




GAN 压缩
项目主页 | 论文 | 视频 | 幻灯片
[新消息!] GAN 压缩已被 T-PAMI 接收! 我们在 arXiv v4 发布了 T-PAMI 版本!
[新消息!] 我们发布了交互式演示的代码,并包含了用 TVM 调优的模型。现在在 Jetson Nano GPU 上可以达到 8FPS 的速度!
[新消息!] 新增对 MUNIT 的支持,这是一种多模态无监督图像到图像转换方法! 请按照测试命令测试预训练模型,并参考教程训练您自己的模型!
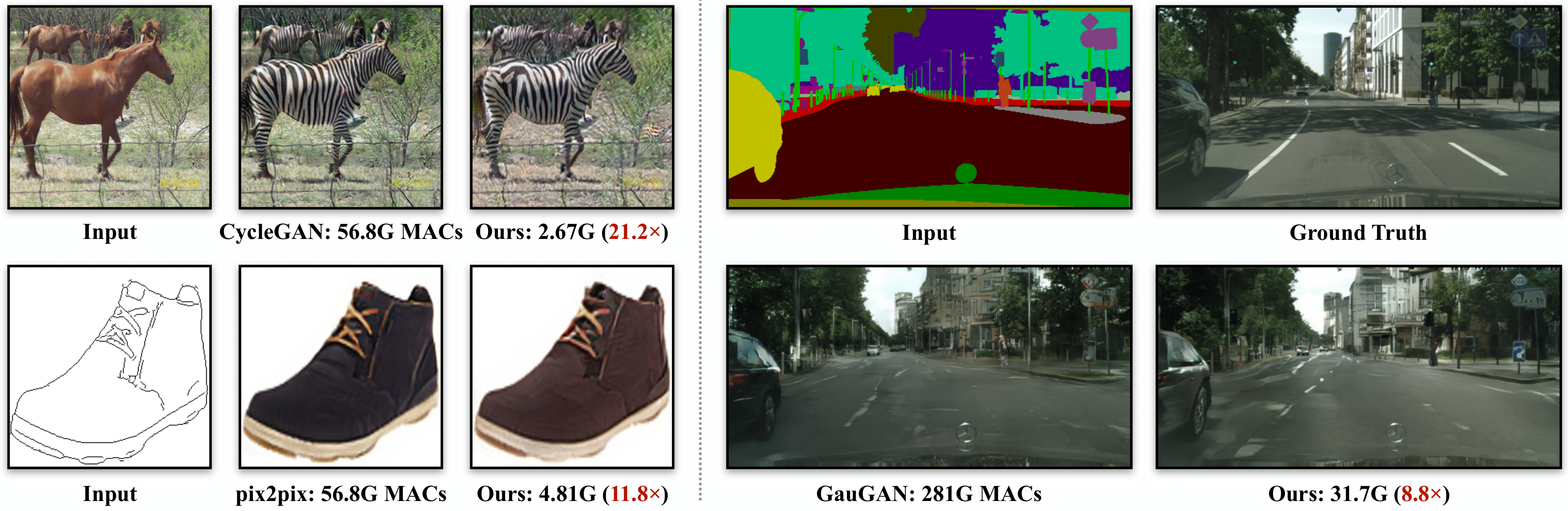 我们提出了 GAN 压缩,这是一种压缩条件 GAN 的通用方法。我们的方法可以将广泛使用的条件 GAN 模型(包括 pix2pix、CycleGAN、MUNIT 和 GauGAN)的计算量减少 9-29 倍,同时保持视觉保真度。我们的方法对各种生成器架构、学习目标以及配对和非配对设置都非常有效。
我们提出了 GAN 压缩,这是一种压缩条件 GAN 的通用方法。我们的方法可以将广泛使用的条件 GAN 模型(包括 pix2pix、CycleGAN、MUNIT 和 GauGAN)的计算量减少 9-29 倍,同时保持视觉保真度。我们的方法对各种生成器架构、学习目标以及配对和非配对设置都非常有效。
GAN 压缩: 面向交互式条件 GAN 的高效架构<br> 李牧阳、林吉、丁瑶瑶、刘志坚、朱俊彦和韩松<br> 麻省理工学院、Adobe 研究院、上海交通大学<br> CVPR 2020 会议论文。
演示
<p align="center"> <img src="https://yellow-cdn.veclightyear.com/835a84d5/deb943bb-cd54-4bc7-9dc3-903f47ccdb8e.gif" width=600> </p>概述
 GAN 压缩框架: ① 给定一个预训练的教师生成器 G',我们通过权重共享蒸馏出一个更小的"一劳永逸"学生生成器 G,其中包含所有可能的通道数。我们在每个训练步骤中为学生生成器 G 选择不同的通道数。② 然后,我们从"一劳永逸"生成器中提取许多子生成器并评估它们的性能。无需重新训练,这是"一劳永逸"生成器的优势。③ 最后,我们根据压缩比目标和性能目标(FID 或 mIoU),使用暴力搜索或进化搜索方法选择最佳子生成器。可选地,我们进行额外的微调,得到最终的压缩模型。
GAN 压缩框架: ① 给定一个预训练的教师生成器 G',我们通过权重共享蒸馏出一个更小的"一劳永逸"学生生成器 G,其中包含所有可能的通道数。我们在每个训练步骤中为学生生成器 G 选择不同的通道数。② 然后,我们从"一劳永逸"生成器中提取许多子生成器并评估它们的性能。无需重新训练,这是"一劳永逸"生成器的优势。③ 最后,我们根据压缩比目标和性能目标(FID 或 mIoU),使用暴力搜索或进化搜索方法选择最佳子生成器。可选地,我们进行额外的微调,得到最终的压缩模型。
性能
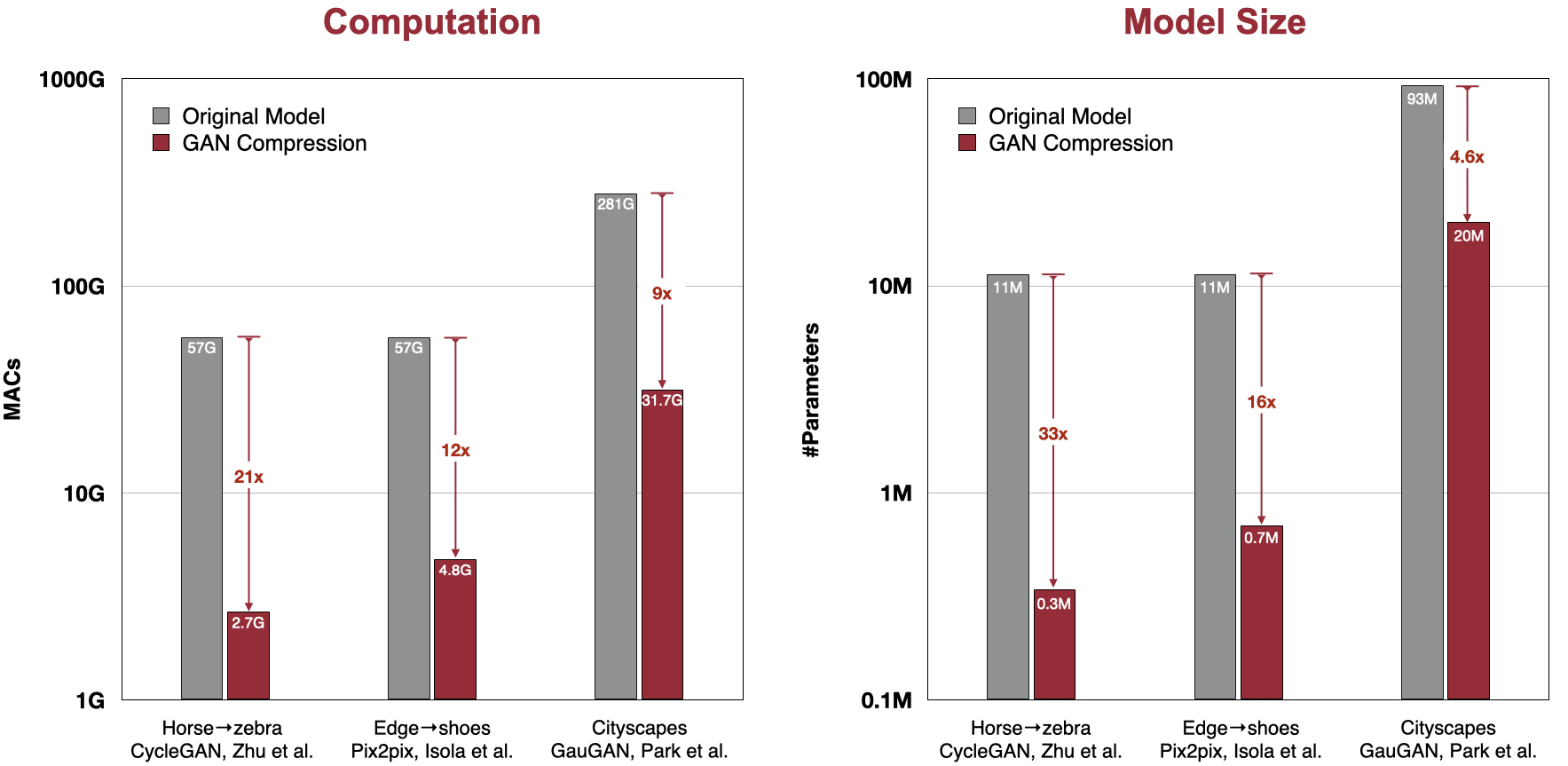
GAN 压缩将 pix2pix、cycleGAN 和 GauGAN 的计算量减少了 9-21 倍,模型大小减少了 4.6-33 倍。
Colab 笔记本
PyTorch Colab 笔记本: CycleGAN 和 pix2pix。
先决条件
- Linux
- Python 3
- CPU 或 NVIDIA GPU + CUDA CuDNN
入门指南
安装
-
克隆此仓库:
git clone git@github.com:mit-han-lab/gan-compression.git cd gan-compression -
安装 PyTorch 1.4 和其他依赖项(如 torchvision)。
- 对于 pip 用户,请输入命令
pip install -r requirements.txt。 - 对于 Conda 用户,我们提供了安装脚本
scripts/conda_deps.sh。或者,您可以使用conda env create -f environment.yml创建新的 Conda 环境。
