


Prometheus ValKey 和 Redis 指标导出器





用于ValKey指标(与Redis兼容)的Prometheus导出器。
支持ValKey和Redis 2.x、3.x、4.x、5.x、6.x和7.x版本
乌克兰仍在遭受俄罗斯侵略,请考虑通过捐款支持乌克兰。

构建和运行导出器
本地构建和运行
git clone https://github.com/oliver006/redis_exporter.git cd redis_exporter go build . ./redis_exporter --version
预构建二进制文件
预构建的二进制文件请查看发布页面。
基本Prometheus配置
在prometheus.yml配置文件的scrape_configs中添加以下块:
scrape_configs: - job_name: redis_exporter static_configs: - targets: ['<<REDIS-EXPORTER-HOSTNAME>>:9121']
并相应调整主机名。
Kubernetes SD配置
为了在下拉列表中显示人类可读的实例名称而不是IP地址,建议使用实例重新标记。
例如,如果通过pod角色抓取指标,可以添加:
- source_labels: [__meta_kubernetes_pod_name] action: replace target_label: instance regex: (.*redis.*)
作为相应抓取配置的重新标记配置。根据正则表达式值,只有名称中包含"redis"的pod才会被重新标记。
根据如何检索抓取目标,可以采用类似的方法处理其他角色类型。
抓取多个Redis主机的Prometheus配置
Prometheus文档中有一篇非常有用的文章,介绍了多目标导出器的工作原理。
使用命令行标志--redis.addr=运行导出器,这样每次抓取/metrics端点时就不会尝试访问本地实例。使用以下配置,Prometheus将使用/scrape端点而不是/metric端点。例如,第一个目标将通过以下Web请求查询:
http://exporterhost:9121/scrape?target=first-redis-host:6379
scrape_configs: ## 导出器将抓取的多个Redis目标的配置 - job_name: 'redis_exporter_targets' static_configs: - targets: - redis://first-redis-host:6379 - redis://second-redis-host:6379 - redis://second-redis-host:6380 - redis://second-redis-host:6381 metrics_path: /scrape relabel_configs: - source_labels: [__address__] target_label: __param_target - source_labels: [__param_target] target_label: instance - target_label: __address__ replacement: <<REDIS-EXPORTER-HOSTNAME>>:9121 ## 抓取导出器本身的配置 - job_name: 'redis_exporter' static_configs: - targets: - <<REDIS-EXPORTER-HOSTNAME>>:9121
Redis实例列在targets下,Redis导出器主机名通过最后一个relabel_config规则配置。
如果Redis实例需要身份验证,可以通过导出器的--redis.password命令行选项设置密码(这意味着目前只能在尝试以这种方式抓取的实例中使用一个密码。如果这是个问�题,请使用多个导出器)。
您还可以使用json文件通过file_sd_configs提供多个目标,如下所示:
scrape_configs: - job_name: 'redis_exporter_targets' file_sd_configs: - files: - targets-redis-instances.json metrics_path: /scrape relabel_configs: - source_labels: [__address__] target_label: __param_target - source_labels: [__param_target] target_label: instance - target_label: __address__ replacement: <<REDIS-EXPORTER-HOSTNAME>>:9121 ## 抓取导出器本身的配置 - job_name: 'redis_exporter' static_configs: - targets: - <<REDIS-EXPORTER-HOSTNAME>>:9121
