


HaGRID - 手势识别图像数据集

我们引入了一个大型图像数据集HaGRID(HAnd Gesture Recognition Image Dataset)用于手势识别(HGR)系统。您可以将其用于图像分类或图像检测任务。建议的数据集允许构建HGR系统,这些系统可用于视频会议服务(Zoom、Skype、Discord、Jazz等)、家庭自动化系统、汽车行业等。
HaGRID的大小为723GB,数据集包含554,800张全高清RGB图像,分为18类手势。此外,如果帧中有第二只空闲的手,某些图像会有no_gesture类。这个额外的类包含120,105个样本。数据被按主体user_id划分为74%的训练集、10%的验证集和16%的测试集,其中训练集有410,800个图像,验证集有54,000个图像,测试集有90,000个图像。
该数据集包含37,583位独特的参与者和至少同样数量的独特场景。参与者年龄在18到65岁之间。该数据集主要在室内收集,光线条件有很大差异,包括人工光和自然光。此外,该数据集还包括在面对和背对窗户的极端条件下拍摄的图像。同时,参与者必须在距离相机0.5到4米的范围内展示手势。
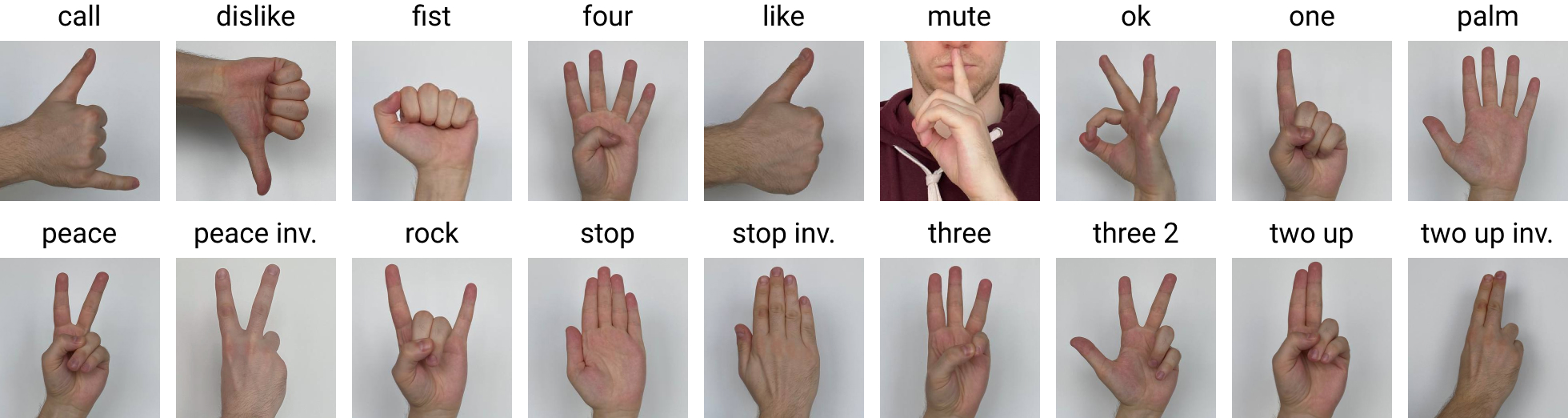
样本及其标注示例:

更多信息请参见我们的arXiv论文HaGRID - 手势识别图像数据集。
🔥 更新日志
2023/09/21:我们发布了HaGRID 2.0. ✌️- 将训��练和测试的所有文件合并到一个目录
- 进一步清理数据,并添加了新的数据
- 支持多GPU训练和测试
- 新增了检测和全帧分类的模型
- 数据集大小为723GB
- 554,800张全高清RGB图像(清理并更新类别,增加种族多样性)
- 额外的
no_gesture类包含120,105个样本 - 训练/验证/测试分割:(410,800) 74% / (54,000) 10% / (90,000) 16% 按主体
user_id - 37,583位独特参与者
2022/06/16: HaGRID (初始数据集) 💪- 数据集大小为716GB
- 552,992张全高清RGB图像,分为18个类别
- 额外的
no_gesture类包含123,589个样本 - 训练/测试分割:(509,323) 92% / (43,669) 8% 按主体
user_id - 34,730位独特参与者,年龄在18到65岁之间
- 距离相机0.5到4米
旧版HaGRID数据集也可以在分支hagrid_v1中获取!
安装
克隆并安装所需的Python包:
git clone https://github.com/hukenovs/hagrid.git # 或镜像链接: cd hagrid # 使用conda或venv创建虚拟环境 conda create -n gestures python=3.11 -y conda activate gestures # 安装依赖 pip install -r requirements.txt
下载
由于训练数据集的大小,我们将其按手势分割成18个压缩包。从以下链接下载并解压缩:
数据集
| 手势 | 大小 | 手势 | 大小 |
|---|---|---|---|
呼叫 | 37.2 GB | 和平 | 41.4 GB |
不喜欢 | 40.9 GB | 和平倒置 | 40.5 GB |
拳头 | 42.3 GB | 岩石 | 41.7 GB |
四 | 43.1 GB | 停止 | 41.8 GB |
喜欢 | 42.2 GB | 停止倒置 | 41.4 GB |
静音 | 43.2 GB | 三 | 42.2 GB |
好 | 42.5 GB | 三2 | 40.2 GB |
一 | 42.7 GB | 两个竖起 | 41.8 GB |
手掌 | 43.0 GB | 两个竖起倒置 | 40.9 GB |
数据集注解: 注解
HaGRID 512px - 完整数据集轻量级版本,最小边长为512像素 26.4 GB
或使用Python脚本下载
python download.py --save_path <PATH_TO_SAVE> \ --annotations \ --dataset
运行以下命令并使用 --dataset 键下载数据集。 使用 --annotations 键下载所选阶段的注解。
usage: download.py [-h] [-a] [-d] [-t TARGETS [TARGETS ...]] [-p SAVE_PATH] 下载数据集... 可选参数: -h, --help 显示帮助消息并退出 -a, --annotations 下载注解 -d, --dataset 下载数据集 -t TARGETS [TARGETS ...], --targets TARGETS [TARGETS ...] 要下载的训练集目标 -p SAVE_PATH, --save_path SAVE_PATH 保存路径
下载完成后,可以运行以下命令解压存档:
unzip <PATH_TO_ARCHIVE> -d <PATH_TO_SAVE>
数据集的结构如下:
├── hagrid_dataset <PATH_TO_DATASET_FOLDER>
│ ├── call
│ │ ├── 00000000.jpg
│ │ ├── 00000001.jpg
│ │ ├── ...
├── hagrid_annotations
│ ├── train <PATH_TO_JSON_TRAIN>
│ │ ├── call.json
│ │ ├── ...
│ ├── val <PATH_TO_JSON_VAL>
│ │ ├── call.json
│ │ ├── ...
│ ├── test <PATH_TO_JSON_TEST>
│ │ ├── call.json
│ │ ├── ...
模型
我们提供了一些预训练的基线模型,使用了经典的骨干架构进行手势分类和手势检测。
| 检测器 | mAP |
|---|---|
| SSDLiteMobileNetV3Small | 57.7 |
| SSDLiteMobileNetV3Large | 71.6 |
| RetinaNet_ResNet50 | 79.1 |
| YoloV7Tiny | 71.6 |
然而,如果您只需要一个手势,您可以使用预训练的全帧分类器而不是检测器。 要使用全帧模型,请删除no_gesture类
| 全帧分类器 | F1手势 |
|---|---|
| MobileNetV3_small | 86.4 |
