




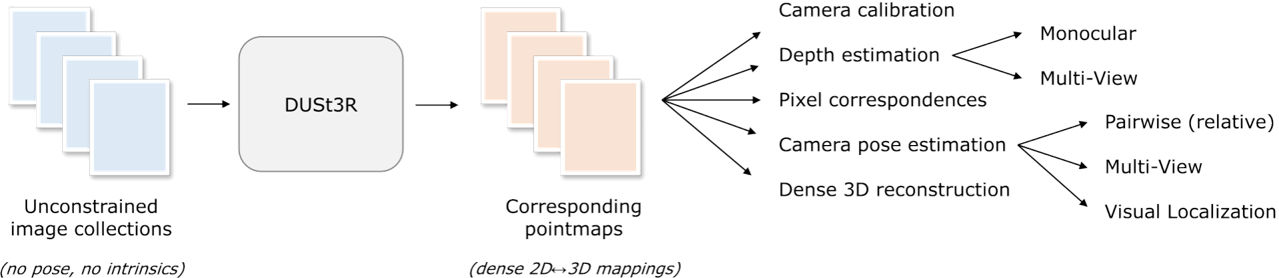
DUSt3R:简化几何3D视觉的官方实现
[项目页面], [DUSt3R arxiv]
请务必查看MASt3R:我们的新模型具有局部特征头、度量点图和更可扩展的全局对齐!

