



基于大语言模型的视频理解优秀资源 
🔥🔥🔥 基于大语言模型的视频理解:一项调查研究
唐云龙<sup>1,*</sup>, 毕静<sup>1,*</sup>, 徐思婷<sup>2,*</sup>, 宋路川<sup>1</sup>, 梁苏珊<sup>1</sup>, 王腾<sup>2,3</sup>, 张道安<sup>1</sup>, 安杰<sup>1</sup>, 林静阳<sup>1</sup>, 朱荣毅<sup>1</sup>, Ali Vosoughi<sup>1</sup>, 黄超<sup>1</sup>, 张泽良<sup>1</sup>, 刘品欣<sup>1</sup>, 冯明茜<sup>1</sup>, 郑锋<sup>2</sup>, 张建国<sup>2</sup>, 罗平<sup>3</sup>, 罗杰波<sup>1</sup>, 徐臣良<sup>1,†</sup> (*核心贡献者, †通讯作者)
<h5 align="center"> </h5><sup>1</sup>罗切斯特大学, <sup>2</sup>南方科技大学, <sup>3</sup>香港大学
📢 新闻
[2024年7月23日]
📢 我们最近更新了我们的调查研究:"基于大语言模型的视频理解:一项调查研究"!
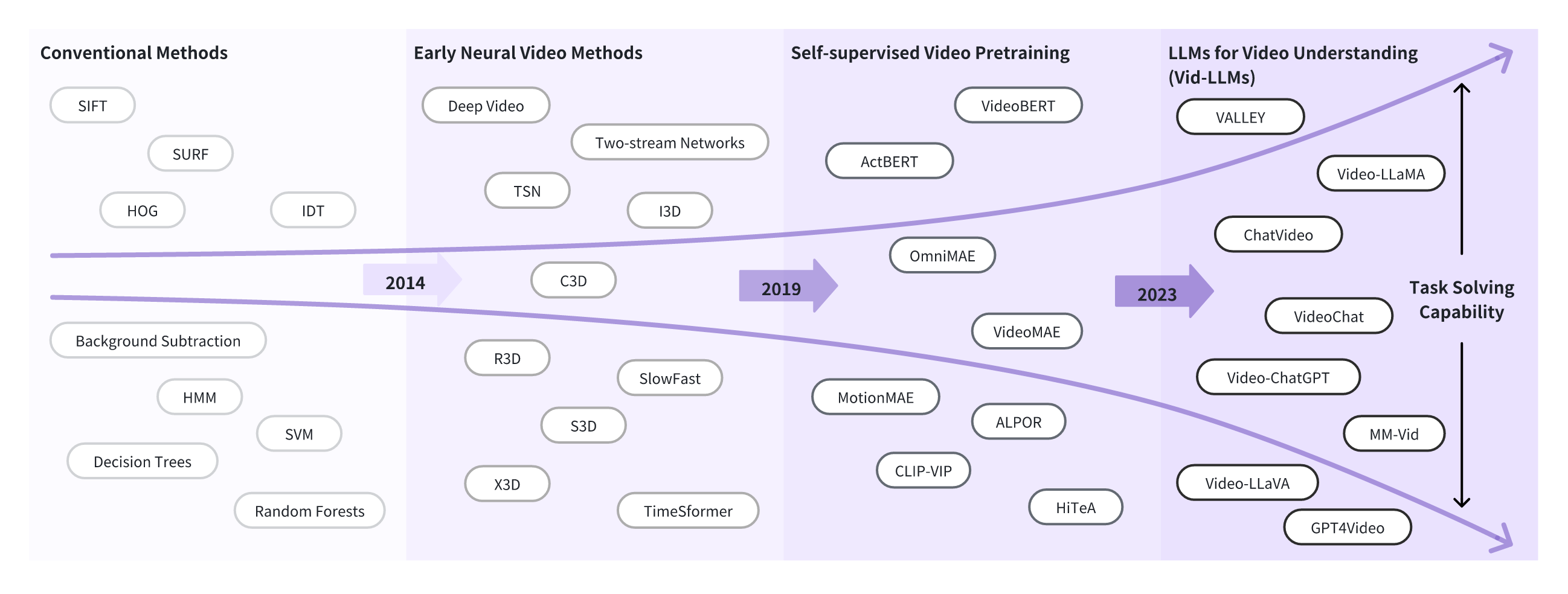
✨ 这项全面的调查涵盖了由大语言模型驱动的视频理解技术(Vid-LLMs)、训练策略、相关任务、数据集、基准测试和评估方法,并讨论了Vid-LLMs在各个领域的应用。
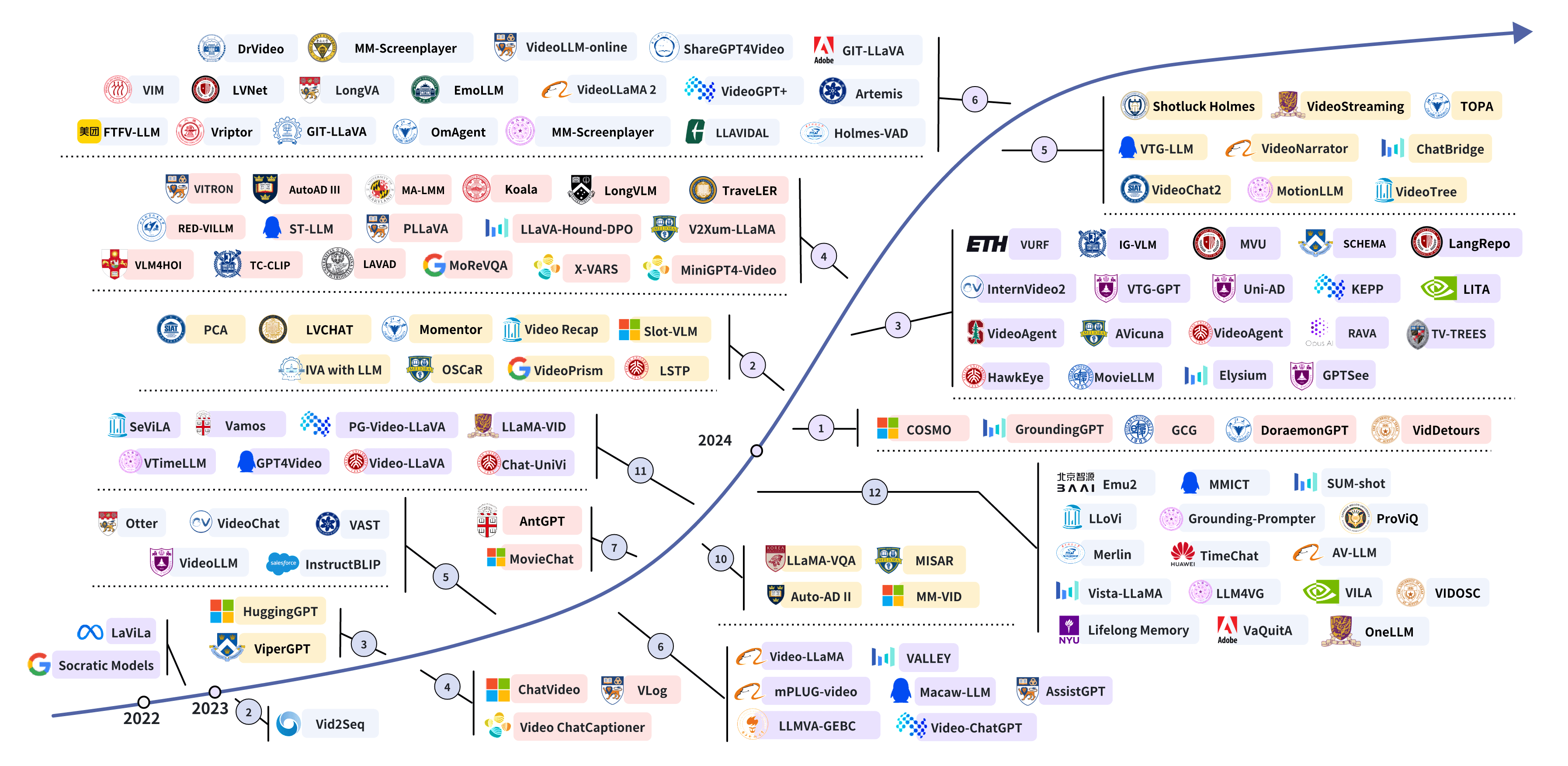
🚀 本次更新的新内容: <br>✅ 更新至2024年6月,新增约100个Vid-LLMs和15个新基准测试。 <br>✅ 根据视频表示和LLM功能引入了Vid-LLMs的新分类法。 <br>✅ 新增了初步章节,从粒度和语言参与的角度重新分类视频理解任务,并增强了LLM背景部分。 <br>✅ 新增了训练策略章节,移除了适配器作为模型分类的因素。 <br>✅ 重新设计了所有图表。
这次重大更新之后将有多次小更新。GitHub仓库也将逐步更新。欢迎阅读并提供反馈❤️
<font size=5><center><b> 目录 </b> </center></font>
为什么我们需要Vid-LLMs?

