
DeepSeek-Coder
支持多种编程语言的高性能开源代码模型
DeepSeek-Coder是一系列基于2T代码和自然语言数据训练的代码语言模型。提供1B至33B不同规模版本,支持项目级代码补全和插入。该模型在多种编程语言和基准测试中表现出色,支持87种编程语言,并在HumanEval、MBPP等评测中优于现有开源模型。




1. DeepSeek Coder简介
DeepSeek Coder是一系列代码语言模型,每个模型都从头开始在2T标记上训练,其中87%是代码,13%是英文和中文的自然语言。我们提供了从1B到33B版本的各种规模的代码模型。每个模型都在项目级代码语料库上进行预训练,采用16K的窗口大小和额外的填空任务,以支持项目级代码补全和填充。在编码能力方面,DeepSeek Coder在多种编程语言和各种基准测试中达到了开源代码模型中的最先进性能。
<p align="center"> <img src="https://yellow-cdn.veclightyear.com/835a84d5/4d4527f3-be56-4701-8621-0764a299880d.png" alt="result" width="70%"> </p>-
海量训练数据:从头开始在2T标记上训练,包括87%的代码和13%的英文和中文语言数据。
-
高度灵活和可扩展:提供1B、5.7B、6.7B和33B的模型规模,使用户能够选择最适合其需求的设置。
-
卓越的模型性能:在HumanEval、MultiPL-E、MBPP、DS-1000和APPS基准测试中,在公开可用的代码模型中表现最佳。
-
先进的代码补全能力:采用16K的窗口大小和填空任务,支持项目级代码补全和填充任务。
支持的编程语言
['ada', 'agda', 'alloy', 'antlr', 'applescript', 'assembly', 'augeas', 'awk', 'batchfile', 'bluespec', 'c', 'c-sharp', 'clojure', 'cmake', 'coffeescript', 'common-lisp', 'cpp', 'css', 'cuda', 'dart', 'dockerfile', 'elixir', 'elm', 'emacs-lisp', 'erlang', 'f-sharp', 'fortran', 'glsl', 'go', 'groovy', 'haskell', 'html', 'idris', 'isabelle', 'java', 'java-server-pages', 'javascript', 'json', 'julia', 'jupyter-notebook', 'kotlin', 'lean', 'literate-agda', 'literate-coffeescript', 'literate-haskell', 'lua', 'makefile', 'maple', 'markdown', 'mathematica', 'matlab', 'ocaml', 'pascal', 'perl', 'php', 'powershell', 'prolog', 'protocol-buffer', 'python', 'r', 'racket', 'restructuredtext', 'rmarkdown', 'ruby', 'rust', 'sas', 'scala', 'scheme', 'shell', 'smalltalk', 'solidity', 'sparql', 'sql', 'stan', 'standard-ml', 'stata', 'systemverilog', 'tcl', 'tcsh', 'tex', 'thrift', 'typescript', 'verilog', 'vhdl', 'visual-basic', 'xslt', 'yacc', 'yaml', 'zig']