@inproceedings{dust3r_cvpr24, title={DUSt3R: Geometric 3D Vision Made Easy}, author={Shuzhe Wang and Vincent Leroy and Yohann Cabon and Boris Chidlovskii and Jerome Revaud}, booktitle = {CVPR}, year = {2024} } @misc{dust3r_arxiv23, title={DUSt3R: Geometric 3D Vision Made Easy}, author={Shuzhe Wang and Vincent Leroy and Yohann Cabon and Boris Chidlovskii and Jerome Revaud}, year={2023}, eprint={2312.14132}, archivePrefix={arXiv}, primaryClass={cs.CV} }
目录
许可证
该代码根据CC BY-NC-SA 4.0许可证分发。 有关更多信息,请参阅LICENSE。
# Copyright (C) 2024-present Naver Corporation. All rights reserved. # Licensed under CC BY-NC-SA 4.0 (non-commercial use only).
入门
安装
- 克隆DUSt3R。
git clone --recursive https://github.com/naver/dust3r cd dust3r # 如果你已经克隆了dust3r: # git submodule update --init --recursive
- 创建环境,这里我们展示使用conda的示例。
conda create -n dust3r python=3.11 cmake=3.14.0 conda activate dust3r conda install pytorch torchvision pytorch-cuda=12.1 -c pytorch -c nvidia # 为你的系统使用正确版本的cuda pip install -r requirements.txt # 可选:你还可以安装额外的包来: # - 添加对HEIC图像的支持 # - 添加pyrender,用于渲染某些数据集预处理中的深度图 # - 添加visloc.py所需的包 pip install -r requirements_optional.txt
- 可选,编译RoPE的cuda内核(如CroCo v2中所示)。
# DUST3R依赖RoPE位置嵌入,你可以为此编译一些cuda内核以提高��运行速度。 cd croco/models/curope/ python setup.py build_ext --inplace cd ../../../
检查点
你可以通过两种方式获取检查点:
-
你可以使用我们的huggingface_hub集成:模型将自动下载。
-
否则,我们提供了几个预训练模型:
| 模型名称 | 训练分辨率 | 头部 | 编码器 | 解码器 |
|---|---|---|---|---|
DUSt3R_ViTLarge_BaseDecoder_224_linear.pth | 224x224 | 线性 | ViT-L | ViT-B |
DUSt3R_ViTLarge_BaseDecoder_512_linear.pth | 512x384, 512x336, 512x288, 512x256, 512x160 | 线性 | ViT-L | ViT-B |
DUSt3R_ViTLarge_BaseDecoder_512_dpt.pth | 512x384, 512x336, 512x288, 512x256, 512x160 | DPT | ViT-L | ViT-B |
你可以在部分:我们的超参数中查看我们用于训练这些模型的超参数
要下载特定模型,例如DUSt3R_ViTLarge_BaseDecoder_512_dpt.pth:
mkdir -p checkpoints/ wget https://download.europe.naverlabs.com/ComputerVision/DUSt3R/DUSt3R_ViTLarge_BaseDecoder_512_dpt.pth -P checkpoints/
对于检查点,请确保同意我们使用的所有公共训练数据集和基础检查点的许可协议,以及CC-BY-NC-SA 4.0。再次说明,有关详细信息,请参见部分:我们的超参数。
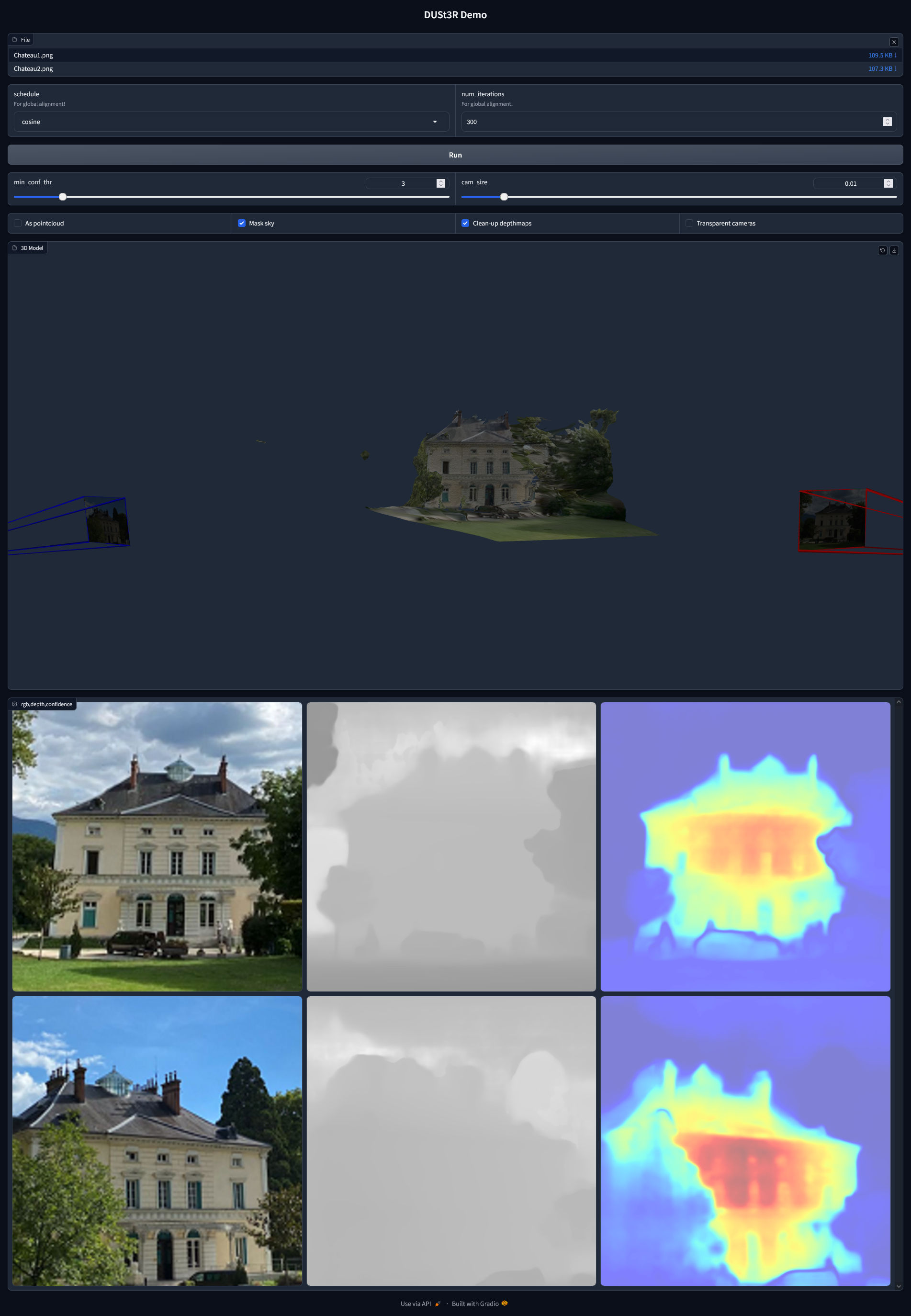
交互式演示
在这个演示中,你应该能够在你的机器上运行DUSt3R来重建场景。 首先选择描述同一场景的图像。
你可以调整全局对齐计划及其迭代次数。
