



4D高斯散射实时动态场景渲染
CVPR 2024
项目主页 | arXiv论文
吴冠军 <sup>1*</sup>, 易陶然 <sup>2*</sup>, 方杰敏 <sup>3‡</sup>, 谢凌曦 <sup>3</sup>, </br>张晓鹏 <sup>3</sup>, 魏巍 <sup>1</sup>, 刘文预 <sup>2</sup>, 田奇 <sup>3</sup>, 王兴刚 <sup>2‡✉</sup>
<sup>1</sup>华中科技大学计算机科学与技术学院 <sup>2</sup>华中科技大学电子信息与通信学院 <sup>3</sup>华为公司
<sup>*</sup> 贡献相同。 <sup>‡</sup> 项目负责人。 <sup>✉</sup> 通讯作者。
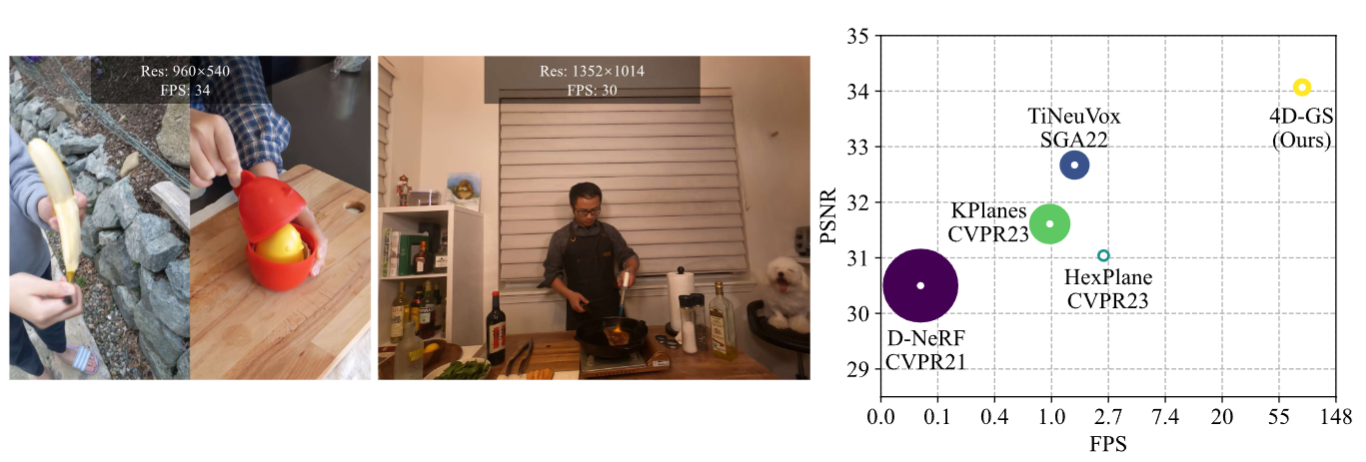 我们的方法收敛速度非常快,并实现了实时渲染速度。
我们的方法收敛速度非常快,并实现了实时渲染速度。
新的Colab演示: (感谢 Tasmay-Tibrewal)
(感谢 Tasmay-Tibrewal)
旧的Colab演示: (感谢 camenduru。)
Light Gaussian实现:此链接 (感谢 pablodawson)
新闻
2024.6.25:我们清理了代码并添加了参数说明。
2024.3.25:更新了hypernerf和dynerf数据集的指导。
2024.03.04:我们更改了Neu3D数据集的超参数,与我们的论文相对应。
2024.02.28:更新SIBR查看器指导。
2024.02.27:被CVPR 2024接收。我们删除了一些用于调试的日志设置,修正后的训练时间在D-NeRF数据集上仅为8分钟(之前为20分钟),在HyperNeRF数据集上为30分钟(之前为1小时)。渲染质量不受影响。
环境设置
请按照3D-GS的指示安装相关包。
git clone https://github.com/hustvl/4DGaussians cd 4DGaussians git submodule update --init --recursive conda create -n Gaussians4D python=3.7 conda activate Gaussians4D pip install -r requirements.txt pip install -e submodules/depth-diff-gaussian-rasterization pip install -e submodules/simple-knn
在我们的环境中,我们使用pytorch=1.13.1+cu116。
数据准备
对于合成场景: 使用D-NeRF提供的数据集。你可以从dropbox下载数据集。
对于真实动态场景: 使用HyperNeRF提供的数据集。你可以从Hypernerf数据集下载场景并按照Nerfies的方式组织它们。
同时,Plenoptic数据集可以从其官方网站下载。为了节省内存,你应该提取每个视频的帧,然后按如下方式组织你的数据集。
├── data
│ | dnerf
│ ├── mutant
│ ├── standup
│ ├── ...
│ | hypernerf
│ ├── interp
│ ├── misc
│ ├── virg
│ | dynerf
│ ├── cook_spinach
│ ├── cam00
│ ├── images
│ ├── 0000.png
│ ├── 0001.png
│ ├── 0002.png
│ ├── ...
│ ├── cam01
│ ├── images
│ ├── 0000.png
│ ├── 0001.png
│ ├── ...
│ ├── cut_roasted_beef
| ├── ...
对于多视角场景: 如果你想训练自己的多视角场景数据集,你可以按如下方式组织你的数据集:
├── data
| | multipleview
│ | (你的数据集名称)
│ | cam01
| ├── frame_00001.jpg
│ ├── frame_00002.jpg
│ ├── ...
│ | cam02
│ ├── frame_00001.jpg
│ ├── frame_00002.jpg
│ ├── ...
│ | ...
之后,你可以使用我们提供的multipleviewprogress.sh来生成相关的姿态和点云数据。你可以这样使用它:
bash multipleviewprogress.sh (你的数据集名称)
你需要确保运行multipleviewprogress.sh后,数据文件夹按以下方式组织:
├── data
| | multipleview
│ | (你的数据集名称)
│ | cam01
| ├── frame_00001.jpg
│ ├── frame_00002.jpg
│ ├── ...
│ | cam02
│ ├── frame_00001.jpg
│ ├── frame_00002.jpg
│ ├── ...
│ | ...
│ | sparse_
│ ├── cameras.bin