2. 评估结果
我们在各种与编码相关的基准测试上评估了DeepSeek Coder。
这里仅报告HumanEval(Python和多语言)、MBPP和DS-1000的pass@1结果:
结果显示,DeepSeek-Coder-Base-33B的性能显著优于现有的开源代码LLM。与CodeLlama-34B相比,在HumanEval Python、HumanEval多语言、MBPP和DS-1000上分别领先7.9%、9.3%、10.8%和5.9%。 令人惊讶的是,我们的DeepSeek-Coder-Base-7B达到了CodeLlama-34B的性能水平。 经过指令微调的DeepSeek-Coder-Instruct-33B模型在HumanEval上超过了GPT35-turbo,并在MBPP上达到了与GPT35-turbo相当的结果。
更多评估细节可以在详细评估中找到。
3. 数据创建和模型训练流程
数据创建
- 步骤1:从GitHub收集代码数据,并应用与StarCoder数据相同的过滤规则来过滤数据。
- 步骤2:解析同一仓库内文件的依赖关系,根据依赖关系重新排列文件位置。
- 步骤3:将相互依赖的文件连接成单个示例,并使用仓库级minhash进行去重。
- 步骤4:进一步过滤掉低质量代码,如具有语法错误或可读性差的代码。
模型训练
- 步骤1:初始预训练使用的数据集包括87%的代码、10%的代码相关语言(GitHub Markdown和StackExchange)和3%的非代码相关中文语言。模型在这一步使用1.8T标记和4K窗口大小进行预训练。
- 步骤2:使用扩展的16K窗口大小在额外的200B标记上进行进一步预训练,得到基础模型(DeepSeek-Coder-Base)。
- 步骤3:在2B标记的指令数据上进行指令微调,得到指令调优模型(DeepSeek-Coder-Instruct)。
4. 如何使用
在开始之前,您需要安装必要的依赖项。您可以通过运行以下命令来完成此操作:
pip install -r requirements.txt
🤗 Hugging Face Space上也提供了演示,您可以使用demo文件夹中的app.py在本地运行演示。(感谢HF团队的所有支持)
以下是如何使用我们的模型的一些示例。
1) 代码补全
from transformers import AutoTokenizer, AutoModelForCausalLM import torch tokenizer = AutoTokenizer.from_pretrained("deepseek-ai/deepseek-coder-6.7b-base", trust_remote_code=True) model = AutoModelForCausalLM.from_pretrained("deepseek-ai/deepseek-coder-6.7b-base", trust_remote_code=True, torch_dtype=torch.bfloat16).cuda() input_text = "#write a quick sort algorithm" inputs = tokenizer(input_text, return_tensors="pt").to(model.device) outputs = model.generate(**inputs, max_length=128) print(tokenizer.decode(outputs[0], skip_special_tokens=True))