[!注意] 如果你选择了一张或两张图像,全局对齐程序将被跳过(模式=GlobalAlignerMode.PairViewer)
点击"运行"并等待。 当全局对齐结束时,重建结果会出现。 使用滑块"min_conf_thr"来显示或移除低置信度区域。
python3 demo.py --model_name DUSt3R_ViTLarge_BaseDecoder_512_dpt # 使用--weights从本地文件加载检查点,例如 --weights checkpoints/DUSt3R_ViTLarge_BaseDecoder_512_dpt.pth # 使用--image_size为所选检查点选择正确的分辨率。512(默认)或224 # 使用--local_network使其在本地网络上可访问,或使用--server_name手动指定url # 使用--server_port更改端口,默认情况下它将从7860开始搜索可用端口 # 使用--device使用不同的设备,默认为"cuda"
使用Docker的交互式演示
要使用Docker运行DUSt3R(包括NVIDIA CUDA支持),请按照以下说明操作:
-
安装Docker:如果尚未安装,请从Docker网站下载并安装
docker和docker compose。 -
安装NVIDIA Docker工具包:为了支持GPU,请从Nvidia网站安装NVIDIA Docker工具包。
-
构建Docker镜像并运行:进入
./docker目录并运行以下命令:
cd docker bash run.sh --with-cuda --model_name="DUSt3R_ViTLarge_BaseDecoder_512_dpt"
或者如果你想在没有CUDA支持的情况下运行演示,运行以下命令:
cd docker bash run.sh --model_name="DUSt3R_ViTLarge_BaseDecoder_512_dpt"
默认情况下,demo.py以--local_network选项启动。
访问http://localhost:7860/以访问Web UI(或用机器名替换localhost以从网络访问)。
run.sh将使用docker-compose-cuda.yml或docker-compose-cpu.yml配置文件启动docker-compose,然后使用entrypoint.sh启动演示。
使用方法
from dust3r.inference import inference from dust3r.model import AsymmetricCroCo3DStereo from dust3r.utils.image import load_images from dust3r.image_pairs import make_pairs from dust3r.cloud_opt import global_aligner, GlobalAlignerMode if __name__ == '__main__': device = 'cuda' batch_size = 1 schedule = 'cosine' lr = 0.01 niter = 300 model_name = "naver/DUSt3R_ViTLarge_BaseDecoder_512_dpt" # 如果需要,你可以在model_name中放置本地检查点的路径 model = AsymmetricCroCo3DStereo.from_pretrained(model_name).to(device) # load_images可以接受图像列表或目录 images = load_images(['croco/assets/Chateau1.png', 'croco/assets/Chateau2.png'], size=512) pairs = make_pairs(images, scene_graph='complete', prefilter=None, symmetrize=True) output = inference(pairs, model, device, batch_size=batch_size) # 在这个阶段,你已经得到了原始的dust3r预测结果 view1, pred1 = output['view1'], output['pred1'] view2, pred2 = output['view2'], output['pred2'] # 这里,view1、pred1、view2、pred2是长度为2的列表字典 # -> 因为我们对称化了(im1, im2)和(im2, im1)对 # 在每个视图中你有: # 一个整数图像标识符: view1['idx'] 和 view2['idx'] # 图像: view1['img'] 和 view2['img'] # 图像形状: view1['true_shape'] 和 