



MagicDrive
✨ 欢迎查看我们关于3D场景生成的新作品 MagicDrive3D!
✨ 如果您需要视频生成功能,请在video分支中查找代码。




MagicDrive生成的视频(点击图片查看视频)。


本仓库包含以下论文的实现:
MagicDrive:具有多样3D几何控制的街景生成 <br> 高瑞远<sup>1*</sup>,陈凯<sup>2*</sup>,谢恩泽<sup>3^</sup>,洪兰清<sup>3</sup>,李震国<sup>3</sup>,杨意<sup>2</sup>,徐强<sup>1^</sup><br> <sup>1</sup>香港中文大学 <sup>2</sup>香港科技大学 <sup>3</sup>华为诺亚方舟实验室 <br> <sup>*</sup>共同第一作者 <sup>^</sup>通讯作者
摘要
<details> <summary><b>简述</b> MagicDrive生成高质量的街景图像和视频,具有多样化的3D几何控制和多视图一致性,可作为各种感知任务中的数据引擎。</summary>近期扩散模型的进展显著提高了2D控制下的数据合成能力。然而,街景生成中的精确3D控制,对3D感知任务至关重要,仍然难以实现。具体来说,使用鸟瞰图(BEV)作为主要条件常常导致几何控制(如高度)的挑战,影响物体形状、遮挡模式和路面高程的表现,这些对感知数据合成至关重要,尤其是对3D物体检测任务。在本文中,我们提出了MagicDrive,一个新颖的街景生成框架,通过定制的编码策略,提供多样化的3D几何控制,包括相机姿态、道路地图和3D边界框,以及文本描述。此外,我们的设计还包含一个跨视图注意力模块,确保多个相机视图之间的一致性。通过MagicDrive,我们实现了高保真度的街景图像和视频合成,捕捉细微的3D几何特征和各种场景描述,增强了BEV分割和3D物体检测等任务。
</details>新闻
- [2024/06/07] MagicDrive现在可以生成60帧视频!我们发布了配置文件:rawbox_mv2.0t_0.4.3_60.yaml。在项目页面查看我们的演示。
- [2024/06/07] 我们发布了16帧视频生成的预训练权重。点击查看!
- [2024/06/01] 我们在ECCV2024举办W-CODA工作坊。挑战赛赛道2将使用MagicDrive作为基线。我们将在不久的将来发布更多资源。敬请关注!
方法
在MagicDrive中,我们采用两种策略(交叉注意力和加性编码器分支)来注入文本提示、相机姿态、物体边界框和道路地图作为生成条件。我们还提出了一个跨视图注意力模块,以实现多视图一致性。
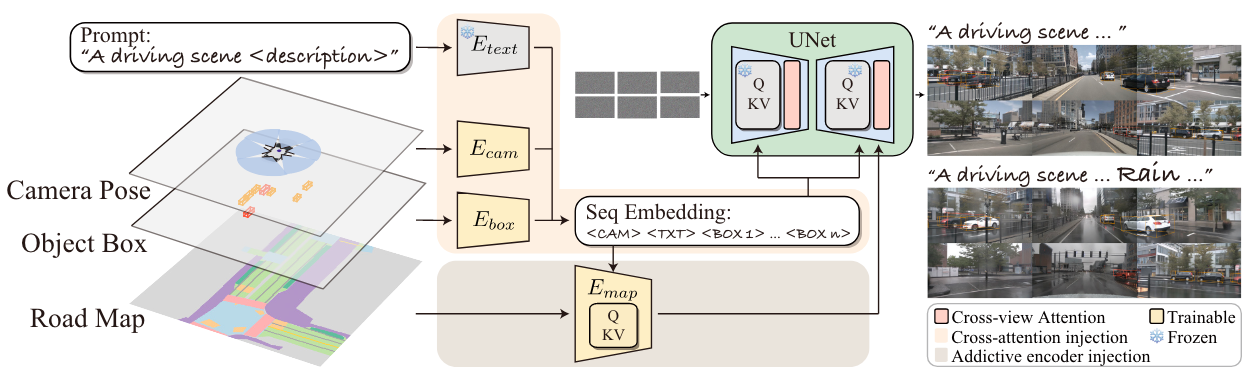
待办事项
入门指南
环境设置
克隆此仓库及其子模块
git clone --recursive https://github.com/cure-lab/MagicDrive.git