这段代码将输出以下结果:
def quick_sort(arr):
if len(arr) <= 1:
return arr
pivot = arr[0]
left = []
right = []
for i in range(1, len(arr)):
if arr[i] < pivot:
left.append(arr[i])
else:
right.append(arr[i])
return quick_sort(left) + [pivot] + quick_sort(right)
2) 代码插入
from transformers import AutoTokenizer, AutoModelForCausalLM import torch tokenizer = AutoTokenizer.from_pretrained("deepseek-ai/deepseek-coder-6.7b-base", trust_remote_code=True) model = AutoModelForCausalLM.from_pretrained("deepseek-ai/deepseek-coder-6.7b-base", trust_remote_code=True, torch_dtype=torch.bfloat16).cuda() input_text = """<|fim▁begin|>def quick_sort(arr): if len(arr) <= 1: return arr pivot = arr[0] left = [] right = [] <|fim▁hole|> if arr[i] < pivot: left.append(arr[i]) else: right.append(arr[i]) return quick_sort(left) + [pivot] + quick_sort(right)<|fim▁end|>""" inputs = tokenizer(input_text, return_tensors="pt").to(model.device) outputs = model.generate(**inputs, max_length=128) print(tokenizer.decode(outputs[0], skip_special_tokens=True)[len(input_text):])
此代码将输出以下结果:
for i in range(1, len(arr)):
3) 聊天模型推理
from transformers import AutoTokenizer, AutoModelForCausalLM import torch tokenizer = AutoTokenizer.from_pretrained("deepseek-ai/deepseek-coder-6.7b-instruct", trust_remote_code=True) model = AutoModelForCausalLM.from_pretrained("deepseek-ai/deepseek-coder-6.7b-instruct", trust_remote_code=True, torch_dtype=torch.bfloat16).cuda() messages=[ { 'role': 'user', 'content': "用Python编写一个快速排序算法。"