view2['true_shape'] # 数据加载器输出的实例字符串: view1['instance'] 和 view2['instance'] # pred1 和 pred2 包含置信度值: pred1['conf'] 和 pred2['conf'] # pred1 包含 view1['img'] 空间中 view1['img'] 的3D点: pred1['pts3d'] # pred2 包含 view1['img'] 空间中 view2['img'] 的3D点: pred2['pts3d_in_other_view'] # 接下来我们将使用global_aligner来对齐预测结果 # 根据你的任务,你可能对原始输出就满意了,不需要这一步 # 只有两个输入图像时,你可以使用GlobalAlignerMode.PairViewer: 它只会转换输出 # 如果使用GlobalAlignerMode.PairViewer,不需要运行compute_global_alignment scene = global_aligner(output, device=device, mode=GlobalAlignerMode.PointCloudOptimizer) loss = scene.compute_global_alignment(init="mst", niter=niter, schedule=schedule, lr=lr) # 从场景中检索有用的值: imgs = scene.imgs focals = scene.get_focals() poses = scene.get_im_poses() pts3d = scene.get_pts3d() confidence_masks = scene.get_masks() # 可视化重建结果 scene.show() # 在两张图像之间找到2D-2D匹配 from dust3r.utils.geometry import find_reciprocal_matches, xy_grid pts2d_list, pts3d_list = [], [] for i in range(2): conf_i = confidence_masks[i].cpu().numpy() pts2d_list.append(xy_grid(*imgs[i].shape[:2][::-1])[conf_i]) # imgs[i].shape[:2] = (H, W) pts3d_list.append(pts3d[i].detach().cpu().numpy()[conf_i]) reciprocal_in_P2, nn2_in_P1, num_matches = find_reciprocal_matches(*pts3d_list) print(f'找到 {num_matches} 个匹配') matches_im1 = pts2d_list[1][reciprocal_in_P2] matches_im0 = pts2d_list[0][nn2_in_P1][reciprocal_in_P2] # 可视化几个匹配 import numpy as np from matplotlib import pyplot as pl n_viz = 10 match_idx_to_viz = np.round(np.linspace(0, num_matches-1, n_viz)).astype(int) viz_matches_im0, viz_matches_im1 = matches_im0[match_idx_to_viz], matches_im1[match_idx_to_viz] H0, W0, H1, W1 = *imgs[0].shape[:2], *imgs[1].shape[:2] img0 = np.pad(imgs[0], ((0, max(H1 - H0, 0)), (0, 0), (0, 0)), 'constant', constant_values=0) img1 = np.pad(imgs[1], ((0, max(H0 - H1, 0)), (0, 0), (0, 0)), 'constant', constant_values=0) img = np.concatenate((img0, img1), axis=1) pl.figure() pl.imshow(img) cmap = pl.get_cmap('jet') for i in range(n_viz): (x0, y0), (x1, y1) = viz_matches_im0[i].T, viz_matches_im1[i].T pl.plot([x0, x1 + W0], [y0, y1], '-+', color=cmap(i / (n_viz - 1)), scalex=False, scaley=False) pl.show(block=True)

