
joytag
多标签AI图像标记模型 支持5000+标签
JoyTag是基于ViT-B/16架构的AI视觉模型,专用于图像多标签分类。采用Danbooru标记体系,支持5000多个标签,适用于手绘和摄影等多种图像类型。模型在0.4阈值下F1分数达0.578,能为每张图像生成独立标签预测。可用于diffusion模型训练等多种应用场景。


JoyTag
JoyTag是一个最先进的人工智能视觉模型,用于图像标记,特别注重性积极性和包容性。它使用Danbooru标记方案,但适用于广泛的图像类型,从手绘到摄影作品。
快速信息
- 下载:HuggingFace
- 试用:HuggingFace Spaces
- 架构:ViT-B/16
- 分辨率:448x448x3
- 参数:91.5M
- 输出:多标签分类
- 标签:5000+
- 训练数据集:Danbooru 2021 + 辅助数据集
- 训练时间:6.6亿样本
- F1分数:0.578 @ 0.4阈值
示例

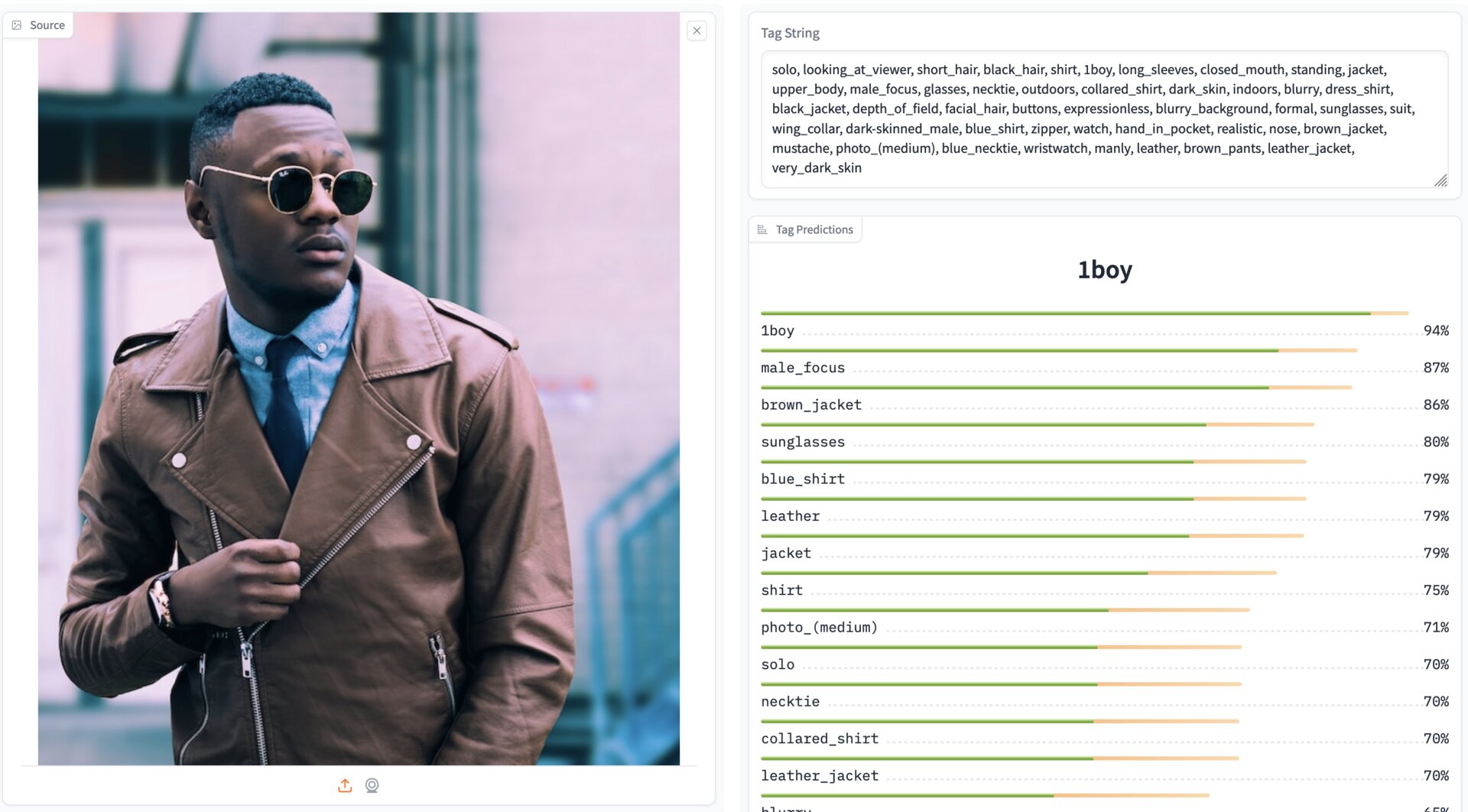
它能做什么?
输入一张图像,它会为5000多个不同标签给出预测。这是一个多标签模型,因此每个标签的预测是相互独立的,不像单类预测视觉模型。这使得自动"标记"图像成为可能,这对于广泛的应用非常有用,包括在缺少文本对的图像上训练扩散模型。
使用JoyTag模型
按上述方式下载模型。使用示例:
from Models import VisionModel from PIL import Image import torch.amp.autocast_mode from pathlib import Path import torch import torchvision.transforms.functional as TVF path = '/home/.../joytag/models' # 更改为您下载模型的位置 THRESHOLD = 0.4 model = VisionModel.load_model(path) model.eval() model = model.to('cuda') with open(Path(path) / 'top_tags.txt', 'r') as f: top_tags = [line.strip() for line in f.readlines() if line.strip()] def prepare_image(image: Image.Image, target_size: int) -> torch.Tensor: # 将图像填充为正方形 image_shape = image.size max_dim = max(image_shape) pad_left = (max_dim - image_shape[0]) // 2 pad_top = (max_dim - image_shape[1]) // 2 padded_image = Image.new('RGB', (max_dim, max_dim), (255, 255, 255)) padded_image.paste(image, (pad_left, pad_top)) # 调整图像大小 if max_dim != target_size: padded_image = padded_image.resize((target_size, target_size), Image.BICUBIC) # 转换为张量 image_tensor = TVF.pil_to_tensor(padded_image) / 255.0 # 标准化 image_tensor = TVF.normalize(image_tensor, mean=[0.48145466, 0.4578275, 0.40821073], std=[0.26862954, 0.26130258, 0.27577711]) return