targets-redis-instances.json应该类似这样:
[ { "targets": [ "redis://redis-host-01:6379", "redis://redis-host-02:6379"], "labels": { } } ]
Prometheus使用文件监视,对json文件的所有更改都会立即应用。
命令行标志
| 名称 | 环境变量名 | 描述 |
|---|---|---|
| redis.addr | REDIS_ADDR | Redis实例的地址,默认为redis://localhost:6379。如果启用了TLS,地址必须类似于rediss://localhost:6379 |
| redis.user | REDIS_USER | 用于身份验证的用户名(Redis 6.0及更新版本的Redis ACL) |
| redis.password | REDIS_PASSWORD | Redis实例的密码,默认为""(无密码) |
| redis.password-file | REDIS_PASSWORD_FILE | 要抓取的Redis实例的密码文件,默认为""(无密码文件) |
| check-keys | REDIS_EXPORTER_CHECK_KEYS | 用逗号分隔的键模式列表,用于导出值和长度/大小,例如:db3=user_count将从数据库3导出键user_count。如果省略db,默认为0。使用此选项指定的键模式将使用SCAN命令查找。如果需要使用glob模式匹配,请使用此选项;对于非模式键,check-single-keys更快。警告:使用--check-keys匹配大量键可能会减慢导出器的速度,以至于无法完成对Redis实例的抓取 |
| check-single-keys | REDIS_EXPORTER_CHECK_SINGLE_KEYS | 用逗号分隔的键列表,用于导出值和长度/大小,例如:db3=user_count将从数据库3导出键user_count。如果省略db,默认为0。使用此标志指定的键将直接查找,不进行任何glob模式匹配。如果不需要glob模式匹配,请使用此选项;它比check-keys更快 |
| check-streams | REDIS_EXPORTER_CHECK_STREAMS | 用逗号分隔的流模式列表,用于导出有关流、组和消费者的信息。语法与check-keys相同 |
| check-single-streams | REDIS_EXPORTER_CHECK_SINGLE_STREAMS | 用逗号分隔的流列表,用于导出有关流、组和消费者的信息。使用此标志指定的流将直接查找,不进行任何glob模式匹配。如果不需要glob模式匹配,请使用此选项;它比check-streams更快 |
| streams-exclude-consumer-metrics | REDIS_EXPORTER_STREAMS_EXCLUDE_CONSUMER_METRICS | 不收集流的每个消费者指标(减少指标数量和基数) |
| check-keys-batch-size | REDIS_EXPORTER_CHECK_KEYS_BATCH_SIZE | 每次执行处理的大约键数。这基本上是作为SCAN命令执行的一部分传入的COUNT选项,用于执行键或键组指标,参见COUNT选项。较大的值可加快扫描速度。但Redis是单线程应用,过大的COUNT可能会影响生产环境 |
| count-keys | REDIS_EXPORTER_COUNT_KEYS | 用逗号分隔的需要计数的模式列表,例如:db3=sessions:*将计算数据库3中所有前缀为sessions:的键。如果省略db,默认为0。警告:导出器运行SCAN来计数键。这可能在大型数据库上性能不佳 |
| script | REDIS_EXPORTER_SCRIPT | 用逗号分隔的Redis Lua脚本路径列表,用于收集额外的指标 |
| debug | REDIS_EXPORTER_DEBUG | 详细的调试输出 |
| log-format | REDIS_EXPORTER_LOG_FORMAT | 日志格式,有效选项为txt(默认)和json |
| namespace | REDIS_EXPORTER_NAMESPACE | 指标的命名空间,默认为redis |
| connection-timeout | REDIS_EXPORTER_CONNECTION_TIMEOUT | 连接Redis实例的超时时间,默认为"15s"(使用Golang时间格式) |
