
emotion2vec
通用语音情感表示模型开源实现
emotion2vec是一个开源的语音情感表示模型,采用自监督预训练方法提取跨任务、跨语言和跨场景的通用情感特征。该模型在IEMOCAP等数据集上取得了领先性能,并在多语言和多任务上展现出优异表现。项目开源了预训练模型、特征提取工具和下游任务训练脚本,为语音情感分析研究提供了有力支持。




新闻
- [2024年6月] 🔧 我们修复了 emotion2vec+ 中的一个错误。请重新拉取最新代码。
- [2024年5月] 🔥 语音情感识别基础模型:emotion2vec+,支持9类情感,已在 Model Scope 和 Hugging Face 上发布。查看一系列用于高性能语音情感识别的 emotion2vec+ (seed, base, large) 模型**(我们推荐使用此版本,而非2024年1月发布的版本)**。
- [2024年1月] 基于 emotion2vec 迭代微调的9类情感识别模型已在 modelscope 和 FunASR 上发布。
- [2024年1月] emotion2vec 已集成到 modelscope 和 FunASR。
- [2023年12月] 我们发布了 论文,并创建了一个 微信群 用于 emotion2vec。
- [2023年11月] 我们发布了 emotion2vec 的代码、检查点和提取的特征。
模型卡片
GitHub 仓库:emotion2vec
| 模型 | ⭐Model Scope | 🤗Hugging Face | 微调数据(小时) |
|---|---|---|---|
| emotion2vec | 链接 | 链接 | / |
| emotion2vec+ seed | 链接 | 链接 | 201 |
