




LLM 蒸馏实践指南
Justin Zhao<sup>†</sup>, Wael Abid<sup>†</sup>
† Predibase, MLX团队
目录
本文档适合谁阅读?
本文档面向对LLM蒸馏在生产应用中感兴趣的工程师和机器学习从业者。我们假设读者已经熟悉深度学习基础知识和大型语言模型(LLM)。虽然本指南�中的建议可以适用于其他场景(如学术研究),但我们的重点是如何最有效地为生产应用蒸馏LLM。
为什么需要蒸馏实践指南?
我们接触过的几乎每个组织都已经使用LLM构建了至少一个新颖的内部应用;我们交谈过的一家大公司在一周内就构建了70个原型。
每个人都在使用大型语言模型构建原型,然而随着LLM变得越来越强大并在各种应用中不可或缺,对更高效、更小型的替代品的需求比以往任何时候都更加迫切。
这种转变源于LLM令人信服的性能,与大型模型的高昂成本、资源需求和较慢的运行速度形成鲜明对比。作为回应,将这些模型蒸馏成更高效、更小型的版本提供了一种平衡能力与成本效益和速度的解决方案。
尽管对模型蒸馏的兴趣很大,但我们发现在实践中让蒸馏模型真正发挥良好作用仍然需要令人惊讶的大量劳动和猜测。轶事和建议片段分散在arxiv、huggingface、discord、substack和社交媒体上,但这些建议的系统化和集中化仍有待实现。
本文档中的建议源自我们在Google和Predibase蒸馏语言模型的经验,结合了我们能找到的任何有关该主题的SLM/LLM研究。我们希望这些高效改进LLM的策略能为从业者和爱好者提供实用、以学术研究为基础的想法,有助于开源语言模型的不断发展和使用。
这是一份动态文档。我们预计会定期进行大小改进。如果您想收到通知,请关注我们的仓库(参见说明)。
对开源的承诺
在Predibase,我们相信未来是经过微调的、专门化的和开源的LLM。开源是公司的DNA。作为一家公��司,我们维护:
<details><summary><em>[关于Predibase的更多信息]</em></summary>Predibase是建立在开源基础上的托管平台。如果您对用于微调和部署LM的托管解决方案感兴趣,可以在这里注册免费试用。
</details>核心概念
在深入探讨大型语言模型(LLM)蒸馏的最佳实践之前,让我们定义模型蒸馏及其应用中常用的术语。
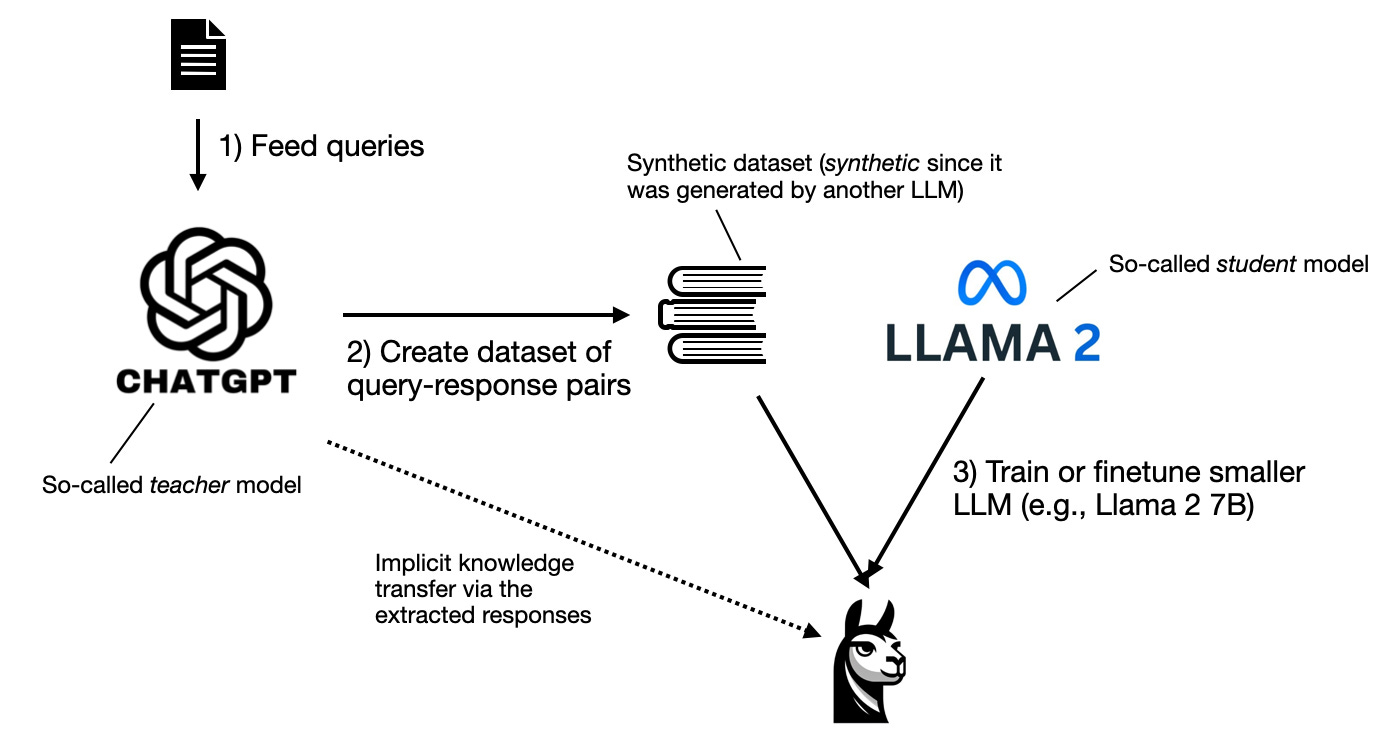
模型蒸馏能够在不显著损失性能的情况下,将大型语言模型精炼和压缩成更易管理、更具成本效益的版本。
大型语言模型(LLM):在海量文本数据上训练的先进AI模型(参见完整列表)。它们似乎对语言有深刻的理解,可以被训练来遵循指令或执行其他涉及文本的任务。
教师模型:我们旨在将知识转移到较小模型的更强大的大型模型。
学生模型:教师模型被蒸馏成的较小模型。
最佳实践
1. 了解小型模型的局限性。
总结:模型蒸馏是一门实证科学,并不能保证在所有情况下都能很好地工作。模型蒸馏的有效性取决于任务和数据。
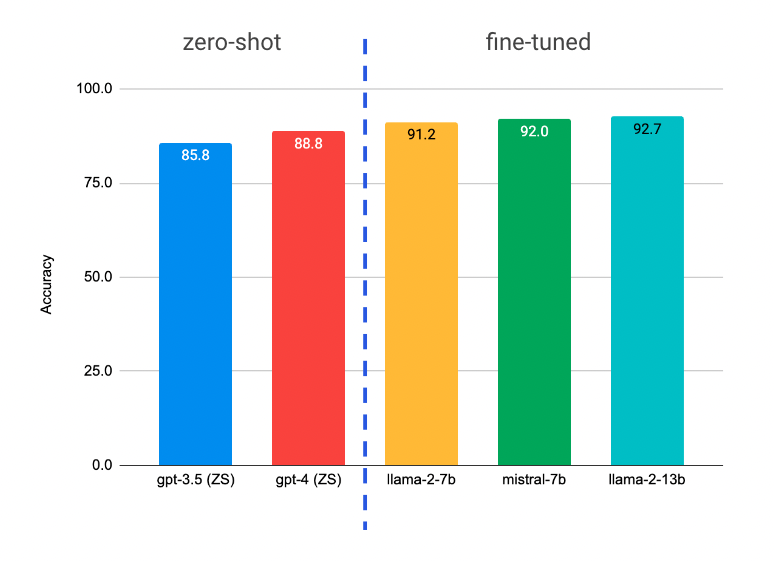
有大量且不断增加的证据表明,当在黄金标签上进行微调时,较小的模型在零样本和少样本任务上的表现优于GPT-4(1, 2)。然而,由于规模有限,较小的模型可能无法像larger counterparts那样有效地捕捉语言的全部深度和细微差别。
在经典的模型蒸馏设置中,学生模型是在教师模型的原始输出上训练的(也称为模仿学习),学生模型通常最多只能达到教师模型的质量。
在《模仿专有LLM的虚假承诺》研究中,研究人员发现,对于某些任务,较小的学生模型会欺骗性地学会模仿教师的风格,但在事实正确性方面却不及教师。
<p align="center" > <img src="https://yellow-cdn.veclightyear.com/835a84d5/0e8ee302-d40e-4aad-9139-3e140435e134.png" /> <p align="center" ><i>NLP任务谱。领域越广泛、所需精度越高,问题就越困难,蒸馏"简单奏效"的可能性就越小。</i></p> </p>事实上,模型蒸馏的有效性在很大程度上取决于具体的任务和数据。对于涉及更广泛领域或需要大量推理能力的任务,学生模型可能比预训练的larger teachers处于更不利的地位。相反,对于简单明确的任务,开箱即用的模仿学习可能完全足以获得有竞争力的学生模型。