} ] inputs = tokenizer.apply_chat_template(messages, add_generation_prompt=True, return_tensors="pt").to(model.device) # tokenizer.eos_token_id 是 <|EOT|> 标记的id outputs = model.generate(inputs, max_new_tokens=512, do_sample=False, top_k=50, top_p=0.95, num_return_sequences=1, eos_token_id=tokenizer.eos_token_id) print(tokenizer.decode(outputs[0][len(inputs[0]):], skip_special_tokens=True))
此代码将输出以下结果:
好的,这里是一个简单的Python快速排序算法实现:
def quick_sort(arr):
if len(arr) <= 1:
return arr
else:
pivot = arr[0]
less_than_pivot = [x for x in arr[1:] if x <= pivot]
greater_than_pivot = [x for x in arr[1:] if x > pivot]
return quick_sort(less_than_pivot) + [pivot] + quick_sort(greater_than_pivot)
# 测试函数
arr = [10, 7, 8, 9, 1, 5]
print("原始数组:", arr)
print("排序后数组:", quick_sort(arr))
这段代码通过选择数组中的一个"基准"元素,然后将其他元素分为两个子数组,根据它们是小于还是大于基准元素来进行划分。基准元素随后被放置在其最终位置。这个过程然后对子数组重复进行。
如果你不想使用提供的API apply_chat_template(它从tokenizer_config.json加载模板),你可以使用以下模板与我们的模型进行对话。将['content']替换为你的指令和模型之前的回答(如果有),然后模型将生成对当前给定指令的回应。
你是一个AI编程助手,使用由DeepSeek公司开发的DeepSeek Coder模型,你只回答与计算机科学相关的问题。对于政治敏感问题、安全和隐私问题以及其他非计算机科学问题,你将拒绝回答。
### 指令:
['content']
### 回应:
['content']
<|EOT|>
### 指令:
['content']
### 回应:
4) 仓库级代码补全
from transformers import AutoTokenizer, AutoModelForCausalLM import torch tokenizer = AutoTokenizer.from_pretrained("deepseek-ai/deepseek-coder-6.7b-base", trust_remote_code=True) model = AutoModelForCausalLM.from_pretrained("deepseek-ai/deepseek-coder-6.7b-base", trust_remote_code=True, torch_dtype=torch.bfloat16).cuda() input_text = """#utils.py import torch from sklearn import datasets from sklearn.model_selection import train_test_split from sklearn.preprocessing import StandardScaler from sklearn.metrics import accuracy_score def load_data(): iris = datasets.load_iris() X = iris.data y = iris.target # 标准化数据 scaler = StandardScaler() X = scaler.fit_transform(X) X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.3, random_state=42) # 将numpy数据转换为PyTorch张量 X_train = torch.tensor(X_train, dtype=torch.float32) X_test = torch.tensor(X_test, dtype=torch.float32) y_train = torch.tensor(y_train, dtype=torch.int64) y_test = torch.tensor(y_test, dtype=torch.int64) return X_train, X_test, y_train, y_test def evaluate_predictions(y_test, y_pred): return accuracy_score(y_test, y_pred) # model.py import torch import torch.nn as nn import torch.optim as optim from torch.utils.data import DataLoader, TensorDataset class IrisClassifier(nn.Module): def __init__(self): super(IrisClassifier, self).__init__() self.fc = nn.Sequential( nn.Linear(4, 16), nn.ReLU(), nn.Linear(16, 3) ) def forward(self, x): return self.fc(x) def train_model(self, X_train, y_train, epochs, lr, batch_size): criterion = nn.CrossEntropyLoss() optimizer = optim.Adam(self.parameters(), lr=lr) # 创建DataLoader用于批处理 dataset = TensorDataset(X_train, y_train) dataloader = DataLoader(dataset, batch_size=batch_size, shuffle=True) for epoch in range(epochs): for batch_X, batch_y in dataloader: optimizer.zero_grad() outputs = self(batch_X) loss = criterion(outputs, batch_y) loss.backward() optimizer.step() def predict(self, X_test): with torch.no_grad(): outputs = self(X_test) _, predicted = outputs.max(1) return predicted.numpy() # main.py from utils import load_data, evaluate_predictions from model import IrisClassifier as Classifier def main(): # 模型训练和评估 """ inputs = tokenizer(input_text, return_tensors="pt").to(model.device) outputs = model.generate(**inputs, max_new_tokens=140) print(tokenizer.decode(outputs[0]))
