
hallo
分层音频驱动人像动画合成框架
Hallo是一个分层音频驱动的视觉合成框架,用于生成人像图像动画。该框架可根据输入音频创建高质量的说话头像视频,支持重现多种经典电影场景。Hallo采用分层设计,整合多个先进模型,实现精细的面部表情和唇形同步。项目提供完整的训练和推理代码,适用于多种应用场景。





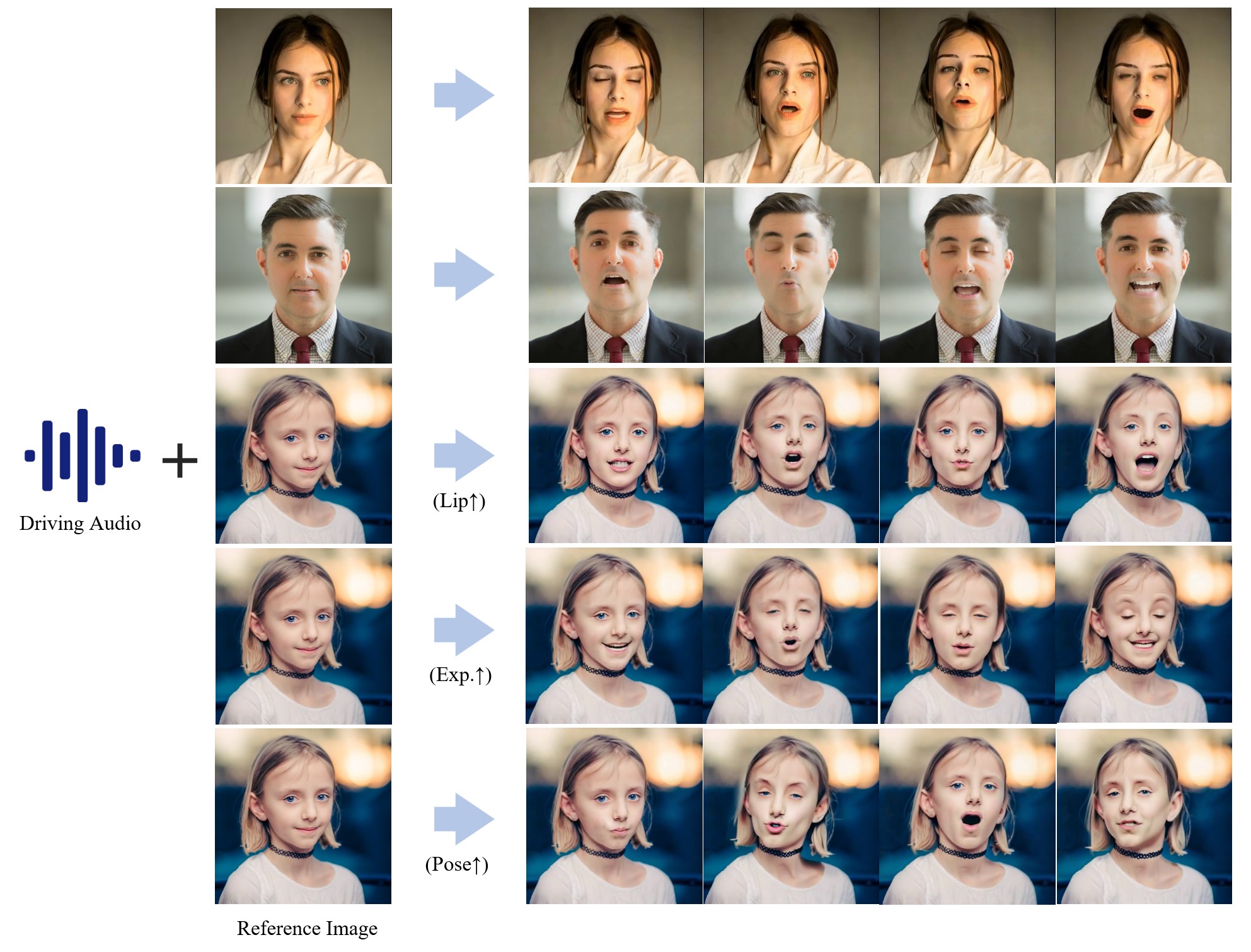
📸 展示
🎬 致敬经典电影
<table class="center"> <tr> <td style="text-align: center"><b>穿普拉达的女王</b></td> <td style="text-align: center"><b>绿皮书</b></td> <td style="text-align: center"><b>无间道</b></td> </tr> <tr> <td style="text-align: center"><a target="_blank" href="https://cdn.aondata.work/video/short_movie/Devil_Wears_Prada-480p.mp4"><img src="https://yellow-cdn.veclightyear.com/835a84d5/829680c9-1d81-429b-b2f0-0187e778f8a2.gif"></a></td> <td style="text-align: center"><a target="_blank" href="https://cdn.aondata.work/video/short_movie/Green_Book-480p.mp4"><img src="https://yellow-cdn.veclightyear.com/835a84d5/45d29388-2108-48e0-bce1-a99f277745da.gif"></a></td> <td style="text-align: center"><a target="_blank" href="https://cdn.aondata.work/video/short_movie/无间道-480p.mp4"><img src="https://yellow-cdn.veclightyear.com/835a84d5/a45e7a4d-2c83-4a66-98d1-d00b4143ae0b.gif"></a></td> </tr> <tr> <td style="text-align: center"><b>心灵捕手</b></td> <td style="text-align: center"><b>爱情呼叫转移</b></td> <td style="text-align: center"><b>肖申克的救赎</b></td> </tr> <tr> <td style="text-align: center"><a target="_blank" href="https://cdn.aondata.work/video/short_movie/Patch_Adams-480p.mp4"><img src="https://yellow-cdn.veclightyear.com/835a84d5/f22e7d9d-9665-4f2b-bc79-0ac2d8e089f8.gif"></a></td> <td style="text-align: center"><a target="_blank" href="https://cdn.aondata.work/video/short_movie/Tough_Love-480p.mp4"><img src="https://yellow-cdn.veclightyear.com/835a84d5/061977ef-6443-47a3-a360-57cbcd55bff7.gif"></a></td> <td style="text-align: center"><a target="_blank" href="https://cdn.aondata.work/video/short_movie/Shawshank-480p.mp4"><img src="https://yellow-cdn.veclightyear.com/835a84d5/b9884376-00f0-4116-a434-2b4629a2abc0.gif"></a></td> </tr> </table>探索更多示例。
