


sdwebuiapi
API client for AUTOMATIC1111/stable-diffusion-webui
Supports txt2img, img2img, extra-single-image, extra-batch-images API calls.
API support have to be enabled from webui. Add --api when running webui. It's explained here.
You can use --api-auth user1:pass1,user2:pass2 option to enable authentication for api access. (Since it's basic http authentication the password is transmitted in cleartext)
API calls are (almost) direct translation from http://127.0.0.1:7860/docs as of 2022/11/21.
Install
pip install webuiapi
Usage
webuiapi_demo.ipynb contains example code with original images. Images are compressed as jpeg in this document.
create API client
import webuiapi
# create API client
api = webuiapi.WebUIApi()
# create API client with custom host, port
#api = webuiapi.WebUIApi(host='127.0.0.1', port=7860)
# create API client with custom host, port and https
#api = webuiapi.WebUIApi(host='webui.example.com', port=443, use_https=True)
# create API client with default sampler, steps.
#api = webuiapi.WebUIApi(sampler='Euler a', steps=20)
# optionally set username, password when --api-auth=username:password is set on webui.
# username, password are not protected and can be derived easily if the communication channel is not encrypted.
# you can also pass username, password to the WebUIApi constructor.
api.set_auth('username', 'password')
txt2img
result1 = api.txt2img(prompt="cute squirrel",
negative_prompt="ugly, out of frame",
seed=1003,
styles=["anime"],
cfg_scale=7,
# sampler_index='DDIM',
# steps=30,
# enable_hr=True,
# hr_scale=2,
# hr_upscaler=webuiapi.HiResUpscaler.Latent,
# hr_second_pass_steps=20,
# hr_resize_x=1536,
# hr_resize_y=1024,
# denoising_strength=0.4,
)
# images contains the returned images (PIL images)
result1.images
# image is shorthand for images[0]
result1.image
# info contains text info about the api call
result1.info
# info contains paramteres of the api call
result1.parameters
result1.image

img2img
result2 = api.img2img(images=[result1.image], prompt="cute cat", seed=5555, cfg_scale=6.5, denoising_strength=0.6)
result2.image

img2img inpainting
from PIL import Image, ImageDraw
mask = Image.new('RGB', result2.image.size, color = 'black')
# mask = result2.image.copy()
draw = ImageDraw.Draw(mask)
draw.ellipse((210,150,310,250), fill='white')
draw.ellipse((80,120,160,120+80), fill='white')
mask
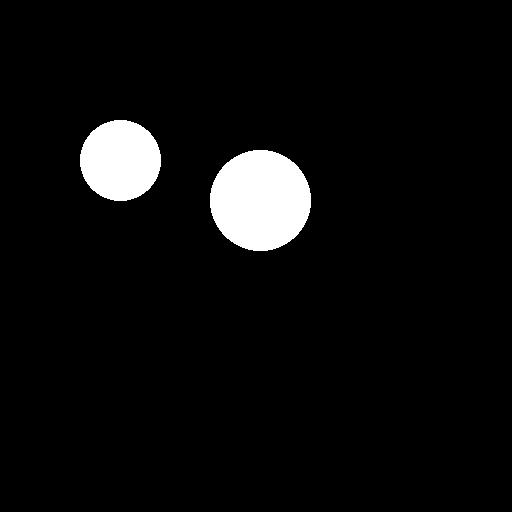
inpainting_result = api.img2img(images=[result2.image],
mask_image=mask,
inpainting_fill=1,
prompt="cute cat",
seed=104,
cfg_scale=5.0,
denoising_strength=0.7)
inpainting_result.image

extra-single-image
result3 = api.extra_single_image(image=result2.image,
upscaler_1=webuiapi.Upscaler.ESRGAN_4x,
upscaling_resize=1.5)
print(result3.image.size)
result3.image
(768, 768)

extra-batch-images
result4 = api.extra_batch_images(images=[result1.image, inpainting_result.image],
upscaler_1=webuiapi.Upscaler.ESRGAN_4x,
upscaling_resize=1.5)
result4.images[0]

result4.images[1]