image_tensor @torch.no_grad() def predict(image: Image.Image): image_tensor = prepare_image(image, model.image_size) batch = { 'image': image_tensor.unsqueeze(0).to('cuda'), } with torch.amp.autocast_mode.autocast('cuda', enabled=True): preds = model(batch) tag_preds = preds['tags'].sigmoid().cpu() scores = {top_tags[i]: tag_preds[0][i] for i in range(len(top_tags))} predicted_tags = [tag for tag, score in scores.items() if score > THRESHOLD] tag_string = ', '.join(predicted_tags) return tag_string, scores image = Image.open('test.jpg') tag_string, scores = predict(image) print(tag_string) for tag, score in sorted(scores.items(), key=lambda x: x[1], reverse=True): print(f'{tag}: {score:.3f}')
目标
大多数公共视觉模型在训练数据集上进行了严格的过滤。这意味着当今的基础视觉模型在基本层面上对广泛的概念表现较弱。这限制了表达自由、包容性和多样性。它还限制了机器学习模型对我们世界的基本理解。JoyTag团队认为,人类用户应该有自由表达自己的权利,不应受到任意和反复无常的内容过滤歧视。JoyTag团队还认为,机器学习模型应该对世界有广泛、深入和包容的理解。这并不排除使用后训练对齐来减少模型中的偏见,但确实排除了使用会减少模型理解世界能力或用户表达能力的过滤或对齐。
JoyTag模型
当前的JoyTag模型是在Danbooru 2021数据集和一组手动标记的图像的组合上训练的,以扩展模型在danbooru领域之外的泛化能力。使用Danbooru数据集作为主要数据源是因为其规模(超过400万张人工标记的图像)、质量和标签的多样性。Danbooru使用的标记系统范围广泛且定义明确。然而,Danbooru数据集在内容多样性方面有限;它主要关注动漫/漫画风格的艺术。例如,数据集中只有0.3%是摄影图像。为了解决这个问题,JoyTag团队手动标记了一小部分来自互联网的图像,重点关注主要数据集中未很好表示的照片和其他内容。
最新的模型版本在整个数据集(包括照片)上实现了0.578的F1分数。在对训练或验证过程中未见过的图像进行手动测试时,该模型表现一致,证明了其良好的泛化能力。
JoyTag模型基于ViT架构,带有CNN干和GAP头。
训练详情
- 批量大小:4096
- LAMB优化器
- Adam Beta:(0.9, 0.999)
- Adam Epsilon:1e-6
- 权重衰减:0.05
- TF32
- FP16混合精度
- 梯度范数裁剪:1.0
- 简单增强
- 学习率:0.004
- 余弦衰减
- 无预热
- 无mixup
- 无标签平滑
- Focal loss,gamma=2.0
- 以224x224的分辨率训练2.2亿样本,然后以448x448的分辨率重新启动训练4.4亿样本。
用于训练JoyTag的脚本和流程在training目录中共享,以防对他人有用。
开发说明
