



从音频到照片级真实感化身:在对话中合成人类
本仓库包含了论文"从音频到照片级真实感化身:在对话中合成人类"的PyTorch实现
:hatching_chick: 在这里试用我们的演示,或继续按照以下步骤在本地运行代码! 感谢大家通过贡献/评论/问题提供的支持!
本代码库提供:
- 训练代码
- 测试代码
- 预训练的动作模型
- 数据集访问
如果您使用了数据集或代码,请引用我们的论文
@inproceedings{ng2024audio2photoreal,
title={From Audio to Photoreal Embodiment: Synthesizing Humans in Conversations},
author={Ng, Evonne and Romero, Javier and Bagautdinov, Timur and Bai, Shaojie and Darrell, Trevor and Kanazawa, Angjoo and Richard, Alexander},
booktitle={IEEE Conference on Computer Vision and Pattern Recognition},
year={2024}
}
仓库内容
- 快速开始: 简易的Gradio演示,让您可以录制音频并渲染视频
- 安装: 环境设置和安装(有关渲染管线的更多详情,请参阅Codec Avatar Body)
- 下载数据和模型: 下载标注和预训练模型
- 运行预训练模型: 如何生成结果文件并使用渲染管线可视化结果。
- 从头开始训练(3个模型): 从头开始运行面部、引导姿势和身体模型的训练管线的脚本。
我们用 :point_down: 图标标注了可以直接复制粘贴到终端的代码。
快速开始
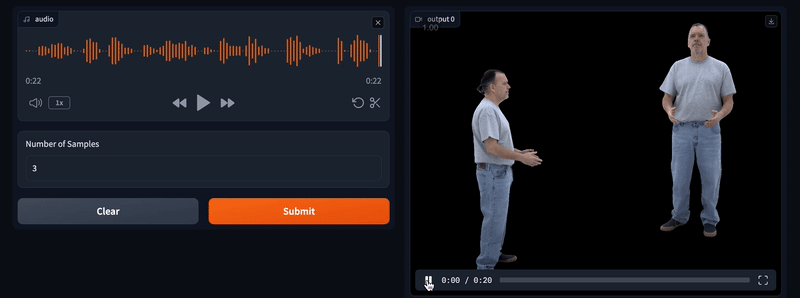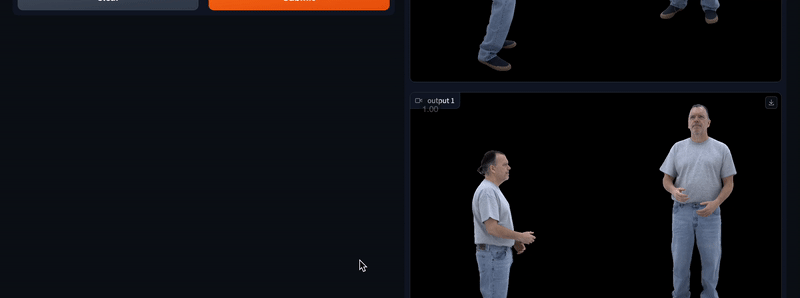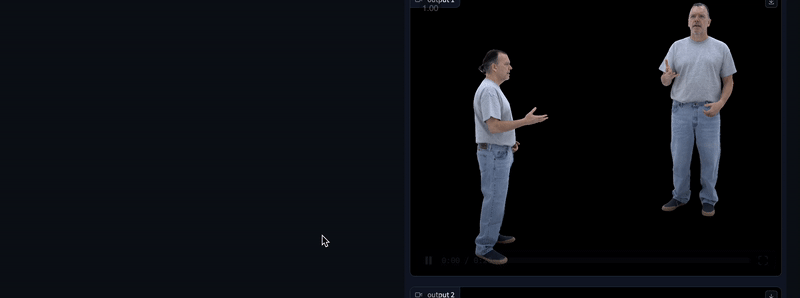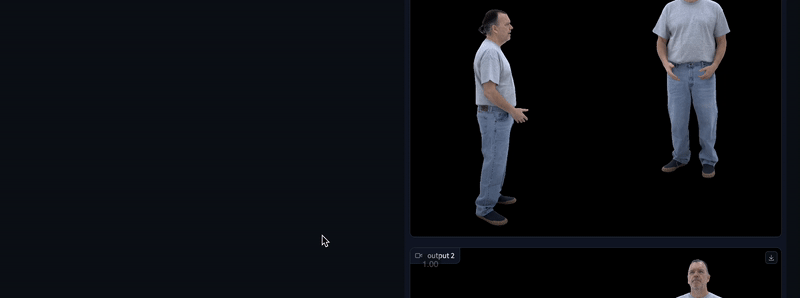
使用这个演示,您可以录制音频片段并选择要生成的样本数量。
确保您有CUDA 11.7和gcc/++ 9.0以兼容pytorch3d
:point_down: 安装必要组件。这将进行环境配置并安装相应的渲染资产、先决条件模型和预训练模型:
conda create --name a2p_env python=3.9
conda activate a2p_env
sh demo/install.sh
:point_down: 运行演示。您可以录制音频,然后渲染相应的结果!
python -m demo.demo
:microphone: 首先,录制您的音频
:hourglass: 请耐心等待,因为渲染可能需要一段时间!
您可以更改要生成的样本数量(1-10),并通过点击每个视频右上角的下载按钮下载您喜欢的视频。
安装
代码已在CUDA 11.7和Python 3.9,gcc/++ 9.0环境下测试通过
:point_down: 如果您尚未通过演示设置完成,请配置环境并下载先决条件模型:
conda create --name a2p_env python=3.9
conda activate a2p_env
pip install -r scripts/requirements.txt
sh scripts/download_prereq.sh
:point_down: 为了使渲染正常工作,请确保您也安装了pytorch3d。
pip install "git+https://github.com/facebookresearch/pytorch3d.git"
有关渲染器的更多详细信息,请参阅CA Bodies仓库。
下载数据和模型
要下载任何数据集,您可以在https://github.com/facebookresearch/audio2photoreal/releases/download/v1.0/<person_id>.zip找到它们,其中您可以将<person_id>替换为PXB184、RLW104、TXB805或GQS883中的任何一个。
可以使用以下命令通过命令行下载。
curl -L https://github.com/facebookresearch/audio2photoreal/releases/download/v1.0/<person_id>.zip -o <person_id>.zip
unzip <person_id>.zip -d dataset/
rm <person_id>.zip
:point_down: 要下载所有数据集,您可以简单地运行以下命令,它将下载并解压所有模型。
sh scripts/download_alldatasets.sh
同样,要下载任何模型,您可以在http://audio2photoreal_models.berkeleyvision.org/<person_id>_models.tar找到它们。
# 下载动作生成
wget http://audio2photoreal_models.berkeleyvision.org/<person_id>_models.tar
tar xvf <person_id>_models.tar
rm <person_id>_models.tar