📰 新闻
2024/06/28: 🎉🎉🎉 我们很高兴地宣布发布我们的模型训练代码。试试您自己的训练数据吧。这里是教程。2024/06/21: 🚀🚀🚀 在🤗Huggingface space上克隆了一个Gradio演示。2024/06/20: 🌟🌟🌟 收到了来自社区的众多贡献,包括Windows版本、ComfyUI、WebUI和Docker模板。2024/06/15: ✨✨✨ 在🤗Huggingface上发布了一些用于推理测试的图像和音频。2024/06/15: 🎉🎉🎉 在🫡GitHub上发布了第一个版本。
🤝 社区资源
探索由我们的社区开发的资源,以增强您使用Hallo的体验:
- TTS x Hallo 说话肖像生成器 - 查看由@Sylvain Filoni制作的这个精彩的Gradio演示!使用这个工具,您可以方便地为Hallo准备肖像图像和音频。
- Huggingface上的演示 - 查看由@multimodalart制作的这个易于使用的Gradio演示。
- hallo-webui - 探索由@daswer123创建的WebUI。
- hallo-for-windows - 使用@sdbds提供的指南在Windows上使用Hallo。
- ComfyUI-Hallo - 使用@AIFSH的ComfyUI工具集成Hallo。
- hallo-docker - 由@ashleykleynhans制作的Hallo Docker镜像。
- RunPod模板 - 由@ashleykleynhans将Hallo部署到RunPod。
感谢他们所有人。
加入我们的社区,探索这些令人惊叹的资源,充分利用Hallo。尽情享受并提升您的创意项目!
🔧️ 框架
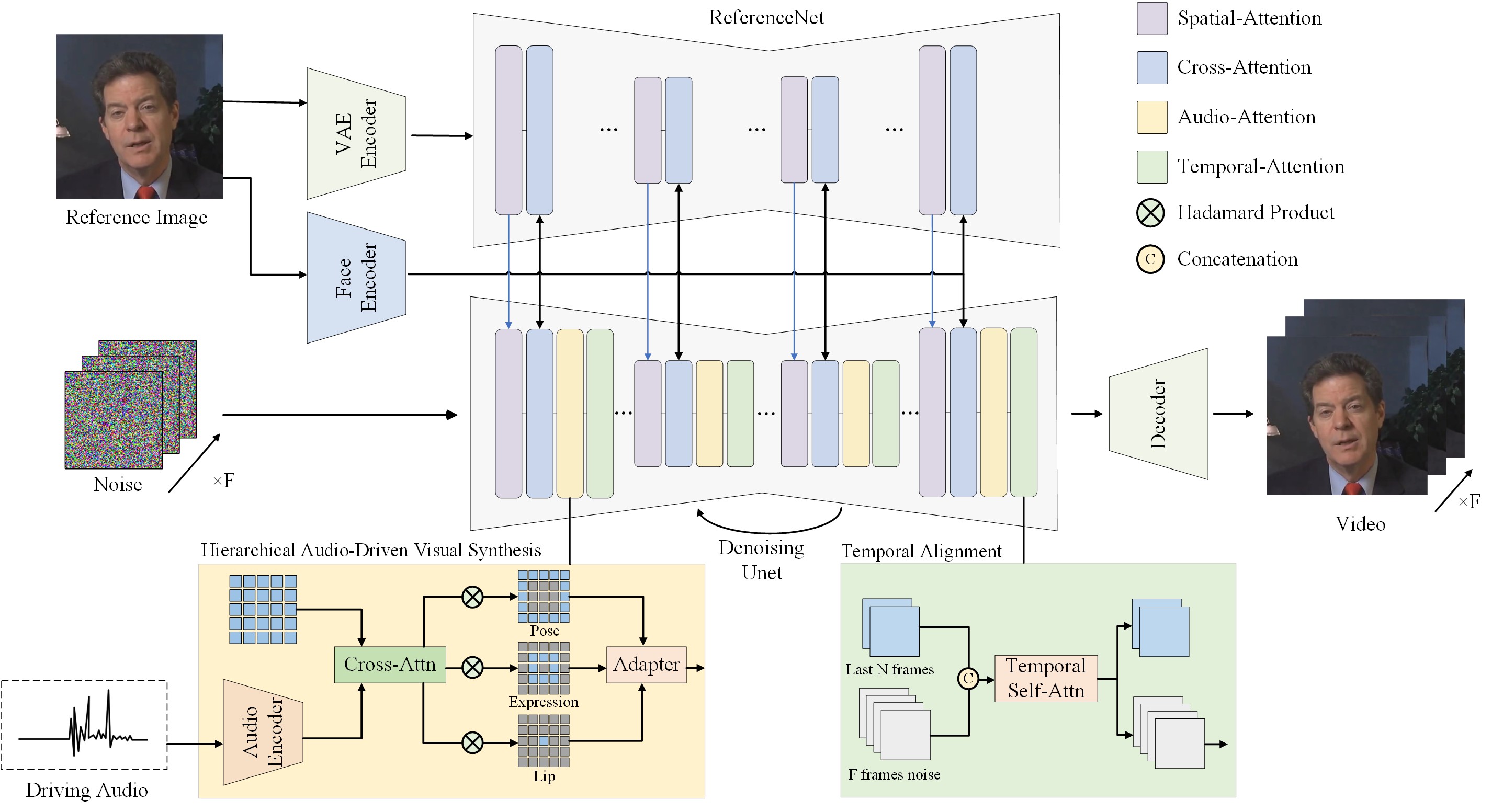
⚙️ 安装
- 系统要求:Ubuntu 20.04/Ubuntu 22.04,Cuda 12.1
- 已测试的GPU:A100
创建conda环境:
conda create -n hallo python=3.10 conda activate hallo
使用pip安装包:
pip install -r requirements.txt pip install .
此外,还需要安装ffmpeg:
apt-get install ffmpeg
🗝️️ 使用方法
推理的入口点是scripts/inference.py。在测试您的案例之前,需要完成两项准备工作:
📥 下载预训练模型
您可以从我们的HuggingFace仓库轻松获取推理所需的所有预训练模型。
通过以下命令将预训练模型克隆到${PROJECT_ROOT}/pretrained_models目录:
git lfs install git clone https://huggingface.co/fudan-generative-ai/hallo pretrained_models
或者您可以从它们的源仓库分别下载:
- hallo:我们的检查点包括去噪UNet、人脸定位器、图像和音频投影。
- audio_separator:Kim_Vocal_2 MDX-Net人声分离模型。(感谢KimberleyJensen)
- insightface:2D和3D人脸分析放置在
pretrained_models/face_analysis/models/中。(感谢deepinsight) - face landmarker:来自mediapipe的人脸检测和网格模型,放置在