<details><summary><em>[案例研究:Jigsaw有毒评论分类]</em></summary>为了展示和contextualize我们将在本文后续章节探讨的LLM蒸馏最佳实践,我们使用了Jigsaw有毒评论分类数据集。 Jigsaw数据集是为了训练模型对具有攻击性的评论进行分类而创建的。它包含16万条来自互联网的真实评论,其中既有具有攻击性的例子,也有非攻击性的例子。
原始数据集对每条评论都有细粒度的标签:toxic、severe_toxic、obscene、threat、insult和identity_hate。我们将所有列合并为一个is_bad列,以获得一个二元分类数据集。1
2. 建立良好的日志记录基础设施
摘要:为生产环境中的LLM建立基本的日志记录基础设施。如果由于流量低、涉及个人隐私信息或其他限制导致日志有限,合成数据生成可能是引导微调数据集的可行选择。
如果你还没有在应用程序中实施日志记录,你真的应该这样做。token很昂贵,而且数据就是石油。
<p align="center" > <img src="https://yellow-cdn.veclightyear.com/835a84d5/25399107-f6ba-43dd-9a4f-1fb0b44119d9.png" /> <p align="center" ><i>使用模型即服务(MaaS)无服务器教师模型的基本日志记录基础设施示例。将请求和响应从MaaS端点流式传输到Amazon S3或Snowflake等存储解决方案。</i></p> </p>使用真实日志引导数据集
收集发送到教师模型的生产流量日志是引导微调数据集的一个很好的精简选择。2
在这里可以看到在streamlit应用中异步记录请求和响应到S3的轻量级示例。
使用合成数据引导数据集
对于由于低流量、涉及个人隐私信息或其他限制而数据有限的应用程序,合成数据生成可能是微调数据的可行选择。
<p align="center"> <img src="https://yellow-cdn.veclightyear.com/835a84d5/fb97288a-8f68-4617-854c-921589ae79b7.png"> <p align="center" ><i>使用合成数据引导你的数据集。合成数据最大的挑战是确保生成的示例是多样化和非重复的。</i></p> </p>像Self-Instruct、Alpacare或微软的phi-1/phi-1.5/phi-2等论文展示了如何通过对GPT模型的种子查询进行创造性变化来生成合成数据集,并用于微调令人信服的小型模型。
"我们推测,在不久的将来,创建合成数据集将成为一项重要的技术技能和AI研究的核心主题。" ~ phi 1.5技术报告
3. 定义明确的评估标准
摘要:对蒸馏模型进行有效评估需要明确定义符合你特定应用需求的标准。评估指标的选择应反映问题�的性质和模型的预期结果。
这是机器学习中众所周知的最佳实践,但由于它非常重要,所以值得重申。
根据应用定制评估:有效的评估需要明确定义符合你特定应用需求的标准。例如,用于JSON生成任务的LLM可能会关注模式adherence检查,提取任务可能会关注准确率或召回率,而其他语言生成任务可能会使用BLEURT、ROUGE或困惑度。关键是选择最能代表模型在其预期环境中成功的指标。
LLM作为评判者的兴起:越来越多地使用LLM自身来评估模型输出,特别是在传统指标可能不足或人工评估成本太高的情况下。这种方法可能很有吸引力,但需要仔细考虑以考虑到潜在的LLM偏见。
测试集的一致性和多样性:建立明确的测试集至关重要。这些集合应该足够多样化,以涵盖模型性能的各个方面,同时又足够一致,以允许随时间可靠地跟踪。避免频繁更改测试集,因为在比较不同模型和迭代的性能时,一致性是关键。
<details><summary><em>[案例研究:Jigsaw有毒评论分类]</em></summary>从Jigsaw数据集中随机抽样测试集,得到的数据集分布为:90%非有毒,10%有毒。
虽然这种分布可能符合我们假设的应用程序接收到的分布(主要是非有毒评论),但我们希望确保我们投入生产的任何模型在检测有毒和非有毒评论方面都同样出色。
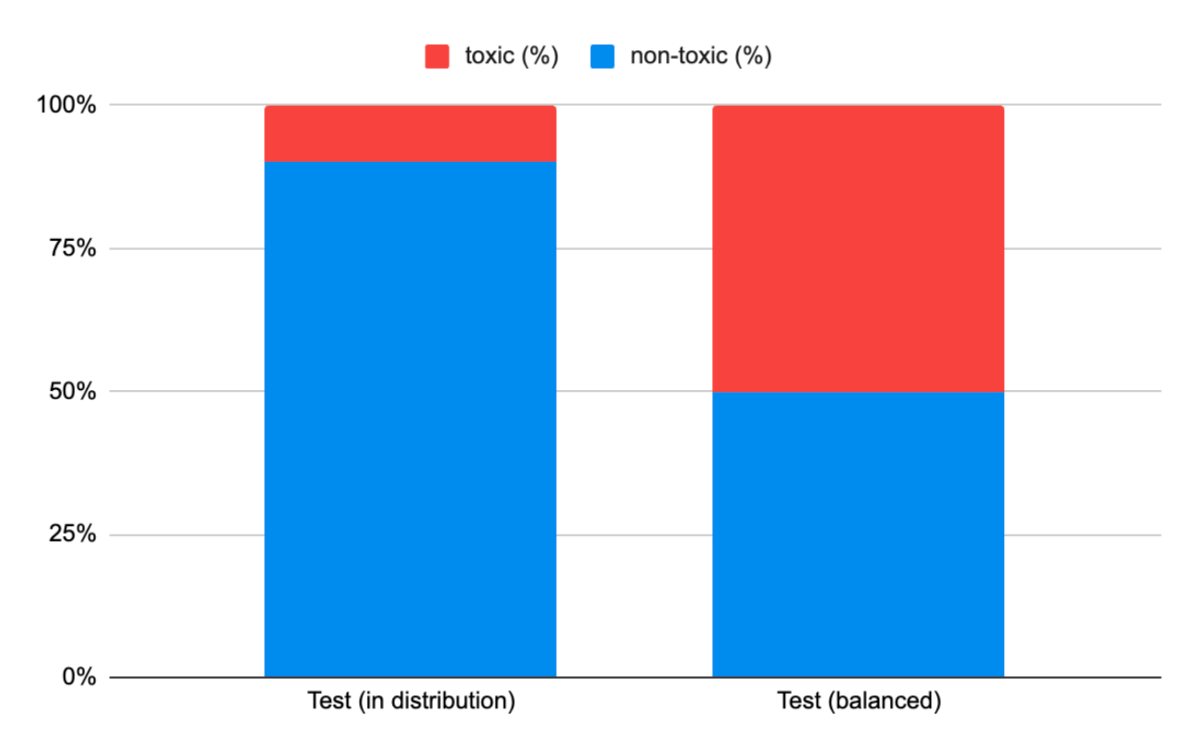
让我们正式确定两个不同的测试集:
test-indist:一个同分布测试集,包含90%非有毒样本和10%有毒样本,从原始测试集中抽取。test-balanced:一个显式平衡的测试集,包含50%非有毒和50%有毒样本,从原始测试集中抽取。
通过同时在这两个测试集上测量模型,我们可以跟踪候选模型对评论的总体分类效果,以及这些分类在真实流量环境中的表现。
</details>4. 最大化教师模型的质量
