
exllama
为现代GPU优化的快速内存高效Llama实现
ExLlama是一个基于Python/C++/CUDA的独立实现,针对4位GPTQ权重进行了优化,旨在提高现代GPU上的运行速度和内存效率。该项目支持NVIDIA 30系列及更新的GPU,可处理Llama、Koala和WizardLM等多种大型语言模型。ExLlama具备基准测试、聊天机器人示例和Web界面等功能,同时支持Docker部署。尽管仍在开发中,项目已展现出卓越的性能和效率。


ExLlama
一个独立的Python/C++/CUDA实现的Llama,用于4位GPTQ权重,旨在在现代GPU上快速且内存高效。
声明:该项目正在进行中,但仍在持续开发中!
硬件要求
我正在使用RTX 4090和RTX 3090-Ti进行开发。30系列及以后的NVIDIA GPU应该能得到很好的支持,但Pascal或更旧的GPU由于FP16支持较差,性能可能不佳。目前对于较旧的GPU,AutoGPTQ或GPTQ-for-LLaMa是更好的选择。理论上也支持ROCm(通过HIP),但我目前没有AMD设备来测试或优化。
依赖项
- Python 3.9或更新版本
torch在2.0.1和2.1.0(每夜版)cu118上测试通过safetensors0.3.2sentencepieceninja
另外,仅针对Web界面:
flaskwaitress
Linux/WSL前提条件
pip install --pre torch --index-url https://download.pytorch.org/whl/nightly/cu118
Windows前提条件
在Windows上运行(不使用WSL):
- 安装MSVC 2022。你可以选择安装完整的
Visual Studio 2022IDE,或者只安装Build Tools for Visual Studio 2022包(确保在安装程序中勾选Desktop development with C++),选择哪个并不重要。 - 安装适当版本的PyTorch,选择一个CUDA版本。我正在使用每夜构建版,但稳定版(2.0.1)也应该可以工作。
- 安装CUDA Toolkit(11.7和11.8似乎都可以使用,只需确保与PyTorch的Compute Platform版本匹配)。
- 为获得最佳性能,启用硬件加速GPU调度。
使用方法
克隆仓库,安装依赖项,并运行基准测试:
git clone https://github.com/turboderp/exllama
cd exllama
pip install -r requirements.txt
python test_benchmark_inference.py -d <模型文件路径> -p -ppl
CUDA扩展在运行时加载,因此无需单独安装。它将在首次运行时编译并缓存到~/.cache/torch_extensions/,这可能需要一点时间。如果一开始没有反应,请给它一分钟时间来编译。
聊天机器人示例:
python example_chatbot.py -d <模型文件路径> -un "Jeff" -p prompt_chatbort.txt
Python模块
jllllll目前维护着一个可安装的Python模块在这里,这可能更适合将ExLlama与其他项目集成
Web界面
我还为它制作了一个简单的Web界面。不要看JavaScript代码,它主要是由ChatGPT编写的,会让你梦魇。但它基本上可以工作,而且很有趣,尤其是多机器人模式:
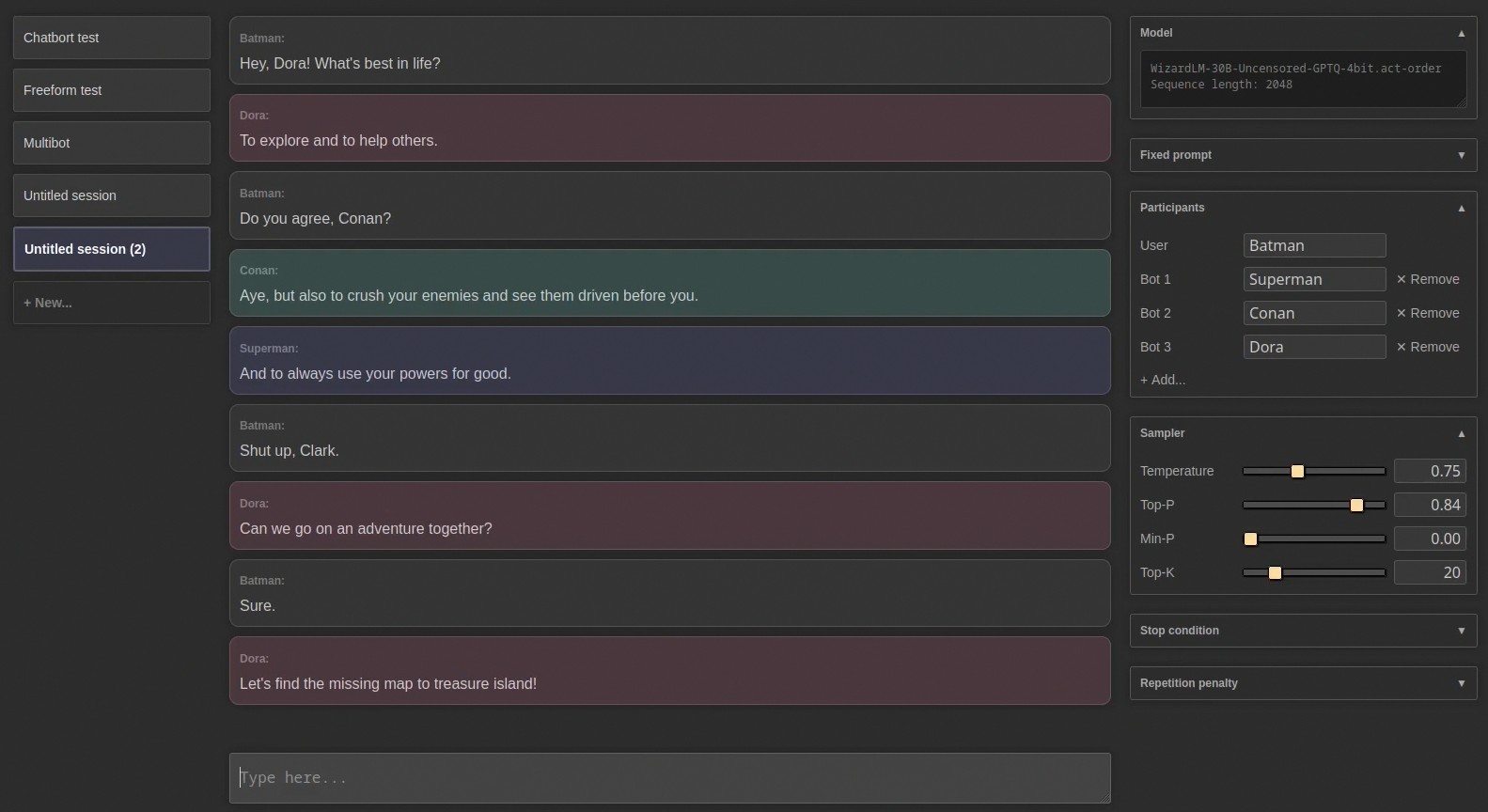
运行方法:
pip install -r requirements-web.txt
