




分割任意物体




Alexander Kirillov、Eric Mintun、Nikhila Ravi、Hanzi Mao、Chloe Rolland、Laura Gustafson、Tete Xiao、Spencer Whitehead、Alex Berg、Wan-Yen Lo、Piotr Dollar、Ross Girshick
[论文] [项目] [演示] [数据集] [博客] [引用]
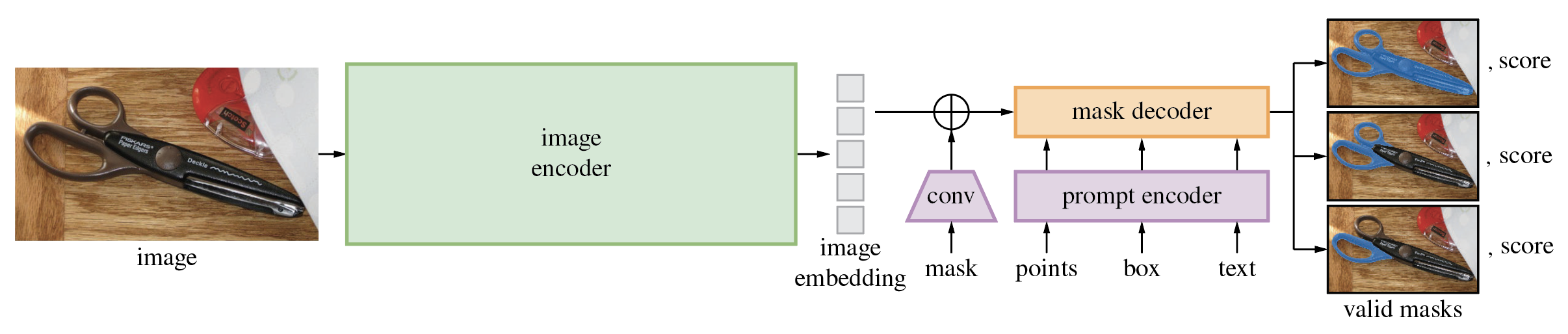
**分割任意物体模�型(SAM)**可以根据输入提示(如点或框)生成高质量的物体掩码,并可用于生成图像中所有物体的掩码。该模型已在包含1100万张图像和11亿个掩码的数据集上进行了训练,并在各种分割任务上表现出强大的零样本性能。
<p float="left"> <img src="https://yellow-cdn.veclightyear.com/835a84d5/58fcfa40-794d-4ed8-8b91-3cfab94e7a7c.png?raw=true" width="37.25%" /> <img src="https://yellow-cdn.veclightyear.com/835a84d5/b7e53e78-2e2c-4fb3-ad54-aa94d9b7f169.jpg?raw=true" width="61.5%" /> </p>免责声明
我不是原始实现的作者。这个仓库是一个将原始实现封装成包的Python包。如果您对原始实现有任何疑问,请参考facebookresearch/segment-anything。原始实现采用Apache License 2.0许可证。
安装
代码要求python>=3.8,以及pytorch>=1.7和torchvision>=0.8。请按照这里的说明安装PyTorch和TorchVision依赖项。强烈建议安装支持CUDA的PyTorch和TorchVision。
使用pip安装Segment Anything:
pip install segment-anything-py
或使用mamba安装Segment Anything:
mamba install -c conda-forge segment-anything
或克隆仓库到本地并安装:
pip install git+https://github.com/facebookresearch/segment-anything.git
以下可选依赖项用于掩码后处理、以COCO格式保存掩码、示例笔记本和以ONNX格式导出模型。运行示例笔记本还需要安装jupyter。
pip install opencv-python pycocotools matplotlib onnxruntime onnx
<a name="GettingStarted"></a>入门
首先下载一个模型检查点。然后只需几行代码就可以使用模型从给定提示获取掩码:
from segment_anything import SamPredictor, sam_model_registry
sam = sam_model_registry["<model_type>"](checkpoint="<path/to/checkpoint>")
predictor = SamPredictor(sam)
predictor.set_image(<your_image>)
masks, _, _ = predictor.predict(<input_prompts>)
或为整个图像生成掩码:
from segment_anything import SamAutomaticMaskGenerator, sam_model_registry
sam = sam_model_registry["<model_type>"](checkpoint="<path/to/checkpoint>")
mask_generator = SamAutomaticMaskGenerator(sam)
masks = mask_generator.generate(<your_image>)
此外,还可以通过命令行为图像生成掩码:
python scripts/amg.py --checkpoint <path/to/checkpoint> --model-type <model_type> --input <image_or_folder> --output <path/to/output>
有关更多详细信息,请参阅使用SAM和提示和自动生成掩码的示例笔记本。
<p float="left"> <img src="https://yellow-cdn.veclightyear.com/835a84d5/0e4c5cb5-105f-474b-8d53-a0eb8fbdc029.png?raw=true" width="49.1%" /> <img src="https://yellow-cdn.veclightyear.com/835a84d5/51a2d194-6d44-4a1d-b52b-718e923f543d.png?raw=true" width="48.9%" /> </p>ONNX导出