- 对于 pip 用户,请输入命令
CycleGAN
设置
-
下载 CycleGAN 数据集(例如,horse2zebra)。
bash datasets/download_cyclegan_dataset.sh horse2zebra -
获取数据集真实图像的统计信息以计算 FID。我们为几个数据集提供了预准备的真实统计信息。例如,
bash datasets/download_real_stat.sh horse2zebra A bash datasets/download_real_stat.sh horse2zebra B
应用预训练模型
-
下载预训练模型。
python scripts/download_model.py --model cycle_gan --task horse2zebra --stage full python scripts/download_model.py --model cycle_gan --task horse2zebra --stage compressed -
测试原始完整模型。
bash scripts/cycle_gan/horse2zebra/test_full.sh -
测试压缩模型。
bash scripts/cycle_gan/horse2zebra/test_compressed.sh -
测量两个模型的延迟。
bash scripts/cycle_gan/horse2zebra/latency_full.sh bash scripts/cycle_gan/horse2zebra/latency_compressed.sh -
由于我们重新训练了模型,上述模型的结果可能与论文中的结果略有不同。我们还发布了论文中的压缩模型。如果存在这样的不一致,您可以尝试以下命令来测试我们的论文模型:
python scripts/download_model.py --model cycle_gan --task horse2zebra --stage legacy bash scripts/cycle_gan/horse2zebra/test_legacy.sh bash scripts/cycle_gan/horse2zebra/latency_legacy.sh
Pix2pix
设置
-
下载 pix2pix 数据集(例如,edges2shoes)。
bash datasets/download_pix2pix_dataset.sh edges2shoes-r -
获取数据集真实图像的统计信息以计算 FID。我们为几个数据集提供了预准备的真实统计信息。例如,
bash datasets/download_real_stat.sh edges2shoes-r B bash datasets/download_real_stat.sh edges2shoes-r subtrain_B
应用预训练模型
-
下载预训练模型。
python scripts/download_model.py --model pix2pix --task edges2shoes-r --stage full python scripts/download_model.py --model pix2pix --task edges2shoes-r --stage compressed -
测试原始完整模型。
bash scripts/pix2pix/edges2shoes-r/test_full.sh -
测试压缩模型。
bash scripts/pix2pix/edges2shoes-r/test_compressed.sh -
测量两个模型的延迟。
bash scripts/pix2pix/edges2shoes-r/latency_full.sh bash scripts/pix2pix/edges2shoes-r/latency_compressed.sh -
由于我们重新训练了模型,上述模型的结果可能与论文中的结果略有不同。我们还发布了论文中的压缩模型。如果存在这样的不一致,您可以尝试以下命令来测试我们的论文模型:
python scripts/download_model.py --model pix2pix --task edges2shoes-r --stage legacy bash scripts/pix2pix/edges2shoes-r/test_legacy.sh bash scripts/pix2pix/edges2shoes-r/latency_legacy.sh
<span id="gaugan">GauGAN</span>
设置
-
准备 cityscapes 数据集。查看此处以准备 cityscapes 数据集。
-
获取数据集真实图像的统计信息以计算 FID。我们为几个数据集提供了预准备的真实统计信息。例如,
bash datasets/download_real_stat.sh cityscapes A
应用预训练模型
-
下载预训练模型。
python scripts/download_model.py --model gaugan --task cityscapes --stage full python scripts/download_model.py --model gaugan --task cityscapes --stage compressed -
测试原始完整模型。
bash scripts/gaugan/cityscapes/test_full.sh -
测试压缩模型。
bash scripts/gaugan/cityscapes/test_compressed.sh -
测量两个模型的延迟。
bash scripts/gaugan/cityscapes/latency_full.sh bash scripts/gaugan/cityscapes/latency_compressed.sh -
由于我们重新训练了模型,上述模型的结果可能与论文中的结果略有不同。我们还发布了论文中的压缩模型。如果存在这样的不一致,您可以尝试以下命令来测试我们的论文模型:
python scripts/download_model.py --model gaugan --task cityscapes --stage legacy bash scripts/gaugan/cityscapes/test_legacy.sh bash scripts/gaugan/cityscapes/latency_legacy.sh
<span id="munit">MUNIT</span>
设置
-
准备数据集(如edges2shoes-r)。
bash datasets/download_pix2pix_dataset.sh edges2shoes-r python datasets/separate_A_and_B.py --input_dir database/edges2shoes-r --output_dir database/edges2shoes-r-unaligned python datasets/separate_A_and_B.py --input_dir database/edges2shoes-r --output_dir database/edges2shoes-r-unaligned --phase val -
获取数据集真实图像的统计信息以计算FID。我们为多个数据集提供了预先准备好的真实统计数据。例如:
bash datasets/download_real_stat.sh edges2shoes-r B bash datasets/download_real_stat.sh edges2shoes-r-unaligned subtrain_B
应用预训练模型
-
下载预训练模型。
python scripts/download_model.py --model gaugan --task cityscapes --stage full python scripts/download_model.py --model gaugan --task cityscapes --stage compressed -