😎 Vid-LLMs:模型
📑 引用
如果您发现我们的调查研究对您的研究有帮助,请引用以下论文:
@article{vidllmsurvey, title={Video Understanding with Large Language Models: A Survey}, author={Tang, Yunlong and Bi, Jing and Xu, Siting and Song, Luchuan and Liang, Susan and Wang, Teng and Zhang, Daoan and An, Jie and Lin, Jingyang and Zhu, Rongyi and Vosoughi, Ali and Huang, Chao and Zhang, Zeliang and Zheng, Feng and Zhang, Jianguo and Luo, Ping and Luo, Jiebo and Xu, Chenliang}, journal={arXiv preprint arXiv:2312.17432}, year={2023}, }
🤖 基于LLM的视频智能体
| 标题 | 模型 | 日期 | 代码 | 会议 |
|---|---|---|---|---|
| Socratic Models: Composing Zero-Shot Multimodal Reasoning with Language | Socratic Models | 2022/04 | 项目主页 | arXiv |
Video ChatCaptioner: Towards Enriched Spatiotemporal Descriptions | Video ChatCaptioner | 2023/04 | 代码 | arXiv |
VLog: Video as a Long Document | VLog | 2023/04 | 代码 | - |
| ChatVideo: A Tracklet-centric Multimodal and Versatile Video Understanding System | ChatVideo | 2023/04 | 项目主页 | arXiv |
| MM-VID: Advancing Video Understanding with GPT-4V(ision) | MM-VID | 2023/10 | - | arXiv |
MISAR: A Multimodal Instructional System with Augmented Reality | MISAR | 2023/10 | 项目主页 | ICCV |
| Grounding-Prompter: Prompting LLM with Multimodal Information for Temporal Sentence Grounding in Long Videos | Grounding-Prompter | 2023/12 | - | arXiv |
| NaVid: Video-based VLM Plans the Next Step for Vision-and-Language Navigation | NaVid | 2024/02 | 项目主页 - | RSS |
| VideoAgent: A Memory-augmented Multimodal Agent for Video Understanding | VideoAgent | 2024/03 | 项目主页 | arXiv |
👾 Vid-LLM预训练
| 标题 | 模型 | 日期 | 代码 | 发表会议 |
|---|---|---|---|---|
从大型语言模型学习视频表示 | LaViLa | 2022年12月 | 代码 | CVPR |
| Vid2Seq:密集视频描述的视觉语言模型大规模预训练 | Vid2Seq | 2023年2月 | 代码 | CVPR |
VAST:视觉-音频-字幕-文本全模态基础模型与数据集 | VAST | 2023年5月 | 代码 | NeurIPS |
| Merlin:赋予多模态大语言模型预见性思维 | Merlin | 2023年12月 | - | arXiv |
👀 Vid-LLM 指令微调
使用连接适配器进行微调
| 标题 | 模型 | 日期 | 代码 | 发表于 |
|---|---|---|---|---|
Video-LLaMA:一个用于视频理解的指令微调视觉语言模型  | Video-LLaMA | 2023年6月 | 代码 | arXiv |