# 下载身体解码器/渲染资产并将它们放在正确的位置
mkdir -p checkpoints/ca_body/data/
wget https://github.com/facebookresearch/ca_body/releases/download/v0.0.1-alpha/<person_id>.tar.gz
tar xvf <person_id>.tar.gz --directory checkpoints/ca_body/data/
rm <person_id>.tar.gz
:point_down: 您也可以使用此脚本下载所有模型:
sh scripts/download_allmodels.sh
上述模型脚本将下载both动作生成模型和身体解码器/渲染模型。请查看脚本以获取更多详细信息。
数据集
一旦数据集下载并解压(通过scripts/download_datasets.sh),它应该展开成以下目录结构:
|-- dataset/
|-- PXB184/
|-- data_stats.pth
|-- scene01_audio.wav
|-- scene01_body_pose.npy
|-- scene01_face_expression.npy
|-- scene01_missing_face_frames.npy
|-- ...
|-- scene30_audio.wav
|-- scene30_body_pose.npy
|-- scene30_face_expression.npy
|-- scene30_missing_face_frames.npy
|-- RLW104/
|-- TXB805/
|-- GQS883/
四位参与者(PXB184, RLW104, TXB805, GQS883)中的每一位应该有独立的"场景"(1到26左右)。
对于每个场景,我们保存了3种类型的数据标注。
*audio.wav:包含原始音频的波形文件(两个通道,1600*T个样本),采样率为48kHz;通道0是当前人物的音频,通道1是其对话伙伴的音频。
*body_pose.npy:(T x 104)数组,表示运动学骨骼中的关节角度。并非所有关节都用3自由度表示。每个104维向量可用于重建完整的身体骨骼。
*face_expression.npy:(T x 256)数组,表示面部编码,其中每个256维向量可重建一个面部网格。
*missing_face_frames.npy:面部编码缺失或损坏的帧索引(t)列表。
data_stats.pth:包含每个人每种模态的均值和标准差。
对于训练/验证/测试集的划分,索引在data_loaders/data.py中定义如下:
train_idx = list(range(0, len(data_dict["data"]) - 6))
val_idx = list(range(len(data_dict["data"]) - 6, len(data_dict["data"]) - 4))
test_idx = list(range(len(data_dict["data"]) - 4, len(data_dict["data"])))
这适用于我们训练的四个数据集参与者中的任何一个。
可视化真实数据
如果你正确安装了渲染依赖,你可以使用以下命令可视化完整数据集:
python -m visualize.render_anno
--save_dir <保存目录路径>
--data_root <数据根目录路径>
--max_seq_length <数字>
视频将根据指定的--max_seq_length参数分段,你可以自行指定(默认为600)。
:point_down: 例如,要可视化PXB184的真实数据标注,你可以运行以下命令:
python -m visualize.render_anno --save_dir vis_anno_test --data_root dataset/PXB184 --max_seq_length 600
预训练模型
我们训练的是针对特定人物的模型,所以每个人都应该有一个关联的目录。例如,对于PXB184,其完整模型解压后应该有以下结构:
|-- checkpoints/
|-- diffusion/
|-- c1_face/
|-- args.json
|-- model:09d.pt
|-- c1_pose/
|-- args.json
|-- model:09d.pt
|-- guide/
|-- c1_pose/
|-- args.json
|-- checkpoints/
|-- iter-:07d.pt
|-- vq/
|-- c1_pose/
|-- args.json
|-- net_iter:06d.pth
每个人有4个模型,每个模型都有一个关联的args.json。
- 一个面部扩散模型,根据音频输出256个面部编码
- 一个姿势扩散模型,根据音频和引导姿势输出104个关节旋转
- 一个引导VQ姿势模型,以1fps的速度根据音频输出VQ标记
- 一个VQ编码器-解码器模型,对连续的104维姿势空间进行向量量化。
运行预训练模型
要运行实际模型,你需要运行预训练模型并生成相关的结果文件,然后再进行可视化。
面部生成
要生成面部的结果文件,运行:
python -m sample.generate
--model_path <模型路径>
--num_samples <样本数>
--num_repetitions <重复次数>
--timestep_respacing ddim500