测试原始完整模型。
bash scripts/munit/edges2shoes-r_fast/test_full.sh -
测试压缩模型。
bash scripts/munit/edges2shoes-r_fast/test_compressed.sh -
测量两个模型的延迟。
bash scripts/munit/edges2shoes-r_fast/latency_full.sh bash scripts/munit/edges2shoes-r_fast/latency_compressed.sh
<span id="cityscapes">Cityscapes数据集</span>
由于许可问题,我们无法提供Cityscapes数据集。请从https://cityscapes-dataset.com下载数据集,并使用脚本[prepare_cityscapes_dataset.py](datasets/prepare_cityscapes_dataset.py)进行预处理。您需要下载gtFine_trainvaltest.zip和leftImg8bit_trainvaltest.zip,并将它们解压到同一文件夹中。例如,您可以将gtFine和leftImg8bit放在database/cityscapes-origin中。您需要使用以下命令准备数据集:
python datasets/get_trainIds.py database/cityscapes-origin/gtFine/ python datasets/prepare_cityscapes_dataset.py \ --gtFine_dir database/cityscapes-origin/gtFine \ --leftImg8bit_dir database/cityscapes-origin/leftImg8bit \ --output_dir database/cityscapes \ --train_table_path datasets/train_table.txt \ --val_table_path datasets/val_table.txt
您将在database/cityscapes中获得预处理后的数据集,以及dataset/table.txt中的映射表(用于计算mIoU)。
COCO-Stuff数据集
我们遵循与NVlabs/spade相同的COCO-Stuff数据集准备方法。具体来说,您需要从nightrome/cocostuff下载train2017.zip、val2017.zip、stuffthingmaps_trainval2017.zip和annotations_trainval2017.zip。图像、标签和实例地图应按照datasets/coco_stuff中的相同目录结构排列。特别地,我们使用了一个结合了"物体实例地图"和"物质标签地图"边界的实例地图。为此,我们使用了一个简单的脚本datasets/coco_generate_instance_map.py。
为了支持mIoU计算,您需要下载预训练的DeeplabV2模型deeplabv2_resnet101_msc-cocostuff164k-100000.pth,并将其也放在仓库的根目录中。
已发布模型的性能
以下我们展示了所有已发布模型的性能:
<table style="undefined;table-layout: fixed; width: 868px"> <colgroup> <col style="width: 130px"> <col style="width: 130px"> <col style="width: 130px"> <col style="width: 130px"> <col style="width: 130px"> <col style="width: 109px"> <col style="width: 109px"> </colgroup> <thead> <tr> <th