│ ├── images.bin
│ ├── ...
│ | points3D_multipleview.ply
│ | poses_bounds_multipleview.npy
训练
对于训练合成场景,如bouncingballs,运行
python train.py -s data/dnerf/bouncingballs --port 6017 --expname "dnerf/bouncingballs" --configs arguments/dnerf/bouncingballs.py
对于训练dynerf场景,如cut_roasted_beef,运行
# 首先,提取每个视频的帧。 python scripts/preprocess_dynerf.py --datadir data/dynerf/cut_roasted_beef # 其次,从输入数据生成点云。 bash colmap.sh data/dynerf/cut_roasted_beef llff # 第三,对第二步生成的点云进行下采样。 python scripts/downsample_point.py data/dynerf/cut_roasted_beef/colmap/dense/workspace/fused.ply data/dynerf/cut_roasted_beef/points3D_downsample2.ply # 最后,训练。 python train.py -s data/dynerf/cut_roasted_beef --port 6017 --expname "dynerf/cut_roasted_beef" --configs arguments/dynerf/cut_roasted_beef.py
对于训练hypernerf场景,如virg/broom:由COLMAP预生成的点云可在此处下载。只需下载它们并放入相应文件夹,你就可以跳过前两个步骤。你也可以直接运行以下命令。
# 首先,通过COLMAP计算密集点云 bash colmap.sh data/hypernerf/virg/broom2 hypernerf # 其次,对第一步生成的点云进行下采样。 python scripts/downsample_point.py data/hypernerf/virg/broom2/colmap/dense/workspace/fused.ply data/hypernerf/virg/broom2/points3D_downsample2.ply # 最后,训练。 python train.py -s data/hypernerf/virg/broom2/ --port 6017 --expname "hypernerf/broom2" --configs arguments/hypernerf/broom2.py
对于训练多视角场景,你需要在"./arguments/mutipleview"下创建一个名为(你的数据集名称).py的配置文件,然后运行
python train.py -s data/multipleview/(你的数据集名称) --port 6017 --expname "multipleview/(你的数据集名称)" --configs arguments/multipleview/(你的数据集名称).py
对于你的自定义数据集,安装nerfstudio并遵循他们的COLMAP流程。你应该首先安装COLMAP,然后:
pip install nerfstudio # 通过colmap流程计算相机姿态 ns-process-data images --data data/your-data --output-dir data/your-ns-data cp -r data/your-ns-data/images data/your-ns-data/colmap/images python train.py -s data/your-ns-data/colmap --port 6017 --expname "custom" --configs arguments/hypernerf/default.py
你可以通过配置文件自定义你的训练配置。
检查点
你也可以使用检查点训练你的模型。
python train.py -s data/dnerf/bouncingballs --port 6017 --expname "dnerf/bouncingballs" --configs arguments/dnerf/bouncingballs.py --checkpoint_iterations 200 # 更改它。
然后加载检查点:
python train.py -s data/dnerf/bouncingballs --port 6017 --expname "dnerf/bouncingballs" --configs arguments/dnerf/bouncingballs.py --start_checkpoint "output/dnerf/bouncingballs/chkpnt_coarse_200.pth" # 最终阶段:--start_checkpoint "output/dnerf/bouncingballs/chkpnt_fine_200.pth"