--guidance_param 10.0
<模型路径>应该是与生成面部相关的扩散模型的路径。
例如,对于参与者PXB184,路径可能是./checkpoints/diffusion/c1_face/model000155000.pt
其他参数说明:
--num_samples:要生成的样本数。要采样完整数据集,使用56(除了TXB805,使用58)。
--num_repetitions:重复采样的次数,使得生成的总序列数为(num_samples * num_repetitions)。
--timestep_respacing:采取多少个扩散步骤。格式始终为ddim<数字>。
--guidance_param:条件对结果的影响程度。我通常使用2.0-10.0的范围,对于面部倾向于使用较高值。
:point_down: 使用提供的预训练模型为PXB184运行面部模型的完整示例如下:
python -m sample.generate --model_path checkpoints/diffusion/c1_face/model000155000.pt --num_samples 10 --num_repetitions 5 --timestep_respacing ddim500 --guidance_param 10.0
这将从数据集中生成10个样本1次。输出结果文件将保存在:
./checkpoints/diffusion/c1_face/samples_c1_face_000155000_seed10_/results.npy
身体生成
生成相应的身体与生成面部非常相似,但现在我们还需要提供用于生成引导姿势的模型。
python -m sample.generate
--model_path <模型路径>
--resume_trans <引导模型路径>
--num_samples <样本数>
--num_repetitions <重复次数>
--timestep_respacing ddim500
--guidance_param 2.0
:point_down: 这里,<引导模型路径>应指向引导变换器。完整命令如下:
python -m sample.generate --model_path checkpoints/diffusion/c1_pose/model000340000.pt --resume_trans checkpoints/guide/c1_pose/checkpoints/iter-0100000.pt --num_samples 10 --num_repetitions 5 --timestep_respacing ddim500 --guidance_param 2.0
同样,输出将保存在:
./checkpoints/diffusion/c1_pose/samples_c1_pose_000340000_seed10_guide_iter-0100000.pt/results.npy
可视化
在身体生成方面,你还可以选择传入--plot标志来渲染逼真的头像。你还需要使用--face_codes标志传入相应生成的面部编码。
如果你已经预先计算了姿势,也可以选择使用--pose_codes标志传入生成的身体。
这将在保存身体results.npy的同一目录中保存视频。
:point_down: 包含三个新标志的完整命令示例如下:
python -m sample.generate --model_path checkpoints/diffusion/c1_pose/model000340000.pt --resume_trans checkpoints/guide/c1_pose/checkpoints/iter-0100000.pt --num_samples 10 --num_repetitions 5 --timestep_respacing ddim500 --guidance_param 2.0 --face_codes ./checkpoints/diffusion/c1_face/samples_c1_face_000155000_seed10_/results.npy --pose_codes ./checkpoints/diffusion/c1_pose/samples_c1_pose_000340000_seed10_guide_iter-0100000.pt/results.npy --plot
其余标志可以保持不变。关于实际的渲染API,请参阅Codec Avatar Body了解安装等信息。
*重要提示:为了可视化完整的真实感头像,你需要先运行面部编码,然后将其传入身体生成代码中。*如果你尝试对面部编码使用--plot调用生成,将无法正常工作。
从头开始训练
你需要训练四个可能的模型:1) 面部扩散模型,2) 身体扩散模型,3) 身体VQ VAE,4) 身体引导transformer。 唯一的依赖关系是4)需要3)。所有其他模型可以并行训练。
1) 面部扩散模型
要训练面部模型,你需要运行以下脚本:
python -m train.train_diffusion
--save_dir <保存目录路径>
--data_root <数据根目录路径>
--batch_size <批次大小>
--dataset social
--data_format face
--layers 8
--heads 8
--timestep_respacing ''