| web.listen-address | REDIS_EXPORTER_WEB_LISTEN_ADDRESS | Web界面和遥测监听的地址,默认为0.0.0.0:9121 |
| web.telemetry-path | REDIS_EXPORTER_WEB_TELEMETRY_PATH | 暴露指标的路径,默认为/metrics |
| redis-only-metrics | REDIS_EXPORTER_REDIS_ONLY_METRICS | 是否仅导出Redis指标而不包括Go运行时指标,默认为false |
| include-config-metrics | REDIS_EXPORTER_INCL_CONFIG_METRICS | 是否将所有配置设置作为指标包括在内,默认为false |
| include-system-metrics | REDIS_EXPORTER_INCL_SYSTEM_METRICS | 是否包括系统指标,如total_system_memory_bytes,默认为false |
| exclude-latency-histogram-metrics | REDIS_EXPORTER_EXCLUDE_LATENCY_HISTOGRAM_METRICS | 不尝试收集延迟直方图指标(以避免在Redis < v7上出现WARNING, LOGGED ONCE ONLY: cmd LATENCY HISTOGRAM错误) |
| redact-config-metrics | REDIS_EXPORTER_REDACT_CONFIG_METRICS | 是否隐藏包含潜在敏感信息(如密码)的配置设置 |
| ping-on-connect | REDIS_EXPORTER_PING_ON_CONNECT | 是否在连接后对Redis实例执行ping操作并将持续时间记录为指标,默认为false |
| is-tile38 | REDIS_EXPORTER_IS_TILE38 | 是否抓取Tile38特定的指标,默认为false |
| is-cluster | REDIS_EXPORTER_IS_CLUSTER | 这是否是一个Redis集群(如果需要在Redis集群上获取键级数据,请启用此选项) |
| export-client-list | REDIS_EXPORTER_EXPORT_CLIENT_LIST | 是否抓取客户端列表特定的指标,默认为false |
| export-client-port | REDIS_EXPORTER_EXPORT_CLIENT_PORT | 导出客户端列表时是否包括客户端的端口。警告:包括端口会增加生成的指标数量,并使Prometheus服务器占用更多内存 |
| skip-tls-verification | REDIS_EXPORTER_SKIP_TLS_VERIFICATION | 导出器连接到Redis实例时是否跳过TLS验证 |
| tls-client-key-file | REDIS_EXPORTER_TLS_CLIENT_KEY_FILE | 如果服务器需要TLS客户端认证,客户端密钥文件的名称(包括完整路径) |
| tls-client-cert-file | REDIS_EXPORTER_TLS_CLIENT_CERT_FILE | 如果服务器需要TLS客户端认证,客户端证书文件的名称(包括完整路径) |
| tls-server-key-file | REDIS_EXPORTER_TLS_SERVER_KEY_FILE | 如果Web界面和遥测应使用TLS,服务器密钥文件的名称(包括完整路径) |
| tls-server-cert-file | REDIS_EXPORTER_TLS_SERVER_CERT_FILE | 如果Web界面和遥测应使用TLS,服务器证书文件的名称(包括完整路径) |
| tls-server-ca-cert-file | REDIS_EXPORTER_TLS_SERVER_CA_CERT_FILE | 如果Web界面和遥测应使用TLS,CA证书文件的名称(包括完整路径) |
| tls-server-min-version | REDIS_EXPORTER_TLS_SERVER_MIN_VERSION | Web界面和遥测使用TLS时可接受的最低TLS版本,默认为TLS1.2(支持TLS1.0、TLS1.1、TLS1.2、TLS1.3) |
| tls-ca-cert-file | REDIS_EXPORTER_TLS_CA_CERT_FILE | 如果服务器需要TLS客户端认证,则为CA证书文件的名称(包括完整路径) |