| emotion2vec+ base | 链接 | 链接 | 4788 |
| emotion2vec+ large | 链接 | 链接 | 42526 |
概述
emotion2vec+:语音情感识别基础模型
指南
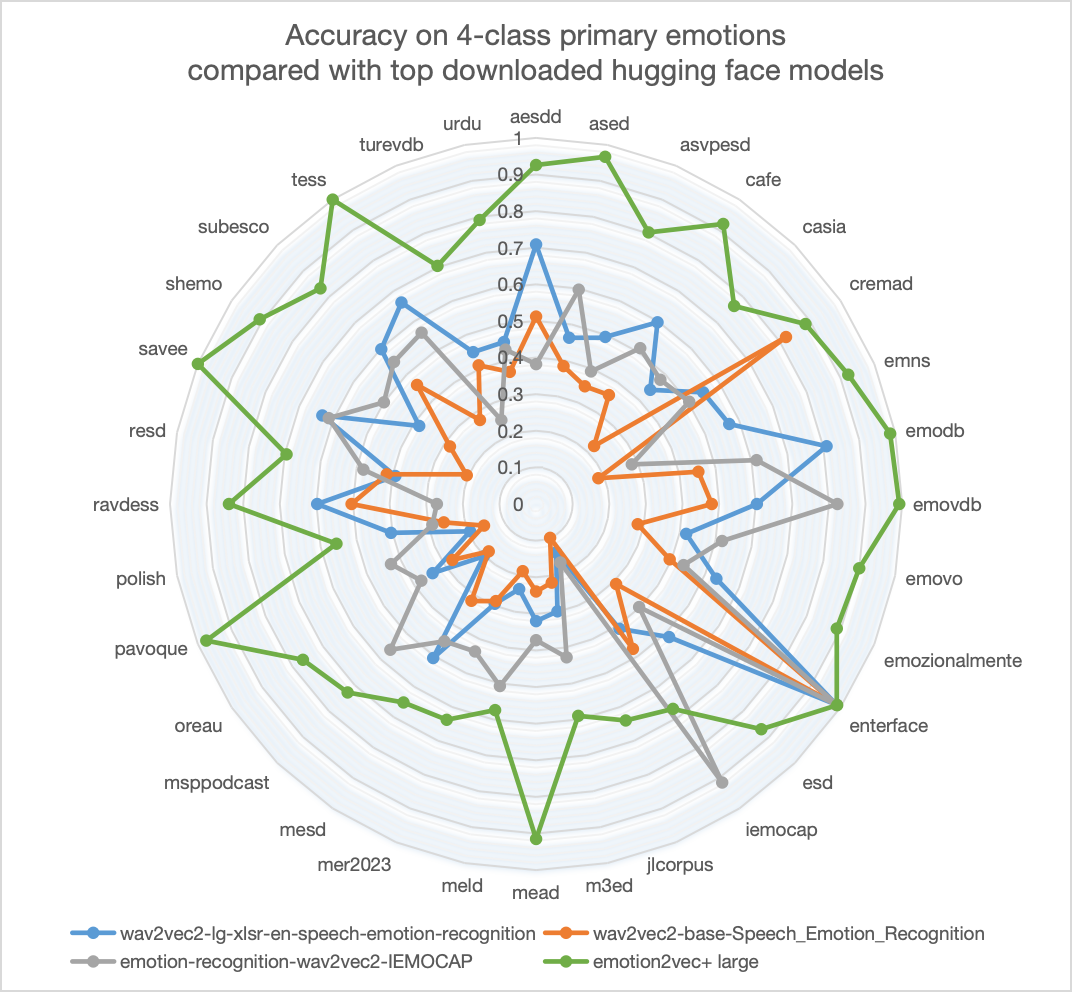
emotion2vec+ 是一系列语音情感识别(SER)基础模型。我们旨在训练一个语音情感识别领域的"whisper",通过数据驱动的方法克服语言和录音环境的影响,实现通用、鲁棒的情感识别能力。emotion2vec+ 的性能显著超过了 Hugging Face 上其他下载量很高的开源模型。
数据工程
我们提供了3个版本的 emotion2vec+,每个版本都是从其前身的数据衍生而来。如果您需要一个专注于语�音情感表征的模型,请参考 emotion2vec:通用语音情感表征模型。
- emotion2vec+ seed:使用来自 EmoBox 的学术语音情感数据进行微调
- emotion2vec+ base:使用经过筛选的大规模伪标记数据进行微调,得到基础大小模型(约90M)
- emotion2vec+ large:使用经过筛选的大规模伪标记数据进行微调,得到大型模型(约300M)
下图illustrates了迭代过程,最终使用160k小时语音情感数据中的40k小时训练得到 emotion2vec+ large 模型。数据工程的详细信息将稍后公布。
性能
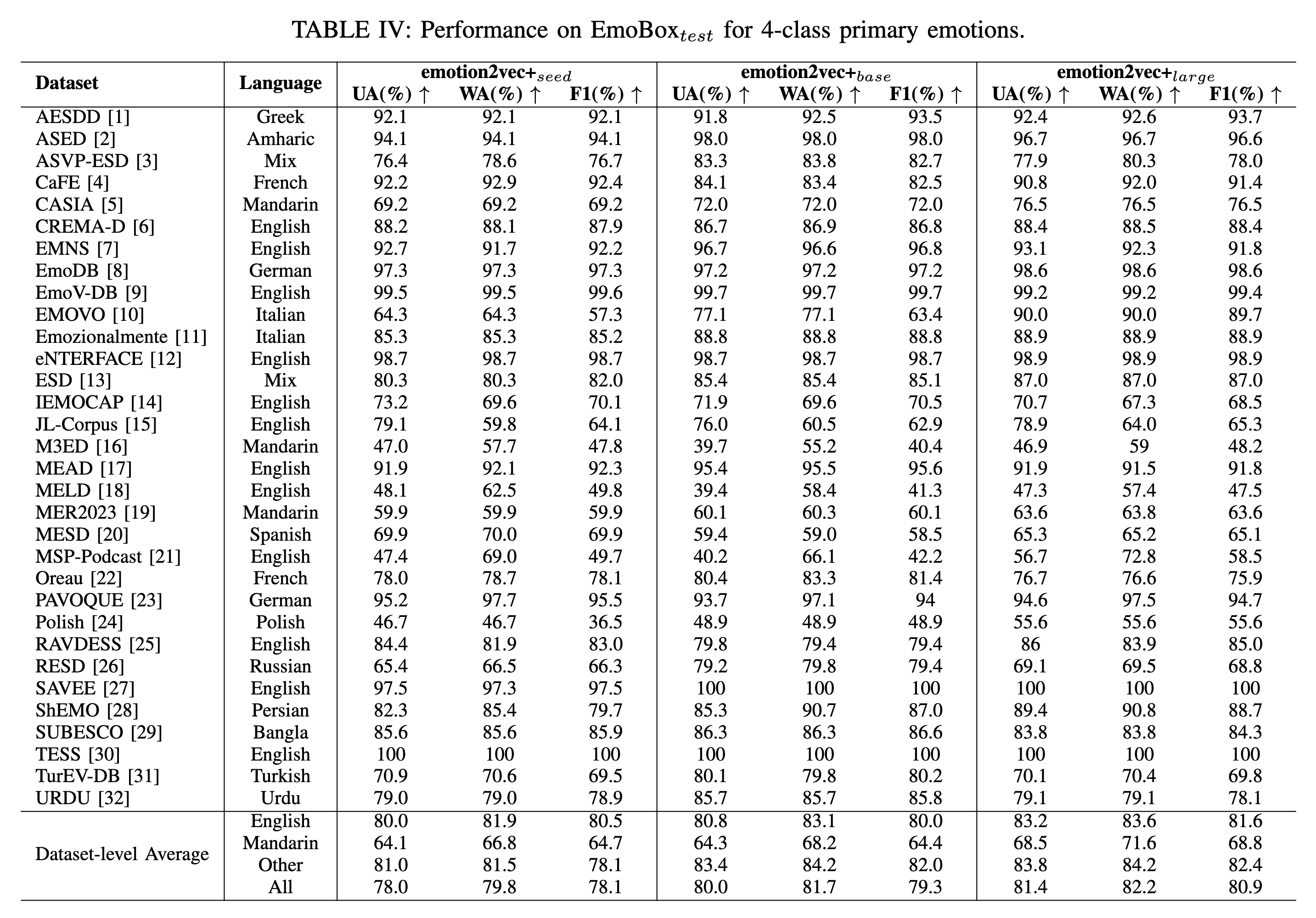
在 EmoBox 上对4类主要情感的性能(无需微调)。模型性能的详细信息将稍后公布。
使用检查点进行推理
从 modelscope 安装(推荐)