目前模型主要受数据限制,如果超出当前训练方案或模型规模,就会出现过拟合。基于L/14@224的模型在过拟�合前能训练到0.51的F1分数。H/14模型也是如此,即使增加了StochDepth,也只有小幅F1提升就过拟合了。这是可以预料的,因为B/16@448的计算成本与L/14@224相似,但参数更少,因此似乎提供了一种在保持良好正则化的同时扩展模型的方法。
在我的测试中,无论是220M还是440M规模,MixUp和标签平滑都没有带来改进。Mixup提供了最强的正则化,但最终的F1分数反而低于不使用它的情况。根据扫描结果,当前的学习率、权重衰减和stochdepth率在220M范围内似乎接近最优。我们没有对448部分的训练设置进行实验,因此那里可能存在更优的学习率。
Trivial augment比RandAugment和其他数据增强方案效果更好,为防止过拟合提供了最佳解决方案。其他增强方法可能有助于进一步正则化并允许更多训练。
过拟合时,模型的F1tend趋于继续改善,而验证损失则急剧下降。
在220M扫描中,与普通BCE损失相比,Focal loss似乎没有显著差异。按标签频率加权也未能改善结果。
损失乘数对稳定训练至关重要,这可能是由于标签数量和极端分布与典型BCE任务相比导致损失过低,GradScaler无法处理。简单地将损失乘以128或256就足以稳定训练。
AdamW也有效,可以提供很小的F1改进,但LAMB结果在训练曲线上更稳定,且不需要调整预热计划。
对于B/16模型,使用CNN stem而不是传统的ViT补丁stem可以大幅提升F1。对于L/14模型,这种改进似乎较小。这方面可能需要更多研究。
局限性
虽然0.578的F1分数对于这样一个高度不平衡的多类任务来说已经很好,但还远非完美。JoyTag模型对NSFW概念的理解远超各种CLIP等基础模型,但在面部表情(笑、微笑、咧嘴笑等)等数据不足的细微概念上仍有失误。
一些概念是主观的,因此模型在这些概念上倾向��于摇摆不定,比如乳房大小。Danbooru对如何标记这些有明确的指导方针,但数据集本身并不完全符合这些指导方针。
额外数据的缺乏意味着当前模型对不常见的数据,如各种类型的服装和时尚,处理能力较弱。例如,"围裙"这个标签在辅助数据集中表现不佳,因此模型在处理它时遇到困难。
"水印"等标签仍然较弱,部分原因是缺乏优质数据,部分原因是即使在448x448分辨率下,许多水印对模型来说也太小而无法识别。
Danbooru标记系统主要针对动漫/漫画风格的艺术,因此尽管JoyTag团队认为该系统足以满足大多数摄影内容的需求,但其原始使用指南必须为摄影内容和模型需求进行"翻译"。例如,"鼻子"标签仅在Danbooru数据集中不到0.5%的情况下使用,因为它被指定为仅在鼻子"画得"比正常"更突出"时使用。这如何转化为摄影内容?JoyTag团队已尽最大努力翻译这些指南,但不平衡和冲突的标记规则使得这样的标签目前仍然存在问题。目前,JoyTag团队倾向于根据简单的"是否可见?"规则来标记照片,这被认为对模型、训练和下游任务来说更直接。"突出"的概念更适合用"*_focus"之类的标签来处理。
JoyTag团队的目标是让模型能够以同等技能处理各种内容,并专注于保持辅助数据集的多样性以减少偏见。然而,这是一场持续的战斗,永远是一项进行中的工作。例如,模型在处理"非常深的肤色"等标签时仍然存在困难。如果你发现模型在某个标签上表现不佳,请开启一个问题,让我们知道你的经历,以便我们更好地指导我们的努力。
指标
除了上面报告的平均F1外,更详细的每个标签指标可在full-metrics.txt中找到。所有指标都是在32,768�大小的验证集上报告的。使用PHash确保验证集不包含任何出现在训练数据中的图像。
在Validation Arena中可以找到与其他模型在未见过的图像上的比较。
未来工作
这是初始版本。JoyTag团队正忙于使用新训练的模型来协助标记更多图像,以扩展辅助数据集并改善模型当前的弱点。
特别感谢
特别感谢SmilingWolf,感谢他们在开创性地训练基于danbooru数据集的视觉模型方面所做的工作。
编辑推荐精选


