
awesome-diffusion-model-in-rl
扩散模型在强化学习领域的最新研究进展汇总
本项目汇总了强化学习领域应用扩散模型的最新研究论文,涵盖离线RL、机器人控制、轨迹规划等多个方向。持续追踪并整理扩散强化学习的前沿进展,为研究人员提供全面的参考资源。每篇论文均附有概述、代码链接和实验环境等详细信息,方便读者深入了解。





RL中的扩散模型精选
![]()



这是一个关于RL中扩散模型研究论文的集合。 本仓库将持续更新以追踪扩散强化学习的前沿进展。
欢迎关注和点赞!
目录
RL中扩散模型概述
RL中的扩散模型由Janner、Michael等人在"使用扩散进行灵活行为合成的规划"中首次提出。它将轨迹优化视为一个扩散概率模型,通过迭代细化轨迹进行规划。
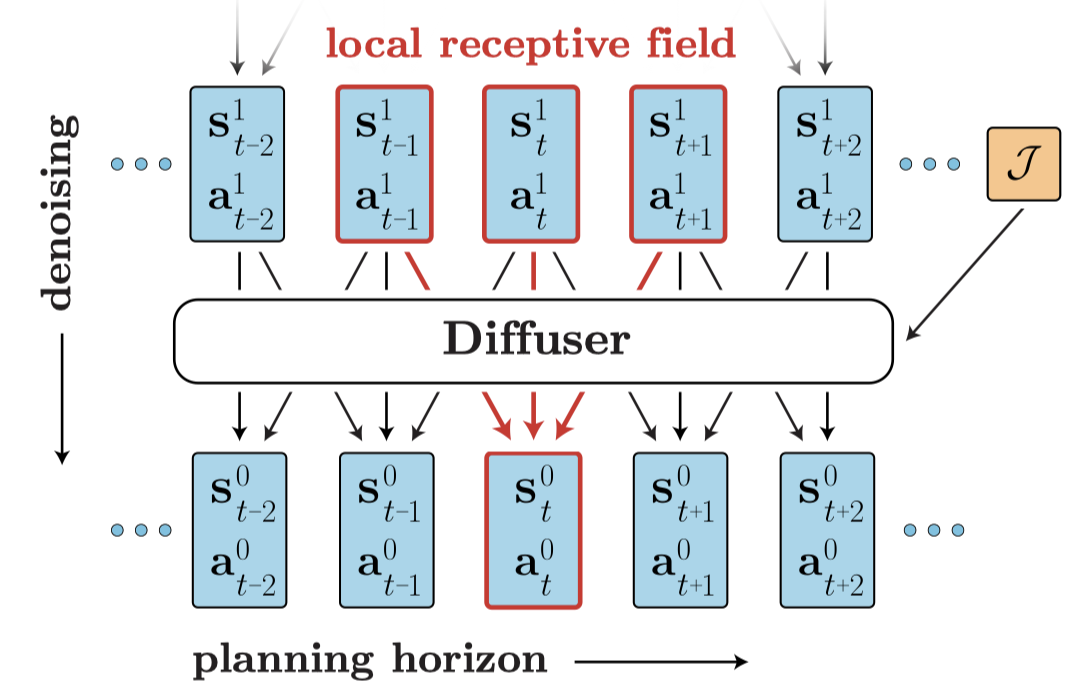
还有另一种方法:Wang, Z.等人在"扩散策略作为离线强化学习的表达性策略类"中提出将扩散模型作为离线RL中的策略优化。具体来说,Diffusion-QL从离线策略优化的角度将策略形成为以状态为条件的条件扩散模型。
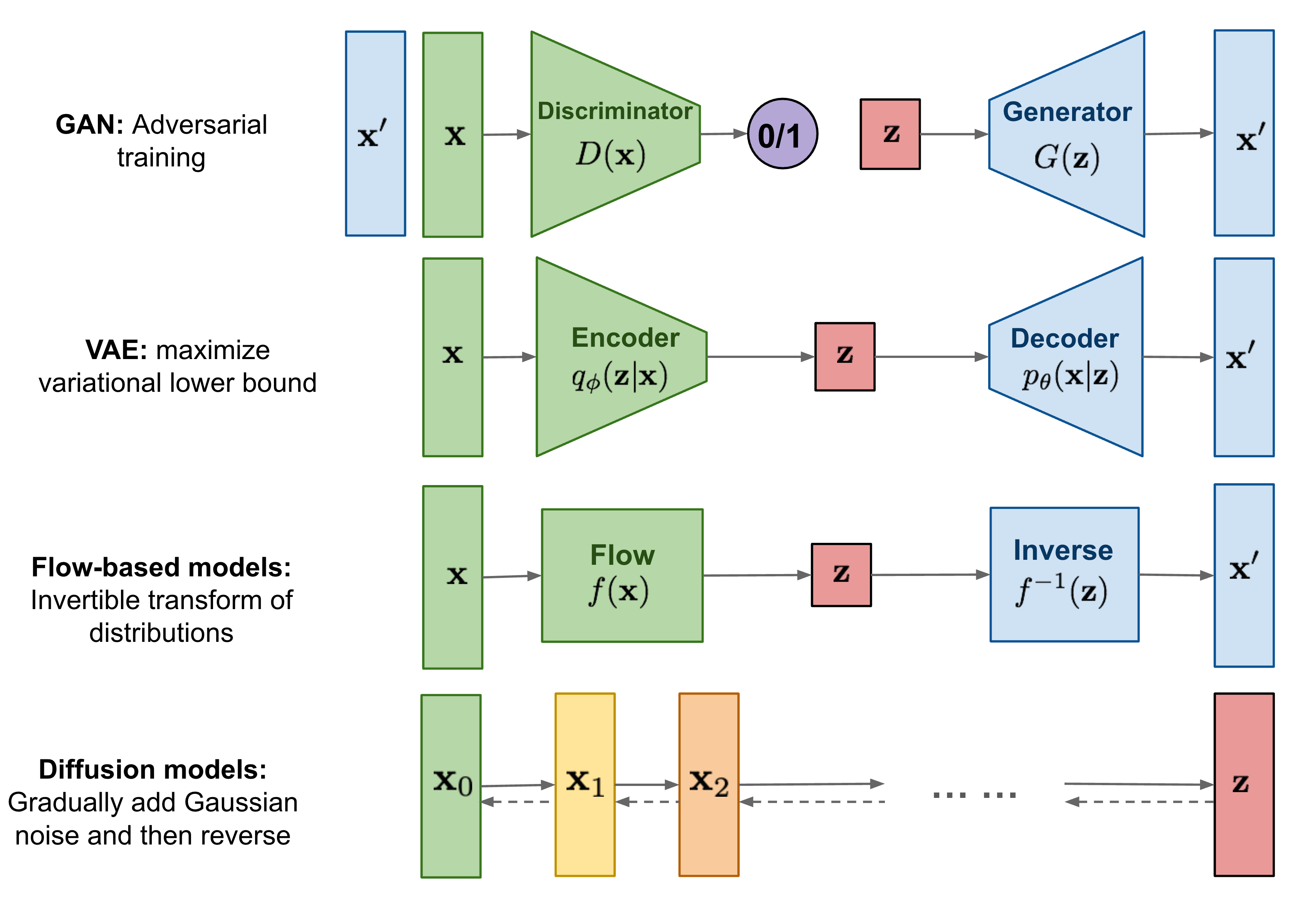
优势
- 绕过了长期信用分配中的自举需求。
- 避免了由于折扣未来奖励而导致的不良短视行为。
- 享受语言和视觉领域广泛使用的扩散模型,这些模型易于扩展和适应多模态数据。
论文
格式:
- [标题](论文链接) [链接]
- 作者1、作者2和作者3...
- 发表方
- 关键词
- 代码
- 实验环境
Arxiv
-
3D扩散策略:通过简单的3D表示实现可泛化的视觉运动策略学习
- Yanjie Ze, Gu Zhang, Kangning Zhang, Chenyuan Hu, Muhan Wang, Huazhe Xu
- 关键词:3D扩散策略,视觉模仿学习
- 实验环境:MetaWorld, Adroit, DexArt
-
扩散演员-评论家:将约束策略迭代公式化为离线强化学习中的扩散噪声回归
- Linjiajie Fang, Ruoxue Liu, Jing Zhang, Wenjia Wang, Bing-Yi Jing
- 关键词:扩散模型,演员-评论家,离线RL
- 实验�环境:D4RL
-
- Ajay Sridhar, Dhruv Shah, Catherine Glossop, Sergey Levine
- 关键词:扩散模型,离线RL
- 实验环境:真实世界机器人操作
-
- Philippe Hansen-Estruch, Ilya Kostrikov, Michael Janner, Jakub Grudzien Kuba, Sergey Levine
- 关键词:扩散模型,离线RL
- 实验环境:D4RL
-