渲染
运行以下脚本来渲染图像。
python render.py --model_path "output/dnerf/bouncingballs/" --skip_train --configs arguments/dnerf/bouncingballs.py
评估
你可以直接运行以下脚本来评估模型。
python metrics.py --model_path "output/dnerf/bouncingballs/"
查看器
脚本
这里有一些有用的脚本,请随意使用它们。
export_perframe_3DGS.py:
获取每个时间戳的所有3D高斯点云。
用法:
python export_perframe_3DGS.py --iteration 14000 --configs arguments/dnerf/lego.py --model_path output/dnerf/lego
一组3D高斯分布将保存在output/dnerf/lego/gaussian_pertimestamp中。
weight_visualization.ipynb:
可视化多分辨率HexPlane模块的权重。
merge_many_4dgs.py:
合并你训练好的4dgs模型。
使用方法:
export exp_name="dynerf" python merge_many_4dgs.py --model_path output/$exp_name/sear_steak
colmap.sh:
从输入数据生成点云
bash colmap.sh data/hypernerf/virg/vrig-chicken hypernerf bash colmap.sh data/dynerf/sear_steak llff
Blender格式似乎无法正常工作。欢迎提交拉取请求来修复这个问题。
downsample_point.py:对由sfm生成的点云进行下采样。
python scripts/downsample_point.py data/dynerf/sear_steak/colmap/dense/workspace/fused.ply data/dynerf/sear_steak/points3D_downsample2.ply
在我的论文中,我总是使用colmap.sh生成密集点云,并将其下采样至少于40000个点。
这里有一些可能有用但未在我的论文中采用的代码,你也可以尝试一下。
优秀的相关/同期工作
欢迎也查看这些优秀的相关/同期工作,包括但不限于:
MD-Splatting: 在高度可变形场景中从4D高斯分布学习度量变形
Diffusion4D: 通过视频扩散模型实现快速时空一致的4D生成
EndoGaussian: 用于动态内窥镜场景重建的实时高斯散射
贡献
本项目仍在开发中。欢迎提出问题或提交拉取请求,为我们的代码库做出贡献。
我们的部分源代码借鉴自3DGS、K-planes、HexPlane、TiNeuVox和Depth-Rasterization。我们衷心感谢这些作者的出色工作。
致谢
我们衷心感谢@zhouzhenghong-gt对我们代码的修订以及对论文内容的讨论。
引用
关于神经体素网格和动态场景重建的一些见解来自TiNeuVox。如果你发现这个仓库/工作对你的研究有帮助,欢迎引用这些论文并给个⭐。
@InProceedings{Wu_2024_CVPR,
author = {Wu, Guanjun and Yi, Taoran and Fang, Jiemin and Xie, Lingxi and Zhang, Xiaopeng and Wei, Wei and Liu, Wenyu and Tian, Qi and Wang, Xinggang},
title = {4D Gaussian Splatting for Real-Time Dynamic Scene Rendering},
booktitle = {Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR)},
month = {June},
year = {2024},
pages = {20310-20320}
}
@inproceedings{TiNeuVox,
author = {Fang, Jiemin and Yi, Taoran and Wang, Xinggang and Xie, Lingxi and Zhang, Xiaopeng and Liu, Wenyu and Nie\ss{}ner, Matthias and Tian, Qi},
title = {Fast Dynamic Radiance Fields with Time-Aware Neural Voxels},
year = {2022},
booktitle = {SIGGRAPH Asia 2022 Conference Papers}
}
编辑推荐精选