在以下场景中,DeepSeek-Coder-6.7B模型有效地调用了model.py文件中的IrisClassifier类及其成员函数,并使用了utils.py文件中的函数,正确完成了main.py文件中的main函数,用于模型训练和评估。
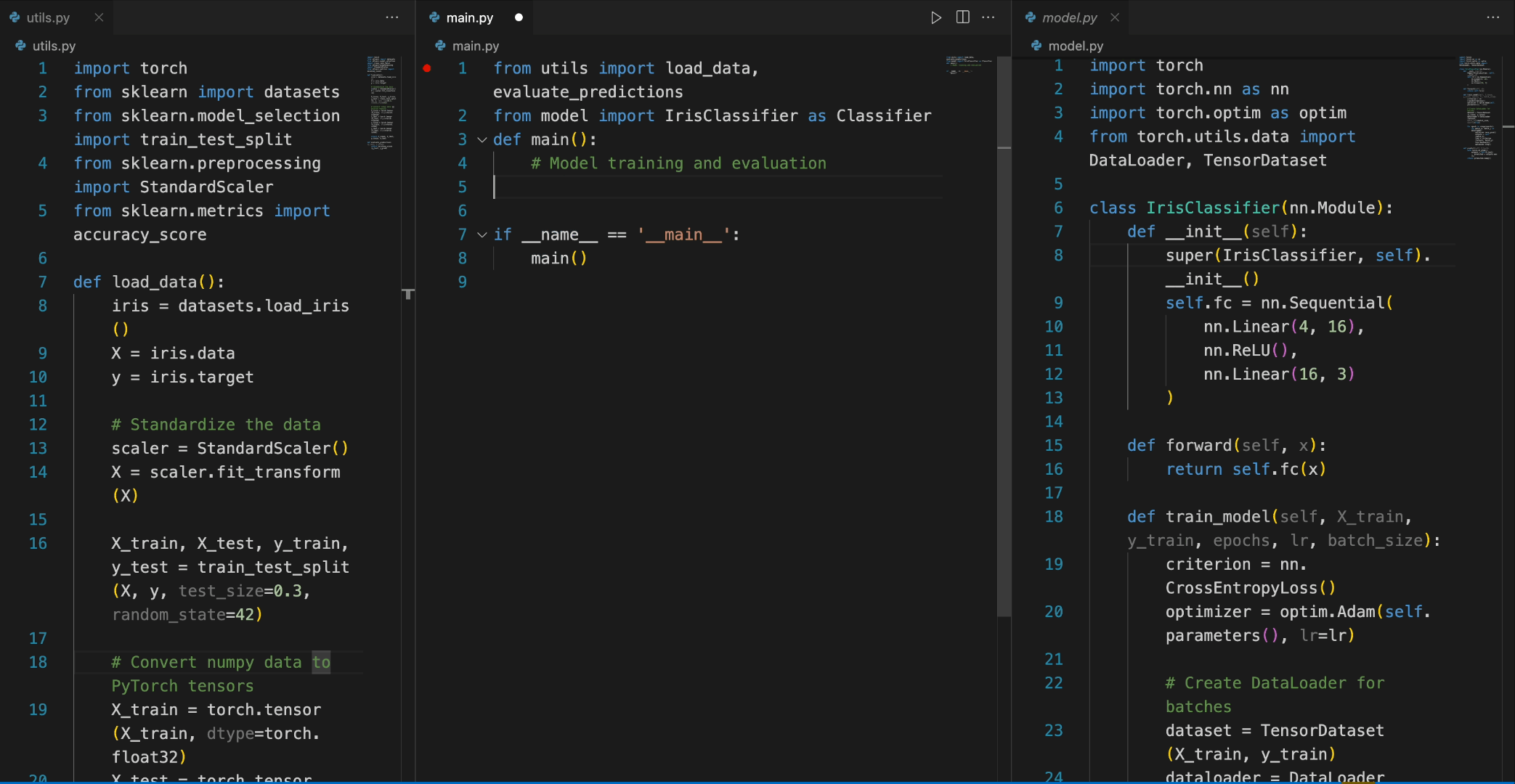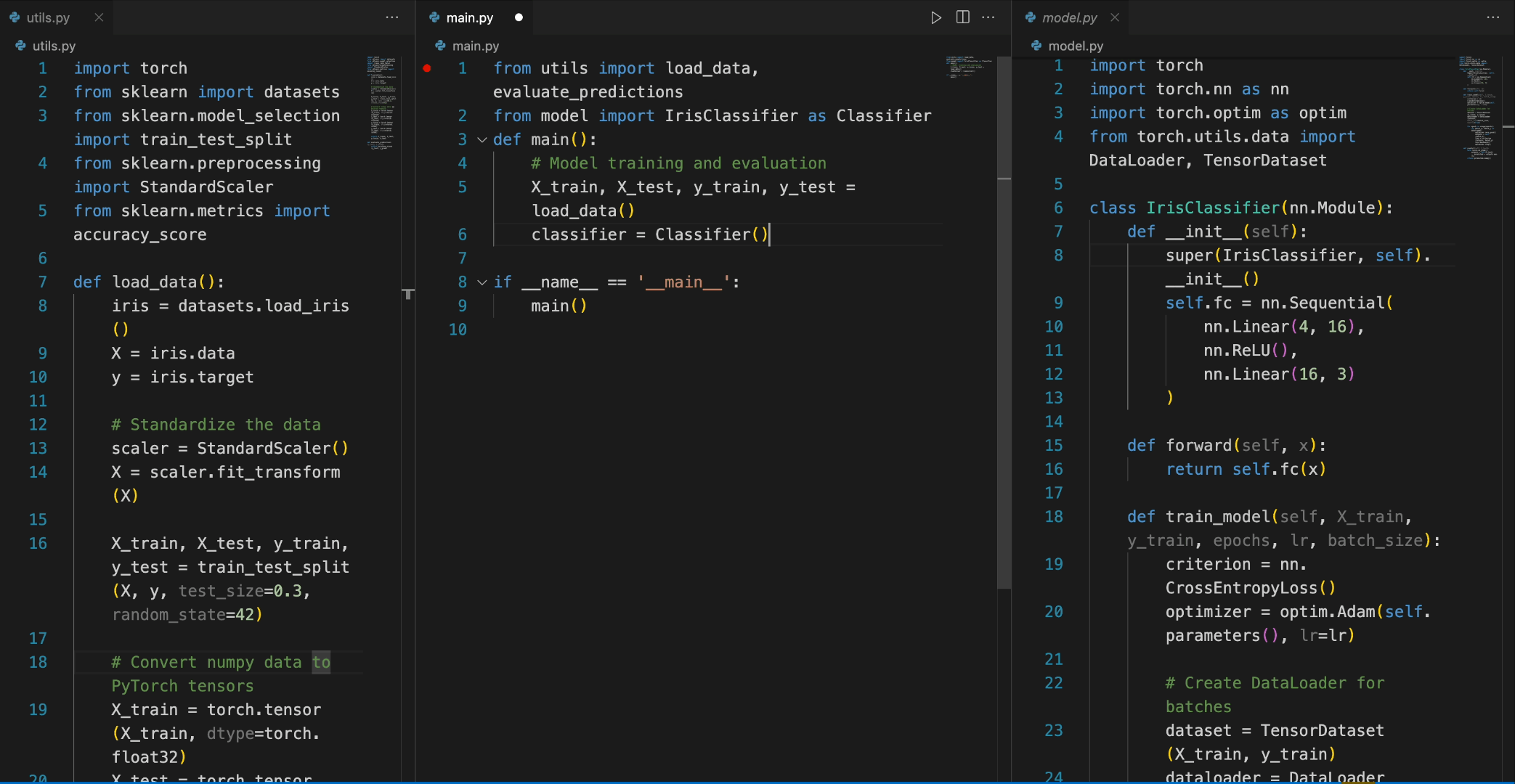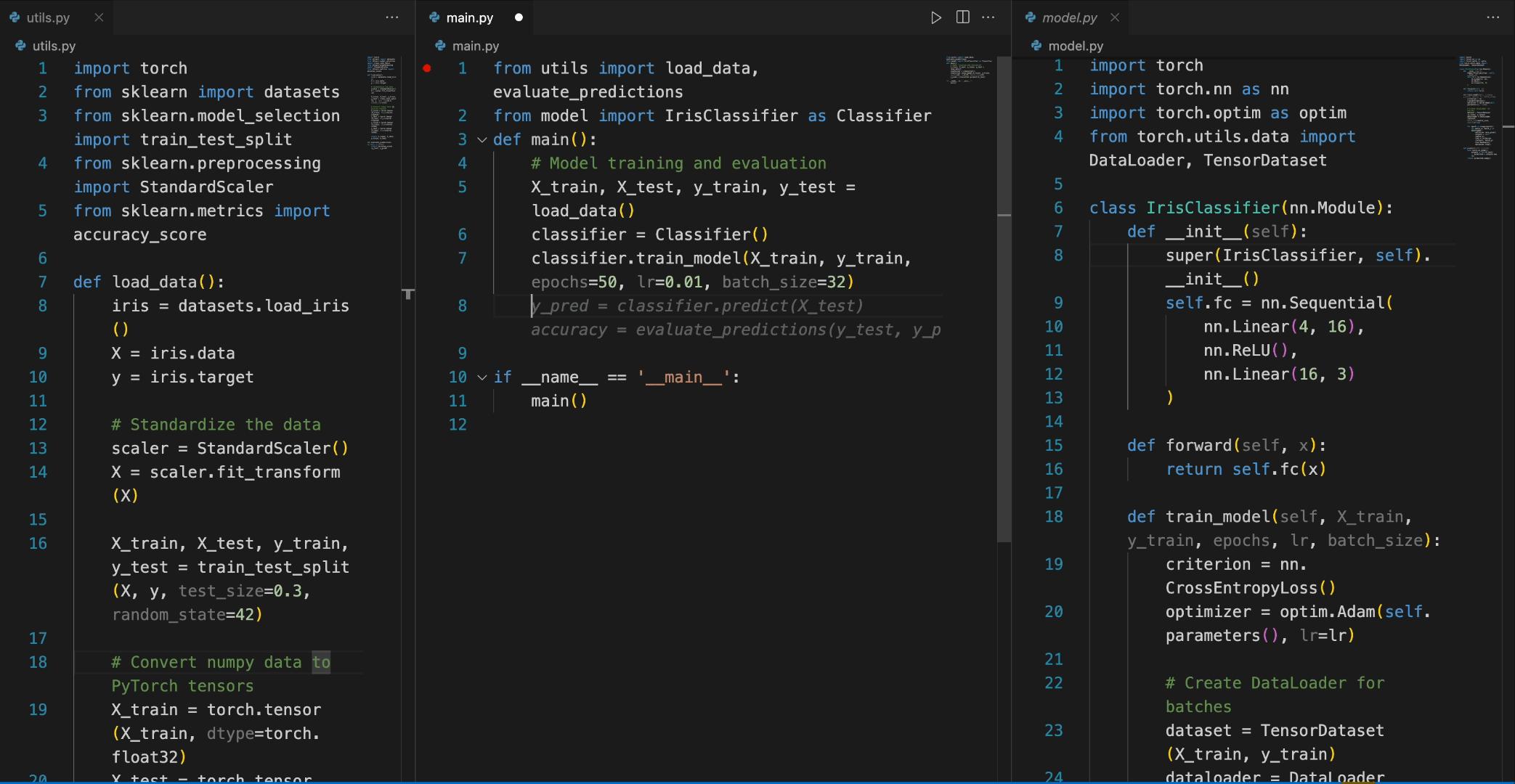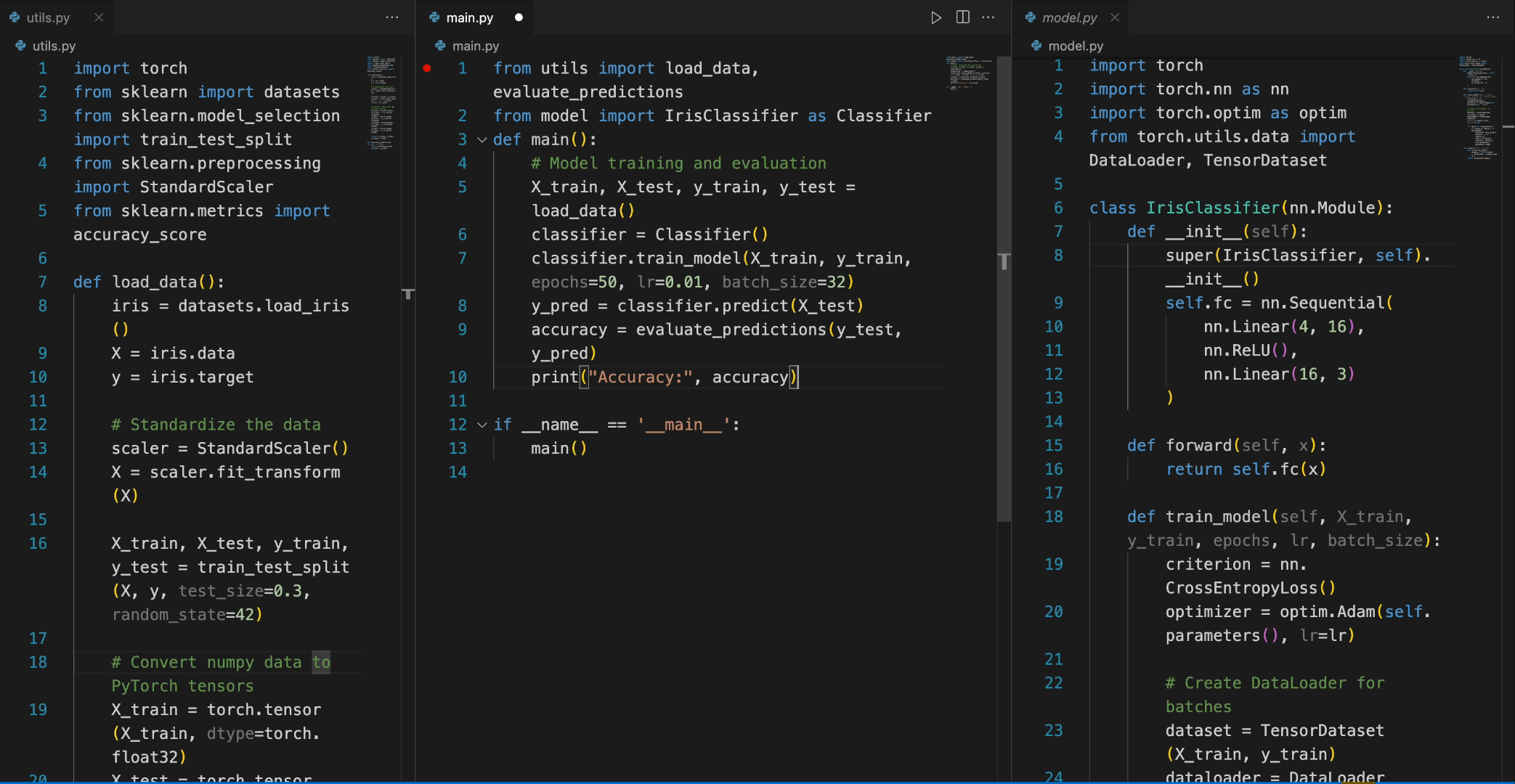
5. 如何微调DeepSeek-Coder
我们提供了脚本finetune/finetune_deepseekcoder.py,供用户在下游任务上微调我们的模型。
该脚本支持使用DeepSpeed进行训练。你��需要通过以下命令安装所需的包:
pip install -r finetune/requirements.txt
请按照样本数据集格式准备你的训练数据。
每行是一个JSON序列化的字符串,包含两个必需字段:instruction和output。
数据准备完成后,你可以使用示例shell脚本来微调deepseek-ai/deepseek-coder-6.7b-instruct。
记得指定DATA_PATH和OUTPUT_PATH。
并根据你的场景选择适当的超参数(如learning_rate、per_device_train_batch_size)。
DATA_PATH="<你的数据路径>" OUTPUT_PATH="<你的输出路径>" MODEL="deepseek-ai/deepseek-coder-6.7b-instruct" cd finetune && deepspeed finetune_deepseekcoder.py \ --model_name_or_path $MODEL_PATH \ --data_path $DATA_PATH \ --output_dir $OUTPUT_PATH \ --num_train_epochs 3 \ --model_max_length 1024 \ --per_device_train_batch_size 16 \ --per_device_eval_batch_size 1 \ --gradient_accumulation_steps 4 \ --evaluation_strategy "no" \ --save_strategy "steps" \ --save_steps 100 \ --save_total_limit 100 \ --learning_rate 2e-5 \ --warmup_steps 10 \ --logging_steps 1 \ --lr_scheduler_type "cosine" \ --gradient_checkpointing True \ --report_to "tensorboard" \ --deepspeed configs/ds_config_zero3.json \ --bf16 True
6. 详细评估结果
以下评估结果的可复现代码可在Evaluation目录中找到。
1) 多语言HumanEval基准测试
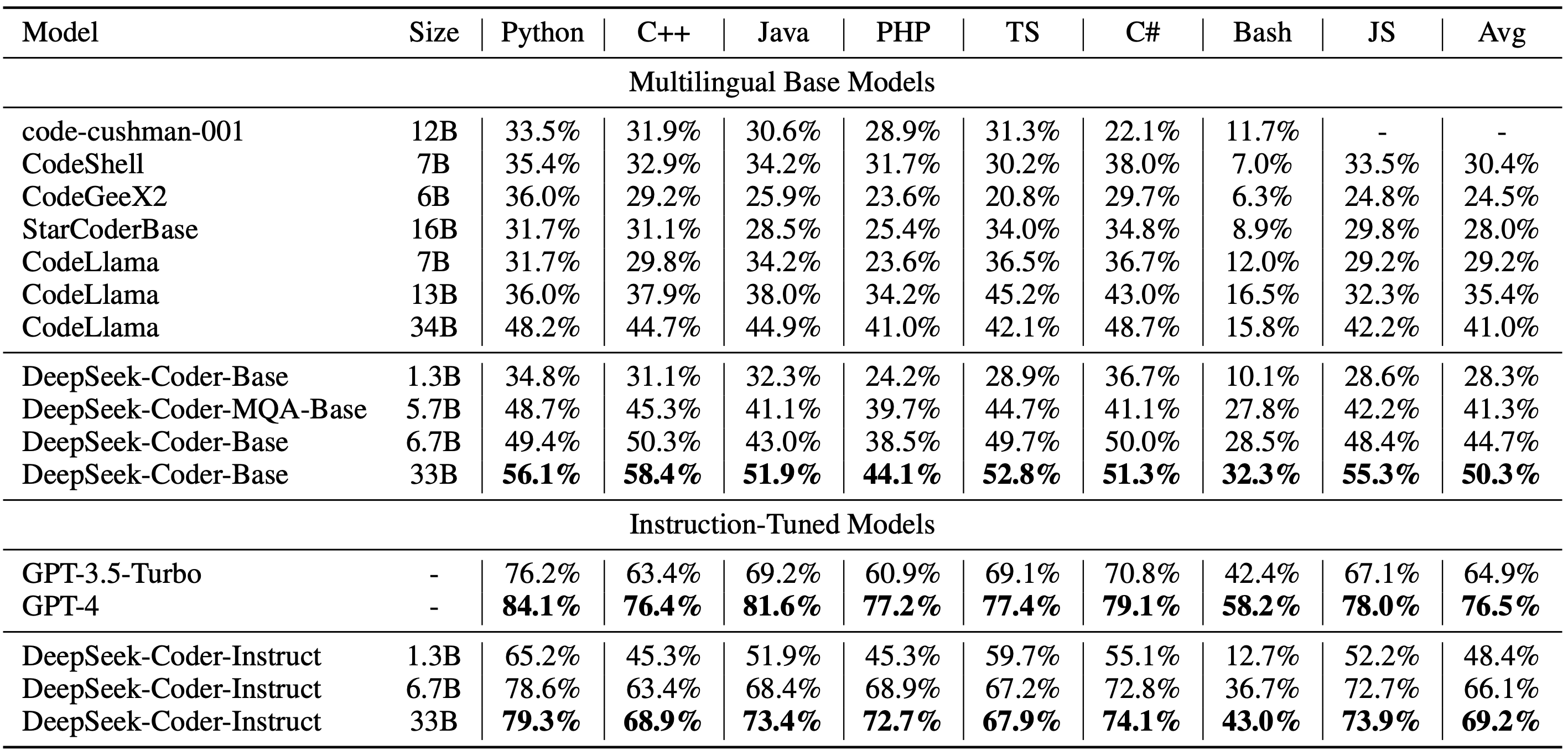
2) MBPP基准测试
