
StyleShot
多样化风格迁移的AI图像生成开源项目
StyleShot是一个开源的AI图像生成项目,专注于实现广泛的风格迁移能力。通过风格感知编码器和StyleGallery数据集,它能够模仿3D、扁平、抽象等多种风格,无需测试时微调。项目在风格迁移性能上展现出优势,为图像风格化研究提供了新的方向和可能性。




StyleShot: 任意风格的快照
<div align="center"><a href='https://arxiv.org/abs/2407.01414'><img src='https://yellow-cdn.veclightyear.com/835a84d5/60f1081d-5467-428a-86ac-da30f895413b.svg'></a> <a href='https://styleshot.github.io/'><img src='https://img.shields.io/badge/Project-Page-Green'></a> <a href='https://openxlab.org.cn/apps/detail/lianchen/StyleShot'><img src='https://yellow-cdn.veclightyear.com/835a84d5/5165b426-3712-401b-9a33-e59fe6231bf0.svg'></a> <a href='https://huggingface.co/Gaojunyao/StyleShot'><img src='https://img.shields.io/badge/%F0%9F%A4%97%20Hugging%20Face-Model-blue'></a> <a target="_blank" href="https://huggingface.co/spaces/nowsyn/StyleShot"> <img src="https://yellow-cdn.veclightyear.com/835a84d5/29cd0853-7e2e-464d-9d8d-62a412d8e27f.svg" alt="Online Demo in HF"/> </a>
高俊尧, 刘彦辰, 孙亚楠<sup>‡</sup>, 唐寅豪, 曾艳红, 陈凯*, 赵彩荣* <br><br> (* 通讯作者, <sup>‡</sup> 项目负责人)
来自同济大学和上海人工智能实验室。
</div>摘要
在本文中,我们展示了一个好的风格表示对于无需测�试时调整的广义风格迁移至关重要且足够。我们通过构建一个风格感知编码器和一个组织良好的风格数据集StyleGallery来实现这一目标。通过专门设计用于风格学习,这个风格感知编码器经过解耦训练策略的训练,可以提取富有表现力的风格表示,而StyleGallery则赋予了泛化能力。我们还采用了一个内容融合编码器来增强图像驱动的风格迁移。我们强调,我们的方法StyleShot简单而有效,无需测试时调整即可模仿各种所需风格,如3D、平面、抽象甚至细粒度风格。严格的实验验证表明,与现有最先进的方法相比,StyleShot在广泛的风格范围内实现了卓越的性能。
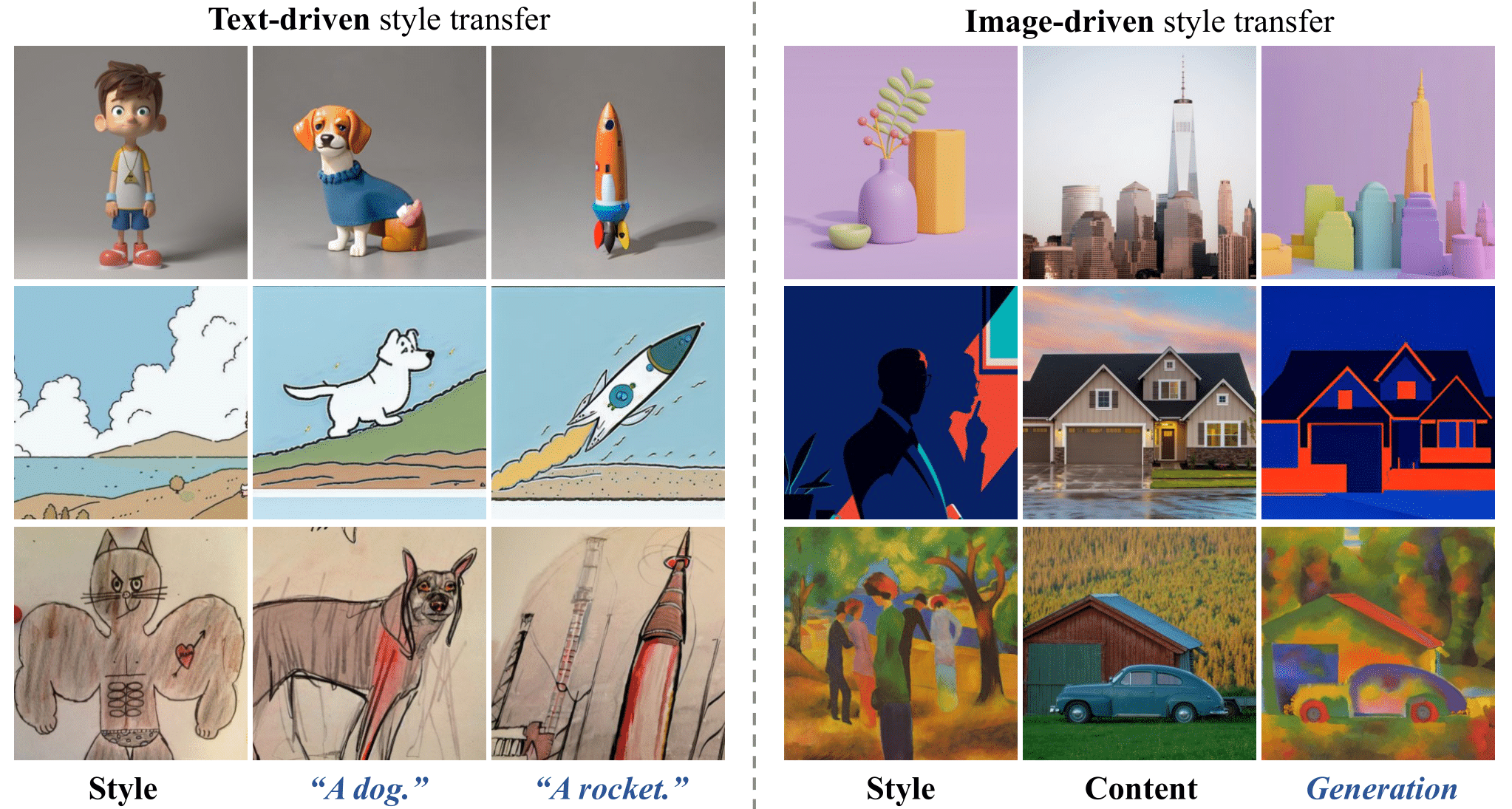
新闻
- [2024/7/5] 🔥 我们在HuggingFace上发布了在线演示。
- [2024/7/3] 🔥 我们发布了StyleShot_lineart,这是一个以内容图像的线稿作为控制的版本。
- [2024/7/2] 🔥 我们发布了论文。
- [2024/7/1] 🔥 我们发布了代码、检查点、项目页面和在线演示。
开始使用
# 安装styleshot
git clone https://github.com/Jeoyal/StyleShot.git
cd StyleShot
# 创建conda环境
conda create -n styleshot python==3.8
conda activate styleshot
pip install -r requirements.txt
# 下载模型
git lfs install
git clone https://huggingface.co/Gaojunyao/StyleShot
git clone https://huggingface.co/Gaojunyao/StyleShot_lineart
模型
你可以从这��里下载我们的预训练权重。要运行演示,你还需要下载以下模型:
推理
对于推理,你应该下载预训练权重并准备自己的参考风格图像或内容图像。
# 运行文本驱动的风格迁移演示
python styleshot_text_driven_demo.py --style "{风格图像路径}" --prompt "{提示词}" --output "{保存路径}"
# 运行图像驱动的风格迁移演示
python styleshot_image_driven_demo.py --style "{风格图像路径}" --content "{内容图像路径}" --preprocessor "Contour" --prompt "{提示词}" --output "{保存路径}"
# 将styleshot与controlnet和t2i-adapter集成
python styleshot_t2i-adapter_demo.py --style "{风格图像路径}" --condition "{条件图像路径}" --prompt "{提示词}" --output "{保存路径}"