| MobileNetV3_large | 91.9 |
| VitB16 | 91.1 |
| ResNet18 | 97.5 |
| ResNet152 | 95.5 |
| ResNeXt50 | 98.3 |
| ResNeXt101 | 97.5 |
您可以使用下载的训练模型�,否则在 configs 文件夹中选择训练参数。
要训练模型,请执行以下命令:
单GPU:
python run.py -c train -p configs/<config>
多GPU:
bash ddp_run.sh -g 0,1,2,3 -c train -p configs/<config>
其中 -g 是GPU ID的列表。
每一步, 当前的损失, 学习率和其他值都会被记录到 Tensorboard。
通过打开命令行查看所有保存的指标和参数(这将在 localhost:6006 打开一个网页):
</details> <details><summary><h3>测试</h3></summary>tensorboard --logdir=<workdir>
通过运行以下命令测试您的模型:
单GPU:
python run.py -c test -p configs/<config>
多GPU:
bash ddp_run.sh -g 0,1,2,3 -c test -p configs/<config>
其中 -g 是GPU ID的列表。
</details>演示
python demo.py -p <PATH_TO_CONFIG> --landmarks
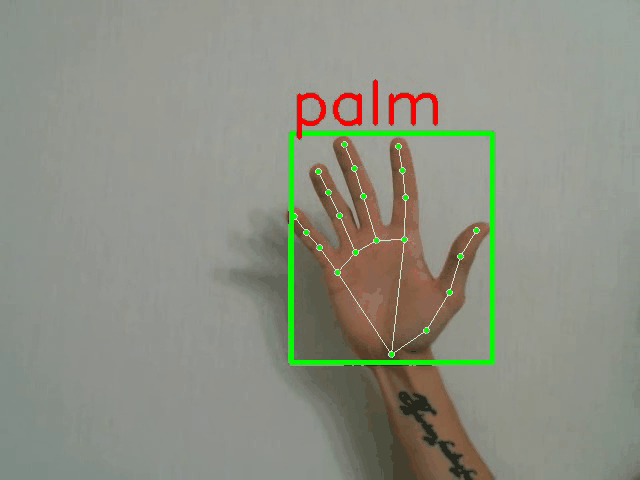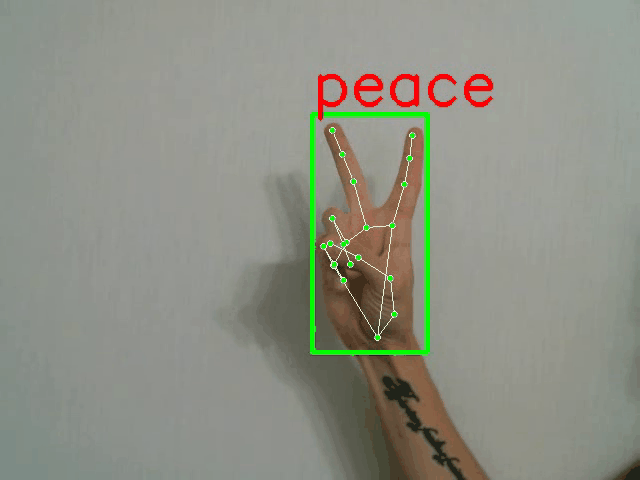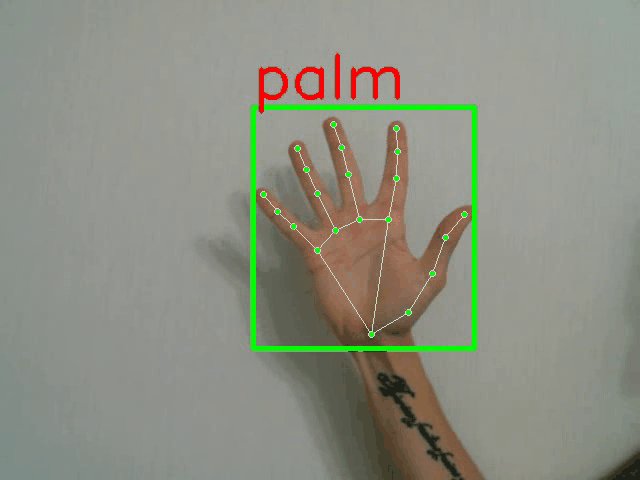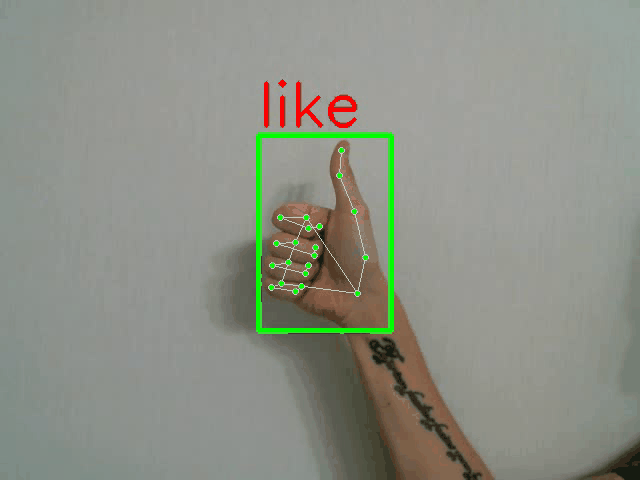
全帧分类器演示
python demo_ff.py -p <PATH_TO_CONFIG>
注释
注释由COCO格式的手部边界框 [左上角X位置, 左上角Y位置, 宽度, 高度] 和手势标签组成。我们提供 user_id 字段,以便您自己将训练/验证/测试数据集分开。
"0534147c-4548-4ab4-9a8c-f297b43e8ffb": { "bboxes": [ [0.38038597, 0.74085361, 0.08349486, 0.09142549], [0.67322755, 0.37933984, 0.06350809, 0.09187757] ], "labels": [ "no_gesture", "one" ], "user_id": "bb138d5db200f29385f..." }
- 键 - 不带扩展名的图像名称
- Bboxes - 归一化边界框列表
[左上角X位置, 左上角Y位置, 宽度, 高度] - 标签 - 类标签列表,如
like,stop,no_gesture - 用户ID - 主体ID(对于将数据拆分为训练/验证子集很有用)。
边界框
| 对象 | 训练 + 验证 | 测试 | 总计 |
|---|---|---|---|
| 手势 | ~ 28 300 | ~ 2 400 | 30 629 |
| 无手势 | 112 740 | 10 849 | 123 589 |
| 总框数 | 622 063 | 54 518 | 676 581 |
转换器
<details><summary> <b>Yolo</b> </summary>我们提供了一个脚本来将注释转换为YOLO格式。要转换注释,请运行以下命令:
python -m converters.hagrid_to_yolo --path_to_config <PATH>
转换后,您需要更改原始定义 img2labels 为:
</details> <details><summary> <b>Coco</b> </summary>def img2label_paths(img_paths): img_paths = list(img_paths) # 将标签路径定义为图像路径的函数 if "train" in img_paths[0]: return [x.replace("train", "train_labels").replace(".jpg", ".txt") for x in img_paths] elif "test" in img_paths[0]: return [x.replace("test", "test_labels").replace(".jpg", ".txt") for x in img_paths] elif "val" in img_paths[0]: return [x.replace("val", "val_labels").replace(".jpg", ".txt") for x in img_paths]
我们还提供了一个脚本来将注释转换为Coco格式。要转换注释,请运行以下命令:
</details> ```bash python -m converters.hagrid_to_coco --path_to_config <路径> ```编辑推荐精选