python webui/app.py -d <模型文件路径>
注意,会话默认存储在~/exllama_sessions/。如果需要,可以使用-sd更改该位置。
Docker
为了获得安全优势和更易部署,也可以在隔离的docker容器中运行Web界面。注意:docker镜像目前仅支持NVIDIA GPU。
要求
建议以无根模式运行docker。
构建
构建docker镜像最简单的方法是使用docker compose。首先,在.env文件中设置MODEL_PATH和SESSIONS_PATH变量为主机上的实际目录。然后运行:
docker compose build
也可以手动构建镜像:
docker build -t exllama-web .
注意:默认情况下,docker容器内的服务由非root用户运行。因此,在容器入口点(entrypoint.sh)中会更改绑定挂载目录(默认docker-compose.yml文件中的/data/model和/data/exllama_sessions)的所有权为这个非root用户。要禁用此功能,如果使用docker compose,请在.env文件中设置RUN_UID=0,或者如果手动构建镜像,使用以下命令:
docker build -t exllama-web --build-arg RUN_UID=0 .
运行
使用docker compose:
docker compose up
现在可以在主机上通过http://localhost:5000访问Web界面。
可以在docker-compose.yml中查看配置,并通过创建docker-compose.override.yml文件来更改配置。
手动运行:
docker run --gpus all -p 5000:5000 -v <模型目录路径>:/data/model/ -v <会话目录路径>:/data/exllama_sessions --rm -it exllama-web --host 0.0.0.0:5000
目前的结果
新实现
| 模型 | 大小 | 分组大小 | 激活 | 序列长度 | 显存 | 提示速度 | 最佳速度 | 最差速度 | 困惑度 |
|---|---|---|---|---|---|---|---|---|---|
| Llama | 7B | 128 | 否 | 2,048 词 | 5,194 MB | 13,918 词/秒 | 173 词/秒 | 140 词/秒 | 6.45 |
| Llama | 13B | 128 | 否 | 2,048 词 | 9,127 MB | 7,507 词/秒 | 102 词/秒 | 86 词/秒 | 5.60 |
| Llama | 33B | 128 | 否 | 2,048 词 | 20,795 MB | 2,959 词/秒 | 47 词/秒 | 40 词/秒 | 4.60 |
| Llama | 33B | 128 | 是 | 2,048 词 | 20,795 MB | 2,784 词/秒 | 45 词/秒 | 37 词/秒 | 4.55 |
| Llama | 33B | 32 | 是 | 1,550 词 <sup>1</sup> | 21,486 MB | 2,636 词/秒 | 41 词/秒 | 37 词/秒 | 4.52 |
| Koala | 13B | 128 | 是 | 2,048 词 | 9,127 MB | 5,529 词/秒 | 93 词/秒 | 79 词/秒 | 6.73 |
| WizardLM | 33B | - | 是 | 2,048 词 | 20,199 MB | 2,313 词/秒 | 47 词/秒 | 40 词/秒 | 5.75 |
