdn.veclightyear.com/835a84d5/d083abd2-1b5b-4806-9648-f18782688e67.png" height=80> | <img src="https://yellow-cdn.veclightyear.com/835a84d5/62971752-507c-42c5-a856-bad09f355a31.png" height=80> |
⚙️ 依赖
- Python 3.8
- PyTorch 1.9.0
- NVIDIA GPU + CUDA
# 克隆 GitHub 仓库并进入默认目录 'RGT'。 git clone https://github.com/zhengchen1999/RGT.git conda create -n RGT python=3.8 conda activate RGT pip install -r requirements.txt -f https://download.pytorch.org/whl/torch_stable.html python setup.py develop
⚒️ 待办事项
- 发布代码和预训练模型
🔗 目录
<a name="datasets"></a>🖨️ 数据集
使用的训练和测试集可以按以下方式下载:
| 训练集 | 测试集 | 可视化结果 |
|---|---|---|
| DIV2K (800张训练图像,100张验证图像) + Flickr2K (2650张图像) [完整训练数据集 DF2K:Google Drive / 百度网盘] | Set5 + Set14 + BSD100 + Urban100 + Manga109 [完整测试数据集:Google Drive / 百度网盘] | Google Drive / 百度网盘 |
下载训练和测试数据集并将它们放入 datasets/ 的相应文件夹中。有关目录结构的详细信息,请参见 datasets。
<a name="models"></a>📦 模型
| 方法 | 参数量 (M) | FLOPs (G) | PSNR (dB) | SSIM | 模型库 | 可视化结果 |
|---|---|---|---|---|---|---|
| RGT-S | 10.20 | 193.08 | 27.89 | 0.8347 | Google Drive / 百度网盘 | Google Drive / 百度网盘 |
| RGT | 13.37 | 251.07 | 27.98 | 0.8369 | Google Drive / 百度网盘 | Google Drive / 百度网盘 |
性能在 Urban100 (x4) 上报告。FLOPs 的输出尺寸为 3×512×512。
<a name="training"></a>🔧 训练
-
下载训练(DF2K,已处理)和测试(Set5、Set14、BSD100、Urban100、Manga109,已处理)数据集,将它们放在
datasets/中。 -
运行以下脚本。训练配置在
options/train/中。
# RGT-S,输入=64x64,4个GPU python -m torch.distributed.launch --nproc_per_node=4 --master_port=4321 basicsr/train.py -opt options/train/train_RGT_S_x2.yml --launcher pytorch python -m torch.distributed.launch --nproc_per_node=4 --master_port=4321 basicsr/train.py -opt options/train/train_RGT_S_x3.yml --launcher pytorch python -m torch.distributed.launch --nproc_per_node=4 --master_port=4321 basicsr/train.py -opt options/train/train_RGT_S_x4.yml --launcher pytorch # RGT,输入=64x64,4个GPU python -m torch.distributed.launch --nproc_per_node=4 --master_port=4321 basicsr/train.py -opt options/train/train_RGT_x2.yml --launcher pytorch python -m torch.distributed.launch --nproc_per_node=4 --master_port=4321 basicsr/train.py -opt options/train/train_RGT_x3.yml --launcher pytorch python -m torch.distributed.launch --nproc_per_node=4 --master_port=4321 basicsr/train.py -opt options/train/train_RGT_x4.yml --launcher pytorch
训练实验位于experiments/目录中。
🔨 测试
🌗 测试带有高分辨率图像的图片
-
下载预训练的模型并将它们放在
experiments/pretrained_models/目录中。我们提供了图像超分辨率的预训练模型:RGT-S和RGT(x2、x3、x4)。
-
下载测试(Set5、Set14、BSD100、Urban100、Manga109)数据集,将它们放在
datasets/目录中。 -
运行以下脚本。测试配置在
options/test/目录中(例如,test_RGT_x2.yml)。注1:您可以在YML文件中设置
use_chop: True(默认为False)以对图像进行分块测试。# 不使用自集成 # RGT-S,复现论文表2中的结果 python basicsr/test.py -opt options/test/test_RGT_S_x2.yml python basicsr/test.py -opt options/test/test_RGT_S_x3.yml python basicsr/test.py -opt options/test/test_RGT_S_x4.yml # RGT,复现论文表2中的结果 python basicsr/test.py -opt options/test/test_RGT_x2.yml python basicsr/test.py -opt options/test/test_RGT_x3.yml python basicsr/test.py -opt options/test/test_RGT_x4.yml -
输出结果在
results/目录中。
🌓 测试没有高分辨率图像的图片
-
下载预训练的模型并将它们放在
experiments/pretrained_models/目录中。我们提供了图像超分辨率的预训练模型:RGT-S和RGT(x2、x3、x4)。
-
将您的数据集(单个低分辨率图像)放在
datasets/single目录中。该文件夹中已包含一些测试图像。 -
运行以下脚本。测试配置在
options/test/目录中(例如,test_single_x2.yml)。注1:默认模型是RGT。您可以通过修改YML文件来使用其他模型,如RGT-S。
注2:您可以在YML文件中设置
use_chop: True(默认为False)以对图像进行分块测试。# 在您的数据集上测试 python basicsr/test.py -opt options/test/test_single_x2.yml python basicsr/test.py -opt options/test/test_single_x3.yml python basicsr/test.py -opt options/test/test_single_x4.yml -
输出结果在
results/目录中。
🔎 结果
我们达到了最先进的性能。详细结果可以在论文中找到。
📎 引用
如果您在研究或工作中发现代码有帮助,请引用以下论文。
@inproceedings{chen2024recursive,
title={Recursive Generalization Transformer for Image Super-Resolution},
author={Chen, Zheng and Zhang, Yulun and Gu, Jinjin and Kong, Linghe and Yang, Xiaokang},
booktitle={ICLR},
year={2024}
}
💡 致谢
本代码基于BasicSR构建。
编辑推荐精选