--max_seq_length 600
重要的是,一些标志如下:
--save_dir: 存储所有输出的目录路径
--data_root: 加载数据的目录路径
--dataset: 要加载的数据集名称;目前我们只支持'social'数据集
--data_format: 设置为'face'表示面部,而不是姿势
--timestep_respacing: 设置为'',表示默认的1000步扩散步骤间隔
--max_seq_length: 训练时单个序列的最大帧数
:point_down: 对人物PXB184进行训练的完整示例如下:
python -m train.train_diffusion --save_dir checkpoints/diffusion/c1_face_test --data_root ./dataset/PXB184/ --batch_size 4 --dataset social --data_format face --layers 8 --heads 8 --timestep_respacing '' --max_seq_length 600
2) 身体扩散模型
训练身体模型与面部模型类似,但有以下额外参数:
python -m train.train_diffusion
--save_dir <保存目录路径>
--data_root <数据根目录路径>
--lambda_vel <数值>
--batch_size <批次大小>
--dataset social
--add_frame_cond 1
--data_format pose
--layers 6
--heads 8
--timestep_respacing ''
--max_seq_length 600
与面部训练不同的标志如下:
--lambda_vel: 使用速度进行训练的额外辅助损失
--add_frame_cond: 设置为'1'表示1 fps。如果未指定,默认为30 fps。
--data_format: 设置为'pose'表示身体,而不是面部
:point_down: 对人物PXB184进行训练的完整示例如下:
python -m train.train_diffusion --save_dir checkpoints/diffusion/c1_pose_test --data_root ./dataset/PXB184/ --lambda_vel 2.0 --batch_size 4 --dataset social --add_frame_cond 1 --data_format pose --layers 6 --heads 8 --timestep_respacing '' --max_seq_length 600
3) 身体VQ VAE
要训练VQ编码器-解码器,你需要运行以下脚本:
python -m train.train_vq
--out_dir <输出目录路径>
--data_root <数据根目录路径>
--batch_size <批次大小>
--lr 1e-3
--code_dim 1024
--output_emb_width 64
--depth 4
--dataname social
--loss_vel 0.0
--add_frame_cond 1
--data_format pose
--max_seq_length 600
:point_down: 对人物PXB184来说,命令如下:
python -m train.train_vq --out_dir checkpoints/vq/c1_vq_test --data_root ./dataset/PXB184/ --lr 1e-3 --code_dim 1024 --output_emb_width 64 --depth 4 --dataname social --loss_vel 0.0 --data_format pose --batch_size 4 --add_frame_cond 1 --max_seq_length 600
4) 身体引导transformer
一旦�你从3)训练了VQ模型,你就可以将其传入以训练身体引导姿势transformer:
python -m train.train_guide
--out_dir <输出目录路径>
--data_root <数据根目录路径>
--batch_size <批次大小>
--resume_pth <VQ模型路径>
--add_frame_cond 1
--layers 6
--lr 2e-4
--gn
--dim 64
:point_down: 对人物PXB184来说,命令如下:
python -m train.train_guide --out_dir checkpoints/guide/c1_trans_test --data_root ./dataset/PXB184/ --batch_size 4 --resume_pth checkpoints/vq/c1_vq_test/net_iter300000.pth --add_frame_cond 1 --layers 6 --lr 2e-4 --gn --dim 64
训练完这4个模型后,你现在可以按照"运行预训练模型"部分生成样本并可视化结果。
你也可以通过传入--render_gt标志来可视化相应的地面真实序列。
许可证
代码和数据集根据CC-NC 4.0 International license发布。
编辑推荐精选