VALLEY:具有增强能力的大型语言模型视频助手 | VALLEY | 2023年6月 | 代码 | - |
Video-ChatGPT:通过大型视觉和语言模型实现详细的视频理解 | Video-ChatGPT | 2023年6月 | 代码 | arXiv |
Macaw-LLM:集成图像、音频、视频和文本的多模态语言建模 | Macaw-LLM | 2023年6月 | 代码 | arXiv |
LLMVA-GEBC:用于通用事件边界描述的大型语言模型视频适配器  | LLMVA-GEBC | 2023年6月 | 代码 | CVPR |
优酷-mPLUG:一个包含1000万规模的中文视频-语言数据集,用于预训练和基准��测试  | mPLUG-video | 2023年6月 | 代码 | arXiv |
MovieChat:从密集标记到稀疏记忆的长视频理解 | MovieChat | 2023年7月 | 代码 | arXiv |
大型语言模型是视频问答的时间和因果推理器 | LLaMA-VQA | 2023年10月 | 代码 | EMNLP |
Video-LLaVA:通过对齐再投影学习统一的视觉表示 | Video-LLaVA | 2023年11月 | 代码 | arXiv |
Chat-UniVi:统一的视觉表示为大型语言模型赋能图像和视频理解能力 | Chat-UniVi | 2023年11月 | 代码 | arXiv |
LLaMA-VID:在大型语言模型中一张图像价值2个标记 | LLaMA-VID | 2023年11月 | 代码 | arXiv |
| VISTA-LLAMA:通过视觉标记等距离实现可靠的视频叙述 | VISTA-LLAMA | 2023年12月 | - | arXiv |
| 用于视频理解的音视频大语言模型 | - | 2023年12月 | - | arXiv |
| AutoAD:上下文中的电影描述 | AutoAD | 2023年6月 | 代码 | CVPR |
| AutoAD II:续集 - 电影音频描述中的谁、何时和什么 | AutoAD II | 2023年10月 | - | ICCV |
多模态大型语言模型的细粒度音视频联合表示 | FAVOR | 2023年10月 | 代码 | arXiv |
VideoLLaMA2:提升视频-LLM中的时空建模和音频理解 | VideoLLaMA2 | 2024年6月 | 代码 | arXiv |
使用插入式适配器进行微调
| 标题 | 模型 | 日期 | 代码 | 发表平台 |
|---|---|---|---|---|
Otter: 一个具有上下文指令微调的多模态模型 | Otter | 2023年6月 | 代码 | arXiv |
VideoLLM: 用大型语言模型建模视频序列 | VideoLLM | 2023年5月 | 代码 | arXiv |
使用混合适配器进行微调
| 标题 | 模型 | 日期 | 代码 | 发表平台 |
|---|---|---|---|---|
VTimeLLM: 赋予LLM掌握视频时刻的能力 | VTimeLLM | 2023年11月 | 代码 | arXiv |
| GPT4Video: 一个统一的多模态大型语言模型,用于遵循指令的理解和安全感知生成 | GPT4Video | 2023年11月 | - | arXiv |
🦾 混合方法
| 标题 | 模型 | 日期 | 代码 | 发表平台 |
|---|---|---|---|---|
VideoChat: 以聊天为中心的视频理解 | VideoChat | 2023年5月 | 代码 演示 | arXiv |
PG-Video-LLaVA: 像素级定位的大型视频-语言模型 | PG-Video-LLaVA | 2023年11月 | 代码 | arXiv |
TimeChat: 一个时间敏感的多模态大型语言模型,用于长视频理解 | TimeChat | 2023年12月 | 代码 | CVPR |
Video-GroundingDINO: 面向开放词汇的时空视频定位 | Video-GroundingDINO | 2023年12月 | 代码 | arXiv |
| 一个视频价值4096个标记:将视频转化为词语以零样本理解它们 | Video4096 | 2023年5月 | EMNLP |
🦾 免训练方法
| 标题 | 模型 | 日期 | 代码 | 发表平台 |
|---|---|---|---|---|
