


超棒的决策变换器
![]()



这是一个**决策变换器(DT)**研究论文的集合。 该仓库将持续更新以追踪 DT 的前沿进展。
欢迎关注和加星!
目录
变换器概述
决策变换器由 Chen L. 等人在"决策变换器:通过序列建模实现强化学习"中提出。它将(离线)强化学习视为一个条件序列建模问题。
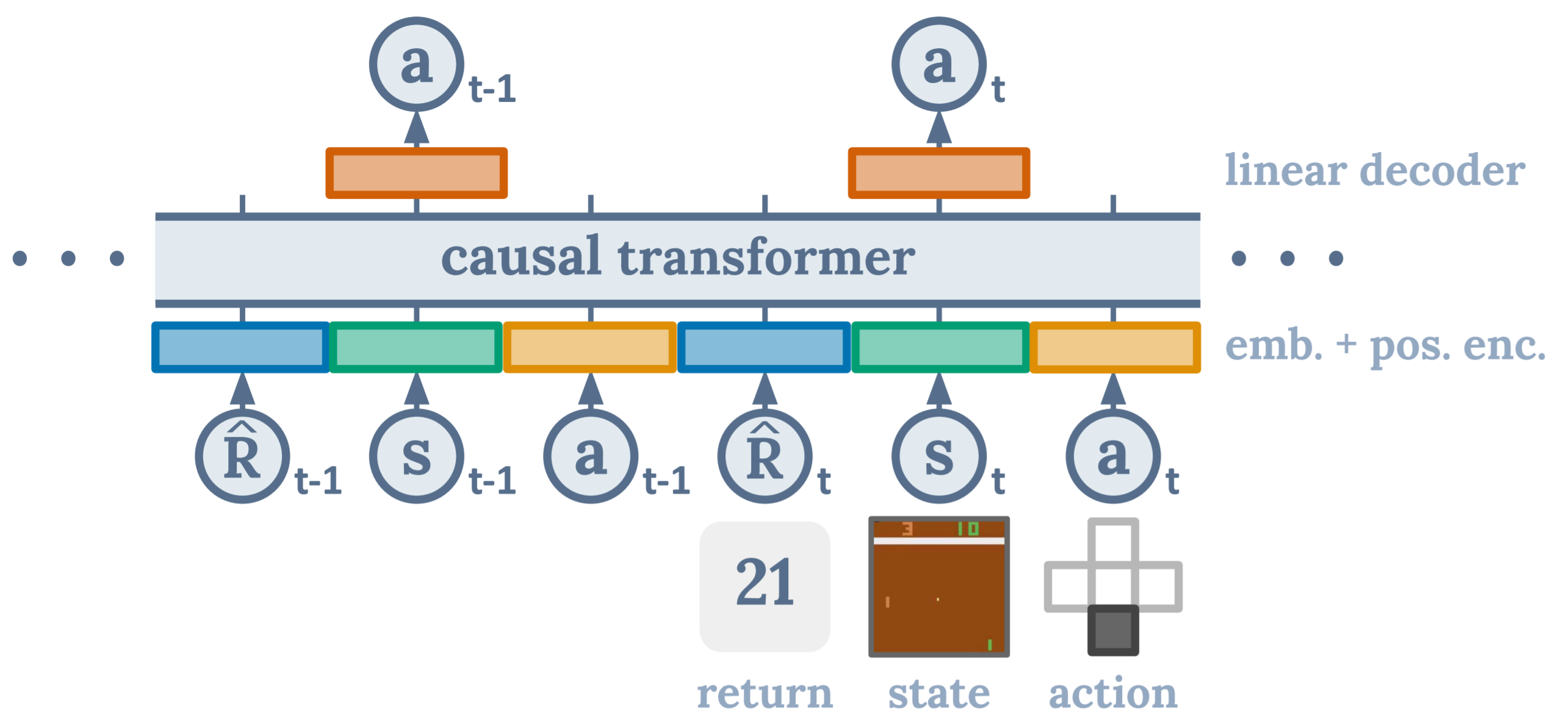
具体而言,DT 模型是一个因果变换器模型,以期望回报、(过去)状态和动作为条件,以自回归方式生成未来动作。
<div align=center> <img src=./dt-architecture.gif/> </div>优势
- 绕过了长期信用分配的自举需求
- 避免了由于对未来奖励折现而导致的不理想的短视行为
- 享受语言和视觉领域广泛使用的变换器模型的优势,这些模型易于扩展和适应多模态数据
综述
-
- Shengchao Hu, Li Shen, Ya Zhang, Yixin Chen, Dacheng Tao
- 出版:IEEE 模式分析与机器智能汇刊 (TPAMI)
-
- Muning Wen, Runji Lin, Hanjing Wang, Yaodong Yang, Ying Wen, Luo Mai, Jun Wang, Haifeng Zhang, Weinan Zhang
- 出版:计算机科学前沿
-
- Wenzhe Li, Hao Luo, Zichuan Lin, Chongjie Zhang, Zongqing Lu, Deheng Ye
- 出版:机器学习研究汇刊 (TMLR)
-
- Pranav Agarwal, Aamer Abdul Rahman, Pierre-Luc St-Charles, Simon J.D. Prince, Samira Ebrahimi Kahou
论文
格式:
- [标题](论文链接) [链接]
- 作者1、作者2和作者3...
- 出版方
- 关键词
- 代码
- 实验环境
Arxiv
-
- Ziqi Zhang, Jingzehua Xu, Zifeng Zhuang, Jinxin Liu, Donglin wang
- 关键词:DT,潜在条件序列建模
- 实验环境:D4RL
-
- Jingdi Chen, Hanhan Zhou, Yongsheng Mei, Gina Adam, Nathaniel D. Bastian, Tian Lan
- 关键词:DT,网络入侵检测
- 实验环境:UNSW-NB15
-
- Shengchao Hu, Li Shen, Ya Zhang, Dacheng Tao
- 关键词:提示调优
- 实验环境:D4RL
-
- Shengchao Hu, Li Shen, Ya Zhang, Dacheng Tao
- 关键词:图变换器
- 实验环境:Atari
-
- Ziqi Zhang, Yile Wang, Yue Zhang, Donglin Wang
- 关键词:语言模型
- 实验环境:MuJoco, Maze 2D
-
SaFormer:一种基于条件序列建模的离线安全强化学习方法
- Qin Zhang, Linrui Zhang, Haoran Xu, Li Shen, Bowen Wang, Yongzhe Chang, Xueqian Wang, Bo Yuan, Dacheng Tao
- 关键词:离线安全强化学习,DT
- 实验环境:D4RL
-
- Ayman Boustati, Hana Chockler, Daniel C. McNamee
- 关键词: 因果推理, 迁移学习
- 实验环境: MINIGRID
-
- Aaron L Putterman, Kevin Lu, Igor Mordatch, Pieter Abbeel
- 关键词: 文本条件决策
- 实验环境: 文本条件Frostbite(多模态基准)
-
- Hamed Khorasgani, Haiyan Wang, Chetan Gupta, Ahmed Farahat
- 发表: 2021年PHM学会年会
- 关键词: 离线监督强化学习, 剩余使用寿命估计
- 实验环境: NASA C-MAPSS
-
- Gregory Furman, Edan Toledo, Jonathan Shock, Jan Buys
- 发表: 第三届Wordplay:语言与游戏交汇研讨会论文集(Wordplay 2022)
- 关键词: 视觉问答
- 实验环境: QAIT
-
- Qinjie Lin, Han Liu, Biswa Sengupta
- 关键词: 多任务强化学习, 稀疏奖励
- 实验环境: MINIGRID
-