Async API support
txt2img, img2img, extra_single_image, extra_batch_images support async api call with use_async=True parameter. You need asyncio, aiohttp packages installed.
result = await api.txt2img(prompt="cute kitten",
seed=1001,
use_async=True
)
result.image
Scripts support
Scripts from AUTOMATIC1111's Web UI are supported, but there aren't official models that define a script's interface.
To find out the list of arguments that are accepted by a particular script look up the associated python file from
AUTOMATIC1111's repo scripts/[script_name].py. Search for its run(p, **args) function and the arguments that come
after 'p' is the list of accepted arguments
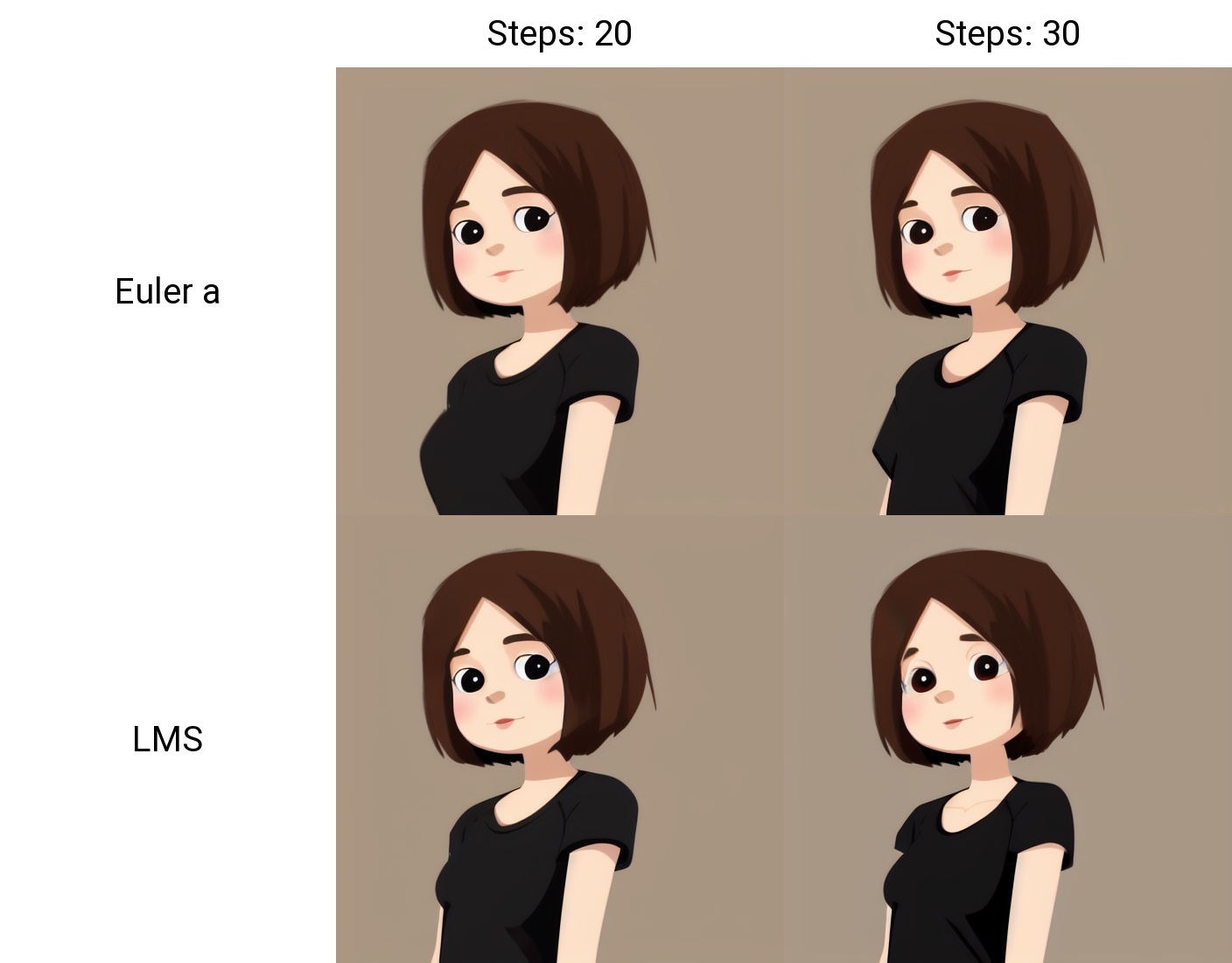
Example for X/Y/Z Plot script:
(scripts/xyz_grid.py file from AUTOMATIC1111's repo)
def run(self, p, x_type, x_values, y_type, y_values, z_type, z_values, draw_legend, include_lone_images, include_sub_grids, no_fixed_seeds, margin_size):
...
List of accepted arguments:
- x_type: Index of the axis for X axis. Indexes start from [0: Nothing]
- x_values: String of comma-separated values for the X axis
- y_type: Index of the axis type for Y axis. As the X axis, indexes start from [0: Nothing]
- y_values: String of comma-separated values for the Y axis
- z_type: Index of the axis type for Z axis. As the X axis, indexes start from [0: Nothing]
- z_values: String of comma-separated values for the Z axis
- draw_legend: "True" or "False". IMPORTANT: It needs to be a string and not a Boolean value
- include_lone_images: "True" or "False". IMPORTANT: It needs to be a string and not a Boolean value
- include_sub_grids: "True" or "False". IMPORTANT: It needs to be a string and not a Boolean value
- no_fixed_seeds: "True" or "False". IMPORTANT: It needs to be a string and not a Boolean value
- margin_size: int value
# Available Axis options (Different for txt2img and img2img!)
XYZPlotAvailableTxt2ImgScripts = [
"Nothing",
"Seed",
