
cleanlab
开源工具自动检测和优化机器学习数据集
cleanlab是一款开源的数据中心AI工具包,能够自动检测机器学习数据集中的标签错误、异常值和重复项等问题。该工具适用于图像、文本和表格等各类数据,并支持所有机器学习模型。除了发现数据问题,cleanlab还可以训练更稳健的模型,评估数据质量。基于可靠的理论基础,cleanlab运行高效,操作简便,是优化数据质量和提升模型性能的实用工具。





cleanlab helps you clean data and labels by automatically detecting issues in a ML dataset. To facilitate machine learning with messy, real-world data, this data-centric AI package uses your existing models to estimate dataset problems that can be fixed to train even better models.
<p align="center"> <img src="https://raw.githubusercontent.com/cleanlab/assets/master/cleanlab/datalab_issues.png" width=74% height=74%> </p> <p align="center"> Examples of various issues in Cat/Dog dataset <b>automatically detected</b> by cleanlab via this code: </p>lab = cleanlab.Datalab(data=dataset, label="column_name_for_labels") # Fit any ML model, get its feature_embeddings & pred_probs for your data lab.find_issues(features=feature_embeddings, pred_probs=pred_probs) lab.report()
- Use cleanlab to automatically check every: image, text, audio, or tabular dataset.
- Use cleanlab to automatically: detect data issues (outliers, duplicates, label errors, etc), train robust models, infer consensus + annotator-quality for multi-annotator data, suggest data to (re)label next (active learning).
Try easy mode with Cleanlab Studio
While this open-source package finds data issues, its utility depends on you having: a good existing ML model + an interface to efficiently fix these issues in your dataset. Providing all these pieces, Cleanlab Studio is a Data Curation platform to find and fix problems in any {image, text, tabular} dataset. Cleanlab Studio automatically runs optimized algorithms from this package on top of AutoML & Foundation models fit to your data, and presents detected issues (+ AI-suggested fixes) in an intelligent data correction interface.
Try it for free! Adopting Cleanlab Studio enables users of this package to:
- Work 100x faster (1 min to analyze your raw data with zero code or ML work; optionally use Python API)
- Produce better-quality data (10x more types of issues auto detected & corrected via built-in AI)
- Accomplish more (auto-label data, deploy ML instantly, audit LLM inputs/outputs, moderate content, ...)
- Monitor incoming data and detect issues in real-time (integrate your data pipeline on an Enterprise plan)
Run cleanlab open-source
This cleanlab package runs on Python 3.8+ and supports Linux, macOS, as well as Windows.
- Get started here! Install via
piporconda. - Developers who install the bleeding-edge from source should refer to this master branch documentation.
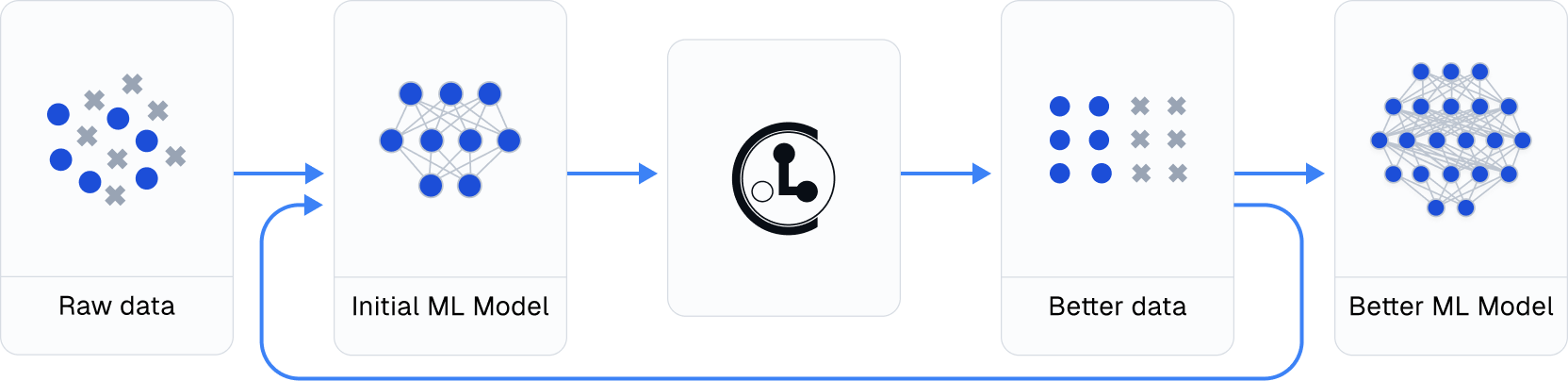
Practicing data-centric AI can look like this:
- Train initial ML model on original dataset.
- Utilize this model to diagnose data issues (via cleanlab methods) and improve the dataset.
- Train the same model on the improved dataset.
- Try various modeling techniques to further improve performance.
Most folks jump from Step 1 → 4, but you may achieve big gains without any change to your modeling code by using cleanlab! Continuously boost performance by iterating Steps 2 → 4 (and try to evaluate with cleaned data).
Use cleanlab with any model and in most ML tasks
All features of cleanlab work with any dataset and any model. Yes, any model: PyTorch, Tensorflow, Keras, JAX, HuggingFace, OpenAI, XGBoost, scikit-learn, etc.
cleanlab is useful across a wide variety of Machine Learning tasks. Specific tasks this data-centric AI package offers dedicated functionality for include:
- Binary and multi-class classification
- Multi-label classification (e.g. image/document tagging)
- Token classification (e.g. entity recognition in text)
- Regression (predicting numerical column in a dataset)
- Image segmentation (images with per-pixel annotations)
- Object detection (images with bounding box annotations)
- Classification with data labeled by multiple annotators
- Active learning with multiple annotators (suggest which data to label or re-label to improve model most)
- Outlier detection (identify atypical data that appears out of distribution)
For other ML tasks, cleanlab can still help you improve your dataset if appropriately applied. See our Example Notebooks and Blog.
So fresh, so cleanlab
Beyond automatically catching all sorts of issues lurking in your data, this data-centric AI package helps you deal with noisy labels and train more robust ML models. Here's an example:
# cleanlab works with **any classifier**. Yup, you can use PyTorch/TensorFlow/OpenAI/XGBoost/etc. cl = cleanlab.classification.CleanLearning(sklearn.YourFavoriteClassifier()) # cleanlab finds data and label issues in **any dataset**... in ONE line of code! label_issues = cl.find_label_issues(data, labels) # cleanlab trains a robust version of your model that works more reliably with noisy data. cl.fit(data, labels) # cleanlab estimates the predictions you would have gotten if you had trained with *no* label issues. cl.predict(test_data) # A universal data-centric AI tool, cleanlab quantifies class-level issues and overall data quality, for any dataset. cleanlab.dataset.health_summary(labels, confident_joint=cl.confident_joint)
cleanlab cleans your data's labels via state-of-the-art confident learning algorithms, published in this paper and blog. See some of the datasets cleaned with cleanlab at labelerrors.com.
cleanlab is:
- backed by theory -- with provable guarantees of exact label noise estimation, even with imperfect models.
- fast -- code is parallelized and scalable.
- easy to use -- one line of code to find mislabeled data, bad annotators, outliers, or train noise-robust models.
- general -- works with any dataset (text, image, tabular, audio,...) + any model (PyTorch, OpenAI, XGBoost,...) <br/>