| SlowFast-LLaVA: 视频��大型语言模型的强大免训练基准 | SlowFast-LLaVA | 2024年7月 | - | arXiv |
任务、数据集和基准测试
识别和预测
| 名称 | 论文 | 日期 | 链接 | 发表平台 |
|---|---|---|---|---|
| Charades | 家庭中的好莱坞:众包数据收集用于活动理解 | 2016 | 链接 | ECCV |
| YouTube8M | YouTube-8M: 一个大规模视频分类基准 | 2016 | 链接 | - |
| ActivityNet | ActivityNet: 人类活动理解的大规模视频基准 | 2015 | 链接 | CVPR |
| Kinetics-GEBC | GEB+: 通用事件边界描述、定位和检索的基准 | 2022 | 链接 | ECCV |
| Kinetics-400 | Kinetics人类动作视频数据集 | 2017 | 链接 | - |
| VidChapters-7M | VidChapters-7M: 大规模视频章节 | 2023 | 链接 | NeurIPS |
字幕和描述
| 名称 | 论文 | 日期 | 链接 | 会议 |
|---|---|---|---|---|
| 微软研究院视频描述语料库 (MSVD) | 收集高度并行的数据用于复述评估 | 2011 | 链接 | ACL |
| 微软研究院视频到文本 (MSR-VTT) | MSR-VTT:一个用于连接视频和语言的大型视频描述数据集 | 2016 | 链接 | CVPR |
| Tumblr GIF (TGIF) | TGIF:一个新的动画GIF描述数据集和基准 | 2016 | 链接 | CVPR |
| Charades | 家庭中的好莱坞:众包数据收集用于活动理解 | 2016 | 链接 | ECCV |
| Charades-Ego | 演员和观察者:第一人称和第三人称视频的联合建模 | 2018 | 链接 | CVPR |
| ActivityNet Captions | 视频中的密集事件描述 | 2017 | 链接 | ICCV |
| HowTo100m | HowTo100M:通过观看一亿个带旁白的视频片��段学习文本-视频嵌入 | 2019 | 链接 | ICCV |
| 电影音频描述 (MAD) | MAD:一个用于电影音频描述中视频语言定位的可扩展数据集 | 2021 | 链接 | CVPR |
| YouCook2 | 从网络教学视频中自动学习程序 | 2017 | 链接 | AAAI |
| MovieNet | MovieNet:一个全面的电影理解数据集 | 2020 | 链接 | ECCV |
| 优酷-mPLUG | 优酷-mPLUG:一个1000万规模的中文视频-语言预训练和基准数据集 | 2023 | 链接 | arXiv |
| 视频时间线标签 (ViTT) | 用于密集视频字幕的多模态预训练 | 2020 | 链接 | AACL-IJCNLP |
| TVSum | TVSum:使用标题对网络视频进行摘要 | 2015 | 链接 | CVPR |
| SumMe | 从用户视频创建摘要 | 2014 | 链接 | ECCV |
| VideoXum | VideoXum:视频的跨模态视觉和文本摘要 | 2023 | 链接 | IEEE Trans Multimedia |
| 多源视频字幕 (MSVC) | VideoLLaMA2:在视频-LLM中推进时空建模和音频理解 | 2024 | 链接 | arXiv |
定位和检索
| 名称 | 论文 | 日期 | 链接 | 会议 |
|---|---|---|---|---|
| Epic-Kitchens-100 | 重新调整自我中心视觉 | 2021 | 链接 | IJCV |
| VCR (视觉常识推理) | 从识别到认知:视觉常识推理 | 2019 | 链接 | CVPR |
| Ego4D-MQ 和 Ego4D-NLQ | Ego4D:环游世界3000小时的自我中心视频 | 2021 | 链接 | CVPR |
| Vid-STG | 它在哪里存在:多形式句子的时空视频定位 | 2020 | 链接 | CVPR |
| Charades-STA | TALL:��通过语言查询的时序活动定位 | 2017 | 链接 | ICCV |
| DiDeMo | 使用自然语言在视频中定位时刻 | 2017 | 链接 | ICCV |
问答
| 名称 | 论文 | 日期 | 链接 | 会议 |
|---|---|---|---|---|