音述AI
全球首个AI音乐社区
音述AI是全球首个AI音乐社区,致力让每个人都能用音乐表达自我。音述AI提供零门槛AI创作工具,独创GETI法则帮助用户精准定义音乐风格,AI润色功能支持自动优化作品质感。音述AI支持交流讨论、二次创作与价值变现。针对中文用户的语言习惯与文化背景进行专门优化,支持国风融合、C-pop等本土音乐标签,让技术更好地承载人文表达。


QoderWork
阿里Qoder团队推出的桌面端AI智能体
QoderWork 是阿里推出的本地优先桌面 AI 智能体,适配 macOS14+/Windows10+,以自然语言交互实现文件管理、数据分析、AI 视觉生成、浏览器自动化等办公任务,自主拆解执行复杂工作流,数据本地运行零上传,技能市场可无限扩展,是高效的 Agentic 生产力办公助手。


lynote.ai
一站式搞定所有学习需求
不再被海量信息淹没,开始真正理解知识。Lynote 可摘要 YouTube 视频、PDF、文章等内容。即时创建笔记,检测 AI 内容并下载资料,将您的学习效率提升 10 倍。


AniShort
为AI短剧协作而生
专为AI短剧协作而生的AniShort正式发布,深度重构AI短剧全流程生产模式,整合创意策划、制作执行、实时协作、在线审片、资产复用等全链路功能,独创无限画布、双轨并行工业化工作流与Ani智能体助手,集成多款主流AI大模型,破解素材零散、版本混乱、沟通低效等行业痛点,助力3人团队效率提升800%,打造标准化、可追溯的AI短剧量产体系,是AI短剧团队协同创作、提升制作效率的核心工具。


seedancetwo2.0
能听懂你表达的视频模型
Seedance two是基于seedance2.0的中国大模型,支持图像、视频、音频、文本四种模态输入,表达方式更丰富,生成也更可控。


nano-banana纳米香蕉中文站
国内直接访问,限时3折
输入简单文字,生成想要的图片,纳米香蕉中文站基于 Google 模型的 AI 图片生成网站,支持文字生图、图生图。官网价格限时3折活动


扣子-AI办公
职场AI,就用扣子
AI办公助手,复杂任务高效处理。办公效率低?扣子空间AI助手支持播客生成、PPT制作、网页开发及报告写作,覆盖科研、商业、舆情等领域的专家Agent 7x24小时响应,生活工作无缝切换,提升50%效率!


堆友
多风格AI绘画神器
堆友平台由阿里巴巴设��计团队创建,作为一款AI驱动的设计工具,专为设计师提供一站式增长服务。功能覆盖海量3D素材、AI绘画、实时渲染以及专业抠图,显著提升设计品质和效率。平台不仅提供工具,还是一个促进创意交流和个人发展的空间,界面友好,适合所有级别的设计师和创意工作者。


码上飞
零代码AI应用开发平台
零代码AI应用开发平台,用户只需一句话简单描述需求,AI能自动生成小程序、APP或H5网页应用,无需编写代码。


Vora
免费创建高清无水印Sora视频
Vora是一个免费创建高清无水印Sora视频的AI工具
推荐工具精选





AI云服务特惠
懂AI专属折扣关注微信公众号
最新AI工具、AI资讯
独家AI资源、AI项目落地

微信扫一扫关注公众号