摘要:教师模型输出的质量是蒸馏学生模型性能的上限。尽可能投资最大化教师模型的性能。
<p align="center"> <img src="https://yellow-cdn.veclightyear.com/835a84d5/83070f3c-317f-448c-9840-59c5eb503866.png"> <p align="center" ><i>在让学生模型模仿教师模型的输出之前,要让教师模型尽可能优秀。</i></p> </p>**选择一个好的教师:**选择教师模型是关键的第一步。选择在你的任务上展示最高准确率和理解力的模型。GPT-4通常很出色,但值得检查是否有更适合你的用例、可能更专门化于你的任务的更好的基础模型。
| 指标 | zephyr-7b-alpha | Mixtral-8x7B-Instruct-v0.1 | Llama-2-70b-hf | Yi-34B-200K | CodeLlama-34b-Instruct-hf | GPT-3.5 | GPT-4 | Gemini |
|---|---|---|---|---|---|---|---|---|
| 总体平均 | 59.5 | 72.6 | 67.9 | 70.8 | 57.3 | 70.9 | 88.3 | 90.7 |
| ARC | 61.0 | 70.2 | 67.3 | 65.4 | 54.3 | 82.9 | 94.9 | 未报告 |
| HellaSwag | 84.0 | 87.6 | 87.3 | 85.6 | 76.9 | 79.4 | 92.4 | 87.8 |
| MMLU | 61.4 | 71.2 | 69.8 | 76.1 | 55.5 | 67.4 | 83.7 | 90.0 |
| TruthfulQA | 57.9 | 64.6 | 44.9 | 53.6 | 44.4 | 61.4 | 79.7 | 未报告 |
| Winogrande | 78.6 | 81.4 | 83.7 | 82.6 | 74.6 | 65.8 | 87.1 | 未报告 |
| GSM8K | 14.0 | 60.7 | 54.1 | 61.6 | 38.0 | 68.2 | 92.1 | 94.4 |
选择一个好的提示词: 迭代你的提示词和提示参数可以显著提高教师模型输出的质量。精心设计的提示词通常会导致更准确和更符合上下文的响应,这反过来为学生模型提供更好的训练材料。
<details><summary><em>[案例研究:Jigsaw有毒评论分类]</em></summary>改变LLM、提示词和温度可以对教师模型的准确性产生重大影响。
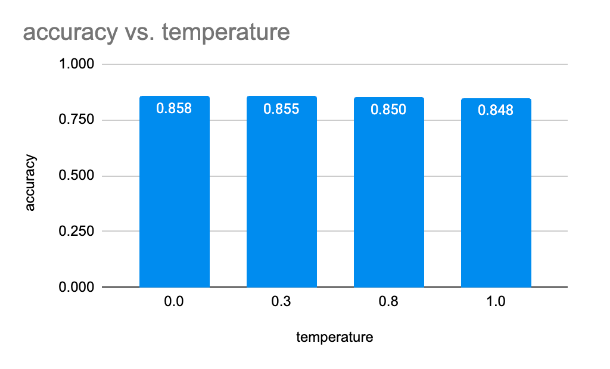
对于这个数据集,最佳温度似乎是0.0。这是有道理的,因为较高的温度会提高LLM输出的创造性,这在二元分类环境中可能不太有用。
我们使用两种不同的提示词突出显示了test-balanced的准确性:
简单提示词:
Given the input text below, please classify whether it is toxic. Provide your classification in a JSON format with the key 'is_bad'. If the comment is indeed toxic, set is_bad=1, otherwise set is_bad=0.
Input text: '%s'
Output:
思维链提示词:
For a well-intentioned content moderation app, we want to flag a comment if it may contain toxic, insulting, obscene, or threatening language. Given the input text, please classify its toxicity. Please format your response in the form of a python dictionary with the following keys:
1. 'is_bad': If the comment is indeed toxic, use set is_bad=1, otherwise set is_bad=0.
2. 'reason': Provide an appropriate amount of detail for for your judgment.