扣子-AI办公
职场AI,就用扣子
AI办公助手,复杂任务高效处理。办公效率低?扣子空间AI助手支持播客生成、PPT制作、网页开发及报告写作,覆盖科研、商业、舆情等领域的专家Agent 7x24小时响应,生活工作无缝切换,提升50%效率!


堆友
多风格AI绘画神器
堆友平台由阿里巴巴设计团队创建,作为一款AI驱动的设计工具,专为设计师提供一站式增长服务。功能覆盖海量3D素材、AI绘画、实时渲染以及专业抠图,显著提升设计品质和效率。平台不仅提供工具,还是一个促进创意交流和个人发展的空间,界面友好,适合所有级别的设计师和创意工作者。


码上飞
零代码AI应用开发平台
零代码AI应用开发平台,用户只需一句话简单描述需求,AI能自动生成小程序、APP或H5网页应用,无需编写代码。


Vora
免费创建高清无水印Sora视频
Vora是一个免费创建高清无水印Sora视频的AI工具


Refly.AI
最适合小白的AI自动化工作流平台
无需编码,轻松生成可复用、可变现的AI自动化工作流


酷表ChatExcel
大模型驱动的Excel数据处理工具
基于大模型交互的表格处理系统,允许用户通过对话方式完成数据整理和可视化分析。系统采用机器学习算法解析用户指令,自动执行排序、公式计算和数据透视等操作,支持多种文件格式导入导出。数据处理响应速度保持在0.8秒以内,支持超过100万行数据的即时分析。


TRAE编程
AI辅助编程,代码自动修复
Trae是一种自适应的集成开发环境(IDE),通过自动化和多元协作改变开发流程。利用Trae,团队能够更快速、精确地编写和部署代码,从而提高编程效率和项目交付速度。Trae具备上下文感知和代码自动完成功能,是提升开发效率的理想工具。


AIWritePaper论文写作
AI论文写作指导平台
AIWritePaper论文写作是一站式AI论文写作辅助工具,简化了选题、文献检索至论文撰写的整个过程。通过简单设定,平台可快速生成高质量论文大纲和全文,配合图表、参考文献等一应俱全,同时提供开题报告和答辩PPT等增值服务,保障数据安全,有效提升写作效率和论文质量。


博思AIPPT
AI一键生成PPT,就用博思AIPPT!
博思AIPPT,新一代的AI生成PPT平台,支持智能生成PPT、AI美化PPT、文本&链接生成PPT、导入Word/PDF/Markdown文档生成PPT等,内置海量精美PPT模板,涵盖商务、教育、科技等不同风格,同时针对每个页面提供多种版式,一键自适应切换,完美适配各种办公场景。


潮际好麦
AI赋能电商视觉革命,一站式智能商拍平台
潮际好麦深耕服装行业,是国内AI试衣效果最好的软件。使用先进AIGC能力为电商卖家批量提供优质的、低成本的商拍图。合作品牌有Shein、Lazada、安踏、百丽等65个国内外头部品牌,以及国内10万+淘宝、天猫、京东等主流平台的品牌商家,为卖家节省将近85%的出图成本,提升约3倍出图效率,让品牌能够快速上架。
推荐工具精选




AI云服务特惠
懂AI专属折扣关注微信公众号
最新AI工具、AI资讯
独家AI资源、AI项目落地

微信扫一扫关注公众号