| set-client-name | REDIS_EXPORTER_SET_CLIENT_NAME | 是否将客户端名称设置为redis_exporter,默认为true |
| check-key-groups | REDIS_EXPORTER_CHECK_KEY_GROUPS | 用于将键分类到组的LUA正则表达式列表,以逗号分隔。这些正则表达式按指定顺序应用于各个键,组名由第一个匹配键的正则表达式的所有捕获组连接生成。如果没有指定的正则表达式匹配某个键,该键将被归类到"unclassified"组下 |
| max-distinct-key-groups | REDIS_EXPORTER_MAX_DISTINCT_KEY_GROUPS | 每个Redis数据库可以独立跟踪的不同键组的最大数量。如果超过此限制,只有内存消耗最高的键组会被单独跟踪(不超过设定的限制),所有剩余的键组将被归类到一个单一的"overflow"键组下进行跟踪 |
| config-command | REDIS_EXPORTER_CONFIG_COMMAND | 用于CONFIG命令的内容,默认为"CONFIG",设置为"-"可跳过配置指标提取 |
Redis 实例地址可以是 tcp 地址:如 redis://localhost:6379、redis.example.com:6379,或者 Unix 套接字:如 unix:///tmp/redis.sock。 | ||
通过使用 rediss:// 模式可以支持 SSL,例如:rediss://azure-ssl-enabled-host.redis.cache.windows.net:6380(注意,连接到非标准 6379 端口时需要指定端口,例如 Azure Redis 实例)。 |
命令行设置的优先级高于环境变量提供的任何配置。
与 Redis 进行身份验证
如果您的 Redis 实例需要身份验证,那么有几种方法可以提供用户名(Redis 6.x 中引入了 ACL)和密码。
您可以将用户名和密码作为地址的一部分提供,有关 redis:// 方案的官方文档请参见这里。
您可以设置 -redis.password-file=sample-pwd-file.json 来指定密码文件,每当导出器连接到 Redis 实例时都��会使用它,无论您是使用 /scrape 端点为多个实例还是使用正常的 /metrics 端点仅抓取一个实例。
它仅在 redis.password == "" 时生效。请参阅 contrib/sample-pwd-file.json 获取一个可用示例,并确保在密码文件条目中始终包含 redis://。
包含密码的 URI 示例为:redis://<<用户名(可选)>>:<<密码>>@<<主机名>>:<<端口>>
或者,您可以使用 --redis.user 和 --redis.password 直接向 redis_exporter 提供用户名和/或密码。
如果您想为 redis_exporter 使用专用的 Redis 用户(而不是默认用户),则需要为该用户启用一系列命令。
您可以使用以下 Redis 命令设置用户,只需将 <<<用户名>>> 和 <<<密码>>> 替换为您想要的值。
ACL SETUSER <<<用户名>>> -@all +@connection +memory -readonly +strlen +config|get +xinfo +pfcount -quit +zcard +type +xlen -readwrite -command +client -wait +scard +llen +hlen +get +eval +slowlog +cluster|info -hello -echo +info +latency +scan -reset -auth -asking ><<<密码>>>
要监控 Sentinel 节点,您可以使用以下带有正确 ACL 的命令:
ACL SETUSER <<<用户名>>> -@all +@connection -command +client -hello +info -auth +sentinel|masters +sentinel|replicas +sentinel|slaves +sentinel|sentinels +sentinel|ckquorum ><<<密码>>>
通过 Docker 运行
最新版本会自动发布到 Docker 注册表。
您可以像这样运行它:
docker run -d --name redis_exporter -p 9121:9121 oliver006/redis_exporter
Docker 镜像也发布到 quay.io docker 仓库,如果遇到 Docker hub 的速率限制问题,您可以从那里拉取它们。
docker run -d --name redis_exporter -p 9121:9121 quay.io/oliver006/redis_exporter