Input text: '%s'
Output:
以下是我们的结果:
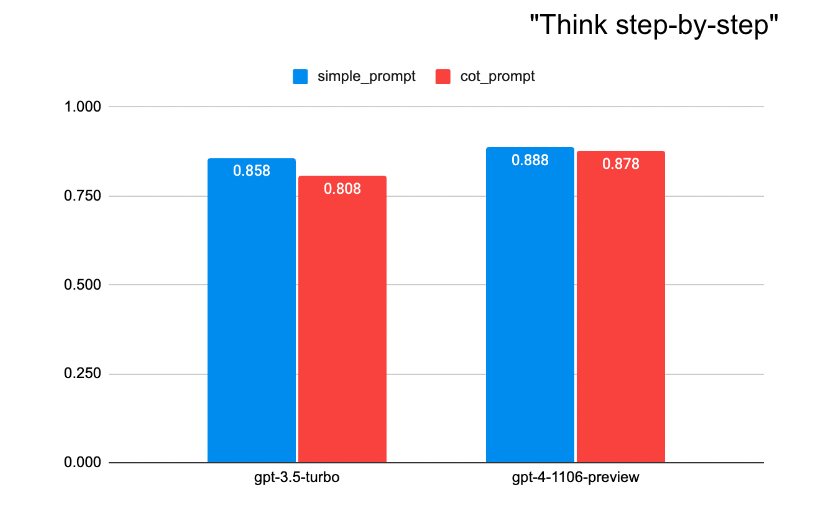
simple_prompt似乎比更复杂的Chain-of-Thought提示词更符合人类标签。
使用GPT-4时,两种�提示词之间的质量差距较小,但似乎更复杂的提示词并不总是导致更好的质量。也许思维链提示引发的额外推理增加了假阳性的比率。
5. 最大化你的训练数据的质量。
总结: 如果你能继续提高训练数据的质量,无论是否涉及教师,你都应该这样做。考虑如何从根本上改善数据质量。
收敛的学生模型所犯的大多数错误都可以追溯到源数据的问题。对于学生模型来说,在源头解决数据质量问题通常比尝试用辅助系统纠正这些问题更有效。
以下是一些最流行的技术。
| 技术 | 难度 | 通用适用性 | 人工劳动 | 描述 |
|---|---|---|---|---|
| 手动修复或整理数据 | ★ | ★★★★★ | ★★★★★ | 手动修复和修订错误输出。标注新数据。这种方法简单但劳动密集,可确保高质量、无错误的训练材料。 |
| 基于规则过滤数据 | ★★ | ★★★★ | ★★★ | 使用基本规则(长度标准、正则表达式模式)来消除低质量数据。虽然设置规则很简单,但确定正确的标准可能会很耗时。 |
| 使用辅助系统(或LLM)对数据进行排序 | ★★★ | ★★★ | ★ | 使用辅助系统(如另一个模型)来评估和排序数据质量。例如,Microsoft的phi-1模型使用GPT-4对训练示例进行评分,使用分类器优先考虑高价值数据,并删除底部X%的示例。另见本文的2.1节。 |
| 用解释痕迹丰富数据 | ★★★ | ★★ | ★ | 收集推理数据。如果你的任务需要非平凡的推理,你可能会发现包括来自教师的解释痕迹或思维链(CoT)输出会带来类似的性能提升。 |
| 聚合你的教师 | ★★★★ | ★ | ★ | 对于可递归定义的任务(如摘要),使用链式方法。对于有精确答案的任务,采用多数投票(参见MedPrompt论文,自洽性论文)。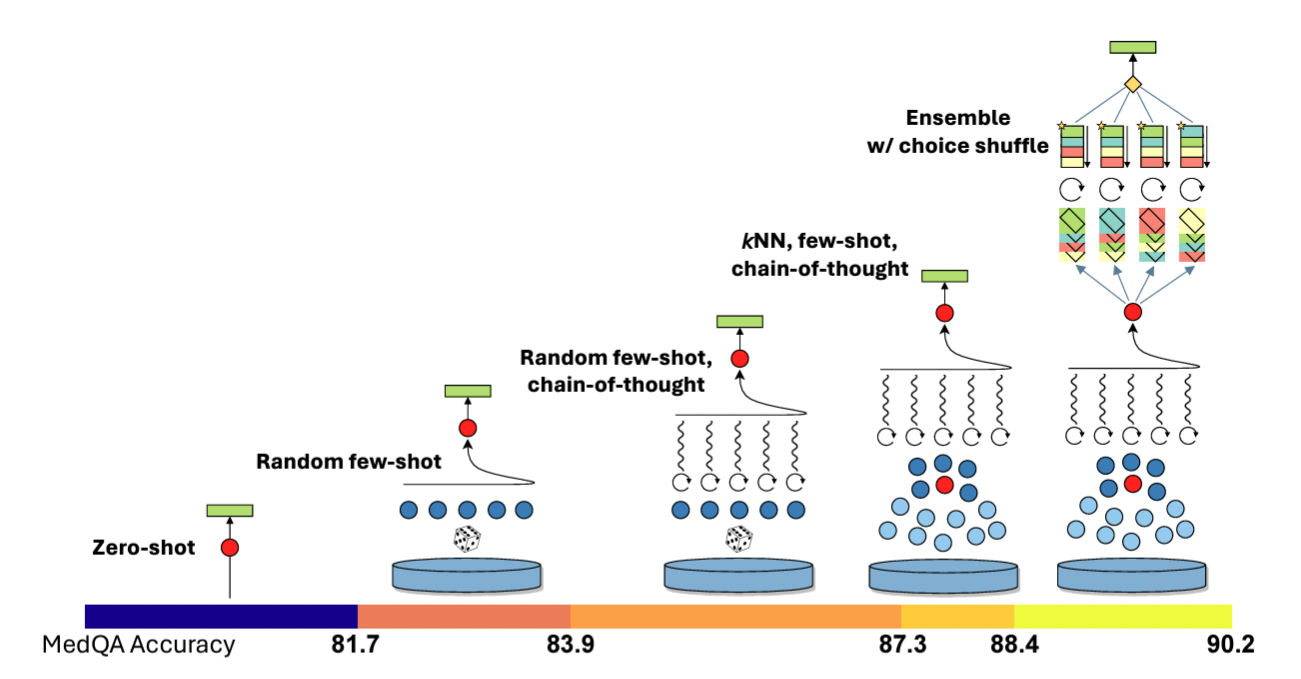 通过在多个教师的合并输出上训练你的学生,你可以使你的学生模型超越任何单个教师。 通过在多个教师的合并输出上训练你的学生,你可以使你的学生模型超越任何单个教师。 |
为了评估数据质量对模型性能的影响,我们可以从Jigsaw数据集中得出6个训练数据子集,并为每个子集训练模型。
- A(1.1k行):分布内,GPT标签。
- B(2.2k行):A + 1.1k行分布内黄金标签。
- C(2.1k行):B经过过滤以移除GPT错误。
- D(3.2k行):B + 1k行带有黄金有毒标签。
- E(5k行):更大的分布内数据集,GPT标签。
- F(10k行):最大的分布内数据集,GPT标签。
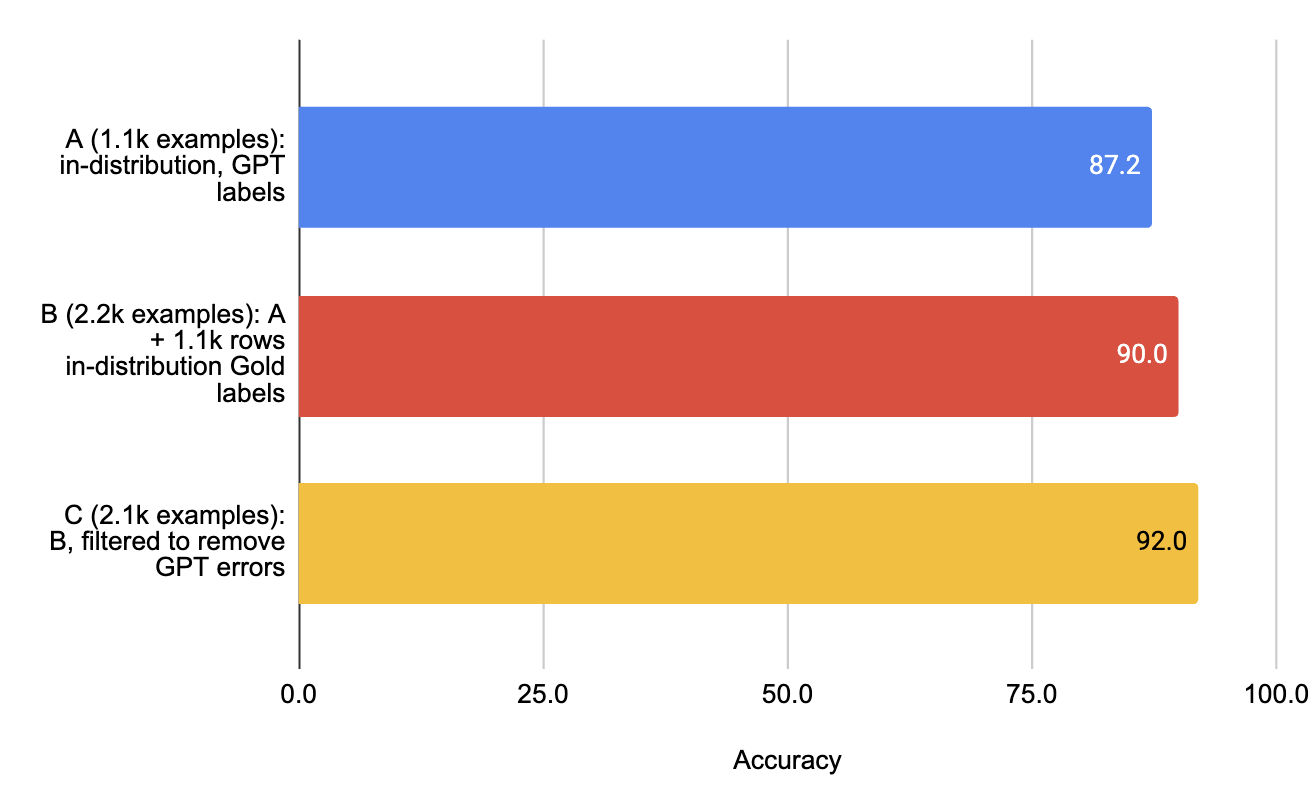
当我们添加高质量的人工标注示例以及移除不正确的教师标注示例时,性能都有所提高。