- Takuma Yoneda, Luzhe Sun, and Ge Yang, Bradly Stadie, Matthew Walter
- 关键词:扩散模型,模仿,机器人学
- 实验环境:2D控制、月球着陆器、月球探测器和方块推动
-
- Lili Chen, Shikhar Bahl, Deepak Pathak
- 关键词:扩散模型,模仿,机器人学
- 实验环境:CALVIN、Franka厨房、语言条件Ravens
-
- Mengda Xu, Zhenjia Xu, Cheng Chi, Manuela Veloso, Shuran Song
- 关键词:扩散模型,模仿,机器人学
- 实验环境:真实世界机器人操作
-
- Eley Ng, Ziang Liu, Monroe Kennedy III
- 关键词:扩散模型,人在环中,机器人学
- 实验环境:人在环中模拟
-
- Zoey Chen, Sho Kiami, Abhishek Gupta, Vikash Kumar
- 关键词:扩散模型、数据合成器、机器人学
- 实验环境:端到端视觉操作任务
-
- Tianhe Yu, Ted Xiao, Austin Stone, Jonathan Tompson, Anthony Brohan, Su Wang, Jaspiar Singh, Clayton Tan, Dee M, Jodilyn Peralta, Brian Ichter, Karol Hausman, Fei Xia
- 关键词:扩散模型、数据合成器、机器人学
- 实验环境:机器人操作任务
-
- Cong Lu, Philip J. Ball, Yee Whye Teh, Jack Parker-Holder
- 关键词:扩散模型、数据合成器
- 实验环境:D4RL
-
- Bogdan Mazoure, Walter Talbott, Miguel Angel Bautista, Devon Hjelm, Alexander Toshev, Josh Susskind
- 关键词:扩散模型、离策略学习、离线强化学习、强化学习、机器人学
- 实验环境:D4RL
-
- Yinan Zheng, Jianxiong Li, Dongjie Yu, Yujie Yang, Shengbo Eben Li, Xianyuan Zhan, Jingjing Liu
- 关键词:时间无关分类器引导、安全离线强化学习
- 代码:官方
- 实验环境:DSRL
-
- Marc Rigter, Jun Yamada, Ingmar Posner
- 关键词:世界模型、基于模型的强化学习、策略引导
- 实验环境:Gym MuJoCo
-
- Zhengbang Zhu, Hanye Zhao, Haoran He, Yichao Zhong, Shenyu Zhang, Yong Yu, Weinan Zhang