音述AI
全球首个AI音乐社区
音述AI是全球首个AI音乐社区,致力让每个人都能用音乐表达自我。音述AI提供零门槛AI创作工具,独创GETI法则帮助用户精准定义音乐风格,AI润色功能支持自动优化作品质感。音述AI支持交流讨论、二次创作与价值变现。针对中文用户的语言习惯与文化背景进行专门优化,支持国风融合、C-pop等本土音乐标签,让技术更好地承载人文表达。


QoderWork
阿里Qoder团队推出的桌面端AI智能体
QoderWork 是阿里推出的本地优先桌面 AI 智能体,适配 macOS14+/Windows10+,以自然语言交互实现文件管理、数据分析、AI 视觉生成、浏览器自动化等办公任务,自主拆解执行复杂工作流,数据本地运行零上传,技能市场可无限扩展,是高效的 Agentic 生产力办公助手。


lynote.ai
一站式搞定所有学习需求
不再被海量信息淹没,开始真正理解知识。Lynote 可摘要 YouTube 视频、PDF、文章等内容。即时创建笔记,检测 AI 内容并下载资料,将您的学习效率提升 10 倍。


AniShort
为AI短剧协作而生
专为AI短剧协作而生的AniShort正式发布,深度重构AI短剧全流程生产模式,整合创意策划、制作执行、实时协作、在线审片、资产复用等全链路功能,独创无限画布、双轨并行工业化工作流与Ani智能体助手,集成多款主流AI大模型,破解素材零散、版本混乱、沟通低效等行业痛点,助力3人团队效率提升800%,打造标��准化、可追溯的AI短剧量产体系,是AI短剧团队协同创作、提升制作效率的核心工具。


seedancetwo2.0
能听懂你表达的视频模型
Seedance two是基于seedance2.0的中国大模型,支持图像、视频、音频、文本四种模态输入,表达方式更丰富,生成也更可控。


nano-banana纳米香蕉中文站
国内直接访问,限时3折
输入简单文字,生成想要的图片,纳米香蕉中文站基于 Google 模型的 AI 图片生成网站,支持文字生图、图生图。官网价格限时3折活动


扣子-AI办公
职场AI,就用扣子
AI办公助手,复杂任务高效处理。办公效率低?扣子空间AI助手支持播客生成、PPT制作、网页开发及报告写作,覆盖科研、商业、舆情等领域的专家Agent 7x24小时响应,生活工作无缝切换,提升50%效率!


堆友
多风格AI绘画神器
堆友平台由阿里巴巴设计团队创建,作为一款AI驱动的设计工具,专为设计师提供一站式增长服务。功能覆盖海量3D素材、AI绘画、实时渲染以及专业抠图,显著提升设计品质和效率。平台不仅提供工具,还是一个促进创意交流和个人发展的空间,界面友好,适合所有级别的设计师和创意工作者。


码上飞
零代码AI应用开发平台
零代码AI应用开发平台,用户只需一句��话简单描述需求,AI能自动生成小程序、APP或H5网页应用,无需编写代码。


Vora
免费创建高清无水印Sora视频
Vora是一个免费创建高清无水印Sora视频的AI工具
推荐工具精选





AI云服务特惠
懂AI专属折扣关注微信公众号
最新AI工具、AI资讯
独家AI资源、AI项目落地

微信扫一扫关注公众号