</details>6. 最好的数据集是多样化和平衡的。
总结: 尽量使你的数据集多样化、不重复和平衡。你的数据集涵盖的场景和复杂性越多,蒸馏出的学生就越有可能以无偏的方式泛化。 创建高质量数��据集的主要挑战之一是确保样本的多样性和非重复性。学生模型的训练数据应涵盖广泛的场景,并在难度、复杂性和风格上有所变化。
多样性很重要,原因有几个:它使语言模型接触到需要处理的不同情况,降低了过拟合或记忆特定模式或解决方案的风险,并提高了模型对未见或新颖情况的泛化能力和鲁棒性。
平衡性同样重要。如果某些情况在整个数据集中代表性不足,你的学生模型可能难以有效学习这些情况。
<p align="center"> <img src="https://yellow-cdn.veclightyear.com/835a84d5/80b35e72-c7c1-4488-8195-eb14b0b92bc8.png"> <p align="center"><i>从实际日志引导的数据集也可能存在变化或平衡不足的问题。对于基于日志的数据集,来自高频用户的过多示例可能会损害整体数据集的代表性。可以通过随机变异来消除日志偏差,通过释义或回译来增强稀有示例,或手动添加缺失的案例。</i></p> </p>不必一开始就了解或解决所有数据分布问题,但预期这些问题是有用的。相信如果你选择了好的测试集,学生模型中的显著偏差应该在评估过程中变得明显,这些偏差通常可以通过调整训练数据来解决。
<details><summary><em>[案例研究:Jigsaw有毒评论分类]</em></summary>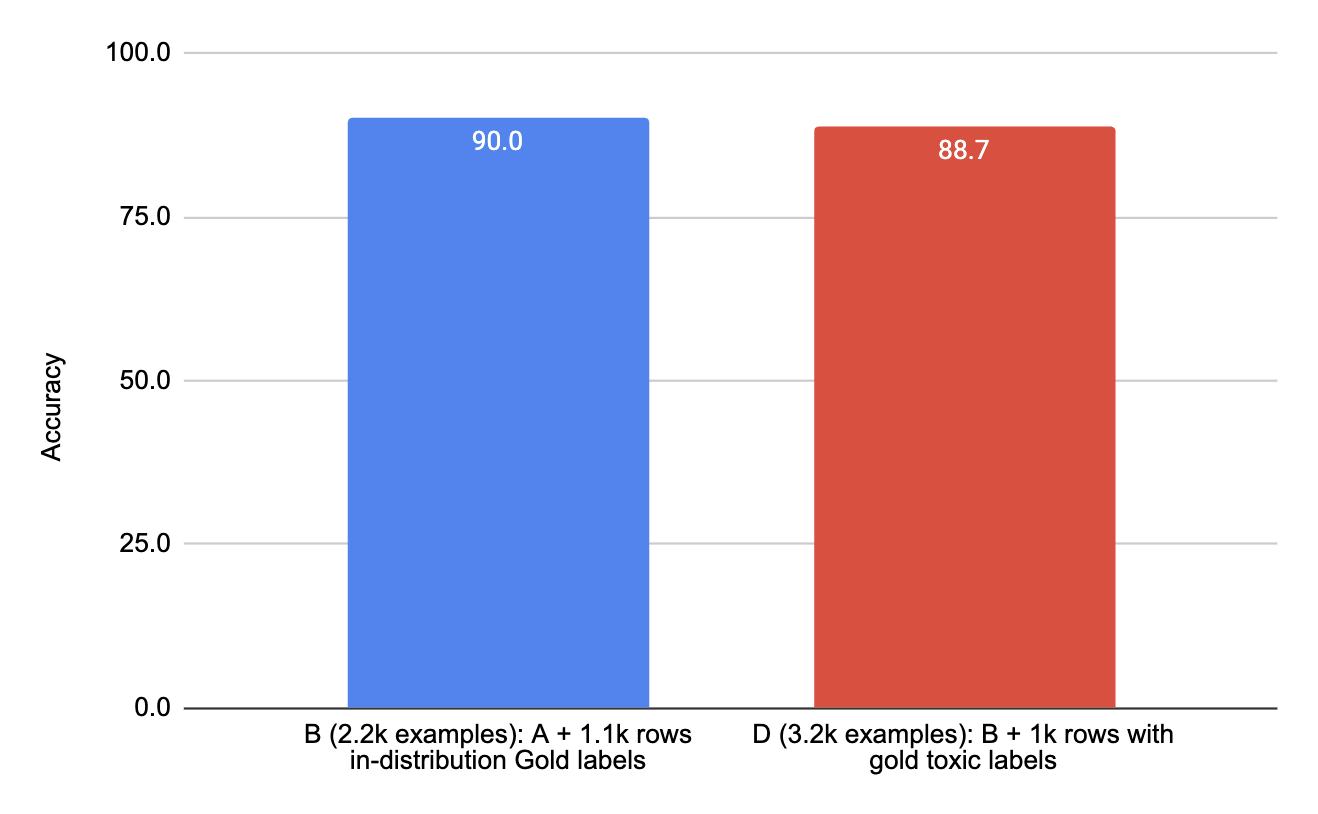
完美平衡并非必要,也不一定更好。
例如,非有毒示例可能比有毒示例更难检测,因此模型可能从更多困难类别的示例中受益,而较少的简单类别示例就足够了。
一开始很难知道什么是最佳的"平衡",或者对于非分类任务,如何衡量或有效地改变数据集的平衡。
更高层次的想法是,如果你有好的测试集,那么当你用(无意中)不平衡的训练数据进行模型评估时,你就能发现偏差模式,这些模式会提示你进行数据集分布调整。
</details>7. 从简单和小规模开始。
摘要:从较小、较简单的模型配置开始,这些配置训练速度快,可以让你调试设置问题,快速迭代,并建立良好的基准,以便日后与更复杂的模型配置进行比较。
拥抱最小、最简单模型的力量。 这不仅是效率问题,更是模型开发的战略方法。较小、较简单的模型训练和理解速度明显更快,允许最快的迭代和反馈。
避免陷入炫酷但复杂的大型模型陷阱。 模型训练中最常见的陷阱之一是一开始就使用过大过复杂的模型配置。这些模型更难理解,会降低迭代速度,延长实验周期。
朴素基线的价值。 总是从朴素、简单的基线模型开始。这些模型作为清晰的基准,用来衡量后续更复杂模型配置的表现。
8. 评估更多数据的边际效用。
摘要:根据经验,通常使用从几百到几万个示例的数据集就能取得有意义的微调结果。要更具体地回答你的任务需要多少数据,可以进行一项消融研究,改变数据集大小并进行推断。