"Var. seed",
"Var. strength",
"Steps",
"Hires steps",
"CFG Scale",
"Prompt S/R",
"Prompt order",
"Sampler",
"Checkpoint name",
"Sigma Churn",
"Sigma min",
"Sigma max",
"Sigma noise",
"Eta",
"Clip skip",
"Denoising",
"Hires upscaler",
"VAE",
"Styles",
]
XYZPlotAvailableImg2ImgScripts = [
"Nothing",
"Seed",
"Var. seed",
"Var. strength",
"Steps",
"CFG Scale",
"Image CFG Scale",
"Prompt S/R",
"Prompt order",
"Sampler",
"Checkpoint name",
"Sigma Churn",
"Sigma min",
"Sigma max",
"Sigma noise",
"Eta",
"Clip skip",
"Denoising",
"Cond. Image Mask Weight",
"VAE",
"Styles",
]
# Example call
XAxisType = "Steps"
XAxisValues = "20,30"
XAxisValuesDropdown = ""
YAxisType = "Sampler"
YAxisValues = "Euler a, LMS"
YAxisValuesDropdown = ""
ZAxisType = "Nothing"
ZAxisValues = ""
ZAxisValuesDropdown = ""
drawLegend = "True"
includeLoneImages = "False"
includeSubGrids = "False"
noFixedSeeds = "False"
marginSize = 0
# x_type, x_values, y_type, y_values, z_type, z_values, draw_legend, include_lone_images, include_sub_grids, no_fixed_seeds, margin_size
result = api.txt2img(
prompt="cute girl with short brown hair in black t-shirt in animation style",
seed=1003,
script_name="X/Y/Z Plot",
script_args=[
XYZPlotAvailableTxt2ImgScripts.index(XAxisType),
XAxisValues,
XAxisValuesDropdown,
XYZPlotAvailableTxt2ImgScripts.index(YAxisType),
YAxisValues,
YAxisValuesDropdown,
XYZPlotAvailableTxt2ImgScripts.index(ZAxisType),
ZAxisValues,
ZAxisValuesDropdown,
drawLegend,
includeLoneImages,
includeSubGrids,
noFixedSeeds,
marginSize, ]
)
result.image
Configuration APIs
# return map of current options
options = api.get_options()
# change sd model
options = {}
options['sd_model_checkpoint'] = 'model.ckpt [7460a6fa]'
api.set_options(options)
# when calling set_options, do not pass all options returned by get_options().
# it makes webui unusable (2022/11/21).
# get available sd models
api.get_sd_models()
# misc get apis
api.get_samplers()
api.get_cmd_flags()