pretrained_models/face_analysis/models中。 - motion module:来自AnimateDiff的运动模块。(感谢guoyww)
- sd-vae-ft-mse:权重旨在与diffusers库一起使用。(感谢stablilityai)
- StableDiffusion V1.5:从Stable-Diffusion-v1-2初始化和微调。(感谢runwayml)
- wav2vec:来自Facebook的wav音频到向量模型。
最终,这些预训练模型应组织如下:
./pretrained_models/ |-- audio_separator/ | |-- download_checks.json | |-- mdx_model_data.json | |-- vr_model_data.json | `-- Kim_Vocal_2.onnx |-- face_analysis/ | `-- models/ | |-- face_landmarker_v2_with_blendshapes.task # 来自mediapipe的人脸标记模型 | |-- 1k3d68.onnx | |-- 2d106det.onnx | |-- genderage.onnx | |-- glintr100.onnx | `-- scrfd_10g_bnkps.onnx |-- motion_module/ | `-- mm_sd_v15_v2.ckpt |-- sd-vae-ft-mse/ | |-- config.json | `-- diffusion_pytorch_model.safetensors |-- stable-diffusion-v1-5/ | `-- unet/ | |-- config.json | `-- diffusion_pytorch_model.safetensors `-- wav2vec/ `-- wav2vec2-base-960h/ |-- config.json |-- feature_extractor_config.json |-- model.safetensors |-- preprocessor_config.json |-- special_tokens_map.json |-- tokenizer_config.json `-- vocab.json
🛠️ 准备推理数据
Hallo对输入数据有一些简单的要求:
对于源图像:
- 应裁剪成正方形。
- 人脸应是主要焦点,占图像的50%-70%。
- 人脸应正面朝向,旋转角度小于30°(不要侧面轮廓)。
对于驱动音频:
- 必须是WAV格式。
- 必须是英语,因为我们的训练数据集仅包含这种语言。
- 确保人声清晰;背景音乐可以接受。
我们提供了一些样本供您参考。
🎮 运行推理
只需运行scripts/inference.py,并传入source_image和driving_audio作为输入:
python scripts/inference.py --source_image examples/reference_images/1.jpg --driving_audio examples/driving_audios/1.wav
默认情况下,动画结果将保存为${PROJECT_ROOT}/.cache/output.mp4。您可以传入--output来指定输出文件名。您可以在examples文件夹中找到更多推理示例。
更多选项:
usage: inference.py [-h] [-c CONFIG] [--source_image SOURCE_IMAGE] [--driving_audio DRIVING_AUDIO] [--output OUTPUT] [--pose_weight POSE_WEIGHT] [--face_weight FACE_WEIGHT] [--lip_weight LIP_WEIGHT] [--face_expand_ratio FACE_EXPAND_RATIO] 选项: -h, --help 显示此帮助信息并退出 -c CONFIG, --config CONFIG --source_image SOURCE_IMAGE 源图像 --driving_audio DRIVING_AUDIO 驱动音频 --output OUTPUT 输出视频文件名 --pose_weight POSE_WEIGHT 姿态权重 --face_weight FACE_WEIGHT 面部权重 --lip_weight LIP_WEIGHT 唇部权重 --face_expand_ratio FACE_EXPAND_RATIO 面部区域
训练
准备训练数据
训练数据使用一些类似于推理时使用的源图像的说话人脸视频,同样需要满足以下要求:
- 应裁剪成正方形。
- 人脸应是主要焦点,占图像的50%-70%。
- 人脸应正面朝向,旋转角度小于30°(不要侧面轮廓)。
将原始视频组织成以下目录结构:
dataset_name/ |-- videos/ | |-- 0001.mp4 | |-- 0002.mp4 | |-- 0003.mp4 | `-- 0004.mp4
您可以使用任何dataset_name,但确保videos目录命名如上所示。
接下来,使用以下命令处理视频:
python -m scripts.data_preprocess --input_dir dataset_name/videos --step 1 python -m scripts.data_preprocess --input_dir dataset_name/videos --step 2
**注意:**依次执行步骤1和2,因为它们执行不同的任务。步骤1将视频转换为帧,从每个视频中提取音频,并生成必要的掩码。步骤2使用InsightFace生成人脸嵌入,使用Wav2Vec生成音频嵌入,需要GPU。对于并行处理,使用-p和-r参数。-p参数指定要启动的实例总数,将数据分为p部分。-r参数指定当前进程应处理哪一部分。您需要手动启动多个实例,使用不同的-r值。
使用以下命令生成元数据JSON文件:
python scripts.extract_meta_info_stage1.py -r path/to/dataset -n dataset_name python scripts.extract_meta_info_stage2.py -r path/to/dataset -n dataset_name
将path/to/dataset替换为videos的父目录路径,如上例中的dataset_name。这将在./data目录中生成dataset_name_stage1.json和dataset_name_stage2.json。
训练
在配置YAML文件configs/train/stage1.yaml和configs/train/stage2.yaml中更新数据元路径设置:
#stage1.yaml data: meta_paths: - ./data/dataset_name_stage1.json #stage2.yaml data: meta_paths: - ./data/dataset_name_stage2.json
使用以下命令开始训练:
accelerate launch -m \ --config_file accelerate_config.yaml \ --machine_rank 0 \ --main_process_ip 0.0.0.0 \ --main_process_port 20055 \ --num_machines 1 \ --num_processes 8 \ scripts.train_stage1 --config ./configs/train/stage1.yaml
Accelerate使用说明
accelerate launch 命令用于启动具有分布式设置的训练过程。
accelerate launch [参数] {训练脚本} --{训练脚本参数1} --{训练脚本参数2} ...