- 安装 modelscope 和 funasr
pip install -U funasr modelscope
- 运行代码
''' 使用微调后的情感识别模型 rec_result 包含 {'feats', 'labels', 'scores'} extract_embedding=False:9类情感及其得分 extract_embedding=True:9类情感及其得分,以及特征 9类情感: iic/emotion2vec_plus_seed, iic/emotion2vec_plus_base, iic/emotion2vec_plus_large(2024年5月发布) iic/emotion2vec_base_finetuned(2024年1月发布) 0: 愤怒 1: 厌恶 2: 恐惧 3: 高兴 4: 中性 5: 其他 6: 悲伤 7: 惊讶 8: 未知 ''' from modelscope.pipelines import pipeline from modelscope.utils.constant import Tasks inference_pipeline = pipeline( task=Tasks.emotion_recognition, model="iic/emotion2vec_large") # 可选:iic/emotion2vec_plus_seed, iic/emotion2vec_plus_base, iic/emotion2vec_plus_large 和 iic/emotion2vec_base_finetuned rec_result = inference_pipeline('https://isv-data.oss-cn-hangzhou.aliyuncs.com/ics/MaaS/ASR/test_audio/asr_example_zh.wav', output_dir="./outputs", granularity="utterance", extract_embedding=False) print(rec_result)
模型将自动下载。
从 FunASR 安装
- 安装 funasr
pip install -U funasr
- 运行代码
''' 使用微调后的情感识别模型 rec_result 包含 {'feats', 'labels', 'scores'} extract_embedding=False:9类情感及其得分 extract_embedding=True:9类情感及其得分,以及特征 9类情感: iic/emotion2vec_plus_seed, iic/emotion2vec_plus_base, iic/emotion2vec_plus_large(2024年5月发布) iic/emotion2vec_base_finetuned(2024年1月发布) 0: 愤怒 1: 厌恶 2: 恐惧 3: 高兴 4: 中性 5: 其他 6: 悲伤 7: 惊讶 8: 未知 ''' from funasr import AutoModel model = AutoModel(model="iic/emotion2vec_base_finetuned") # 可选:iic/emotion2vec_plus_seed, iic/emotion2vec_plus_base, iic/emotion2vec_plus_large 和 iic/emotion2vec_base_finetuned wav_file = f"{model.model_path}/example/test.wav" rec_result = model.generate(wav_file, output_dir="./outputs", granularity="utterance", extract_embedding=False) print(rec_result)
模型将自动下载。
FunASR 支持 wav.scp(kaldi 风格)的文件列表输入:
wav_name1 wav_path1.wav
wav_name2 wav_path2.wav
...
更多详情请参考 FunASR。
emotion2vec:通用语音情感表征模型
指南
emotion2vec 是首个通用语音情感表征模型。通过自监督预训练,emotion2vec 具备跨任务、跨语言、跨场景提取情感表征的能力。
性能
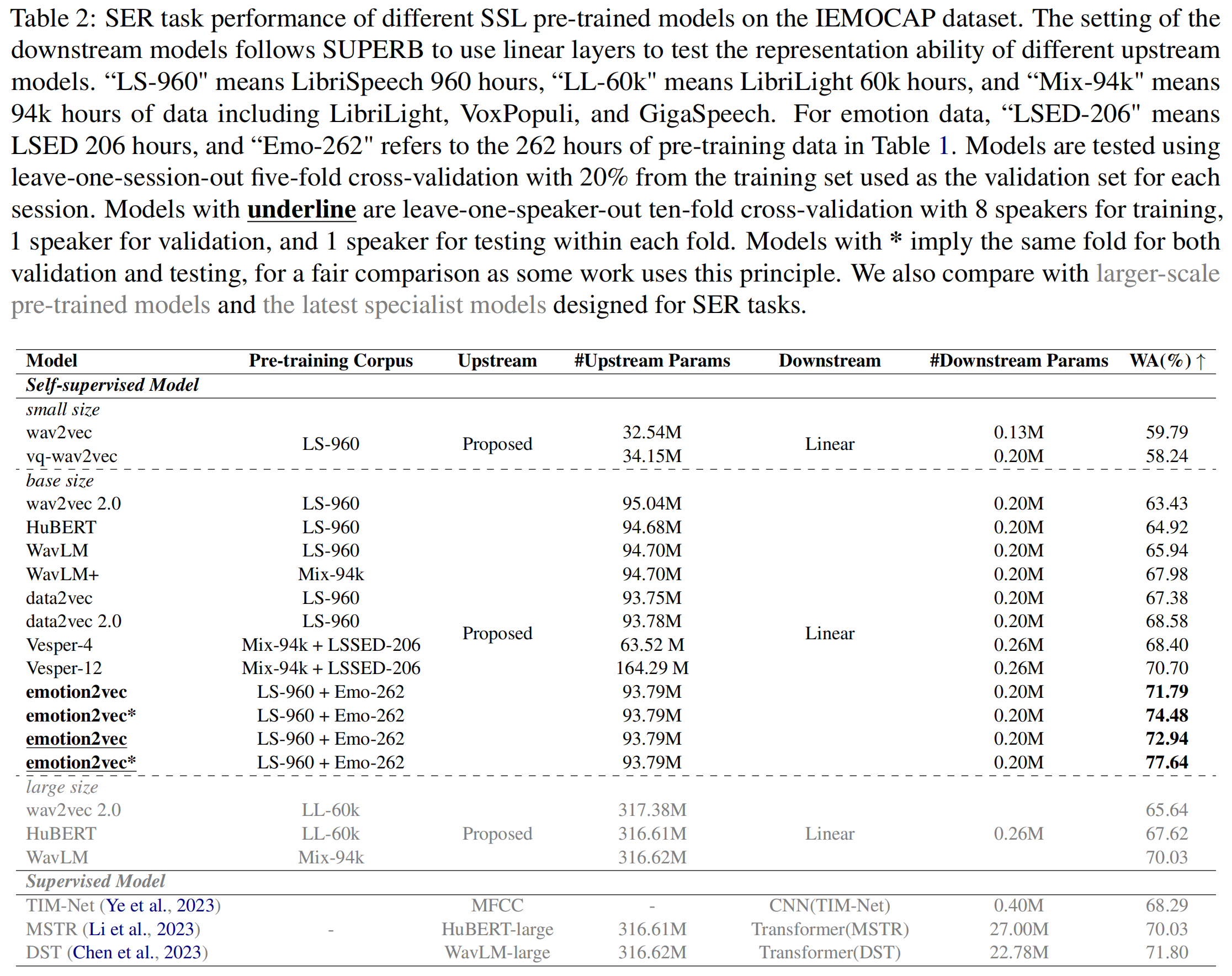
IEMOCAP 上的性能
emotion2vec 仅使用线性层就在主流的 IEMOCAP 数据集上取得了最先进的结果。更多详情请参考论文。
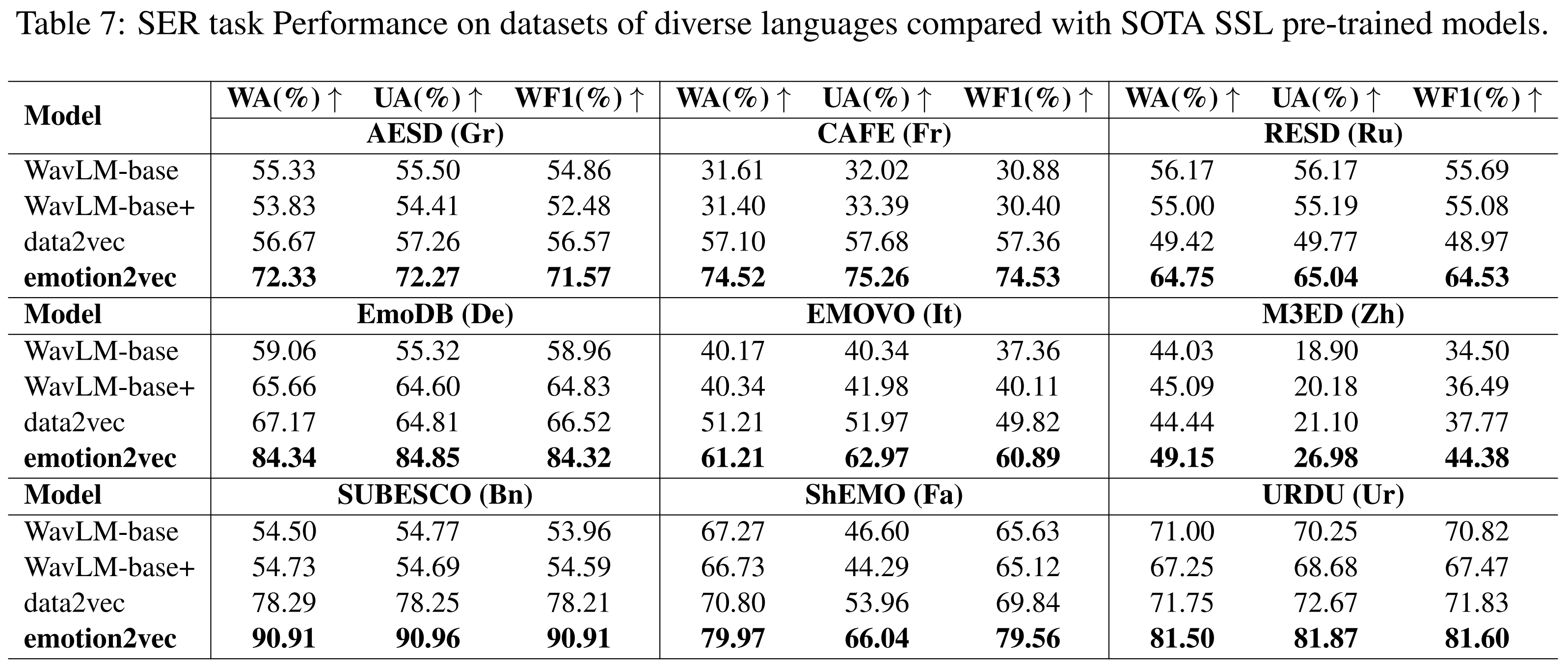
�其他语言上的性能
与最先进的 SSL 模型相比,emotion2vec 在多种语言(普通话、法语、德语、意大利语等)上取得了最先进的结果。更多详情请参考论文。
其他语音情感任务上的性能
更多详情请参考论文。
可视化
IEMOCAP数据集上学习特征的UMAP可视化。<span style="color:red;">红色</span>和<span style="color:blue;">蓝色</span>调分别表示低唤起和高唤起的情感类别。更多详细信息请参阅论文。