Citation and related publications
cleanlab is based on peer-reviewed research. Here are relevant papers to cite if you use this package:
<details><summary><a href="https://arxiv.org/abs/1911.00068">Confident Learning (JAIR '21)</a> (<b>click to show bibtex</b>) </summary>@article{northcutt2021confidentlearning,
title={Confident Learning: Estimating Uncertainty in Dataset Labels},
author={Curtis G. Northcutt and Lu Jiang and Isaac L. Chuang},
journal={Journal of Artificial Intelligence Research (JAIR)},
volume={70},
pages={1373--1411},
year={2021}
}
@inproceedings{northcutt2017rankpruning,
author={Northcutt, Curtis G. and Wu, Tailin and Chuang, Isaac L.},
title={Learning with Confident Examples: Rank Pruning for Robust Classification with Noisy Labels},
booktitle = {Proceedings of the Thirty-Third Conference on Uncertainty in Artificial Intelligence},
series = {UAI'17},
year = {2017},
location = {Sydney, Australia},
numpages = {10},
url = {http://auai.org/uai2017/proceedings/papers/35.pdf},
publisher = {AUAI Press},
}
@inproceedings{kuan2022labelquality,
title={Model-agnostic label quality scoring to detect real-world label errors},
author={Kuan, Johnson and Mueller, Jonas},
booktitle={ICML DataPerf Workshop},
year={2022}
}
@inproceedings{kuan2022ood,
title={Back to the Basics: Revisiting Out-of-Distribution Detection Baselines},
author={Kuan, Johnson and Mueller, Jonas},
booktitle={ICML Workshop on Principles of Distribution Shift},
year={2022}
}
@inproceedings{wang2022tokenerrors,
title={Detecting label errors in token classification data},
author={Wang, Wei-Chen and Mueller, Jonas},
booktitle={NeurIPS Workshop on Interactive Learning for Natural Language Processing (InterNLP)},
year={2022}
}
@inproceedings{goh2022crowdlab,
title={CROWDLAB: Supervised learning to infer consensus labels and quality scores for data with multiple annotators},
author={Goh, Hui Wen and Tkachenko, Ulyana and Mueller, Jonas},
booktitle={NeurIPS Human in the Loop Learning Workshop},
year={2022}
}
@inproceedings{goh2023activelab,
title={ActiveLab: Active Learning with Re-Labeling by Multiple Annotators},
author={Goh, Hui Wen and Mueller, Jonas},
booktitle={ICLR Workshop on Trustworthy ML},
year={2023}
}
@inproceedings{thyagarajan2023multilabel,
title={Identifying Incorrect Annotations in Multi-Label Classification Data},
author={Thyagarajan, Aditya and Snorrason, Elías and Northcutt, Curtis and Mueller, Jonas},
booktitle={ICLR Workshop on Trustworthy ML},
year={2023}
}
@inproceedings{cummings2023drift,
title={Detecting Dataset Drift and Non-IID Sampling via k-Nearest Neighbors},
author={Cummings, Jesse and Snorrason, Elías and Mueller, Jonas},
booktitle={ICML Workshop on Data-centric Machine Learning Research},
year={2023}
}
@inproceedings{zhou2023errors,
title={Detecting Errors in Numerical Data via any Regression Model},
author={Zhou, Hang and Mueller, Jonas and Kumar, Mayank and Wang, Jane-Ling and Lei, Jing},
booktitle={ICML Workshop on Data-centric Machine Learning Research},
year={2023}
}
@inproceedings{tkachenko2023objectlab,
title={ObjectLab: Automated Diagnosis of Mislabeled Images in Object Detection Data},
author={Tkachenko, Ulyana and Thyagarajan, Aditya and Mueller, Jonas},
booktitle={ICML Workshop on Data-centric Machine Learning Research},
编辑推荐精选