python styleshot_controlnet_demo.py --style "{风格图像路径}" --condition "{条件图像路径}" --prompt "{提示词}" --output "{保存路径}"
- styleshot_text_driven_demo:基于参考风格图像和文本提示的文本驱动风格迁移。
- styleshot_image_driven_demo:基于参考风格图像和内容图像的图像驱动风格迁移。
- styleshot_controlnet_demo,styleshot_t2i-adapter_demo:与controlnet和t2i-adapter的集成。
训练
我们采用两阶段训练策略来训练我们的StyleShot,以更好地融合内容和风格。对于训练数据,您可以使用我们的训练数据集StyleGallery或将自己的数据集制作成json文件。
# 训练阶段1,仅训练风格组件。
accelerate launch --num_processes 8 --multi_gpu --mixed_precision "fp16" \
tutorial_train_styleshot_stage_1.py \
--pretrained_model_name_or_path="runwayml/stable-diffusion-v1-5/" \
--image_encoder_path="{图像编码器路径}" \
--image_json_file="{data.json}" \
--image_root_path="{图像路径}" \
--mixed_precision="fp16" \
--resolution=512 \
--train_batch_size=16 \
--dataloader_num_workers=4 \
--learning_rate=1e-04 \
--weight_decay=0.01 \
--output_dir="{输出目录}" \
--save_steps=10000
# 训练阶段2,仅训练内容组件。
accelerate launch --num_processes 8 --multi_gpu --mixed_precision "fp16" \
tutorial_train_styleshot_stage_2.py \
--pretrained_model_name_or_path="runwayml/stable-diffusion-v1-5/" \
--pretrained_ip_adapter_path="./pretrained_weight/ip.bin" \
--pretrained_style_encoder_path="./pretrained_weight/style_aware_encoder.bin" \
--image_encoder_path="{图像编码器路径}" \
--image_json_file="{data.json}" \
--image_root_path="{图像路径}" \
--mixed_precision="fp16" \
--resolution=512 \
--train_batch_size=16 \
--dataloader_num_workers=4 \
--learning_rate=1e-04 \
--weight_decay=0.01 \
--output_dir="{输出目录}" \
--save_steps=10000
StyleGallery<a name="style_gallery"></a>
我们精心策划了一个风格平衡的数据集,称为StyleGallery,其中包含从公开可用数据集中提取的广泛多样的图像风格,用于训练我们的StyleShot。 要准备我们的数据集StyleGallery,请参考教程,或从这里下载json文件。
StyleBench
为解决基于参考的风格化生成缺乏基准的问题,我们建立了一个<a href='https://drive.google.com/file/d/1I-Zv5blsrJsckXrvcP_f8TJ4gy6xrwCA/view?usp=drive_link'>风格评估基准</a>,包含490个参考图像中的73种不同风格。
免责声明
我们开发此仓库用于研究目的,因此它只能用于个人/研究/非商业用途。
引用
如果您发现StyleShot对您的研究和应用有用,请使用以下BibTeX进行引用:
@article{gao2024styleshot, title={StyleShot: A Snapshot on Any Style}, author={Junyao, Gao and Yanchen, Liu and Yanan, Sun and Yinhao, Tang and Yanhong, Zeng and Kai, Chen and Cairong, Zhao}, booktitle={arXiv preprint arxiv:2407.01414}, year={2024} }
致谢
该代码基于<a href='https://github.com/tencent-ailab/IP-Adapter'>IP-Adapter</a>构建。
编辑推荐精选