提取特征
下载提取的特征
我们提供了流行情感数据集IEMOCAP的提取特征。这些特征从emotion2vec的最后一层提取。特征以.npy格式存储,提取特征的采样率为50Hz。句级特征通过平均帧级特征计算得出。
- 帧级:Google Drive | 百度网盘(密码:zb3p)
- 句级:Google Drive | 百度网盘(密码:qu3u)
所有wav文件都从原始数据集中提取,用于各种下游任务。如果想要使用标准的5531个句子进行4种情感分类的训练,请参考iemocap_downstream文件夹。
从您的数据集提取特征
从源代码安装
最低环境要求为python>=3.8和torch>=1.13。我们的测试环境为python=3.8和torch=2.01。
- 克隆仓库。
pip install fairseq git clone https://github.com/ddlBoJack/emotion2vec.git
- 从以下位置下载emotion2vec检查点:
- Google Drive
- 百度网盘(密码:b9fq)
- modelscope:
git clone https://www.modelscope.cn/damo/emotion2vec_base.git
- 修改并运行
scripts/extract_features.sh
从modelscope安装(推荐)
- 安装modelscope和funasr
pip install -U funasr modelscope
- 运行代码。
''' 使用情感表示模型 rec_result只包含{'feats'} granularity="utterance":{'feats': [*768]} granularity="frame":{feats: [T*768]} ''' from modelscope.pipelines import pipeline from modelscope.utils.constant import Tasks inference_pipeline = pipeline( task=Tasks.emotion_recognition, model="iic/emotion2vec_base") rec_result = inference_pipeline('https://isv-data.oss-cn-hangzhou.aliyuncs.com/ics/MaaS/ASR/test_audio/asr_example_zh.wav', output_dir="./outputs", granularity="utterance") print(rec_result)
模型将自动下载。
更多详细信息请参考modelscope上的emotion2vec_base和emotion2vec_base_finetuned。
从FunASR安装
- 安装funasr
pip install -U funasr
- 运行代码。
''' 使用情感表示模型 rec_result只包含{'feats'} granularity="utterance":{'feats': [*768]} granularity="frame":{feats: [T*768]} ''' from funasr import AutoModel model = AutoModel(model="iic/emotion2vec_base") wav_file = f"{model.model_path}/example/test.wav" rec_result = model.generate(wav_file, output_dir="./outputs", granularity="utterance") print(rec_result)
模型将自动下载。
FunASR支持wav.scp(kaldi风格)的文件列表输入:
wav_name1 wav_path1.wav
wav_name2 wav_path2.wav
...
更多详细信息请参考FunASR。
训练您的下游模型
我们在iemocap_downstream文件夹中提供了IEMOCAP数据集的训练脚本。您可以修改这些脚本以在其他数据集上训练您的下游模型。
引用
如果您觉得我们的emotion2vec代码和论文有用,请引用:
@article{ma2023emotion2vec,
title={emotion2vec: Self-Supervised Pre-Training for Speech Emotion Representation},
author={Ma, Ziyang and Zheng, Zhisheng and Ye, Jiaxin and Li, Jinchao and Gao, Zhifu and Zhang, Shiliang and Chen, Xie},
journal={arXiv preprint arXiv:2312.15185},
year={2023}
}
编辑推荐精选