代码在V100服务器上使用Pytorch==1.10.2和cuda 10.2进行了测试。要设置Python环境,请按以下步骤操作:
# 选项1:仅运行GUI pip install -r requirements/gui.txt # 😍 我们的GUI不需要mm系列包。 # 继续从`third_party`安装diffusers。 # 选项2:运行完整的测试演示(同时在训练前测试您的环境) cd ${ROOT} pip install -r requirements/dev.txt # 继续按如下方式安装`third_party`。
我们选择使用cd ${FOLDER}; pip -vvv install .安装以下包的源代码:
# 安装第三方包 third_party/ ├── bevfusion -> 基于db75150 ├── diffusers -> 基于v0.17.1 (afcca39) └── xformers -> 基于v0.0.19 (8bf59c9),可选
查看关于我们xformers的说明。如果您在环境设置中遇到问题,请先查看常见问题。
使用以下命令为accelerate设置默认配置:
accelerate config
我们的默认日志目录是${ROOT}/magicdrive-log。请做好准备。
预训练权重
我们的训练基于stable-diffusion-v1-5。我们假设您将它们放在${ROOT}/pretrained/中,如下所示:
{ROOT}/pretrained/stable-diffusion-v1-5/ ├── text_encoder ├── tokenizer ├── unet ├── vae └── ...
使用MagicDrive生成街景
从onedrive下载我们为MagicDrive预训练的权重,并将其放在${ROOT}/pretrained/中
运行我们的演示
👍 我们建议用户首先运行我们的交互式GUI,因为我们已经最小化了GUI演示的依赖项。
cd ${ROOT} python demo/interactive_gui.py # 基于gradio的gui,使用您的网络浏览器
根据#37的建议,提示可以通过GUI配置!
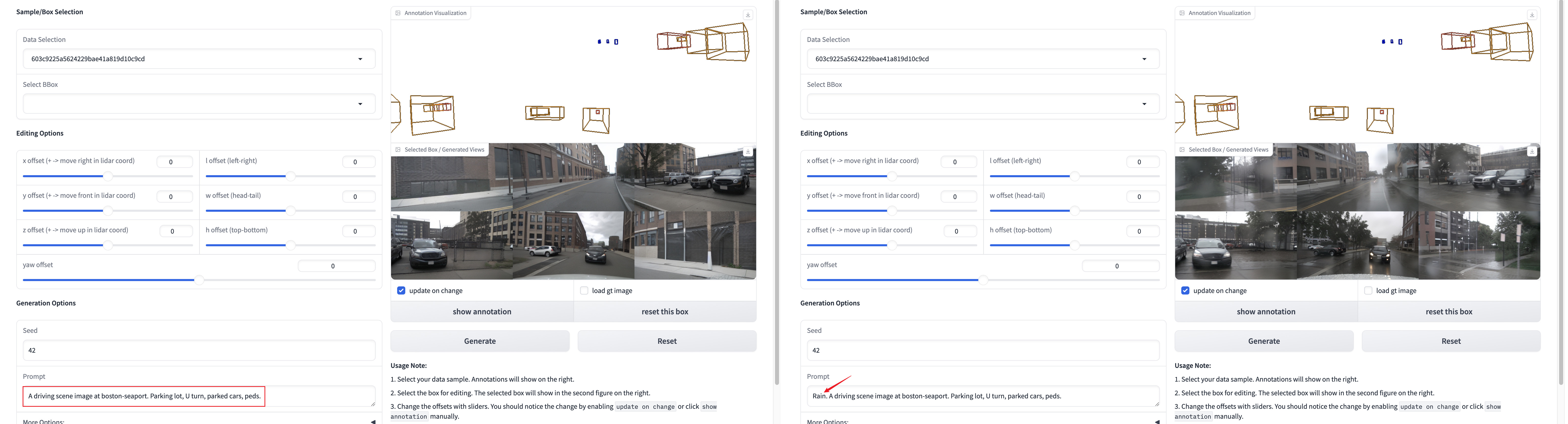
运行我们的相机视图生成演示。
cd ${ROOT} python demo/run.py resume_from_checkpoint=magicdrive-log/SDv1.5mv-rawbox_2023-09-07_18-39_224x400
生成的图像将位于magicdrive-log/test中。更多信息可以在演示文档中找到。
训练MagicDrive
准备数据
我们按照bevfusion的说明准备nuScenes数据集。具体来说,
- 从网站下载nuScenes数据集并将它们放在
./data/中。您应该有这些文件:data/nuscenes ├── maps ├── mini ├── samples ├── sweeps ├── v1.0-mini └── v1.0-trainval