| MSVD-QA | 通过逐步细化外观和动作的注意力进行视频问答 | 2017 | 链接 | ACM Multimedia |
| MSRVTT-QA | 通过逐步细化外观和动作的注意力进行视频问答 | 2017 | 链接 | ACM Multimedia |
| TGIF-QA | TGIF-QA:视觉问答中的时空推理 | 2017 | 链接 | CVPR |
| ActivityNet-QA | ActivityNet-QA:一个通过问答理解复杂网络视频的数据集 | 2019 | 链接 | AAAI |
| Pororo-QA | DeepStory:通过深度嵌入记忆网络进行视频故事问答 | 2017 | 链接 | IJCAI |
| TVQA | TVQA:局部化的组合视频问答 | 2018 | 链接 | EMNLP |
视频指令微调
预训练数据集
| 名称 | 论文 | 日期 | 链接 | 会议 |
|---|---|---|---|---|
| VidChapters-7M | VidChapters-7M:大规模视频章节数据集 | 2023 | 链接 | NeurIPS |
| VALOR-1M | VALOR:视觉-音频-语言全感知预训练模型和数据集 | 2023 | 链接 | arXiv |
| 优酷-mPLUG | 优酷-mPLUG:一个千万级中文视频-语言数据集用于预训练和基准测试 | 2023 | 链接 | arXiv |
| InternVid | InternVid:用于多模态理解和生成的大规模视频-文本数据集 | 2023 | 链接 | arXiv |
| VAST-27M | VAST:视觉-音频-字幕-文本全模态基础模型和数据集 | 2023 | 链接 | NeurIPS |
微调数据集
| 名称 | 论文 | 日期 | 链接 | 会议 |
|---|---|---|---|---|
| MIMIC-IT | MIMIC-IT:多模态上下文指令微调 | 2023 | 链接 | arXiv |
| VideoInstruct100K | Video-ChatGPT:通过大型视觉和语言模型实现详细的视频理解 | 2023 | 链接 | arXiv |
| TimeIT | TimeChat:用于长视频理解的时间敏感多模态大语言模型 | 2023 | 链接 | CVPR |
基于视频的大语言模型基准
| 标题 | 日期 | 代码 | 会议 |
|---|---|---|---|
| LVBench:一个极长视频理解基准 | 2024/06 | 代码 | - |
| Video-Bench:一个全面的基准和工具包,用于评估基于视频的大语言模型 | 2023/11 | 代码 | - |
| 感知测试:多模态视频模型的诊断基准 | 2023/05 | 代码 | NeurIPS 2023, ICCV 2023 Workshop |
| 优酷-mPLUG:一个千万级中文视频-语言数据集用于预训练和基准测试 | 2023/07 | 代码 | - |
| FETV:一个用于开放域文本到视频生成的细粒度评估基准 | 2023/11 | 代码 | NeurIPS 2023 |
| MoVQA:一个用于长篇电影理解的多功能问答基准 | 2023/12 | 代码 | - |
| MVBench:一个全面的多模态视频理解基准 | 2023/12 | 代码 | - |
| TempCompass:视频大语言模型真的理解视频吗? | 2024/03 | 代码 | ACL 2024 |
| Video-MME:首个全面评估多模态大语言模型在视频分析中表现的基准 | 2024/06 | 代码 | - |
| VideoHallucer:评估大型视频-语言模型中的内在和外在幻觉 | 2024/06 | 代码 | - |
贡献
我们欢迎每个人为这个仓库做出贡献,帮助改进它。你可以提交拉取请求来添加新的论文、项目和有用的材料,或者纠正你可能发现的任何错误。请确保你的拉取请求遵循"标题|模型|日期|代码|会议"的格式。感谢你的宝贵贡献!
🌟 星标历史
♥️ 贡献者
<a href="https://github.com/yunlong10/Awesome-LLMs-for-Video-Understanding/graphs/contributors"> <img src="https://contrib.rocks/image?repo=yunlong10/Awesome-LLMs-for-Video-Understanding" /> </a>编辑推荐精选