"我需要多少数据来微调我的模型?" ~ 这是我们最常被问到的问题之一。
说实话,这真的取决于多个因素,如任务难度、输出变异性、推理复杂性、示例长度、任务与预训练数据的一致性以及超参数。有些问题只需要最少的数据就能收敛,而其他问题则需要大�量训练却仍无法收敛。
要确定适合你特定情况的数据集大小,可以进行一项消融实验,保持其他训练参数不变,只改变数据集大小(例如,5%、10%、25%、50%、75%、100%)。
这样的实验可以揭示微调时增加数据的边际效用。如果增加数据量并没有带来太多改善,建议重新评估训练流程的其他方面,找出可能的改进领域。
如果你发现增加数据的边际效用很高,那么可以考虑使用数据增强技术,如反向翻译,或手动标注更多数据。
<details><summary><em>[案例研究:Jigsaw有毒评论分类]</em></summary>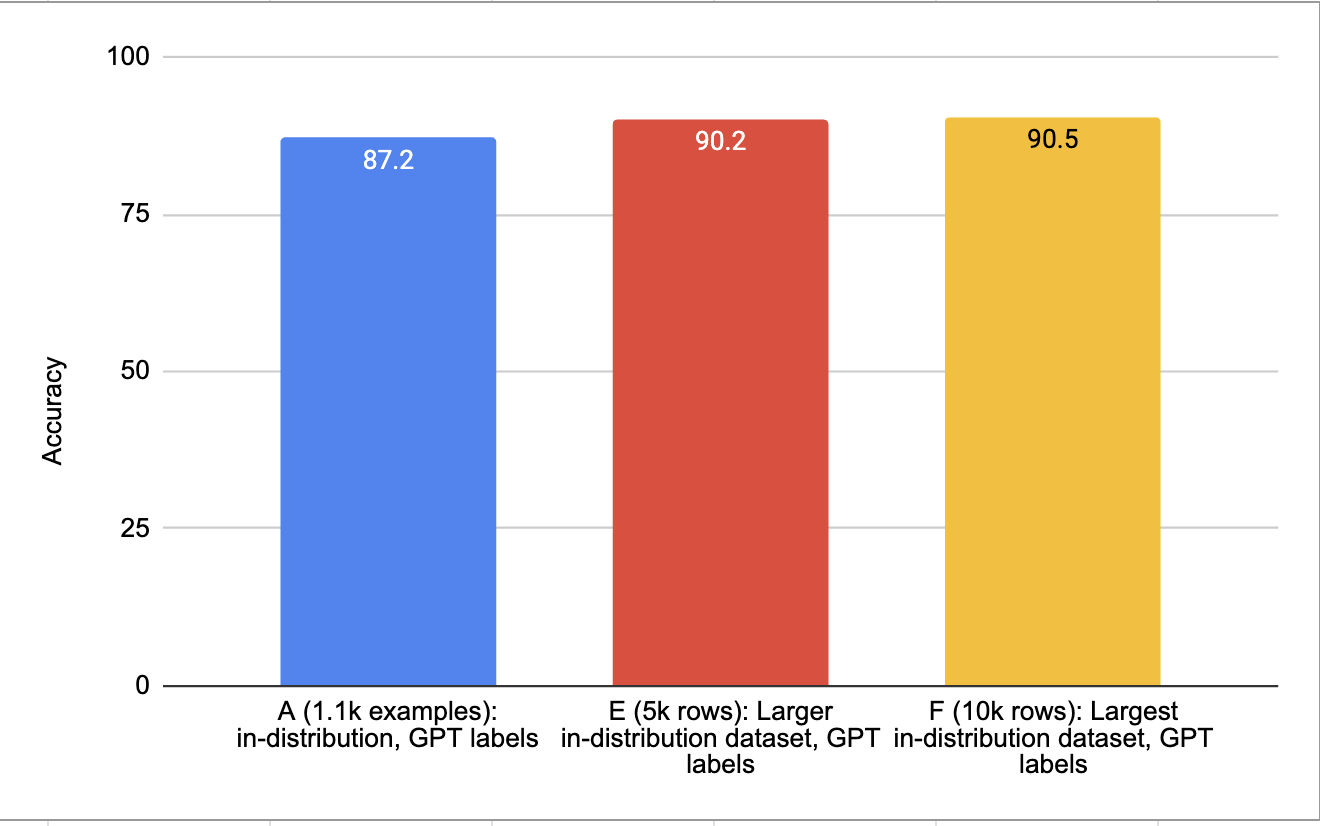
虽然从1.1K个示例到5K个示例的性能有很大提升,但从5K到10K的提升相当有限。根据这些分数,我们可以大致推断,对于这个模型配置,增加超过10K个示例的训练数据的边际效用在递减。
</details>9. 考虑如何部署你的学生模型。
摘要:虽然不必一开始就决定,但心中有一个模型部署计划会有助于优先考虑可以最终部署的模型实验。
如果你计划在生产环境中部署多个大语言模型,探索参数高效微调(PEFT)技术会很有益处。PEFT,如LoRA(低秩适应),只训练模型权重的一小部分,不像全量微调那样需要为每个模型分配专用的GPU资源。LoRA已被证明能达到与全量微调相当的性能,使其成为高效部署的可行选择。
例如,LoRA Exchange (LoRAX)是一种优化的服务解决方案�,可以使用共享GPU资源服务众多微调模型。LoRAX与传统的大语言模型服务方法的显著区别在于它能在单个GPU上容纳超过一百个针对特定任务的微调模型。这种能力大大降低了服务微调模型的成本和复杂性。LoRaX特别适合参数高效微调的模型,为部署提供了简化的解决方案。
虽然使用更大模型进行全量微调可能会产生最高的绝对质量,但在增加成本或服务延迟方面的权衡可能无法证明性能的边际收益是合理的。
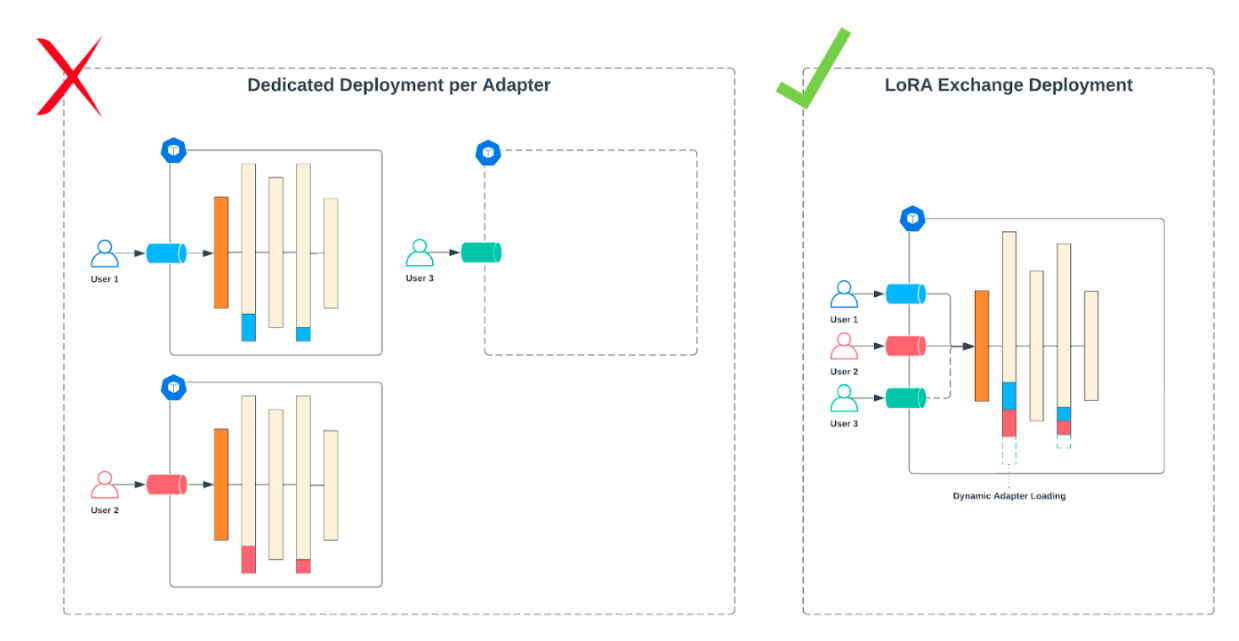
在模型开发过程的早期就考虑目标服务架构。你选择的模型类型可能会极大地影响它将如何被服务,这应该指导你如何优先安排实验。
10. 广泛实验,每次改变一个参数。
摘要:探索优于利用:将大部分时间和精力用于获取对问题的洞察。每次只改变一个变量,尽量不要钻牛角尖。
同时进行多个实验的技巧:
- 使用模型仓库或电子表格保持组织。
- 并行进行但每次只改变一个参数。
- 预期会有一些繁琐工作和猜测。
- 优化迭代速度(简单到复杂,小规模到大规模)
以下建议源于我们试图明确自己微调大语言模型的方法。这远非一个综合列表,但这里是我们最喜欢的一些探索想法。
| 类别 | 想法 | 对质量的影响 | 对速度的影响 | 复杂度 | 描述 |