Pixmax
一站式AI短剧创作平台
Pixmax专注打造下一代“ AI 视觉创作引擎”,整合行业顶尖 AI 大模型、工工业级精准控制及企业级协同管理功能,是全方位的 AI 内容创作平台。


豆包
字节跳动旗下 AI 智能助手
字节跳动旗下 AI 智能助手


GPT Plus|Pro充值
GPT充值
支持 ChatGPT Plus / Pro 充值服务,支付便捷,自动发货,售后可查。


GPT Image 2中文站
AI 图片生成平台
GPT Image 2 是面向用户的 AI 图片生成平台,支持文生图、图生图及多模型创意工作流。


Vecbase
你的AI Agent团队
Vecbase 是专为 AI 团队打造的智能工作空间,将数据管理、模型协作与知识沉淀整合于一处。算法、产品与业务在同一平台无缝协同,让从数据到 AI 应用的落地更快一步。


音述AI
全球首个AI音乐社区
音述AI是全球首个AI音乐社区,致力让每个人都能用音乐表达自我。音述AI提供零门槛AI创作工具,独创GETI法则帮助用户精准定义音乐风格,AI润色功能支持自动优化作品质感。音述AI支持交流讨论、二次创作与价值变现。针对中文用户的语言习惯与文化背景进行专门优化,支持国风融合、C-pop等本土音乐标签,让技术更好地承载人文表达。


QoderWork
阿里Qoder团队推出的桌面端AI智能体
QoderWork 是阿里推出的本地优先桌面 AI 智能体,适配 macOS14+/Windows10+,以自然语言交互实现文件管理、数据分析、AI 视觉生成、浏览器自动化等办公任务,自主拆解执行复杂工作流,数据本地运行零上传,技能市场可无限扩展,是高效的 Agentic 生产力办公助手。


lynote.ai
一站式搞定所有学习需求
不再被海量信息淹没,开始真正理解知识。Lynote 可摘要 YouTube 视频、PDF、文章等内容。即时创建笔记,检测 AI 内容并下载资料,将您的学习效率提升 10 倍。


AniShort
为AI短剧协作而生
专为AI短剧协作而生的AniShort正式发布,深度重构AI短剧全流程生产模式,整合创意策划、制作执行、实时协作、在线审片、资产复用等全链路功能,独创无限画布、双轨并行工业化工作流与Ani智能体助手,集成多款主流AI大模型,破解素材零散、版本混乱、沟通低效等行业痛点,助力3人团队效率提升800%,打造标准化、可追溯的AI短剧量产体系,是AI短剧团队协同创作、提升制作效率的核心工具。


seedancetwo2.0
能听懂你表达的视频模型
Seedance two是基于seedance2.0的中国大模型,支持图像、视频、音频、文本四种模态输入,表达方式更丰富,生成也更可控。
推荐工具精选






AI云服务特惠
懂AI专属折扣关注微信公众号
最新AI工具、AI资讯
独家AI资源、AI项目落地

微信扫一扫关注公众号