[!提示] 您可以从OneDrive下载
.pkl文件。它们应该足够用于训练和测试。
-
通过以下方式生成mmdet3d注释文件:
python tools/create_data.py nuscenes --root-path ./data/nuscenes \ --out-dir ./data/nuscenes_mmdet3d_2 --extra-tag nuscenes您应该有这些文件:
data/nuscenes_mmdet3d_2 ├── nuscenes_dbinfos_train.pkl (-> ${bevfusion-version}/nuscenes_dbinfos_train.pkl) ├── nuscenes_gt_database (-> ${bevfusion-version}/nuscenes_gt_database) ├── nuscenes_infos_train.pkl └── nuscenes_infos_val.pkl注意:如上所示,一些文件可以与bevfusion的原始版本软链接。如果某些文件位于
data/nuscenes中,您可以手动将它们移动到data/nuscenes_mmdet3d_2。 -
(可选)为加快数据加载速度,我们为BEV地图准备了h5格式的缓存文件。它们可以通过
tools/prepare_map_aux.py与configs/dataset中的不同配置生成。例如:python tools/prepare_map_aux.py +process=train python tools/prepare_map_aux.py +process=val您将得到类似
./val_tmp.h5和./train_tmp.h5的文件。生成后,您必须正确重命名缓存文件。我们的默认设置是:data/nuscenes_map_aux ├── train_26x200x200_map_aux_full.h5 (42G) └── val_26x200x200_map_aux_full.h5 (9G)
训练模型
使用以下命令启动训练(使用8xV100):
accelerate launch --mixed_precision fp16 --gpu_ids all --num_processes 8 tools/train.py \ +exp=224x400 runner=8gpus
在训练过程中,您可以查看tensorboard以获取日志和中间结果。
此外,我们提供了调试配置来测试您的环境和数据加载过程(使用2xV100):
accelerate launch --mixed_precision fp16 --gpu_ids all --num_processes 2 tools/train.py \ +exp=224x400 runner=debug runner.validation_before_run=true