|---|---|---|---|---|---|
| 架构参数 | 基础模型 | ★★★★★ | ★★ | ★ | 尝试几个不同的基础模型,看看对学生模型的性能有什么影响。就像老师一样,不�同的基础模型可能天生更接近你的任务。 |
| 架构参数 | 精度和量化 | ★★★★ | ★★★★ | ★★ | 降低精度可以显著减小模型大小,使其能够以更大的批量大小进行训练,从而提高吞吐量。虽然量化有时可能因为精度降低而导致模型准确性略有下降,但并非总是如此。在我们的实验中,与速度和大小减少的收益相比,这种权衡通常是微不足道的。 |
| 架构参数 | 适配器参数(秩和alpha) | ★★★★ | ★★★ | ★★ | LoRA中的秩决定了用于近似模型中全秩权重矩阵的低秩矩阵的大小。更高的秩可以增加模型学习复杂模式的能力,但代价是需要训练更多参数。相反,较低的秩更节省参数,但限制了模型的表达能力。 |
| 架构参数 | 基础模型大小 | ★★★ | ★★★★★ | ★ | 尝试不同的大小,以了解模型性能和模型大小之间的权衡。由于任务的复杂性,某些任务可能会从更大的模型中显著受益。然而,更大的模型更容易过拟合训练数据,特别是当数据集不够大或多样化时,或者质量提升可能微乎其微。越来越多地,它是 |
| 架构参数 | 提示 | ★★ | ★★ | ★ | 提示对教师模型有非常大的影响,但在有监督微调(SFT)中,模型的权重会直接更新,精心设计提示对质量的直接影响并不那么大。 |
| 训练参数 | 轮数 | ★★★★★ | ★★★★★ | ★ | 简单地训练模型更长时间(更多轮数)通常会得到更好的模型。 |
| 训练参数 | 学习率(LR)和LR调度 | ★★★★★ | ★ | ★ | 最佳学习率确保模型能高效学习,既不会错过也不会超过最佳权重。适当的预热�可以提高模型训练的稳定性和性能,而衰减则有助于在学习复杂模式和避免过拟合训练数据之间保持平衡。 |
| 训练参数 | 最大序列长度 | ★★★ | ★★★ | ★ | 对于长尾数据,考虑截断数据以最大化GPU利用率。 |
| 训练参数 | 批量大小 | ★★★ | ★★★★★ | ★ | 充分利用你的GPU。选择不会导致内存溢出的最大批量大小。 |
| 训练策略 | 课程学习 | ★★★★ | ★★★ | ★★★★★ | 渐进学习,也称为课程学习,是一种训练策略,其中模型在一系列阶段中进行微调,每个阶段使用不同类型的训练数据,通常从更一般或更嘈杂的数据逐步过渡到更具体、高质量或领域内的数据。渐进学习模仿人类自然学习的方式:从广泛的概念开始,逐渐聚焦于更具体和复杂的想法。来自orca-2的渐进学习示例:[图片] |
| 训练策略 | RLHF/RLAIF/DPO | ★★★★ | ★★★★★ | ★★★★★ | RLHF/RLHAIF/DPO,也称为"偏好调整",模型通过强化学习更好地与人类偏好保持一致。这最初由OpenAI推广,但成本极高,似乎是最后一步优化。我们还没有遇到一家公司对这种级别的优化有迫切需求。RLHF vs. RLAIF的高层次图示:[图片] |