训练
在本节中,我们将展示一个简短的演示,以开始训练DUSt3R。
数据集
目前,我们添加了以下训练数据集:
- CO3Dv2 - 知识共享署名-非商业性使用 4.0 国际许可协议
- ARKitScenes - 知识共享署名-非商业性使用-相同方式共享 4.0
- ScanNet++ - 非商业研究和教育目的
- BlendedMVS - 知识共享署名 4.0 国际许可协议
- WayMo开放数据集 - 非商业用途
- Habitat-Sim
- MegaDepth
- StaticThings3D
- WildRGB-D
对于每个数据集,我们在datasets_preprocess目录中提供了一个预处理脚本,并在需要时提供了包含图像对列表的压缩包。
你需要自行从官方源下载数据集,同意其许可协议,下载我��们的图像对列表,并运行预处理脚本。
链接:
ARKitScenes图像对
ScanNet++图像对
BlendedMVS图像对
WayMo开放数据集图像对
Habitat元数据
MegaDepth图像对
StaticThings3D图像对
[!注意] 它们与用于训练DUSt3R的内容并不完全相同,但应该足够接近。
演示
对于这个训练演示,我们将下载并准备CO3Dv2的一个子集 - 知识共享署名-非商业性使用 4.0 国际许可协议,并在其上启动训练代码。 演示模型将在一个非常小的数据集上训练几个epoch。 它的效果不会很好。
# 下载并准备co3d子集 mkdir -p data/co3d_subset cd data/co3d_subset git clone https://github.com/facebookresearch/co3d cd co3d python3 ./co3d/download_dataset.py --download_folder ../ --single_sequence_subset rm ../*.zip cd ../../.. python3 datasets_preprocess/preprocess_co3d.py --co3d_dir data/co3d_subset --output_dir data/co3d_subset_processed --single_sequence_subset # 下载预训练的croco v2检查点 mkdir -p checkpoints/ wget https://download.europe.naverlabs.com/ComputerVision/CroCo/CroCo_V2_ViTLarge_BaseDecoder.pth -P checkpoints/ # dust3r的训练分为3个步骤。 # 在这个示例中,我们会减少训练轮数。关于我们在论文中使用的实际超参数,请参见下一节:"我们的超参数" # 步骤1 - 训练224分辨率的dust3r torchrun --nproc_per_node=4 train.py \ --train_dataset "1000 @ Co3d(split='train', ROOT='data/co3d_subset_processed', aug_crop=16, mask_bg='rand', resolution=224, transform=ColorJitter)" \ --test_dataset "100 @ Co3d(split='test', ROOT='data/co3d_subset_processed', resolution=224, seed=777)" \ --model "AsymmetricCroCo3DStereo(pos_embed='RoPE100', img_size=(224, 224), head_type='linear', output_mode='pts3d', depth_mode=('exp', -inf, inf), conf_mode=('exp', 1, inf), enc_embed_dim=1024, enc_depth=24, enc_num_heads=16, dec_embed_dim=768, dec_depth=12, dec_num_heads=12)" \ --train_criterion "ConfLoss(Regr3D(L21, norm_mode='avg_dis'), alpha=0.2)" \ --test_criterion "Regr3D_ScaleShiftInv(L21, gt_scale=True)" \ --pretrained "checkpoints/CroCo_V2_ViTLarge_BaseDecoder.pth" \ --lr 0.0001 --min_lr 1e-06 --warmup_epochs 1 --epochs 10 --batch_size 16 --accum_iter 1 \ --save_freq 1 --keep_freq 5 --eval_freq 1 \ --output_dir "checkpoints/dust3r_demo_224" # 步骤2 - 训练512分辨率的dust3r torchrun --nproc_per_node=4 train.py \ --train_dataset "1000 @ Co3d(split='train', ROOT='data/co3d_subset_processed', aug_crop=16, mask_bg='rand', resolution=[(512, 384), (512, 336), (512, 288), (512, 256), (512, 160)], transform=ColorJitter)" \ --test_dataset "100 @ Co3d(split='test', ROOT='data/co3d_subset_processed', resolution=(512,384), seed=777)" \ --model "AsymmetricCroCo3DStereo(pos_embed='RoPE100', patch_embed_cls='ManyAR_PatchEmbed', img_size=(512, 512), head_type='linear', output_mode='pts3d', depth_mode=('exp', -inf, inf), conf_mode=('exp', 1, inf), enc_embed_dim=1024, enc_depth=24, enc_num_heads=16, dec_embed_dim=768, dec_depth=12, dec_num_heads=12)" \ --train_criterion "ConfLoss(Regr3D(L21, norm_mode='avg_dis'), alpha=0.2)" \ --test_criterion "Regr3D_ScaleShiftInv(L21, gt_scale=True)" \ --pretrained "checkpoints/dust3r_demo_224/checkpoint-best.pth" \ --lr 0.0001 --min_lr 1e-06 --warmup_epochs 1 --epochs 10 --batch_size 4 --accum_iter 4 \ --save_freq 1 --keep_freq 5 --eval_freq 1 \ --output_dir "checkpoints/dust3r_demo_512" # 步骤3 - 使用dpt训练512分辨率的dust3r torchrun --nproc_per_node=4 train.py \ --train_dataset "1000 @ Co3d(split='train', ROOT='data/co3d_subset_processed', aug_crop=16, mask_bg='rand', resolution=[(512, 384), (512, 336), (512, 288), (512, 256), (512, 160)], transform=ColorJitter)" \ --test_dataset "100 @ Co3d(split='test', ROOT='data/co3d_subset_processed', resolution=(512,384), seed=777)" \ --model "AsymmetricCroCo3DStereo(pos_embed='RoPE100', patch_embed_cls='ManyAR_PatchEmbed', img_size=(512, 512), head_type='dpt', output_mode='pts3d', depth_mode=('exp', -inf, inf), conf_mode=('exp', 1, inf), enc_embed_dim=1024, enc_depth=24, enc_num_heads=16, dec_embed_dim=768, dec_depth=12, dec_num_heads=12)" \ --train_criterion "ConfLoss(Regr3D(L21, norm_mode='avg_dis'), alpha=0.2)" \ --test_criterion "Regr3D_ScaleShiftInv(L21, gt_scale=True)" \ --pretrained "checkpoints/dust3r_demo_512/checkpoint-best.pth" \ --lr 0.0001 --min_lr 1e-06 --warmup_epochs 1 --epochs 10 --batch_size 2 --accum_iter 8 \ --save_freq 1 --keep_freq 5 --eval_freq 1 --disable_cudnn_benchmark \ --output_dir "checkpoints/dust3r_demo_512dpt"
我们的超参数
以下是我们用于训练模型的命令:
# 注意:数据集的ROOT路径已省略 # 224 线性模型 torchrun --nproc_per_node 8 train.py \ --train_dataset=" + 100_000 @ Habitat(1_000_000, split='train', aug_crop=16, resolution=224, transform=ColorJitter) + 100_000 @ BlendedMVS(split='train', aug_crop=16, resolution=224, transform=ColorJitter) + 100_000 @ MegaDepth(split='train', aug_crop=16, resolution=224, transform=ColorJitter) + 100_000 @ ARKitScenes(aug_crop=256, resolution=224, transform=ColorJitter) + 100_000 @ Co3d(split='train', aug_crop=16, mask_bg='rand', resolution=224, transform=ColorJitter) + 100_000 @ StaticThings3D(aug_crop=256, mask_bg='rand', resolution=224, transform=ColorJitter) + 100_000 @ ScanNetpp(split='train', aug_crop=256, resolution=224, transform=ColorJitter) + 100_000 @ InternalUnreleasedDataset(aug_crop=128, resolution=224, transform=ColorJitter) " \ --test_dataset=" Habitat(1_000, split='val', resolution=224, seed=777) + 1_000 @ BlendedMVS(split='val', resolution=224, seed=777) + 1_000 @ MegaDepth(split='val', resolution=224, seed=777) + 1_000 @ Co3d(split='test', mask_bg='rand', resolution=224, seed=777) " \ --train_criterion="ConfLoss(Regr3D(L21, norm_mode='avg_dis'), alpha=0.2)" \ --test_criterion="Regr3D_ScaleShiftInv(L21, gt_scale=True)" \ --model="AsymmetricCroCo3DStereo(pos_embed='RoPE100', img_size=(224, 224), head_type='linear', output_mode='pts3d', depth_mode=('exp', -inf, inf), conf_mode=('exp', 1, inf), enc_embed_dim=1024, enc_depth=24, enc_num_heads=16, dec_embed_dim=768, dec_depth=12, dec_num_heads=12)" \ --pretrained="checkpoints/CroCo_V2_ViTLarge_BaseDecoder.pth" \ --lr=0.0001 --min_lr=1e-06 --warmup_epochs=10 --epochs=100 --batch_size=16 --accum_iter=1 \ --save_freq=5 --keep_freq=10 --eval_freq=1 \ --output_dir="checkpoints/dust3r_224" # 512 线性 torchrun --nproc_per_node 8 train.py \ --train_dataset=" + 10_000 @ Habitat(1_000_000, 分割='训练', 增强裁剪=16, 分辨率=[(512, 384), (512, 336), (512, 288), (512, 256), (512, 160)], 转换=颜色抖动) + 10_000 @ BlendedMVS(分割='训练', 增强裁剪=16, 分辨率=[(512, 384), (512, 336), (512, 288), (512, 256), (512, 160)], 转换=颜色抖动) + 10_000 @ MegaDepth(分割='训练', 增强裁剪=16, 