| OpenLlama | 3B | 128 | 是 | 2,048 词 | 3,128 MB | 16,419 词/秒 | 226 词/秒 | 170 词/秒 | 7.81 |
<sup>1</sup> 无法在不耗尽内存的情况下达到完整序列长度
所有测试均在配备桌面环境的普通RTX 4090 / 12900K上进行,同时还有其他几个应用程序也在使用显存。
"提示"速度是指列出的序列长度减去128个词元的推理速度。"最差"是完整上下文最后128个词元的平均速度(最坏情况),"最佳"列出了空序列中前128个词元的速度(最佳情况)。
显存使用量是由PyTorch报告的,不包括PyTorch自身的开销(CUDA内核、内部缓冲区等)。这在某种程度上是不可预测的。最好的办法是仅优化模型的显存使用,可能的话在24 GB GPU上瞄准20 GB,以确保有足够空间容纳桌面环境和Torch的所有内部组件。
困惑度的测量仅用于验证模型是否正常工作。使用的数据集是来自WikiText的特定小样本,因此分数不能与其他Llama基准进行比较,仅用于比较不同Llama模型之间的差异。
双GPU结果
以下基准测试来自4090 + 3090-Ti,使用参数-gs 17.2,24:
| 模型 | 大小 | 分组大小 | 激活 | 序列长度 | 显存 | 提示速度 | 最佳速度 | 最差速度 | 困惑度 |
|---|---|---|---|---|---|---|---|---|---|
| Llama | 65B | 128 | 是 | 2,048 词 | 39,804 MB | 1,109 词/秒 | 20 词/秒 | 18 词/秒 | 4.20 |
| Llama | 65B | 32 | 是 | 2,048 词 | 43,424 MB | 1,037 词/秒 | 17 词/秒 | 16 词/秒 | 4.11 |
| Llama-2 | 70B | 128 | 是 | 2,048 词 | 40,680 MB | 914 词/秒 | 17 词/秒 | 14 词/秒 | 4.15 |
| Llama-2 | 70B | 32 | 是 | 2,048 词 | 36,815 MB | 874 词/秒 | 15 词/秒 | 12 词/秒 | 4.10 |
注意,由于预训练数据集不同,Llama和Llama 2之间的困惑度分数可能不完全具有可比性。
待办事项
待办事项列表已移至这里。
兼容性
这里列出了目前确认可以正常工作的模型。
最近更新
2023-01-09:添加了rope_theta参数,以支持(至少部分)CodeLlama。如果您之前使用alpha = 97或类似设置,对于CodeLlama模型,您将不再需要这样做。关于扩展词汇表仍有一些问题需要解决。
2023-08-09:添加了对分片模型的支持。config.model_path现在可以��接受文件名或文件名列表。如果给定模型目录,model_init()将检测多个.safetensors文件。注意各种示例中的变化:model_path = glob.glob(st_pattern)[0]变为简单的model_path = glob.glob(st_pattern)。此外,util/shard.py中有一个小脚本,用于拆分大型.safetensors文件。它还会为分片模型生成一个index.json文件,以保证完整性,尽管ExLlama不需要它来读取分片。请注意,safetensors依赖项已升级到0.3.2版本。
2023-08-12:初步、初始和试验性发布ExLlamaV2。它目前还不能完成ExLlamaV1的所有功能,但在已有功能上表现更好。快来看看吧!
编辑推荐精选