Pixmax
一站式AI短剧创作平台
Pixmax专注打造下一代“ AI 视觉创作引擎”,整合行业顶尖 AI 大模型、工工业级精准控制及企业级协同管理功能,是全方位的 AI 内容创作平台。


豆包
字节跳动旗下 AI 智能助手
字节跳动旗下 AI 智能助手


GPT Plus|Pro充值
GPT充值
支持 ChatGPT Plus / Pro 充值服务,支付便捷,自动发货,售后可查。


GPT Image 2中文站
AI 图片生成平台
GPT Image 2 是面向用户的 AI 图片生成平台,支持文生图、图生图及多模型创意工作流。


Vecbase
你的AI Agent团队
Vecbase 是专为 AI 团队打造的智能工作空间,将数据管理、模型协作与知识沉淀整合于一处。算法、产品与业务在同一平台无缝协同,让从数据到 AI 应用的落地更快一步。


音�述AI
全球首个AI音乐社区
音述AI是全球首个AI音乐社区,致力让每个人都能用音乐表达自我。音述AI提供零门槛AI创作工具,独创GETI法则帮助用户精准定义音乐风格,AI润色功能支持自动优化作品质感。音述AI支持交流讨论、二次创作与价值变现。针对中文用户的语言习惯与文化背景进行专门优化,支持国风融合、C-pop等本土音乐标签,让技术更好地承载人文表达。


QoderWork
阿里Qoder团队推出的桌面端AI智能体
QoderWork 是阿里推出的本地优先桌面 AI 智能体,适配 macOS14+/Windows10+,以自然语言交互实现文件管理、数据分析、AI 视觉生成、浏览器自动化等��办公任务,自主拆解执行复杂工作流,数据本地运行零上传,技能市场可无限扩展,是高效的 Agentic 生产力办公助手。


lynote.ai
一站式搞定所有学习需求
不再被海量信息淹没,开始真正理解知识。Lynote 可摘要 YouTube 视频、PDF、文章等内容。即时创建笔记,检测 AI 内容并下载资料,将您的学习效率提升 10 倍。


AniShort
为AI短剧协作而生
专为AI短剧协作而生的AniShort正式发布,深度重构AI短剧全流程生产模式,整合创意策划、制作执行、实时协作、在线审片、资产复用等全链路功能,独创无限画布、双轨并行工业化工作流与Ani智能体助手,集成多款主流AI大模型,破解素材零散、版本混乱、沟通低效等行业痛点,助力3人团队效率提升800%,打造标准化、可追溯的AI短剧量产体系,是AI短剧团队协同创作、提升制作效率的核心工具。


seedancetwo2.0
能听懂你表达的视频模型
Seedance two是基于seedance2.0的中国大模型,支持图像、视频、音频、文本四种模态输入,表达方式更丰富,生成也更可控。
推荐工具精选






AI云服务特惠
懂AI专属折扣关注微信公众号
最新AI工具、AI资讯
独家AI资源、AI项目落地

微信扫一扫关注公众号