rowspan="2">模型</th> <th rowspan="2">数据集</th> <th rowspan="2">方法</th> <th rowspan="2">参数数量</th> <th rowspan="2">MACs</th> <th colspan="2">评估指标</th> </tr> <tr> <td>FID</td> <td>mIoU</td> </tr> </thead> <tbody> <tr> <td rowspan="4">CycleGAN</td> <td rowspan="4">马→斑马</td> <td>原始</td> <td>11.4M</td> <td>56.8G</td> <td>65.75</td> <td>--</td> </tr> <tr> <td>GAN压缩(论文)</td> <td>0.342M</td> <td>2.67G</td> <td>65.33</td> <td>--</td> </tr> <tr> <td>GAN压缩(重新训练)</td> <td>0.357M</td> <td>2.55G</td> <td>65.12</td> <td>--</td> </tr> <tr> <td>快速GAN压缩</td> <td>0.355M</td> <td>2.64G</td> <td>65.19</td> <td>--</td> </tr> <tr> <td rowspan="11">Pix2pix</td> <td rowspan="4">边缘→鞋子</td> <td>原始</td> <td>11.4M</td> <td>56.8G</td> <td>24.12</td> <td>--</td> </tr> <tr> <td>GAN压缩(论文)</td> <td>0.700M</td> <td>4.81G</td> <td>26.60</td> <td>--</td> </tr> <tr> <td>GAN压缩(重新训练)</td> <td>0.822M</td> <td>4.99G</td> <td>26.70</td> <td>--</td> </tr> <tr> <td>快速GAN压缩</td> <td>0.703M</td> <td>4.83G</td> <td>25.76</td> <td>--</td> </tr> <tr> <td rowspan="4">城市景观</td> <td>原始</td> <td>11.4M</td> <td>56.8G</td> <td>--</td> <td>42.06</td> </tr> <tr> <td>GAN压缩(论文)</td> <td>0.707M</td> <td>5.66G</td> <td>--</td> <td>40.77</td> </tr> <tr> <td>GAN压缩(重新训练)</td> <td>0.781M</td> <td>5.59G</td> <td>--</td> <td>38.63</td> </tr> <tr> <td>快速GAN压缩</td> <td>0.867M</td> <td>5.61G</td> <td>--</td> <td>41.71</td> </tr> <tr> <td rowspan="3">地图→航拍照片<br></td> <td>原始</td> <td>11.4M</td> <td>56.8G</td> <td>47.91</td> <td>--</td> </tr> <tr> <td>GAN压缩</td> <td>0.746M</td> <td>4.68G</td> <td>48.02</td> <td>--</td> </tr> <tr> <td>快速GAN压缩</td> <td>0.708M</td> <td>4.53G</td> <td>48.67</td> <td>--</td> </tr> <tr> <td rowspan="6">GauGAN</td> <td