SAM的轻量级掩码解码器可以导出为ONNX格式,以便在支持ONNX运行时的任何环境中运行,例如在演示中展示的浏览器内运行。使用以下命令导出模型:
python scripts/export_onnx_model.py --checkpoint <检查点路径> --model-type <模型类型> --output <输出路径>
有关如何将SAM主干网络的图像预处理与使用ONNX模型进行掩码预测相结合的详细信息,请参阅示例笔记本。建议使用最新稳定版本的PyTorch进行ONNX导出。
Web演示
demo/文件夹包含一个简单的单页React应用,展示了如何在Web浏览器中使用多线程运行导出的ONNX模型进行掩码预测。更多详情请参阅demo/README.md。
<a name="Models"></a>模型检查点
提供了三种不同主干网络大小的模型版本。可以通过运行以下代码实例化这��些模型:
from segment_anything import sam_model_registry
sam = sam_model_registry["<模型类型>"](checkpoint="<检查点路径>")
点击下面的链接下载相应模型类型的检查点。
default或vit_h:ViT-H SAM模型vit_l:ViT-L SAM模型vit_b:ViT-B SAM模型
数据集
点击此处查看数据集概述。可以在这里下载数据集。下载数据集即表示您已阅读并接受SA-1B数据集研究许可协议的条款。
我们将每张图像的掩码保存为json文件。可以在Python中以以下格式加载为字典。
{ "image" : 图像信息, "annotations" : [注释], } 图像信息 { "image_id" : int, # 图像ID "width" : int, # 图像宽度 "height" : int, # 图像高度 "file_name" : str, # 图像文件名 } 注释 { "id" : int, # 注释ID "segmentation" : dict, # 以COCO RLE格式保存的掩码 "bbox" : [x, y, w, h], # 掩码周围的框,采用XYWH格式 "area" : int, # 掩码的像素面积 "predicted_iou" : float, # 模型对掩码质量的自我预测 "stability_score" : float, # 掩码质量的衡量指标 "crop_box" : [x, y, w, h], # 用于生成掩码的图像裁剪,采用XYWH格式 "point_coords" : [[x, y]], # 输入模型以生成掩码的点坐标 }
图像ID可以在sa_images_ids.txt中找到,该文件也可以使用上面的链接下载。
要将COCO RLE格式的掩码解码为二进制:
from pycocotools import mask as mask_utils
mask = mask_utils.decode(annotation["segmentation"])
有关操作RLE格式存储的掩码的更多说明,请参阅此处。
许可证
该模型基于Apache 2.0许可证授权。
贡献
贡献者
Segment Anything项目的实现离不开众多贡献者的帮助(按字母顺序排列):
Aaron Adcock, Vaibhav Aggarwal, Morteza Behrooz, Cheng-Yang Fu, Ashley Gabriel, Ahuva Goldstand, Allen Goodman, Sumanth Gurram, Jiabo Hu, Somya Jain, Devansh Kukreja, Robert Kuo, Joshua Lane, Yanghao Li, Lilian Luong, Jitendra Malik, Mallika Malhotra, William Ngan, Omkar Parkhi, Nikhil Raina, Dirk Rowe, Neil Sejoor, Vanessa Stark, Bala Varadarajan, Bram Wasti, Zachary Winstrom
引用Segment Anything
如果您在研究中使用了SAM或SA-1B,请使用以下BibTeX条目。
@article{kirillov2023segany,
title={Segment Anything},
author={Kirillov, Alexander and Mintun, Eric and Ravi, Nikhila and Mao, Hanzi and Rolland, Chloe and Gustafson, Laura and Xiao, Tete and Whitehead, Spencer and Berg, Alexander C. and Lo, Wan-Yen and Doll{\'a}r, Piotr and Girshick, Ross},
journal={arXiv:2304.02643},
year={2023}
}
编辑推荐精选