11. 查看模型的个别错误。
**摘要:**虽然总体指标和高级自动评估方法提供了模型性能的广泛概览,但手动审查模型输出的示例可以带来无与伦比的价值,从而更深入地定性理解模型性能。
特别是在生成式上下文中,模型性能无法用一个明确的指标简洁总结时,花时间深入研究模型出错的具体例子不仅是评估过程中的一步,它是模型开发过程中的关键组成部分。
**识别具体错误:**只有通过检查模型出错的个别示例,你才能开始分类和理解这些错误的性质。模型是否一直在某些类型的输入上遇到困难?是否存在错误更频繁或更可能发生的特定模式或上下文?
**揭示数据问题:**通常,错误模式可以追溯到数据准备问题或训练集中的不充分表示。尽早识别这些问题可以节省大量资源和时间,否则可能会浪费在无用的参数优化上。没有什么比花费数百个GPU小时优化建模参数,然后发现数据质量问题更令人沮丧或浪费的了。
[图片]
<p align="center"><i>微调LLM的损失曲线都会看起来像这样,但这些检查点之间的定性差异可能是巨大的。</i></p>12. 实际部署和监控你的生产模型。
**摘要:**虽然测试集提供了一个受控环境进行评估,但模型有效性的真正考验在于它如何在实际用户和实时输入下表现。部署你的模型并观察其在真实世界环境中的表现!
实际部署和监控你的生产模型...真的。无论你是研究员、工程师还是介于两者之间,通过对模型进行实际生产化的尽职调查都有很多可以学习的。
模型部署选项
- **实时实验和渐进推出:**从将小比例流量(如1%,然后10%)引导到学生模型开始。密切监控关键应用指标如延迟和用户交互的变化,然后再扩大规模。其他名称:增量/金丝雀发布。
- **暗启动:**继续在生产中使用教师模型,但在后台将部分流量路由到学生模型。比较学生模型预测与教师模型不同的情况,以评估学生模型的质量准备情况。其他名称:影子部署。
- **混合启动:**如果教师模型表现优于学生模型,考虑混合部署。学生模型可以处理更��简单、资源消耗较少的查询,而教师模型处理更复杂的请求。这种方法在效率和质量之间取得平衡。其他名称:蓝绿部署。
基础设施保障措施
- **监控输入:**微调模型因更专业化而对特征漂移敏感。
- **监控输出:**建立故障安全机制以审查生成的输出。生产中的LLM通常伴随着基于规则或基于模型的系统来识别问题并触发回退机制。请注意,使用另一个LLM进行输出监控可能会增加延迟。
- **维护日志:**继续记录任何生产LLM的输入和输出。日志对未来的模型改进或重新蒸馏将非常有价值。
贡献
我们非常希望听到你的反馈!
-
如果你喜欢这个手册,请点个星星!你也可以通过在Ludwig slack或LoRAX Discord上联系我们,或在LinkedIn上找到我们。用户评价有助于我们证明创建更多类似资源的合理性。
-
如果发现任何不正确的地方,请提出问题以开始讨论。对于不适合作为问题提出的问题或其他消息,请在GitHub上开启新的讨论主题。
-
这是一份活的文档。我们预计会定期进行大大小小的改进。如果你想收到通知,请关注我们的仓库(参见说明)。
-
这个列表中是否还缺少其他最佳实践?欢迎创建PR!我们承诺会迅速审查你的建议。
Footnotes
编辑推荐精选


GPT Plus|Pro充值
GPT充值
支持 ChatGPT Plus / Pro 充值服务,支付便捷,自动发货,售后可查。


GPT Image 2中文站
AI 图片生成平台
GPT Image 2 是面向用户的 AI 图片生成平台,支持文生图、图生图及多模型创意工作流。


Vecbase
你的AI Agent团队
Vecbase 是专为 AI 团队打造的智能工作空间,将数据管理、模型协作与知识沉淀整合于一处。算法、产品与业务在同一平台无缝协同,让从数据到 AI 应用的落地更快一步。


音述AI
全球首个AI音乐社区
音述AI是全球首个AI音乐社区,致力让每个人都能用音乐表达自我。音述AI提供零门槛AI创作工具,独创GETI法则帮助用户精准定义音乐风格,AI润色功能支持自动优化作品质感。音述AI支持交流讨论、二次创作与价值变现。针对中文用户的语言习惯与文化背景进行专门优化,支持国风融合、C-pop等本土音乐标签,让技术更好地承载人文表达。


QoderWork
阿里Qoder团队推出的桌面端AI智能体
QoderWork 是阿里推出的本地优先桌面 AI 智能体,适配 macOS14+/Windows10+,以自然语言��交互实现文件管理、数据分析、AI 视觉生成、浏览器自动化等办公任务,自主拆解执行复杂工作流,数据本地运行零上传,技能市场可无限扩展,是高效的 Agentic 生产力办公助手。


lynote.ai
一站式搞定所有学习需求
不再被海量信息淹没,开始真正理解知识。Lynote 可摘要 YouTube 视频、PDF、文章等内容。即时创建笔记,检测 AI 内容并下载资料,将您的学习效率提升 10 倍。


AniShort
为AI短剧协作而生
专为AI短剧协作而生的AniShort正式发布,深度重构AI短剧全流程生产模式,整合创意策划、制作执行、实时协作、在线审片、资产复用等全链路功能,独创无限画布、双轨并行工业化工作流与Ani智能体助手,集成多款主流AI大模型,破解素材零散、版本混乱、沟通低效等行业痛点,助力3人团队效率提升800%,打造标准化、可追溯的AI短剧量产体系,是AI短剧团队协同创作、提升制作效率的核心工具。


seedancetwo2.0
能听懂你表达的视频模型
Seedance two是基于seedance2.0的中国大模型,支持图像、视频、音频、文本四种模态输入,表达方式更丰富,生成也更可控。


nano-banana纳米香蕉中文站
国内直接访问,限时3折
输入简单文字,生成想要的图片,纳米香蕉中文站基于 Google 模型的 AI 图片生成网站,支持文字生图、图生图。官网价格限时3折活动


扣子-AI办公
职场AI,就用扣子
AI办公助手,复杂任务高效处理。办公效率低?扣子空间AI助手支持播客生成、PPT制作、网页开发及报告写作,覆盖科研、商业、舆情等领域的专家Agent 7x24小时响应,生活工作无缝切换,提升50%效率!
推荐工具精选





AI云服务特惠
懂AI专属折扣关注微信公众号
最新AI工具、AI资讯
独家AI资源、AI项目落地

微信扫一扫关注公众号