扣子-AI办公
职场AI,就用扣子
AI办公助手,复杂任务高效处理。办公效率低?扣子空间AI助手支持播客生成、PPT制作、网页开发及报告写作,覆盖科研、商业、舆情等领域的专家Agent 7x24小时响应,生活工作无缝切换,提升50%效率!


堆友
多风格AI绘画神器
堆友平台由阿里巴巴设计团队创建,作为一款AI驱动的设计工具,专为设计师提供一站式增长服务。功能覆盖海量3D素材、AI绘画、实时渲染以及专业抠图,显著提升设计品质和效率。平台不仅提供工具,还是一个促进创意交流和个人发展的空间,界面友好,适合所有级别的设计师和创意工作者。


码上飞
零代码AI应用开发平台
零代码AI应用开发平台,用户只需一句话简单描述需求,AI能自动生成小程序、APP或H5网页应用,无需编写代码。


Vora
免费创建高清无水印Sora视频
Vora是一个免费创建高清无水印Sora视频的AI工具


Refly.AI
最适合小白的AI自动化工作流平台
无需编码,轻松生成可复用、可变现的AI自动化工作流


酷表ChatExcel
大模型驱动的Excel数据处理工具
基于大模型交互的表格处理系统,允许用户通过对话方式完成数据整理和可视化分析。系统采用机器学习算法解析用户指令,自动执行排序、公式计算和数据透视等操作,支持多种文件格式导入导出。数据处理响应速度保持在0.8秒以内,支持超过100万行数据的即时分析。


TRAE编程
AI辅助编程,代码自动修复
Trae是一种自适应的集成开发环境(IDE),通过自动化和多元协作改变开发流程。利用Trae,团队能够更快速、精确地编写和部署代码,从而提高编程效率和项目交付速度。Trae具备上下文感知和代码自动完成功能,是提升开发效率的理想工具。


AIWritePaper论文写作
AI论文写作指导平台
AIWritePaper论文写作是一站式AI论文写作辅助工具,简化了选题、文献检索至论文撰写的整个过程。通过简单设定,平台可快速生成高质量论文大纲和全文,配合图表、参考文献等一应俱全,同时提供开题报告和答辩PPT等增值服务,保障数据安全,有效提升写作效率和论文质量。


博思AIPPT
AI一键生成PPT,就用博思AIPPT!
博思AIPPT,新一代的AI生成PPT平台,支持智能生成PPT、AI美化PPT、文本&链接生成PPT、导入Word/PDF/Markdown文档生成PPT等,内置海量精美PPT模板,涵盖商务、教育、科技等不同风格,同时针对每个页面提供多种版式,一键自适应切换,完美适配各种办公场景。


潮际好麦
AI赋能电商视觉革命,一站式智能商拍平台
潮际好麦深耕服装行业,是国内AI试衣效果最好的软件。使用先进AIGC能力为电商卖家批量提供优质的、低成本的商拍图。合作品牌有Shein、Lazada、安踏、百丽等65个国内外头部品牌,以及国内10万+淘宝、天猫、京东等主流平台的品牌商家,为卖家节省将近85%的出图成本,提升约3倍出图效率,让品牌能够快速上架。
推荐工具精选




AI云服务特惠
懂AI专属折扣关注微�信公众号
最新AI工具、AI资讯
独家AI资源、AI项目落地

微信扫一扫关注公众号