小云雀
字节旗下AI内容创作Agent
小云雀是字节跳动旗下剪映团队推出的AI内容创作Agent,主打”一句话打造一个爆款”的零门槛创作体验。用户只需输入一句指令,可自动生成15-60秒短视频、数字人口播视频、风格化海报等内容,支持200+可商用数字人形象和19种语言及方言。小云雀核心功能包括智能成片、AI设计、照片会说话、爆款复刻等,已接入豆包大模型、DeepSeek Chat及自研Seedance 2.0视频生成模型、Seedream 5.0图像生成模型。目前支持安卓APP和网页版,每日登录可领取120积分。适合自媒体创作者、电商营销人员、教育工作者及普通用户使用,近期因用户量激增,视频生成排队时长可达8小时。


豆包
字节跳动旗下 AI 智能助手
字节跳动旗下 AI 智能助手


Pixmax
一站式AI短剧创作平台
Pixmax专注打造下一代“ AI 视觉创作引擎”,整合行业顶尖 AI 大模型、工工业级精准控制及企业级协同管理功能,是全方位的 AI 内容创作平台。


GPT Plus|Pro充值
GPT充值
支持 ChatGPT Plus / Pro 充值服务,支付便捷,自动发货,售后可查。


GPT Image 2中文站
AI 图片生成平台
GPT Image 2 是面向用户的 AI 图片生成平台,支持文生图、图生图及多模型创意工作流。


Vecbase
你的AI Agent团队
Vecbase 是专为 AI 团队打造的智能工作空间,将数据管理、模型协作与知识沉淀整合于一处。算法、产品与业务在同一平台无缝协同,让从数据到 AI 应用的落地更�快一步。


音述AI
全球首个AI音乐社区
音述AI是全球首个AI音乐社区,致力让每个人都能用音乐表达自我。音述AI提供零门槛AI创作工具,独创GETI法则帮助用户精准定义音乐风格,AI润色功能支持自动优化作品质感。音述AI支持交流讨论、二次创作与价值变现。针对中文用户的语言习惯与文化背景进行专门优化,支持国风融合、C-pop等本土音乐标签,让技术更好地承载人文表达。


QoderWork
阿里Qoder团队推出的桌面端AI智能体
QoderWork 是阿里推出的本地优先桌面 AI 智能体,适配 macOS14+/Windows10+,以自然语言交互实现文件管理、数据分析、AI 视觉生成、浏览器自动化等办公任务,自主拆解执行复杂工作流,数据本地运行零上传,技能市场可无限扩展,是高效的 Agentic 生产力办公助手。


lynote.ai
一站式搞定所有学习需求
不再被海量信息淹没,开始真正理解知识。Lynote 可摘要 YouTube 视频、PDF、文章等内容。即时创建笔记,检测 AI 内容并下载资料,将您的学习效率提升 10 倍。


AniShort
为AI短剧协作而生
专为AI短剧协作而生的AniShort正式发布,深度重构AI短剧全流程生产模式,整合创意策划、制作执行、实时协作、在线审片、资产复用等全链路功能,独创无限画布、双轨并行工业化工作流与Ani智能体助手,集成多款主流AI大模型,破�解素材零散、版本混乱、沟通低效等行业痛点,助力3人团队效率提升800%,打造标准化、可追溯的AI短剧量产体系,是AI短剧团队协同创作、提升制作效率的核心工具。
推荐工具精选






AI云服务特惠
懂AI专属折扣关注微信公众号
最新AI工具、AI资讯
独家AI资源、AI项目落地

微信扫一扫关注公众号