- 关键词:综述
-
- Yuhui Chen, Haoran Li, Dongbin Zhao
- 关键词:Q学习、样本效率、一致性策略
- 实验环境:DMC、Gym MuJoCo、D4RL
-
- Longxiang He, Linrui Zhang, Junbo Tan, Xueqian Wang
- 关键词:约束策略搜索、离线强化学习
- 实验环境:D4RL
-
- Vineet Jain, Siamak Ravanbakhsh
- 关键词:约束策略搜索、离线强化学习
- 实验环境:离线目标条件设置
-
AlignDiff:通过行为可定制扩散模型对齐多样化人类偏好
- Zibin Dong, Yifu Yuan, Jianye Hao, Fei Ni, Yao Mu, Yan Zheng, Yujing Hu, Tangjie Lv, Changjie Fan, Zhipeng Hu
- 关键词:RLHF、对齐、无分类器
- 实验环境:Gym MuJoCo
-
- Zihan Ding, Chi Jin
- 关键词:一致性策略、三种典型强化学习设置
- 实验环境:D4RL、Gym MuJoCo
-
- Zhengbang Zhu, Minghuan Liu, Liyuan Mao, Bingyi Kang, Minkai Xu, Yong Yu, Stefano Ermon, Weinan Zhang
- 关键词:多智能体、离线强化学习、无分类器
- 实验环境:MPE、SMAC、多智能体轨迹预测(MATP)
-
- Suzan Ece Ada, Erhan Oztop, Emre Ugur
- 关键词:离线强化学习、分布外泛化
- 实验环境:2D多模态上下文赌博机、D4RL
-
- Cheng Chi, Siyuan Feng, Yilun Du, Zhenjia Xu, Eric Cousineau, Benjamin Burchfiel, Shuran Song
- 关键词:机器人操作
- 实验环境:Robomimic、Push-T、多模态推块、Franka厨房
-
- Zhixuan Liang, Yao Mu, Mingyu Ding, Fei Ni, Masayoshi Tomizuka, Ping Luo
- 关键词:目标条件模仿学习、机器人学、无分类器
- 实验环境:CALVIN、Block-Push、Relay Kitchen
CVPR 2024
- 面向运动学感知多任务机器人操作的分层扩散策略
- Xiao Ma, Sumit Patidar, Iain Haughton, Stephen James
- 发表于: CVPR 2024
- 关键词: 长期任务规划, 扩散模型
- 代码: 官方
- 实验环境: RLBench
ICLR 2024
-