<img src="https://yellow-cdn.veclightyear.com/835a84d5/15e9401a-0333-4e92-977f-76da7355208d.png" alt="MBPP" width="40%"> #### 3) DS-1000 基准测试 4) Program-Aid 数学推理基准测试
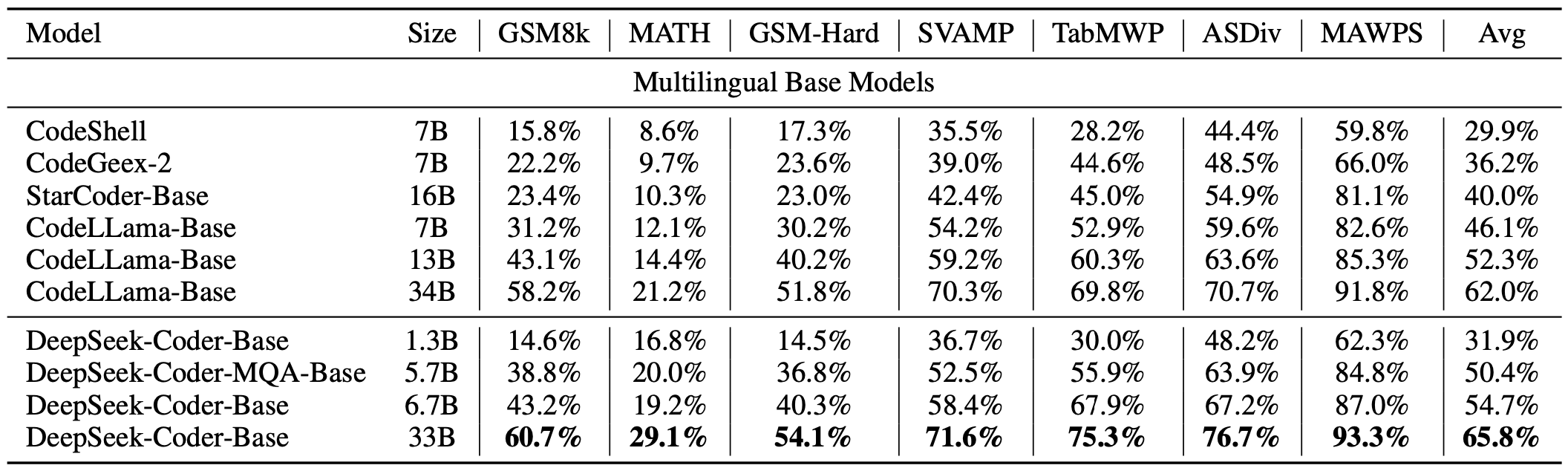
使用 vLLM 进行推理
您也可以使用 vLLM 进行高吞吐量推理。
文本补全
from vllm import LLM, SamplingParams tp_size = 4 # 张量并行度 sampling_params = SamplingParams(temperature=0.7, top_p=0.9, max_tokens=100) model_name = "deepseek-ai/deepseek-coder-6.7b-base" llm = LLM(model=model_name, trust_remote_code=True, gpu_memory_utilization=0.9, tensor_parallel_size=tp_size) prompts = [ "如果一个国家的每个人都彼此相爱,", "研究还应该关注这些技术", "要确定标签是否正确,我们需要" ] outputs = llm.generate(prompts, sampling_params) generated_text = [output.outputs[0].text for output in outputs] print(generated_text)
对话补全
from transformers import AutoTokenizer from vllm import LLM, SamplingParams tp_size = 4 # 张量并行度 sampling_params = SamplingParams(temperature=0.7, top_p=0.9, max_tokens=100) model_name = "deepseek-ai/deepseek-coder-6.7b-instruct" tokenizer = AutoTokenizer.from_pretrained(model_name) llm = LLM(model=model_name, trust_remote_code=True, gpu_memory_utilization=0.9, tensor_parallel_size=tp_size) messages_list = [ [{"role": "user", "content": "你是谁?"}], [{"role": "user", "content": "你能做什么?"}], [{"role": "user", "content": "简要解释一下Transformer。"}], ] prompts = [tokenizer.apply_chat_template(messages, add_generation_prompt=True, tokenize=False) for messages in messages_list] sampling_params.stop = [tokenizer.eos_token] outputs = llm.generate(prompts, sampling_params) generated_text = [output.outputs[0].text for output in outputs] print(generated_text)
7. 问答
能否提供用于模型量化的tokenizer.model文件?