Pixmax
一站式AI短剧创作平台
Pixmax专注打造下一��代“ AI 视觉创作引擎”,整合行业顶尖 AI 大模型、工工业级精准控制及企业级协同管理功能,是全方位的 AI 内容创作平台。


豆包
字节跳动旗下 AI 智能助手
字节跳动旗下 AI 智能助手


GPT Plus|Pro充值
GPT充值
支持 ChatGPT Plus / Pro 充值服务,支付便捷,自动发货,售后可查。


GPT Image 2中文站
AI 图片生成平台
GPT Image 2 是面向用户的 AI 图片生成平台,支持文生图、图生图及多模型创意工作流�。


Vecbase
你的AI Agent团队
Vecbase 是专为 AI 团队打造的智能工作空间,将数据管理、模型协作与知识沉淀整合于一处。算法、产品与业务在同一平台无缝协同,让从数据到 AI 应用的落地更快一步。


音述AI
全球首个AI音乐社区
音述AI是全球首个AI音乐社区,致力让每个人都能用音乐表达自我。音述AI提供零门槛AI创作工具,独创GETI法则帮助用户精准定义音乐风格,AI润色功能支持自动优化作品质感。音述AI支持交流讨论、二次创作与价值变现。针对中文用户的语言习惯与文化背景进行专门优化,支持国风融合、C-pop等本土音乐标签,让技术更好地承载人文表达。


QoderWork
阿里Qoder团队推出的桌面端AI智能体
QoderWork 是阿里推出的本地优先桌面 AI 智能体,适配 macOS14+/Windows10+,以自然语言交互实现文件管理、数据分析、AI 视觉生成、浏览器自动化等办公任务,自主拆解执行复杂工作流,数据本地运行零上传,技能市场可无限扩展,是高效的 Agentic 生产力办公助手。


lynote.ai
一站式搞定所有学习需求
不再被海量信息淹没,开始真正理解知识。Lynote 可摘要 YouTube 视频、PDF、文章等内容。即时创建笔记,检测 AI 内容并下载资料,将您的学习效率提升 10 倍。


AniShort
为AI短剧协作而生
专为AI短剧协作而生的AniShort正式发布,深度重构AI短剧全流程生产模式,整合创意策划、制作执行、实时协作、在线审片、资产复用等全链路功能,独创无限画布、双轨并行工业化工作流与Ani智能体助手,集成多款主流AI大模型,破解素材零散、版本混乱、沟通低效等行业痛点,助力3人团队效率提升800%,打造标准化、可追溯的AI短剧量产体系,是AI短剧团队协同创作、提升制作效率的核心工具。


seedancetwo2.0
能听懂你表达的视频模型
Seedance two是基于seedance2.0的中国大模型,支持图像、视频、音频、文本四种模态输入,表达方式更丰富,生成也更可控。
推荐工具精选






AI云服务特惠
懂AI专属折扣关注微信公众号
最新AI工具、AI资讯
独家AI资源、AI项目落地

微信扫一扫关注公众号