- Kevin Black, Michael Janner, Yilun Du, Ilya Kostrikov, Sergey Levine
- 发表于: ICLR 2024
- 关键词: 强化学习, RLHF, 扩散模型
- 代码: 官方
- 实验环境: 无
-
- Lunjun Zhang, Yuwen Xiong, Ze Yang, Sergio Casas, Rui Hu, Raquel Urtasun
- 发表于: ICLR 2024
- 关键词: 离散扩散; 世界模型; 自动驾驶
- 代码: 官方
- 实验环境: NuScenes, KITTI Odometry, Argoverse2 Lidar
NeurIPS 2023
-
- Haoran He, Chenjia Bai, Kang Xu, Zhuoran Yang, Weinan Zhang, Dong Wang, Bin Zhao, Xuelong Li
- 发表于: NeurIPS 2023
- 关键词: 多任务强化学习, 扩散模型, 规划, 数据合成
- 实验环境: D4RL
ICML 2023
-
- 范颖、李康旭
- 发表于:ICML 2023
- 关键词:基于强化学习的扩散模型训练、在线强化学习、采样优化
- 代码:官方
- 实验环境:CIFAR10、CelebA
-
MetaDiffuser:扩散模型作为离线元强化学习的条件规划器
- 倪飞、郝建烨、穆尧、袁一夫、郑岩�、王斌、梁志轩
- 发表于:ICML 2023
- 关键词:离线元强化学习、条件轨迹生成、泛化、分类器引导
- 实验环境:MuJoCo
ICLR 2023
-
- Tim Pearce、Tabish Rashid、Anssi Kanervisto、Dave Bignell、Mingfei Sun、Raluca Georgescu、Sergio Valcarcel Macua、Shan Zheng Tan、Ida Momennejad、Katja Hofmann、Sam Devlin
- 发表于:ICLR 2023
- 关键词:离线强化学习、策略优化、模仿学习、无分类器
- 实验环境:Claw、Kitchen、CSGO
ICRA 2023
- 用于可控交通模拟的引导条件扩散
- Ziyuan Zhong、Davis Rempe、Danfei Xu、Yuxiao Chen、Sushant Veer、Tong Che、Baishakhi Ray、Marco Pavone
- 发表于:ICRA 2023
- 关键词:交通模拟、多智能体、无分类器
- 实验环境:nuScenes
NeurIPS 2022
ICML 2022
贡献
我们的目标是使这个仓库变得更好。如果您有兴趣贡献,请参考这里的贡献指南。
许可证
强化学习中的优秀扩散模型在 Apache 2.0 许可下发布。
编辑推荐精选