Pixmax
一站式AI短剧创作平台
Pixmax专注打造下一代“ AI 视觉创作引擎”,整合行业顶尖 AI 大模型、工工业级精准控制及企业级协同管理功能,是全方位的 AI 内容创作平台。


豆包
字节跳动旗下 AI 智能助手
字节跳动旗下 AI 智能助手


GPT Plus|Pro充值
GPT充值
支持 ChatGPT Plus / Pro 充值服务,支付便捷,自动发货,售后可查。


GPT Image 2中文站
AI 图片生成平台
GPT Image 2 是面向用户的 AI 图片生成平台,支持文生图、图生图及多模型创意工作流。


Vecbase
你的AI Agent团队
Vecbase 是专为 AI 团队打造的智能工作空间,将数据管理、模型协作与知识沉淀整合于一处。算法、产品与业务在同一平台无缝协同,让从数据到 AI 应用的落地更快一步。


音述AI
全球首个AI音乐社区
音述AI是全球首个AI音乐社区,致力让每个人都能用音乐表达自我。音述AI提供零门槛AI创作工具,独创GETI法则帮助用户精准定义音乐风格,AI润色功能支持自动优化作品质感。音述AI支持交流讨论、二次创作与价值变现。针对中文用户的语言习惯与文化背景进行专门优化,支持国风融合、C-pop等本土音乐标签,让技术更好地承载人文表达。


QoderWork
阿里Qoder团队推出的桌面端AI智能体
QoderWork 是阿里推出的本地优先桌面 AI 智能体,适配 macOS14+/Windows10+,以自然语言交互实现文件管理、数据分析、AI 视觉生成、浏览器自动化等办公任务,自主拆解执行复杂工作流,数据本地运行零上传,技能市场可无限扩展,是高效的 Agentic 生产力办公助手。


lynote.ai
一站式搞定所有学习需求
不再被海量信息淹没,开始真正理解知识。Lynote 可摘要 YouTube 视频、PDF、文章等内容。即时创建笔记,检测 AI 内容并下载资料,将您的学习效率提升 10 倍。


AniShort
为AI短剧协作而生
专为AI短剧协作而生的AniShort正式发布,深度重构AI短剧全流程生产模式,整合创意策划、��制作执行、实时协作、在线审片、资产复用等全链路功能,独创无限画布、双轨并行工业化工作流与Ani智能体助手,集成多款主流AI大模型,破解素材零散、版本混乱、沟通低效等行业痛点,助力3人团队效率提升800%,打造标准化、可追溯的AI短剧量产体系,是AI短剧团队协同创作、提升制作效率的核心工具。


seedancetwo2.0
能听懂你表达的视频模型
Seedance two是基于seedance2.0的中国大模型,支持图像、视频、音频、文本四种模态输入,表达方式更丰富,生成也更可控。
推荐工具精选






{kind=link}
AI云服务特惠
懂AI专属折扣关注微信公众号
最新AI工具、AI资讯
独家AI资源、AI项目落地

微信扫一扫关注公众号