api.get_hypernetworks()
api.get_face_restorers()
api.get_realesrgan_models()
api.get_prompt_styles()
api.get_artist_categories() # deprecated ?
api.get_artists() # deprecated ?
api.get_progress()
api.get_embeddings()
api.get_cmd_flags()
api.get_scripts()
api.get_schedulers()
api.get_memory()
# misc apis
api.interrupt()
api.skip()
Utility methods
# save current model name
old_model = api.util_get_current_model()
# get list of available models
models = api.util_get_model_names()
# get list of available samplers
api.util_get_sampler_names()
# get list of available schedulers
api.util_get_scheduler_names()
# refresh list of models
api.refresh_checkpoints()
# set model (use exact name)
api.util_set_model(models[0])
# set model (find closest match)
api.util_set_model('robodiffusion')
# wait for job complete
api.util_wait_for_ready()
LORA and alwayson_scripts example
r = api.txt2img(prompt='photo of a cute girl with green hair <lora:Moxin_10:0.6> shuimobysim __juice__',
seed=1000,
save_images=True,
alwayson_scripts={"Simple wildcards":[]} # wildcards extension doesn't accept more parameters.
)
r.image
Extension support - Model-Keyword
# https://github.com/mix1009/model-keyword
mki = webuiapi.ModelKeywordInterface(api)
mki.get_keywords()
ModelKeywordResult(keywords=['nousr robot'], model='robo-diffusion-v1.ckpt', oldhash='41fef4bd', match_source='model-keyword.txt')
Extension support - Instruct-Pix2Pix
# Instruct-Pix2Pix extension is now deprecated and is now part of webui.
# You can use normal img2img with image_cfg_scale when instruct-pix2pix model is loaded.
r = api.img2img(prompt='sunset', images=[pil_img], cfg_scale=7.5, image_cfg_scale=1.5)
r.image
Extension support - ControlNet
# https://github.com/Mikubill/sd-webui-controlnet
api.controlnet_model_list()
api.controlnet_version()
api.controlnet_module_list()
# normal txt2img
r = api.txt2img(prompt="photo of a beautiful girl with blonde hair", height=512, seed=100)
img = r.image
img