SimStu-Transformer:一种基于Transformer的模拟学生行为方法
- Zhaoxing Li, Lei Shi, Alexandra Cristea, Yunzhan Zhou, Chenghao Xiao, Ziqi Pan
- 关键词: 智能辅导系统
-
- Carson Smith
- 关键词: 组合优化
ICML 2024
-
- Shengchao Hu, Ziqing Fan, Li Shen, Ya Zhang, Yanfeng Wang, Dacheng Tao
- 发表: ICML 2024
- 关键词: 多任务, 决策转换器
- 实验环境: MetaWorld
-
- Shengchao Hu, Ziqing Fan, Chaoqin Huang, Li Shen, Ya Zhang, Yanfeng Wang, Dacheng Tao
- 发表: ICML 2024
- 关键词: Q-学习, 决策转换器
- 实验环境: D4RL
-
- Zijian Guo, Weichao Zhou, Wenchao Li
- 发表: ICML 2024
- 关键词: 信号时序逻辑(STL), 决策转换器
- 实验环境: DSRL
-
- Sili Huang, Jifeng Hu, Hechang Chen, Lichao Sun, Bo Yang
- 发表: ICML 2024
- 关键词: 层次结构, 决策转换器
- 实验环境: D4RL
-
- Yi Ma, Jianye Hao, Hebin Liang, Chenjun Xiao,
- 发表: ICML 2024
- 关键词: 决策转换器, 分层强化学习
- 实验环境: D4RL
ICLR 2024
-
- Shengchao Hu, Li Shen, Ya Zhang, Dacheng Tao
- 发表于:ICLR 2024
- 关键词:通信、序列建模
- 实验环境:SMAC
-
- Prajjwal Bhargava, Rohan Chitnis, Alborz Geramifard, Shagun Sodhani, Amy Zhang
- 关键词:离线强化学习、序列建模、强化学习
- 实验环境:D4RL
-
Transformer作为决策者:通过监督预训练实现可证明的上下文内强化学习
- Licong Lin, Yu Bai, Song Mei
- 关键词:transformer、上下文学习、强化学习、学习理论
- 实验环境:随机线性赌臂问题
-
- Raj Ghugare, Santiago Miret, Adriana Hugessen, Mariano Phielipp, Glen Berseth
- 关键词:化学、强化学习、语言模型
- 实验环境:对接和pytdc任务
NeurIPS 2023
-
- Sabrina McCallum, Max Taylor-Davies, Stefano V. Albrecht, Alessandro Suglia
- 发表于:NeurIPS 2023 Workshop
- 关键词:DT、语言反馈
- 实验环境:BabyAI
-
- Shalev Lifshitz, Keiran Paster, Harris Chan, Jimmy Ba, Sheila McIlraith
- 发表于:NeurIPS 2023
- 关键词:指令调优视频预训练
- 实验环境:Minecraft
-
Transformer作为统计学家:具有上下文算法选择的可证明上下文学习
- Yu Bai, Fan Chen, Huan Wang, Caiming Xiong, Song Mei
- 发表于:NeurIPS 2023
- 关键词:上下文学习、transformer、深度学习理论、学习理论
- 实验环境:上下文回归问题
-
- Yueh-Hua Wu, Xiaolong Wang, Masashi Hamaya
- 发表于:NeurIPS 2023
- 关键词:离线强化学习、轨迹拼接、多任务
- 实验环境:D4RL
CoRL 2023
-
- Vidhi Jain, Yixin Lin, Eric Undersander, Yonatan Bisk, Akshara Rai
- 发表于:CoRL 2023
- 关键词:任务规划、提示、控制、泛化
- 代码:官方
- 实验环境:洗碗机装载
-