latest docker 镜像仅包含导出器二进制文件。
如果出于调试目的需要在具有 shell 的镜像中运行导出器,则可以运行 alpine 镜像:
docker run -d --name redis_exporter -p 9121:9121 oliver006/redis_exporter:alpine
如果您尝试访问主机节点上运行的 Redis 实例,则需要添加 --network host,以便 redis_exporter 容器可以访问它:
docker run -d --name redis_exporter --network host oliver006/redis_exporter
在 Kubernetes 上运行
这里是一个 Kubernetes 部署配置示例,说明如何将 redis_exporter 作为 Redis 实例的边车部署。
Tile38
Tile38 现在原生支持 Prometheus 导出服务器指标和对象、字符串等的基本统计信息。
您还可以使用 redis_exporter 导出 Tile38 指标,特别是通过使用 Lua 脚本或 -check-keys 标志导出更高级的指标。
要启用 Tile38 支持,请使用 --is-tile38=true 运行导出器。
导出的内容
INFO 命令中的大多数项目都被导出,详情请参阅 Redis 文档。
此外,对于每个数据库,都有关于总键数、过期键数和数据库中键的平均 TTL 的指标。
您还可以使用 -check-keys(或相关)标志导出键的值。导出器还将导出键的大小(或根据数据类型导出长度)。
这可用于导出(有序)集合、哈希、列表、流等中的元素数量。
如果键是字符串格式并与 --check-keys(或相关)匹配,则其字符串值将作为标签导出到 key_value_as_string 指标中。
如果您需要自定义指标收集,可以使用 -script 标志提供以逗号分隔的 Redis Lua 脚本 路径列表。如果您只传递一个脚本,可以省略逗号。contrib 文件夹中可以找到一个示例。
redis_memory_max_bytes 指标
redis_memory_max_bytes 指标将显示 Redis 可以使用的最大字节数。
如果您正在抓取的 Redis 实例未设置内存限制,则该值为零(这是 Redis 的默认设置)。
您可以通过检查 redis_config_maxmemory 指标是否为零来确认是否是这种情况,或者通过 redis-cli 连接到 Redis 实例并运行 CONFIG GET MAXMEMORY 命令来确认。
效果展示
Grafana 截图示例:
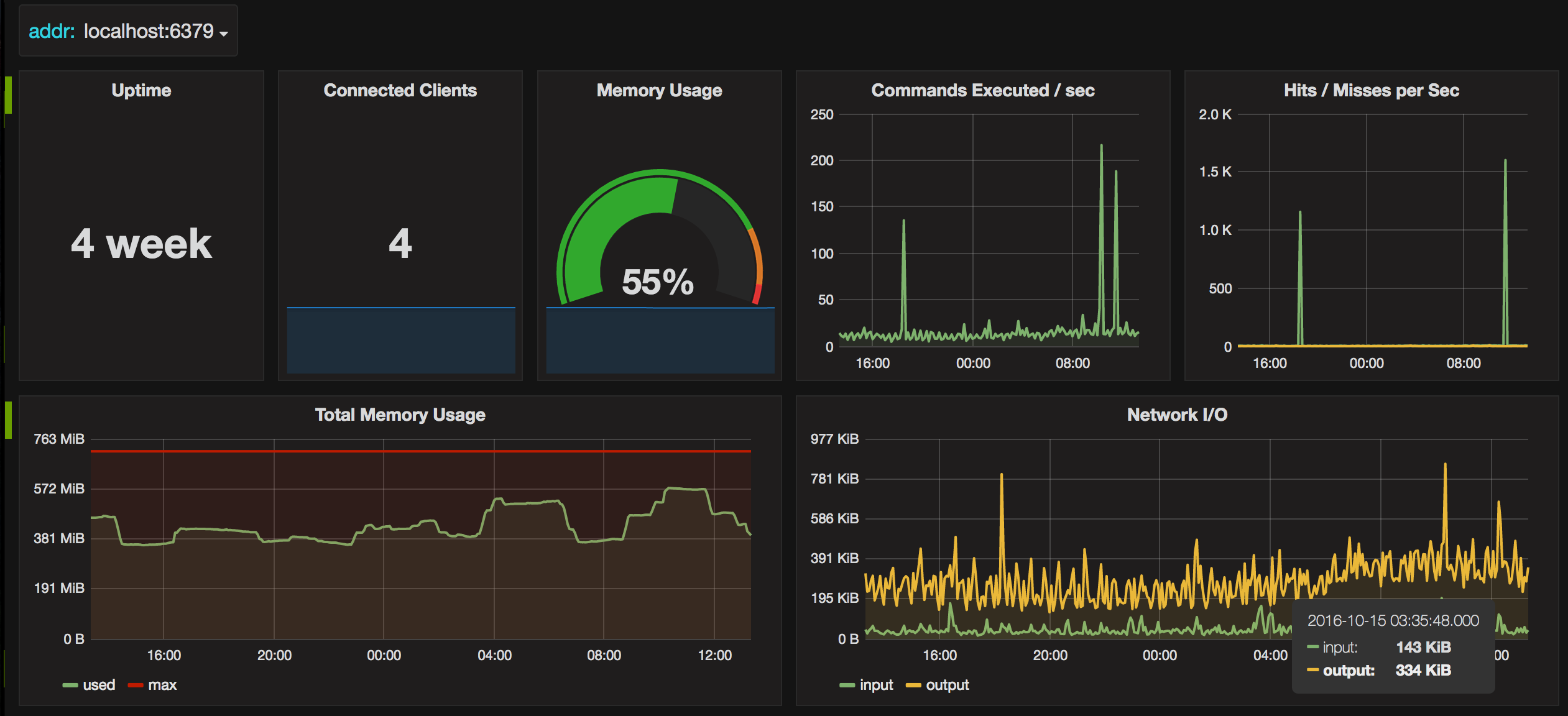
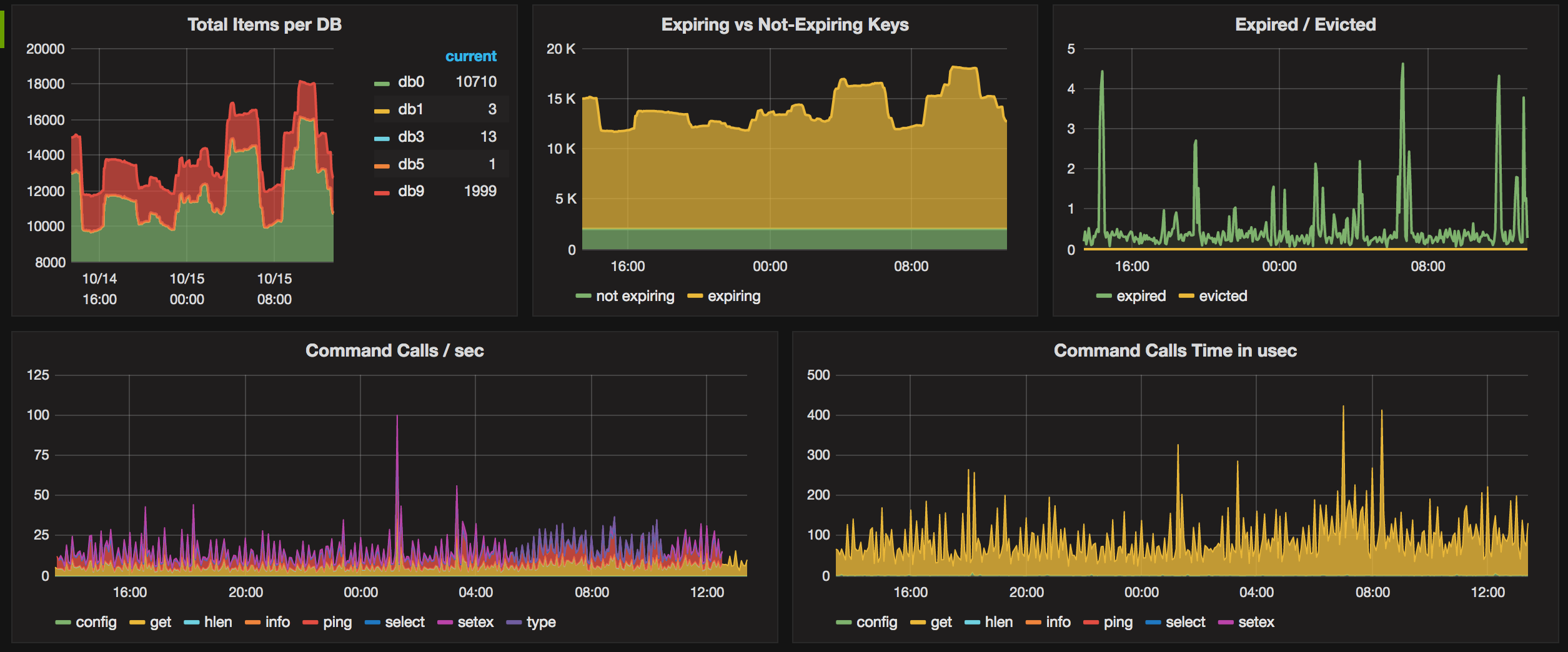
Grafana 仪表板可在 grafana.com 和/或 github.com 上获得。
同时查看多个 Redis
如果运行 Redis Sentinel,可能需要同时查看各个集群成员的指标。为此,仪表板的下拉菜单是多值类型的,允许选择多个 Redis。请注意,这里有一个注意事项;顶部的单一统计面板,即 正常运行时间、总内存使用量 和 客户端,在查看多个 Redis 时不起作用。
使用 mixin
redis-mixin 中提供了一组示例规则、警报和仪表板。
从 0.x 升级到 1.x
PR #256 引入了重大更改,这些更改作为版本 v1.0.0 发布。
如果你只抓取一个Redis实例并使用命令行标志--redis.address和--redis.password,那么你很可能不受影响�。
否则,请查看PR #256和这个README以获取更多信息。
按键组聚合内存使用
当一个Redis实例用于多个目的时,能够看到Redis内存如何在不同使用场景中消耗是很有用的。当一个没有驱逐策略的Redis实例内存不足时,这一点尤为重要,因为我们想确定是某些应用程序行为不当(例如没有删除不再使用的键)还是Redis实例需要扩容以应对增加的资源需求。幸运的是,大多数使用Redis的应用程序会为与其特定目的相关的键采用某种命名约定,如(层次化)命名空间前缀,这可以被redis_exporter的check-keys、check-single-keys和count-keys参数利用来显示特定场景的内存使用指标。按键组聚合内存使用更进一步,利用Redis LUA脚本支持的灵活性,通过用户定义的LUA正则表达式列表将Redis实例上的所有键分类到组中,从而可以将内存使用指标聚合到易于识别的组中。