分辨率=[(512, 384), (512, 336), (512, 288), (512, 256), (512, 160)], 转换=颜色抖动) + 10_000 @ ARKitScenes(增强裁剪=256, 分辨率=[(512, 384), (512, 336), (512, 288), (512, 256), (512, 160)], 转换=颜色抖动) + 10_000 @ Co3d(分割='训练', 增强裁剪=16, 背景遮罩='随机', 分辨率=[(512, 384), (512, 336), (512, 288), (512, 256), (512, 160)], 转换=颜色抖动) + 10_000 @ StaticThings3D(增强裁剪=256, 背景遮罩='随机', 分辨率=[(512, 384), (512, 336), (512, 288), (512, 256), (512, 160)], 转换=颜色抖动) + 10_000 @ ScanNetpp(分割='训练', 增强裁剪=256, 分辨率=[(512, 384), (512, 336), (512, 288), (512, 256), (512, 160)], 转换=颜色抖动) + 10_000 @ 内部未发布数据集(增强裁剪=128, 分辨率=[(512, 384), (512, 336), (512, 288), (512, 256), (512, 160)], 转换=颜色抖动) " \ --test_dataset=" Habitat(1_000, 分割='验证', 分辨率=(512,384), 随机种子=777) + 1_000 @ BlendedMVS(分割='验证', 分辨率=(512,384), 随机种子=777) + 1_000 @ MegaDepth(分割='验证', 分辨率=(512,336), 随机种子=777) + 1_000 @ Co3d(分割='测试', 分辨率=(512,384), 随机种子=777) " \ --train_criterion="置信度损失(三维回归(L21, 归一化模式='平均距离'), alpha=0.2)" \ --test_criterion="三维回归_尺度平移不变(L21, 真实尺度=True)" \ --model="非对称CroCo3D立体视觉(位置嵌入='RoPE100', 图像块嵌入类='多AR_图像块嵌入', 图像尺寸=(512, 512), 头部类型='线性', 输出模式='3D点', 深度模式=('指数', -inf, inf), 置信度模式=('指数', 1, inf), 编码器嵌入维度=1024, 编码器深度=24, 编码器头数=16, 解码器嵌入维度=768, 解码器深度=12, 解码器头数=12)" \ --pretrained="检查点/dust3r_224/最佳检查点.pth" \ --lr=0.0001 --min_lr=1e-06 --warmup_epochs=20 --epochs=100 --batch_size=4 --accum_iter=2 \ --save_freq=10 --keep_freq=10 --eval_freq=1 --print_freq=10 \ --output_dir="检查点/dust3r_512" # 512 dpt torchrun --nproc_per_node 8 train.py \ --train_dataset=" + 10_000 @ Habitat(1_000_000, 分割='训练', 增强裁剪=16, 分辨率=[(512, 384), (512, 336), (512, 288), (512, 256), (512, 160)], 转换=颜色抖动) + 10_000 @ BlendedMVS(分割='训练', 增强裁剪=16, 分辨率=[(512, 384), (512, 336), (512, 288), (512, 256), (512, 160)], 转换=颜色抖动) + 10_000 @ MegaDepth(分割='训练', 增强裁剪=16, 分辨率=[(512, 384), (512, 336), (512, 288), (512, 256), (512, 160)], 转换=颜色抖动) + 10_000 @ ARKitScenes(增强裁剪=256, 分辨率=[(512, 384), (512, 336), (512, 288), (512, 256), (512, 160)], 转换=颜色抖动) + 10_000 @ Co3d(分割='训练', 增强裁剪=16, 背景遮罩='随机', 分辨率=[(512, 384), (512, 336), (512, 288), (512, 256), (512, 160)], 转换=颜色抖动) + 10_000 @ StaticThings3D(增强裁剪=256, 背景遮罩='随机', 分辨率=[(512, 384), (512, 336), (512, 288), (512, 256), (512, 160)], 转换=颜色抖动) + 10_000 @ ScanNetpp(分割='训练', 增强裁剪=256, 分辨率=[(512, 384), (512, 336), (512, 288), (512, 256), (512, 160)], 转换=颜色抖动) + 10_000 @ 内部未发布数据集(增强裁剪=128, 分辨率=[(512, 384), (512, 336), (512, 288), (512, 256), (512, 160)], 转换=颜色抖动) " \ --test_dataset=" Habitat(1_000, 分割='验证', 分辨率=(512,384), 随机种子=777) + 1_000 @ BlendedMVS(分割='验证', 分辨率=(512,384), 随机种子=777) + 1_000 @ MegaDepth(分割='验证', 分辨率=(512,336), 随机种子=777) + 1_000 @ Co3d(分割='测试', 分辨率=(512,384), 随机种子=777) " \ --train_criterion="置信度损失(三维回归(L21, 归一化模式='平均距离'), alpha=0.2)" \ --test_criterion="三维回归_尺度平移不变(L21, 真实尺度=True)" \ --model="非对称CroCo3D立体视觉(位置嵌入='RoPE100', 图像块嵌入类='多AR_图像块嵌入', 图像尺寸=(512, 512), 头部类型='dpt', 输出模式='3D点', 深度模式=('指数', -inf, inf), 置信度模式=('指数', 1, inf), 编码器嵌入维度=1024, 编码器深度=24, 编码器头数=16, 解码器嵌入维度=768, 解码器深度=12, 解码器头数=12)" \ --pretrained="检查点/dust3r_512/最佳检查点.pth" \ --lr=0.0001 --min_lr=1e-06 --warmup_epochs=15 --epochs=90 --batch_size=4 --accum_iter=2 \ --save_freq=5 --keep_freq=10 --eval_freq=1 --print_freq=10 --disable_cudnn_benchmark \ --output_dir="检查点/dust3r_512dpt"
编辑推荐精选