扣子-AI办公
职场AI,就用扣子
AI办公助手,复杂任务高效处理。办公效率低?扣子空间AI助手支持播客生成、PPT制作、网页开发及报告写作,覆盖科研、商业、舆情等领域的专家Agent 7x24小时响应,生活工作无缝切换,提升50%效率!


堆友
多风格AI绘画神器
堆友平台由阿里巴巴设计团队创建,作为一款AI驱动的设计工具,专为设计师提供一站式增长服务。功能覆盖海量3D素材、AI绘画、实时渲染以及专业抠图,显著提升设计品质和效率。平台不仅提供工具��,还是一个促进创意交流和个人发展的空间,界面友好,适合所有级别的设计师和创意工作者。


码上飞
零代码AI应用开发平台
零代码AI应用开发平台,用户只需一句话简单描述需求,AI能自动生成小程序、APP或H5网页应用,无需编写代码。


Vora
免费创建高清无水印Sora视频
Vora是一个免费创建高清无水印Sora视频的AI工具


Refly.AI
最适合小白的AI自动化工作流平台
无需编码,轻松生成可复用、可变现的AI自动化工作流


酷表ChatExcel
大模型驱动的Excel数据处理工具
基于大模型交互的表格处理系统,允许用户通过对话方式完成数据整理和可视化分析。系统采用机器学习算法解析用户指令,自动执行排序、公式计算和数据透视等操作,支持多种文件格式导入导出。数据处理响应速度保持在0.8秒以内,支持超过100万行数据的即时分析。


TRAE编程
AI辅助编程,代码自动修复
Trae是一种自适应的集成开发环境(IDE),通过自动化和多元协作改变开发流程。利用Trae,团队能够更快速、精确地编写和部署代码,从而提高编程效率和项目交付速度。Trae具备上下文感知和代码自动完成功能,是提升开发效率的理想工具。


AIWritePaper论文写作
AI论文写作指导平台
AIWritePaper论文写作是一站式AI论文写作辅助工具,简化了选题、文献检索至论文撰写的整个过程。通过简单设定,平台可快速生成高质量论文大纲和全文,配合图表、参考文献等一应俱全,同时提供开题报告和答辩PPT等增值服务,保障数据安全,有效提升写作效率和论文质量。


博思AIPPT
AI一键生成PPT,就用博思AIPPT!
博思AIPPT,新一代的AI生成PPT平台,支持智能生成PPT、AI美化PPT、文本&链接生成PPT、导入Word/PDF/Markdown文档生成PPT等,内置海量精美PPT模板,涵盖商务、教育、科技等不同风格,同时针对每个页面提供多种版式,一键自适应切换,完美适配各种办公场景。


潮际好麦
AI赋能电商视觉革命,一站式智能商拍平台
潮际好麦深耕服装行业,是国内AI试衣效果最好的软件。使用先进AIGC能力为电商卖家批量提供优质的、低成本的商拍图。合作品牌有Shein、Lazada、安踏、百丽等65个国内外头部品牌,以及国内10万+淘宝、天猫、京东等主流平台的品牌商家,为卖家节省将近85%的出图成本,提升约3倍出图效率,让品牌能够快速上架。
推荐工具精选




AI云服务特惠
懂AI专属折扣关注微信公众号
最新AI工具、AI资讯
独家AI资源、AI项目落地

微信扫一扫关注公众号