要启用按键组聚合内存使用,只需通过redis_exporter参数check-key-groups指定一个非空的、逗号分隔的LUA正则表达式列表。在每次按键组聚合内存指标时,redis_exporter将为每个Redis数据库设置一个SCAN游标,通过LUA脚本分批处理所有键。然后,同一个LUA脚本会逐个处理每个键批次,如下所示:
- 调用
MEMORY USAGE命令收集每个键的内存使用情况 - 按指定顺序将指定的LUA正则表达式应用于每个键,给定键所属的组名将从第一个匹配该键的正则表达式的捕获组连接而成。例如,将正则表达式
^(.*)_[^_]+$应用于键key_exp_Nick将产生组名key_exp。如果没有指定的正则表达式匹配某个键,该键将被分配到unclassified组
一旦键被分类,相应组的内存使用和键计数器将在本地LUA表中递增。当一个批次中的所有键都被处理后,这个聚合的指标表将与下一个SCAN游标位置一起返回给redis_exporter,redis_exporter可以将所有批次的数据聚合成一个分组内存使用指标表,供Prometheus指标抓取器使用。
除了使LUA正则表达式的全部灵活性可用于将键分类到组中外,LUA脚本还有减少网络流量的好处,因为它在Redis服务器上执行所有MEMORY USAGE命令,并以比键级数据更紧凑的格式将聚合数据返回给redis_exporter。使用SCAN游标处理由服务器端LUA脚本处理的键批次也有助于防止Redis单一处理线程中出现无限延迟气泡,并且可以通过check-keys-batch-size参数根据特定环境调整批次大小。
扫描Redis实例的整个键空间可能听起来有点奢侈,但只需一次扫描就可以将所有键分类到组中,在一个中等规模的系统上,有约78万个键和一个相当复杂的17个正则表达式列表,完成一次按键组的内存使用聚合平均需要约5秒。当然,特定系统的实际性能会因总键数、用于分类的正则表达式的数量和复杂度以及配置的批次大小而有很大差异。
为了保护Prometheus不被配置错误的组分类正则表达式(例如应用正则表达式^(.*)$,其中每个键都将被分类到自己的不同组)导致的大量时间序列所淹没,可以通过max-distinct-key-groups参数配置每个Redis数据库的不同键组数量限制。如果超过max-distinct-key-groups限制,只有内存使用最高的键组将在限制内单独跟踪,剩余的键组将在一个单一的overflow键组下报告。
以下是启用按键组聚合内存使用时将暴�露的额外指标列表:
| 名称 | 标签 | 描述 |
|---|---|---|
| redis_key_group_count | db,key_group | 一个键组中的键数量 |
| redis_key_group_memory_usage_bytes | db,key_group | 按键组的内存使用 |
| redis_number_of_distinct_key_groups | db | 当overflow组完全展开时Redis数据库中不同键组的数量 |
| redis_last_key_groups_scrape_duration_milliseconds | 最后一次按键组聚合内存使用的持续时间(毫秒) |
收集Redis列表及其大小的脚本
如果使用Redis版本<4.0,通过默认的redis_exporter无法获取我们需要基于长度或内存收集的大多数有用指标。 借助LUA脚本,我们可以收集这些指标。 其中一个脚本contrib/collect_lists_length_growing.lua将帮助收集Redis列表的长度。 有了这个计数,我们可以采取以下行动,如在Grafana或任何类似工具中使用这些Prometheus指标创建警报或仪表板。
开发
测试需要各种真实的Redis实例,不仅为了验证导出器的正确性,还为了与旧版本的Redis以及类似Redis的系统(如KeyDB或Tile38)的兼容性。
contrib/docker-compose-for-tests.yml文件包含了所需的所有服务定义。
你可以先通过运行make docker-env-up启动Redis测试实例,然后每次想运行测试时,可以运行make docker-test。这将把当前目录(包含.go源文件)挂载到docker容器中并启动测试。
测试完成后,你可以通过运行make docker-env-down来关闭堆栈。
或者你可以通过运行make docker-all一次性启动堆栈、运行测试,然后关闭堆栈。
注意使用持久化测试环境时,测试初始化可能导致意外结果。当make docker-env-up执行一次,而make docker-test不断运行或在执行过程中停止时,数据库中的键数量会发生变化,这可能导致测试意外失败。作为临时解决方案,请定期使用make docker-env-down进行清理。
社区努力
如果你有更多建议、问题或关于添加内容的想法,请开启一个issue或PR。
编辑推荐精选