- Yevgen Chebotar, Quan Vuong, Alex Irpan, Karol Hausman, Fei Xia, Yao Lu, Aviral Kumar, Tianhe Yu, Alexander Herzog, Karl Pertsch, Keerthana Gopalakrishnan, Julian Ibarz, Ofir Nachum, Sumedh Sontakke, Grecia Salazar, Huong T Tran, Jodilyn Peralta, Clayton Tan, Deeksha Manjunath, Jaspiar Singht, Brianna Zitkovich, Tomas Jackson, Kanishka Rao, Chelsea Finn, Sergey Levine
- 发表于:CoRL 2023
- 关键词:强化学习、离线强化学习、Transformer、Q学习、机器人操作
- 代码:非官方
- 实验环境:无
IROS 2023
-
PACT:用于自回归机器人预训练的感知-动作因果Transformer
- Rogerio Bonatti, Sai Vemprala, Shuang Ma, Felipe Frujeri, Shuhang Chen, Ashish Kapoor
- 发表于:IROS 2023
- 关键词:机器人学、预训练、多任务、表示
- 实验环境:MuSHR汽车, Habitat
ICML 2023
-
- Zuxin Liu, Zijian Guo, Yihang Yao, Zhepeng Cen, Wenhao Yu, Tingnan Zhang, Ding Zhao
- 发表: ICML 2023
- 关键词: 离线安全强化学习, 决策转换器
- 实验环境: Bullet-Safety-Gym
-
Q学习决策转换器: 利用动态规划进行离线强化学习中的条件序列建模
- Taku Yamagata, Ahmed Khalil, Raul Santos-Rodriguez
- 发表: ICML 2023
- 关键词: Q学习
- 实验环境: D4RL
ICRA 2023
- LATTE: 语言轨迹转换器
- Arthur Bucker, Luis Figueredo, Sami Haddadin, Ashish Kapoor, Shuang Ma, Sai Vemprala, Rogerio Bonatti
- 发表: ICRA 2023
- 关键词: 多模态, 机器人学
- 代码: 官方, 官方
- 实验环境: CoppeliaSim
ICLR 2023
-
- Johann Brehmer, Joey Bose, Pim de Haan, Taco Cohen
- 发表: ICLR 2023 重生强化学习研讨会
- 关键词: 丰富的几何结构, 等变性, 条件生成建模, 表示
- 实验环境: 无
NeurIPS 2022
-
- Keiran Paster, Sheila McIlraith, Jimmy Ba
- 发表: NeurIPS 2022
- 关键词: 随机环境
- 实验环境: 赌博, 四子棋, 2048
-
- Roland Memisevic, Sunny Panchal, Mingu Lee
- 发表: NeurIPS 2022 FMDM研讨会
- 关键词: 生成
- 实验环境: 遍历(玩具实验)
CoRL 2022
-
- Dhruv Shah, Arjun Bhorkar, Hrishit Leen, Ilya Kostrikov, Nicholas Rhinehart, Sergey Levine
- 发表: CoRL 2022 (口头报告)
- 关键词: 视觉导航
- 实验环境: RECON
ICML 2022
-
- Brandon Trabucco, Mariano Phielipp, Glen Berseth
- 发表于: ICML 2022 (海报)
- 关键词: 形态学, 迁移学习, 零样本
- 实验环境: Modular-RL
AAAI 2022
- 用Transformer做梦
- Catherine Zeng, Jordan Docter, Alexander Amini, Igor Gilitschenski, Ramin Hasani, Daniela Rus
- 发表于: AAAI 2022 (RLG研讨会)
- 关键词: Dreamer, 世界模型
- 实验环境: Deepmind Lab, VISTA
ICLR 2022
-
- Brandon Trabucco, Mariano Phielipp, Glen Berseth
- 发表于: ICLR 2022 (GPL研讨会海报)
- 关键词: 形态学, 迁移学习, 零样本
- 实验环境: Modular-RL
NeurIPS 2021
ICML 2021
贡献
我们的目标是使这个仓库变得更好。如果您有兴趣贡献,请参考这里的贡献指南。
许可证
Awesome Decision Transformer 在 Apache 2.0 许可下发布。
编辑推荐精选