Accelerate 的参数:
-m, --module:将启动脚本解释为 Python 模块。--config_file:Hugging Face Accelerate 的配置文件。--machine_rank:在多节点设置中当前机器的排名。--main_process_ip:主节点的 IP 地址。--main_process_port:主节点的端口。--num_machines:参与训练的节点总数。--num_processes:训练的进程总数,与所有机器上的 GPU 总数匹配。
训练参数:
{training_script}:训练脚本,如scripts.train_stage1或scripts.train_stage2。--{训练脚本参数1}:特定于训练脚本的参数。我们的训练脚本接受一个参数--config,用于指定训练配置文件。
对于多节点训练,你需要在每个节点上分别手动运行命令,使用不同的 machine_rank。
更多设置请参考 Accelerate 文档。
📅️ 路线图
| 状态 | 里程碑 | 预计时间 |
|---|---|---|
| ✅ | 推理源代码在 GitHub 上与大家见面 | 2024-06-15 |
| ✅ | 预训练模型在 Huggingface 上发布 | 2024-06-15 |
| ✅ | 发布数据准备和训练脚本 | 2024-06-28 |
| 🚀 | 提升模型在中文普通话上的表现 | 待定 |
- 改进:测试并确保与 Windows 操作系统的兼容性。#39
- 缺陷:输出视频可能会丢失几帧。#41
- 缺陷:声音音量影响推理结果(音频归一化)。
-
改进:推理代码逻辑优化。这个解决方案并未显示出明显的性能改进。正在尝试其他方法。
📝 引用
如果您发现我们的工作对您的研究有用,请考虑引用以下论文:
@misc{xu2024hallo,
title={Hallo: Hierarchical Audio-Driven Visual Synthesis for Portrait Image Animation},
author={Mingwang Xu and Hui Li and Qingkun Su and Hanlin Shang and Liwei Zhang and Ce Liu and Jingdong Wang and Yao Yao and Siyu zhu},
year={2024},
eprint={2406.08801},
archivePrefix={arXiv},
primaryClass={cs.CV}
}
🌟 招聘机会
复旦大学生成视觉实验室目前有多个研究岗位空缺!包括:
- 研究助理
- 博士后研究员
- 博士生
- 硕士生
有兴趣的个人可以通过 siyuzhu@fudan.edu.cn 联系我们获取更多信息。
⚠️ 社会风险与缓解措施
由音频驱动的人像图像动画技术的发展带来了社会风险,如创建可能被滥用于深度伪造的逼真肖像的伦理影响。为缓解这些风险,建立伦理准则和负责任的使用实践至关重要。使用个人图像和声音也引发了隐私和同意问题。解决这些问题需要透明的数据使用政策、知情同意和保护隐私权。通过解决这些风险并实施缓解措施,该研究旨在确保该技术的负责任和道德发展。
🤗 致谢
我们要感谢 magic-animate、AnimateDiff、ultimatevocalremovergui、AniPortrait 和 Moore-AnimateAnyone 仓库的贡献者,感谢他们的开放研究和探索。
如果我们遗漏了任何开源项目或相关文章,我们希望立即补充对这项具体工作的致谢。
👏 社区贡献者
感谢所有帮助改进这个项目的贡献者!
<a href="https://github.com/fudan-generative-vision/hallo/graphs/contributors"> <img src="https://contrib.rocks/image?repo=fudan-generative-vision/hallo" /> </a>编辑推荐精选