音述AI
全球首个AI音乐社区
音述AI是全球首个AI音乐社区,致力让每个人都能用音乐表达自�我。音述AI提供零门槛AI创作工具,独创GETI法则帮助用户精准定义音乐风格,AI润色功能支持自动优化作品质感。音述AI支持交流讨论、二次创作与价值变现。针对中文用户的语言习惯与文化背景进行专门优化,支持国风融合、C-pop等本土音乐标签,让技术更好地承载人文表达。


QoderWork
阿里Qoder团队推出的桌面端AI智能体
QoderWork 是阿里推出的本地优先桌面 AI 智能体,适配 macOS14+/Windows10+,以自然语言交互实现文件管理、数据分析、AI 视觉生成、浏览器自动化等办公任务,自主拆解执行复杂工作流,数据本地运行零上传,技能市场可无限扩展,是高效的 Agentic 生产力办公助手。


lynote.ai
一站式搞定所有学习需求
不再被海量信息淹没,开始真正理解知识。Lynote 可摘要 YouTube 视频、PDF、文章等内容。即时创建笔记,检测 AI 内容并下载资料,将您的学习效率提升 10 倍。


AniShort
为AI短剧协作而生
专为AI短剧协作而生的AniShort正式发布,深度重构AI短剧全流程生产模式,整合创意策划、制作执行、实时协作、在线审片、资产复用等全链路功能,独创无限画布、双轨并行工业化工作流与Ani智能体助手,集成多款主流AI大模型,破解素材零散、版本混乱、沟通低效等行业痛点,助力3人团队效率提升800%,打造标准化、可追溯的AI短剧量产体系,是AI短剧团队协同创作、提升制作效率的核心工具。