测试模型
训练完成后,您可以通过以下方式测试您的驾驶视图生成模型:
python tools/test.py resume_from_checkpoint=${YOUR MODEL} # 以我们的预训练模型为例 python tools/test.py resume_from_checkpoint=./pretrained/SDv1.5mv-rawbox_2023-09-07_18-39_224x400
请在./magicdrive-log/test/中查看结果。
测试FID
首先,您应该生成完整的验证集:
python perception/data_prepare/val_set_gen.py \ resume_from_checkpoint=./pretrained/SDv1.5mv-rawbox_2023-09-07_18-39_224x400 \ task_id=224x400 fid.img_gen_dir=./tmp/224x400 +fid=data_gen +exp=224x400 # 对于map=zero作为CFG的空条件,添加`runner.pipeline_param.use_zero_map_as_unconditional=true`
对于此脚本,也可以通过accelerate使用多进程/多节点。只需使用类似训练的命令启动即可。
然后,使用以下命令测试FID分数:
# 我们假设您的torch缓存目录位于"../pretrained/torch_cache/"。如果您想 # 使用默认位置,请注释掉"tools/fid_score.py"中倒数第二行。 python tools/fid_score.py cfg \ resume_from_checkpoint=./pretrained/SDv1.5mv-rawbox_2023-09-07_18-39_224x400 \ fid.rootb=tmp/224x400
或者,我们在这里提供了预生成的验证集样本。
您可以将它们放在./tmp中,并通过以下命令启动测试:
python tools/fid_score.py cfg \ resume_from_checkpoint=./pretrained/SDv1.5mv-rawbox_2023-09-07_18-39_224x400 \ fid.rootb=tmp/224x400/samples # FID=14.46065995481922 # 或 `fid.rootb=tmp/224x400map0/samples`,FID=16.195992872931697
定量结果
<details> <summary>比较MagicDrive与其他方法的生成质量:</summary>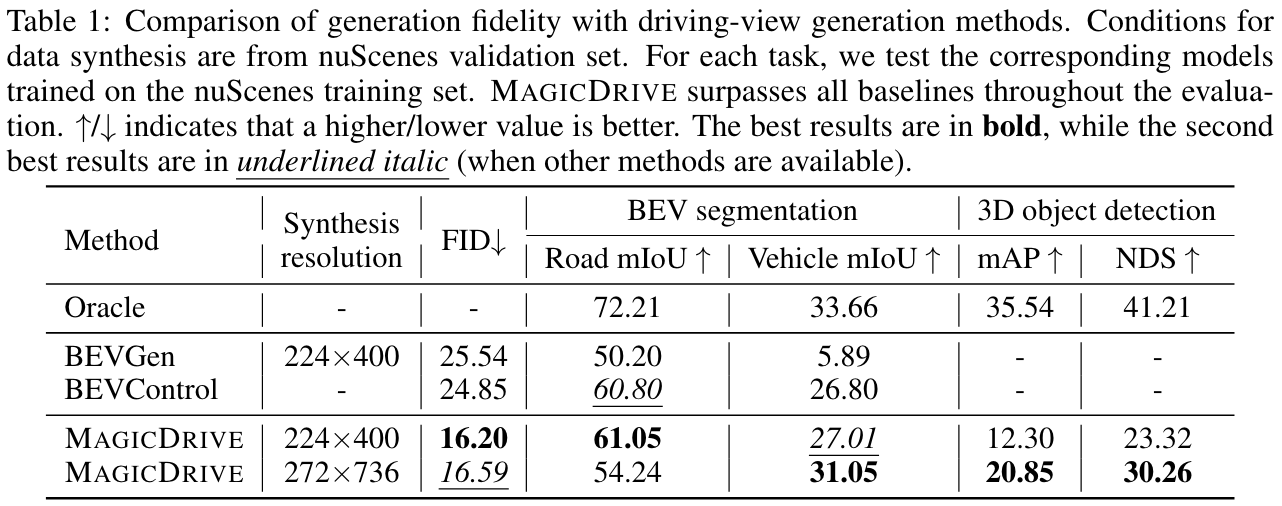
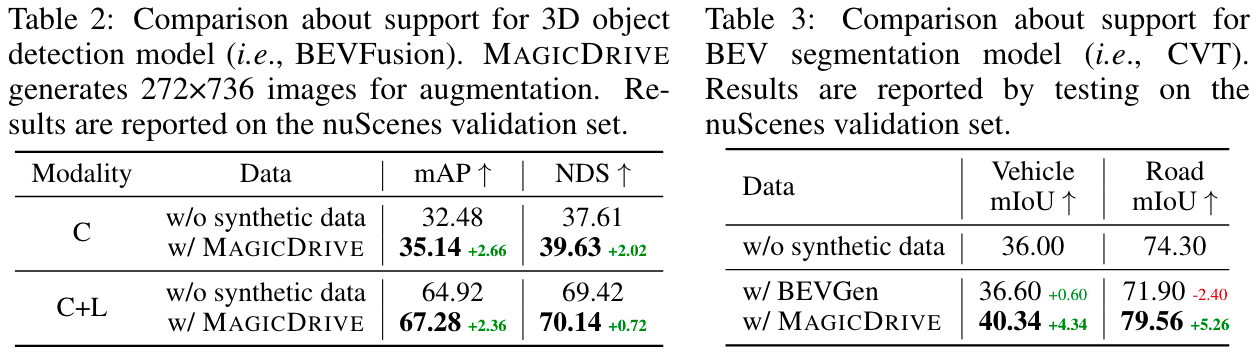
更多结果可以在主论文中找到。
定性结果
更多结果可以在主论文中找到。