小云雀
字节旗下AI内容创作Agent
小云雀是字节跳动旗下剪映团队推出的AI内容创作Agent,主打”一句话打造一个爆款”的零门槛创作体验。用户只需输入一句指令,可自动生成15-60秒短视频、数字人口播视频、风格化海报等内容,支持200+可商用数字人形象和19种语言及方言。小云雀核心功能包括智能成片、AI设计、照片会说话、爆款复刻等,已接入豆包大模型、DeepSeek Chat及自研Seedance 2.0视频生成模型、Seedream 5.0图像生成模型。目前支持安卓APP和网页版,每日登录可领取120积分。适合自媒体创作者、电商营销人员、教育工作者及普通用户使用,近期因用户量激增,视频生成排队时长可达8小时。


豆包
字节跳动旗下 AI 智能助手
字节跳动旗下 AI 智能助手


Pixmax
一站式AI短剧创作平台
Pixmax专注打造下一代“ AI 视觉创作引擎”,整合行业顶尖 AI 大模型、工工业级精准控制及企业级协同管理功能,是全方位的 AI ��内容创作平台。


GPT Plus|Pro充值
GPT充值
支持 ChatGPT Plus / Pro 充值服务,支付便捷,自动发货,售后可查。


GPT Image 2中文站
AI 图片生成平台
GPT Image 2 是面向用户的 AI 图片生成平台,支持文生图、图生图及多模型创意工作流。


Vecbase
你的AI Agent团队
Vecbase 是专为 AI 团队打造的智能工作空间,将数据管理、模型协作与知识沉淀整合于一处。算法、产品与业务在同一平台无缝协同,让从数据到 AI 应用的落地更快一步。


音述AI
全球首个AI音乐社区
音述AI是全球首个AI音乐社区,致力让每个人都能用音乐表达自我。音述AI提供零门槛AI创作工具,独创GETI法则帮助用户精准定义音乐风格,AI润色功能支持自动优化作品质感。音述AI支持交流讨论、二次创作与价值变现。针对中文用户的语言习惯与文化背景进行专门优化,支持国风融合、C-pop等本土音乐标签,让技术更好地承载人文表达。


QoderWork
阿里Qoder团队推出的桌面端AI智能体
QoderWork 是阿里推出的本地优先桌面 AI 智能体,适配 macOS14+/Windows10+,以自然语言交互实现文件管理、数据分析、AI 视觉生成、浏览器自动化等办公任务,自主拆解执行复杂工作流,数据本地运行零上传,技能市场可无限扩展,是高效的 Agentic 生产力办公助手。


lynote.ai
一站式搞定所有学习需求
不再被海量信息淹没,开始真正理解知识。Lynote 可摘要 YouTube 视频、PDF、文章等内容。即时创建笔记,检测 AI 内容并下载资料,将您的学习效率提升 10 倍。


AniShort
为AI短剧协作而生
专为AI短剧协作而生的AniShort正式发布,深度重构AI短剧全流程生产模式,整合创意策划、制作执行、实时协作、在线审片、资产复用等全链路功能,独创无限画布、双轨并行工业化工作流与Ani智能体助手,集成多款主流AI大模型,破解素材零散、版本混乱、沟通低效等行业痛点,助力3人团队效率提升800%,打造标准化、可追溯的AI短剧量产体系,是AI短剧团队协同创作、提升制作效率的核心工具。
推荐工具精选






AI云服务特惠
懂AI专属折扣关注微信公众号
最新AI工具、AI资讯
独家AI资源、AI项目落地

微信扫一扫关注公众号