seedancetwo2.0
能听懂你表达的视频模型
Seedance two是基于seedance2.0的中国大模型,支持图像、视频、音频、文本四种模态输入,表达方式更丰富,生成也更可控。


nano-banana纳米香蕉中文站
国内直接访问,限时3折
输入简单文字,生成想要的图片,纳米香蕉中文站基于 Google 模型的 AI 图片生成网站,支持文字生图、图生图。官网价格限时3折活动


扣子-AI办公
职场AI,就用扣子
AI办公助手,复杂任务高效处理。办公效率低?扣子空间AI助手支持播客生成、PPT制作、网页开发及报告写作,覆盖科研、商业、舆情等领域的专家Agent 7x24小时响应,生活工作无缝切换,提升50%效率!


堆友
多风格AI绘画神器
堆友平台由阿里巴巴设计团队创建,作为一款AI驱动的设计工具,专为设计师提供一站式增长服务。功能覆盖海量3D素材、AI绘画、实时渲染以及专业抠图,显著提升设计品质和效率。平台不仅提供工具,还是一个促进创意交流和个人发展的空间,界面友好,适合所有级别的设计师和创意工作者。


码上飞
零代码AI应用开发平台
零代码AI应用开发平台,用户只需一句话简单描述需求,AI能自动生成小程序、APP或H5网页应用,无需编写代码。


Vora
免费创建高清无水印Sora视频
Vora是一个免费创建高清无水印Sora视频的AI工具
推荐工具精选





AI云服务特惠
懂AI专属折扣关注微信公众号
最新AI工具、AI资讯
独家AI资源、AI项目落地

微信扫一扫关注公众号