扣子-AI办公
职场AI,就用扣子
AI办公助手,复杂任务高效处理。办公效率低?扣子空间AI助手支持播客生成、PPT制作、网页开发及报告写作,覆盖科研、商业、舆情等领域的专家Agent 7x24小时响应,生活工作无缝切换,提升50%效率!


堆友
多风格AI绘画神器
堆友平台由阿里巴巴设计团队创建,作为一款AI驱动的设计工具,专为设计师提供一站式增长服务。功能覆盖海量3D素材、AI绘画、实时渲染以及专业抠图,显著提升设计品质和�效率。平台不仅提供工具,还是一个促进创意交流和个人发展的空间,界面友好,适合所有级别的设计师和创意工作者。


码上飞
零代码AI应用开发平台
零代码AI应用开发平台,用户只需一句话简单描述需求,AI能自动生成小程序、APP或H5网页应用,无需编写代码。


Vora
免费创建高清无水印Sora视频
Vora是一个免费创建高清无水印Sora视频的AI工具


Refly.AI
最适合小白的AI自动化工作流平台
无需编码,轻松生成可复用、可变现的AI自动化工作流


酷表ChatExcel
大模型驱动的Excel数据处理工具
基于大模型交互的表格处理系统,允许用户通过对话方式完成数据整理和可视化分析。系统采用机器学习算法解析用户指令,自动执行排序、公式计算和数据透视等操作,支持多种文件格式导入导出。数据处理响应速度保持在0.8秒以内,支持超过100万行数据的即时分析。


TRAE编程
AI辅助编程,代码自动修复
Trae是一种自适应的集成开发环境(IDE),通过自动化和多元协作改变开发流程。利用Trae,团队能够更快速、精确地编写和部署代码,从而提高编程效率和项目交付速度。Trae具备上下文感知和代码自动完成功能,是提升开发效率的理想工具。


AIWritePaper论文写作
AI论文写作指导平台
AIWritePaper论文写作是一站式AI论文写作辅助工具,简化了选题、文献检索至论文撰写的整个过程。通过简单设定,平台可快速生成高质量论文大纲和全文,配合图表、参考文献等一应俱全,同时提供开题报告和答辩PPT等增值服务,保障数据安全,有效提升写作效率和论文质量。


博思AIPPT
AI一键生成PPT,就用博思AIPPT!
博思AIPPT,新一代的AI生成PPT平台,支持智能生成PPT、AI美化PPT、文本&链接生成PPT、导入Word/PDF/Markdown文档生成PPT等,内置海量精美PPT模板,涵盖商务、教育、科技等不同风格,同时针对每个页面提供多种版式,一键自适应切换,完美适配各种办公场景。


潮际好麦
AI赋能电商视觉革命,一站式智能商拍平台
潮际好麦深耕服装行业,是国内AI试衣效果最好的软件。使用先进AIGC能力为电商卖家批量提供优质的、低成本的商拍图。合作品牌有Shein、Lazada、安踏、百丽等65个国内外头部品牌,以及国内10万+淘宝、天猫、京东等主流平台的品牌商家,为卖家节省将近85%的出图成本,提升约3倍出图效率,让品牌能够快速上架。
推荐工具精选




AI云服务特惠
懂AI专属折扣关注微信公众号
最新AI工具、AI资讯
独家AI资源、AI项目落地

微信扫一扫关注公众号