# txt2img with ControlNet
# input_image parameter is changed to image (change in ControlNet API)
unit1 = webuiapi.ControlNetUnit(image=img, module='canny', model='control_v11p_sd15_canny [d14c016b]')
r = api.txt2img(prompt="photo of a beautiful girl", controlnet_units=[unit1])
r.image

# img2img with multiple ControlNets
unit1 = webuiapi.ControlNetUnit(image=img, module='canny', model='control_v11p_sd15_canny [d14c016b]')
unit2 = webuiapi.ControlNetUnit(image=img, module='depth', model='control_v11f1p_sd15_depth [cfd03158]', weight=0.5)
r2 = api.img2img(prompt="girl",
images=[img],
width=512,
height=512,
controlnet_units=[unit1, unit2],
sampler_name="Euler a",
cfg_scale=7,
)
r2.image

r2.images[1]

r2.images[2]

r = api.controlnet_detect(images=[img], module='canny')
r.image
Extension support - AnimateDiff
# https://github.com/continue-revolution/sd-webui-animatediff
adiff = webuiapi.AnimateDiff(model='mm_sd15_v3.safetensors',
video_length=24,
closed_loop='R+P',
format=['GIF'])
r = api.txt2img(prompt='cute puppy', animatediff=adiff)
# save GIF file. need save_all=True to save animated GIF.
r.image.save('puppy.gif', save_all=True)
# Display animated GIF in Jupyter notebook
from IPython.display import HTML
HTML('<img src="data:image/gif;base64,{0}"/>'.format(r.json['images'][0]))
Extension support - RemBG (contributed by webcoderz)
# https://github.com/AUTOMATIC1111/stable-diffusion-webui-rembg
rembg = webuiapi.RemBGInterface(api)
r = rembg.rembg(input_image=img, model='u2net', return_mask=False)
r.image
Extension support - SegmentAnything (contributed by TimNekk)
# https://github.com/continue-revolution/sd-webui-segment-anything segment = webuiapi.SegmentAnythingInterface(api) # Perform a segmentation prediction
编辑推荐精选


音述AI
全球首个AI音乐社区
音述AI是全球首个AI音乐社区,致力让每个人都能用音乐表达自我。音述AI提供零门槛AI创作工具,独创GETI法则帮助用户精准定义音乐风格,AI润色功能支持自动优化作品质感。音述AI支持交流讨论、二次创作与价值变现。针对中文用户的语言习惯与文化背景进行专门优化,支持国风融合、C-pop等本土音乐标签,让技术更好地承载人文表达。


lynote.ai
一站式搞定所有学习需求
不再被海量信息淹没,开始真正理解知识。Lynote 可摘要 YouTube 视频、PDF、文章等内容。即时创建笔记,检测 AI 内容并下载资料,将您的学习效率提升 10 倍。


AniShort
为AI短剧协作而生
专为AI短剧协作而生的AniShort正式发布,深度重构AI短剧全流程生产模式,整合创意策划、制作执行、实时协作、在线审片、资产复用等全链路功能,独创无限画布、双轨并行工业化工作流与Ani智能体助手,集成多款主流AI大模型,破解素材零散、版本混乱、沟通低效等行业痛点,助力3人团队效率提升800%,打造标准化、可追溯的AI短剧量产体系,是AI短剧团队协同创作、提升制作效率的核心工具。


seedancetwo2.0
能听懂你表达的视频模型
Seedance two是基于seedance2.0的中国大模型,支持图像、视频、音频、文本四种模态输入,表达方式更丰富,生成也更可控。


nano-banana纳米香蕉中文站
国内直接访问,限时3折
输入简单文字,生成想要的图片,纳米香蕉中文站基于 Google 模型的 AI 图片生成网站,支持文字生图、图生图。官网价格限时3折活动


扣子-AI办公
职场AI,就用扣子
AI办公助手,复杂任务高效处理。办公效率低?扣子空间AI助手支持播客生成、PPT制作、网页开发及报告写作,覆盖科研、商业、舆情等领域的专家Agent 7x24小时响应,生活工作无缝切换,提升50%效率!


堆友
多风格AI绘画神器
堆友平台由阿里巴巴设计团队创建,作为一款AI驱动的设计工具,专为设计师提供一站式增长服务。功能覆盖海量3D素材、AI绘画、实时渲染以及专业抠图,显著提升设计品质和效率。平台不仅提供工具,还是一个促进创意交流和个人发展的空间,界面友好,适合所有级别的设计师和创意工作者。


码上飞
零代码AI应用开发平台
零代码AI应用开发平台,用户只需一句话简单描述需求,AI能自动生成小程序、APP或H5网页应用,无需编写代码。


Vora
免费创建高清无水印Sora视频
Vora是一个免费创建高清无水印Sora视频的AI工具


Refly.AI
最适合小白的AI自动化工作流平台
无需编码,轻松生成可复用、可变现的AI自动化工作流
推荐工具精选





AI云服务特惠
懂AI专属折扣关注微信公众号
最新AI工具、AI资讯
独家AI资源、AI项目落地

微信扫一扫关注公众号