扣子-AI办公
职场AI,就用扣子
AI办公助手,复杂任务高效处理。办公效率低?扣子空间AI助手支持播客生成、PPT制作、网页开发及报告写作,覆盖科研、商业、舆情等领域的专家Agent 7x24小时响应,生活工作无缝切换,提升50%效率!


堆友
多风格AI绘画神器
堆友平台由阿里巴巴设计团队创建,作为一款AI驱动的设计工具,专为设计师提供一站式增长服务。功能覆盖海量3D素材、AI绘画、实时渲染以及专业抠图,显著提升设计品质和效率。平台不仅提供工具,还是一个促进创意交流和个人发展的空间,界面友好,适合所有级别的设计师和创意工作者。


码上飞
零代码AI应用开发平台
零代码AI应用开发平台,用户只需一句话简单描述需求,AI能自动生成小程序、APP或H5网页应用,无需编写代码。


Vora
免费创建高清无水印Sora视频
Vora是一个免费创建高清无水印Sora视频的AI工具


Refly.AI
最适合小白的AI自动化工作流平台
无需编码,轻松生成可复用、可变现的AI自动化工作流


酷表ChatExcel
大模型驱动的Excel数据处理工具
基于大模型交互的表格处理系统,允许用户通过对话方式完成数据整理和可视化分析。系统采用机器学习算法解析用户指令,自动执行排序、公式计算和数据透视等操作,支持多种文件格式导入导出。数据处理响应速度保�持在0.8秒以内,支持超过100万行数据的即时分析。


TRAE编程
AI辅助编程,代码自动修复
Trae是一种自适应的集成开发环境(IDE),通过自动化和多元协作改变开发流程。利用Trae,团队能够更快速、精确地编写和部署代码,从而提高编程效率和项目交付速度。Trae具备上下文感知和代码自动完成功能,是提升开发效率的理想工具。


AIWritePaper论文写作
AI论文写作指导平台
AIWritePaper论文写作是一站式AI论文写作辅助工具,简化了选题、文献检索至论文撰写的整个过程。通过简单设定,平台可快速生成高质量论文大纲和全文,配合图表、参考文献等一应俱全,同时提供开题报告和答辩PPT等增值服务,保障数据安全,有效提升写作效率和论文质量。


博思AIPPT
AI一键生成PPT,就用博思AIPPT!
博思AIPPT,新一代的AI生成PPT平台,支持智能生成PPT、AI美化PPT、文本&链接生成PPT、导入Word/PDF/Markdown文档生成PPT等,内置海量精美PPT模板,涵盖商务、教育、科技等不同风格,同时针对每个页面提供多种版式,一键自适应切换,完美适配各种办公场景。


潮际好麦
AI赋能电商视觉革命,一站式智能商拍平台
潮际好麦深耕服装行业,是国内AI试衣效果最好的软件。使用先进AIGC能力为电商卖家批量提供优质的、低成本的商拍图。合作品牌有Shein、Lazada、安踏、百丽等65个国内外头部品牌,以及国内10万+淘宝、天猫、京东等主流平台的品牌商家,为卖家节省将近85%的出图成本,提升约3倍出图效率,让品牌能够快速上架。
推荐工具精选




AI云服务特惠
懂AI专属折扣关注微信公众号
最新AI工具、AI资讯
独家AI资源、AI项目落地

微信扫一扫关注公众号