DeepSeek Coder 使用 HuggingFace Tokenizer 来实现字节级BPE算法,并使用专门设计的预分词器以确保最佳性能。目前,没有直接将tokenizer转换为SentencePiece tokenizer的方法。我们正在为开源量化方法做出贡献,以便更好地使用HuggingFace Tokenizer。
GGUF(llama.cpp)
我们已向流行的量化仓库 llama.cpp 提交了一个 PR,以全面支持所有HuggingFace预分词器,包括我们的。
在等待PR合并的同时,您可以按照以下步骤生成GGUF模型:
git clone https://github.com/DOGEwbx/llama.cpp.git cd llama.cpp git checkout regex_gpt2_preprocess # 按照README设置环境 make python3 -m pip install -r requirements.txt # 生成GGUF模型 python convert-hf-to-gguf.py <MODEL_PATH> --outfile <GGUF_PATH> --model-name deepseekcoder # 以q4_0量化为例 ./quantize <GGUF_PATH> <OUTPUT_PATH> q4_0 ./main -m <OUTPUT_PATH> -n 128 -p <PROMPT>
GPTQ(exllamav2)
更新:exllamav2 已经能够支持Huggingface Tokenizer。请拉取最新版本并尝试。
记得将RoPE缩放设置为4以获得正确的输出,更多讨论可以在这个PR中找到。
如何使用deepseek-coder-instruct来完成代码?
尽管deepseek-coder-instruct模型在监督微调(SFT)过程中没有专门针对代码补全任务进行训练,但它们仍然保留了有效执行代码补全的能力。要启用此功能,您只需调整eos_token_id参数。将eos_token_id设置为32014,而不是deepseek-coder-instruct配置中的默认值32021。这一修改促使模型以不同方式识别序列的结束��,从而便于执行代码补全任务。
8. 资源
awesome-deepseek-coder 是一个与DeepSeek Coder相关的精选开源项目列表。
9. 许可证
本代码仓库采用MIT许可证。DeepSeek Coder模型的使用受模型许可证约束。DeepSeek Coder支持商业使用。
详细信息请参阅 LICENSE-CODE 和 LICENSE-MODEL。
10. 引用
@misc{deepseek-coder,
author = {Daya Guo, Qihao Zhu, Dejian Yang, Zhenda Xie, Kai Dong, Wentao Zhang, Guanting Chen, Xiao Bi, Y. Wu, Y.K. Li, Fuli Luo, Yingfei Xiong, Wenfeng Liang},
title = {DeepSeek-Coder: When the Large Language Model Meets Programming -- The Rise of Code Intelligence},
journal = {CoRR},
volume = {abs/2401.14196},
year = {2024},
url = {https://arxiv.org/abs/2401.14196},
}
11. 联系方式
如果您有任何问题,请提出issue或通过 service@deepseek.com 联系我们。
编辑推荐精选


GPT Plus|Pro充值
GPT充值
支持 ChatGPT Plus / Pro 充值服务,支付便捷,自动发货,售后可查。


GPT Image 2中文站
AI 图片生成平台
GPT Image 2 是面向用户的 AI 图片生成平台,支持文生图、图生图及多模型创意工作流。


Vecbase
你的AI Agent团队
Vecbase 是专为 AI 团队打造的智能工作空间,将数据管理、模型协作与知识沉淀整合于一处。算法、产品与业务在同一平台无缝协同,让从数据到 AI 应用的落地更快一步。


音述AI
全球首个AI音乐社区
音述AI是全球首个AI音乐社区,致力让每个人都能用音乐表达自我。音述AI提供零门槛AI创作工具,独创GETI法则帮助用户精准定义音乐风格,AI润色功能支持自动优化作品质感。音述AI支持交流讨论、二次创作与价值变现。针对中文用户的语言习惯与文化背景进行专门优化,支持国风融合、C-pop等本土音乐标签,让技术更好地承载人文表达。


QoderWork
阿里Qoder团队推出的桌面端AI智能体
QoderWork 是阿里推出的本地优先桌面 AI 智能体,适配 macOS14+/Windows10+,以自然语言交互实现文件管理、数据分析、AI 视觉生成、浏览器自动化等办公任务,自主拆解执行复杂工作流,数据本地运行零上传,技能市场可无限扩展,是高效的 Agentic 生产力办公助手。


lynote.ai
一站式搞定所有学习需求
不再被海量信息淹没,开始真正理解知识。Lynote 可摘要 YouTube 视频、PDF、文章等内容。即时创建笔记,检测 AI 内容并下载资料,将您的学习效率提升 10 倍。


AniShort
为AI短剧协作而生
专为AI短剧协作而生的AniShort正式发布,深度重构AI短剧全流程生产模式,整合创意策划、制作执行、实时协作、在线审片、资产复用等全链路功能,独创无限画布、双轨并行工业化工作流与Ani智能体助手,集成多款主流AI大模型,破解素材零散、版本混乱、沟通低效等行业痛点,助力3人团队效率提升800%,打造标准化、可追溯的AI短剧量产体系,是AI短剧团队协同创作、提升制作效率的核心工具。


seedancetwo2.0
能听懂你表达的视频模型
Seedance two是基于seedance2.0的中国大模型,支持图像、视频、音频、文本四种模态输入,表达方式更丰富,生成也更可控。


nano-banana纳米香蕉中文站
国内直接访问,限时3折
输入简单文字,生成想要的图片,纳米香蕉中文站基于 Google 模型的 AI 图片生成网站,支持文字生图、图生图。官网价格限时3折活动


扣子-AI办公
职场AI,就用扣子
AI办公助手,复杂任务高效处理。办公效率低?扣子空间AI助手支持播客生成、PPT制作、网页开发及报告写作,覆盖科研、商业、舆情等领域的专家Agent 7x24小时响应,生活工作无缝切换,提升50%效率!
推荐工具精选





AI云服务特惠
懂AI专属折扣�关注微信公众号
最新AI工具、AI资讯
独家AI资源、AI项目落地

微信扫一扫关注公众号