rowspan="4">城市景观</td> <td>原始</td> <td>93.0M</td> <td>281G</td> <td>57.60</td> <td>61.04</td> </tr> <tr> <td>GAN压缩(论文)</td> <td>20.4M</td> <td>31.7G</td> <td>55.19</td> <td>61.22</td> </tr> <tr> <td>GAN压缩(重新训练)</td> <td>21.0M</td> <td>31.2G</td> <td>56.43</td> <td>60.29</td> </tr> <tr> <td>快速GAN压缩</td> <td>20.2M</td> <td>31.3G</td> <td>56.25</td> <td>61.17</td> </tr> <tr> <td rowspan="2">COCO-Stuff</td> <td>原始</td> <td>97.5M</td> <td>191G</td> <td>21.38</td> <td>38.78</td> </tr> <tr> <td>快速GAN压缩</td> <td>26.0M</td> <td>35.5G</td> <td>25.06</td> <td>35.05</td> </tr> <tr> <td rowspan="2">MUNIT</td> <td rowspan="2">边缘→鞋子</td> <td>原始</td> <td>15.0M</td> <td>77.3G</td> <td>30.13</td> <td>--</td> </tr> <tr> <td>快速GAN压缩</td> <td>1.10M</td> <td>2.63G</td> <td>30.53</td> <td>--</td> </tr> </tbody> </table>训练
请参考快速GAN压缩和GAN压缩的教程,了解如何在我们的数据集和您自己的数据集上训练模型。
FID计算
要计算FID分数,您需要从数据集的真实图像中获取一些统计信息。我们提供了一个脚本get_real_stat.py来提取统计信息。例如,对于edges2shoes数据集,您可以运行以下命令:
python get_real_stat.py \ --dataroot database/edges2shoes-r \ --output_path real_stat/edges2shoes-r_B.npz \ --direction AtoB
对于成对的图像到图像转换(pix2pix和GauGAN),我们计算生成的测试图像与真实测试图像之间的FID。对于非成对的图像到图像转换(CycleGAN),我们计算生成的测试图像与真实训练+测试图像之间的FID。这允许我们使用更多的图像进行稳定的FID评估,就像之前的无条件GAN研究中所做的那样。这两种协议的差异很小。当使用真实测试图像而不是真实训练+测试图像时,我们压缩的CycleGAN模型的FID增加了4。
代码结构
为了帮助用户更好地理解和使用我们的代码,我们简要概述了每个包和每个模块的功能和实现。
引用
如果您在研究中使用了这份代码,请引用我们的论文。
@inproceedings{li2020gan, title={GAN Compression: Efficient Architectures for Interactive Conditional GANs}, author={Li, Muyang and Lin, Ji and Ding, Yaoyao and Liu, Zhijian and Zhu, Jun-Yan and Han, Song}, booktitle={Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition}, year={2020} }
致谢
我们的代码是基于pytorch-CycleGAN-and-pix2pix、SPADE和MUNIT开发的。
我们还要感谢pytorch-fid用于FID计算,drn用于城市景观mIoU计算,以及deeplabv2用于Coco-Stuff mIoU计算。
编辑推荐精选