小云雀
字节旗下AI内容创作Agent
小云雀是字节跳动旗下剪映团队推出的AI内容创作Agent,主打”一句话打造一个爆款”的零门槛创作体验。用户只需输入一句指令,可自动生成15-60秒短视频、数字人口播视频、风格化海报等内容,支持200+可商用数字人形象和19种语言及方言。小云雀核心功能包括智能成片、AI设计、照片会说话、爆款复刻等,已接入豆包大模型、DeepSeek Chat及自研Seedance 2.0视频生成模型、Seedream 5.0图像生成模型。目前支持安卓APP和网页版,每日登录可领取120积分。适合自媒体创作者、电商营销人员、教育工作者及普通用户使用,近期因用户量激增,视频生成排队时长可达8小时。


豆包
字节跳动旗下 AI 智能助手
字节跳动旗下 AI 智能助手


Pixmax
一站式AI短剧创作平台
Pixmax专注打造下一代“ AI 视觉创作引擎”,整合行业顶尖 AI 大模型、工工业级精准控制及企业级协同管理功能,是全方位的 AI 内容创作平台。


GPT Plus|Pro充值
GPT充值
支持 ChatGPT Plus / Pro 充值服务,支付便捷,自动发货,售后可查。


GPT Image 2中文站
AI 图片生成平台
GPT Image 2 是面向用户的 AI 图片生成平台,支持文生图、图生图及多模型创意工作流。


Vecbase
你的AI Agent团队
Vecbase 是专为 AI 团队打造的智能工作空间,将数据管理、模型协作与知识沉淀整合于一处。算法、产品与业务在同一平台无缝协同,让从数据到 AI 应用的落地更快一步。


音述AI
全球首个AI音乐社区
音述AI是全球首个AI音乐社区,致力让每个人都能用音乐表达自我。音述AI提供零门槛AI创作工具,独创GETI法则帮助用户精准定义音乐风格,AI润色功能支持自动优化作品质感。音述AI支持交流讨论、二次创作与价值变现。针对中文用户的语言习惯与文化背景进行专门优化,支持国风融合、C-pop等本土音乐标签,让技术更好地承载人文表达。


QoderWork
阿里Qoder团队推出的桌面端AI智能体
QoderWork 是阿里推出的本地优先桌面 AI 智能体,适配 macOS14+/Windows10+,以自然语言交互实现文件管理、数据分析、AI 视觉生成、浏览器自动化等办公任务,自主拆解执行复杂工作流,数据本地运行零上传,技能市场可无限扩展,是高效的 Agentic 生产力办公助手。


lynote.ai
一站式搞定所有学习需求
不再被海量信息淹没,开始真正理解知识。Lynote 可摘要 YouTube 视频、PDF、文章等内容。即时创建笔记,检测 AI 内容并下载资料,将您的学习效率提升 10 倍。


AniShort
为AI短剧协作而生
专为AI短剧协作而生的AniShort正式发布,深度重构AI短剧全流程生产模式,整合创意策划、制作执行、实时协作、在线审片、资产复用等全链路功能,独创无限画布、双轨并行工业化工作流与Ani智能体助手,集成多款主流AI大模型,破解素材零散、版本混乱、沟通低效等行业痛点,助力3人团队效率提升800%,打造标准化、可追溯的AI短剧量产体系,是AI短剧团队协同创作、提升制作效率的核心工具。
推荐工具精选






AI云服务特惠
懂AI专属折扣关注微信公众号
最新AI工具、AI资讯
独家AI资源、AI项目落地

微信扫一扫关注公众号