引用我们
@inproceedings{gao2023magicdrive, title={{MagicDrive}: Street View Generation with Diverse 3D Geometry Control}, author={Gao, Ruiyuan and Chen, Kai and Xie, Enze and Hong, Lanqing and Li, Zhenguo and Yeung, Dit-Yan and Xu, Qiang}, booktitle = {International Conference on Learning Representations}, year={2024} }
致谢
我们采用了以下开源项目:
编辑推荐精选


扣子-AI办公
职场AI,就用扣子
AI办公助手,复杂任务高效处理。办公效率低?扣子空间AI助手支持播客生成、PPT制作、网页开发及报告写作,覆盖科研、商业、舆情等领域的专家Agent 7x24小时响应,生活工作无缝切换,提升50%效率!


堆友
多风格AI绘画神器
堆友平台由阿里巴巴设计团队创建,作为一款AI驱动的设计工具,专为设计师提供一站式增长服务。功能覆盖海量3D素材、AI绘画、实时渲染以及专业抠图,显著提升设计品质和效率。平台不仅提供工具,还是一个促进创意交流和个人发展的空间,界面友好,适合所有级别的设计师和创意工作者。


码上飞
零代码AI应用开发平台
零代码AI应用开发平台,用户只需一句话简单描述需求,AI能自动生成小程序、APP或H5网页应用,无需编写代码。


Vora
免费创建高清无水印Sora视频
Vora是一个免费创建高清无水印Sora视频的AI工具


Refly.AI
最适合小白的AI自动化工作流平台
无需编码,轻松生成可复用、可变现的AI自动化工作流


酷表ChatExcel
大模型驱动的Excel数据处理工具
基于大模型交互的表格处理系统,允许用户通过对话方式完成数据整理和可视化分析。系统采用机器学习算法解析用户指令,自动执行排序、公式计算和数据透视等操作,支持多种文件格式导入导出。数据处理响应速度保持在0.8秒以内,支持超过100万行数据的即时分析。


TRAE编程
AI辅助编程,代码自动修复
Trae是一种自适应的集成开发环境(IDE),通过自动化和多元协作改变开发流程。利用Trae,团队能够更快速、精确地编写和部署代码,从而提高编程效率和项目交付速度。Trae具备上下文感知和代码自动完成功能,是提升开发效率的理想工具。


AIWritePaper论文写作
AI论文写作指导平台
AIWritePaper论文写作是一站式AI论文写作辅助工具,简化了选题、文献检索至论文撰写的整个过程。通过简单设定,平台可快速生成高质量论文大纲和全文,配合图表、参考文献等一应俱全,同时提供开题报告和答辩PPT等增值服务,保障数据安全,有效提升写作效率和论文质量。


博思AIPPT
AI一键生成PPT,就用博思AIPPT!
博思AIPPT,新一代的AI生成PPT平台,支持智能生成PPT、AI美化PPT、文本&链接生成PPT、导入Word/PDF/Markdown文档生成PPT等,内置海量精美PPT模板,涵盖商务、教育、科技等不同风格,同时针对每个页面提供多种版式,一键自适应切换,完美适配各种办公场景。


潮际好麦
AI赋能电商视觉革命,一站式智能商拍平台
潮际好麦深耕服装行业,是国内AI试衣效果最好的软件。使用先进AIGC能力为电商卖家批量提供优质的、低成本的商拍图。合作品牌有Shein、Lazada、安踏、百丽等65个国内外头部品牌,以及国内10万+淘宝、天猫、京东等主流平台的品牌商家,为卖家节省将近85%的出图成本,提升约3倍出图效率,让品牌能够快速上架。
推荐工具精选




AI云服务特惠
懂AI专属折扣关注微信公众号
最新AI工具、AI资讯
独家AI资源、AI项目落地

微信扫一扫关注公众号