扣子-AI办公
职场AI,就用扣子
AI办公助手,复杂任务高效处理。办公效率低?扣子空间AI助手支持播客生成、PPT制作、网页开发及报告写作,覆盖科研、商业、舆情等领域的专家Agent 7x24小时响应,生活工作无缝切换,提升50%效率!


堆友
多风格AI绘画神器
堆友平台由阿里巴巴设计团队创建,作为一款AI驱动的设计工具,专为设计师提供一站式增长服务。功能覆盖海量3D素材、AI绘画、实时渲染以及专业抠图,显著提升设计品质和效率。平台不仅提供工具,还是一个促进创意交流和个人发展的空间,界面友好,适合所有级别的设计师和创意工作者。


码上飞
零代码AI应用开发平台
零代码AI应用开发平台,用户只需一句话简单描述需求,AI能自动生成小程序、APP或H5网页�应用,无需编写代码。


Vora
免费创建高清无水印Sora视频
Vora是一个免费创建高清无水印Sora视频的AI工具


Refly.AI
最适合小白的AI自动化工作流平台
无需编码,轻松生成可复用、可变现的AI自动化工作流


酷表ChatExcel
大模型驱动的Excel数据处理工具
基于大模型交互的表格处理系统,允许用户通过对话方式完成数据整理和可视化分析。系统采用机器学习算法解析用户指令,自动执行排序、公式计算和数据透视等操作,支持多种文件格式导入导出。数据处理响应速度保持在0.8秒以内,支持超过100万行数据的即时分析。


TRAE编程
AI辅助编程,代码自动修复
Trae是一种自适应的集成开发环境(IDE),通过自动化和多元协作改变开发流程。利用Trae,团队能够更快速、精确地编写和部署代码,从而提高编程效率和项目交付��速度。Trae具备上下文感知和代码自动完成功能,是提升开发效率的理想工具。


AIWritePaper论文写作
AI论文写作指导平台
AIWritePaper论文写作是一站式AI论文写作辅助工具,简化了选题、文献检索至论文撰写的整个过程。通过简单设定,平台可快速生成高质量论文大纲和全文,配合图表、参考文献等一应俱全,同时提供开题报告和答辩PPT等增值服务,保障数据安全,有效提升写作效率和论文质量。


博思AIPPT
AI一键生成PPT,就用博思AIPPT!
博思AIPPT,新一代的AI生成PPT平台,支持智能生成PPT、AI美化PPT、文本&链接生成PPT、导入Word/PDF/Markdown文档生成PPT等,内置海量精美PPT模板,涵盖商务、教育、科技等不同风格,同时针对每个页面提供多种版式,一键自适应切换,完美适配各种办公场景。


潮际好麦
AI赋能电商视觉革命,一站式智能商拍平台
潮际好麦深耕服装行业,是国内AI试衣效果最好的软件。使用先进AIGC能力为电商卖家批量提供优质的、低成本的商拍图。合作品牌有Shein、Lazada、安踏、百丽等65个国内外头部品牌,以及国内10万+淘宝、天猫、京东等主流平台的品牌商家,为卖家节省将近85%的出图成本,提升约3倍出图效率,让品牌能够快速上架。
推荐工具精选




AI云服务特惠
懂AI专属折扣关注微信公众号
最新AI工具、AI资讯
独家AI资源、AI项目落地

微信扫一扫关注公众号