GPT Plus|Pro充值
GPT充值
支持 ChatGPT Plus / Pro 充值服务,支付便捷,自动发货,售后可查。


GPT Image 2中文站
AI 图片生成平台
GPT Image 2 是面向用户的 AI 图片生成平台,支持文生图、图生图及多模型创意工作流。


Vecbase
你的AI Agent团队
Vecbase 是专为 AI 团队打造的智能工作空间,将数据管理、模型协作与知识沉淀整合于一处。算法、产品与业务在同一平台无缝协同,让从数据到 AI 应用的落地更快一步。


音述AI
全球首个AI音乐社区
音述AI是全球首个AI音乐社区,致力让每个人都能用音乐表达自我。音述AI提供零门槛AI创作工具,独创GETI法则帮助用户精准定义音乐风格,AI润色功能支持自动优化作品质感。音述AI支持交流讨论、二次创作与价值变现。针对中文用户的语言习惯与文化背景进行专门优化,支持国风融合、C-pop等本土音乐标签,让技术更好地承载人文表达。


QoderWork
阿里Qoder团队推出的桌面端AI智能体
QoderWork 是阿里推出的本地优先桌面 AI 智能体,适配 macOS14+/Windows10+,以自然语言交互实现文件管理、数据分析、AI 视觉生成、浏览器自动化等办公任务,自主拆解执行复杂工作流,数据本地运行零上传,技能市场可无限扩展,是高效的 Agentic 生产力办公助手。


lynote.ai
一站式搞定所有学习需求
不再被海量信息淹没,开始真正理解知识。Lynote 可摘要 YouTube 视频、PDF、文章等内容。即时创建笔记,检测 AI 内容并下载资料,将您的学习效率提升 10 倍。


AniShort
为AI短剧协作而生
专为AI短剧协作而生的AniShort正式发布,深度重构AI短剧全流程生产模式,整合创意策划、制作执行、实时协作、在线审片、资产复用等全链路功能,独创无限画布、双轨并行工业化工作流与Ani智能体助手,集成多款主流AI大模型,破解素材零散、版本混乱、沟通低效等行业痛点,助力3人团队效率提升800%,打造标准化、可追溯的AI短剧量产体系,是AI短剧团队协同创作、提升制作效率的核心工具。


seedancetwo2.0
能听懂你表达的视频模型
Seedance two是基于seedance2.0的中国大模型,支持图像、视频、音频、文本四种模态输入,表达方式更丰富,生成也更可控。


nano-banana纳米香蕉中文站
国内直接访问,限时3折
输入简单文字,生成想要的图片,纳米香蕉中文站基于 Google 模型的 AI 图片生成网站,支持文字生图、图生图。官网价格限时3折活动


扣子-AI办公
职场AI,就用扣子
AI办公助手,复杂任务高效处理。办公效率低?扣子空间AI助手支持播客生成、PPT制作、网页开发及报告写作,覆盖科研、商业、舆情等领域的专家Agent 7x24小时响应,生活工作无缝切换,提升50%效率!
推荐工具精选





AI云服务特惠
懂AI专属折扣关注微信公众号
最新AI工具、AI资讯
独家AI资源、AI项目落地

微信扫一扫关注公众号