


<a href="https://blobcity.com"><img src="https://cdn.blobcity.com/assets/blobcity-logo.svg" style="width: 40%"/></a>
![]()
BlobCity AutoAI
A framework to find the best performing AI/ML model for any AI problem. Works for Classification and Regression type of problems on numerical data. AutoAI makes AI easy and accessible to everyone. It not only trains the best-performing model but also exports high-quality code for using the trained model.
The framework is currently in beta release, with active development being still in progress. Please report any issues you encounter.
Getting Started
pip install blobcity
import blobcity as bc model = bc.train(file="data.csv", target="Y_column") model.spill("my_code.py")
Y_column is the name of the target column. The column must be present within the data provided.
Automatic inference of Regression / Classification is supported by the framework.
Data input formats supported include:
- Local CSV / XLSX file
- URL to a CSV / XLSX file
- Pandas DataFrame
model = bc.train(file="data.csv", target="Y_column") #local file
model = bc.train(file="https://example.com/data.csv", target="Y_column") #url
model = bc.train(df=my_df, target="Y_column") #DataFrame
Pre-processing
The framework has built-in support for several data pre-processing techniques, such as imputing missing values, column encoding, and data scaling.
Pre-processing is carried out automatically on train data. The predict function carries out the same pre-processing on new data. The user is not required to be concerned with the pre-processing choices of the framework.
One can view the pre-processing methods used on the data by exporting the entire model configuration to a YAML file. Check the section below on "Exporting to YAML."
Feature Selection
model.features() #prints the features selected by the model
['Present_Price', 'Vehicle_Age', 'Fuel_Type_CNG', 'Fuel_Type_Diesel', 'Fuel_Type_Petrol', 'Seller_Type_Dealer', 'Seller_Type_Individual', 'Transmission_Automatic', 'Transmission_Manual']
AutoAI automatically performs a feature selection on input data. All features (except target) are potential candidates for the X input.
AutoAI will automatically remove ID / Primary-key columns.
This does not guarantee that all specified features will be used in the final model. The framework will perform an automated feature selection from amongst these features. This only guarantees that other features if present in the data will not be considered.
AutoAI ignores features that have a low importance to the effective output. The feature importance plot can be viewed.
model.plot_feature_importance() #shows a feature importance graph
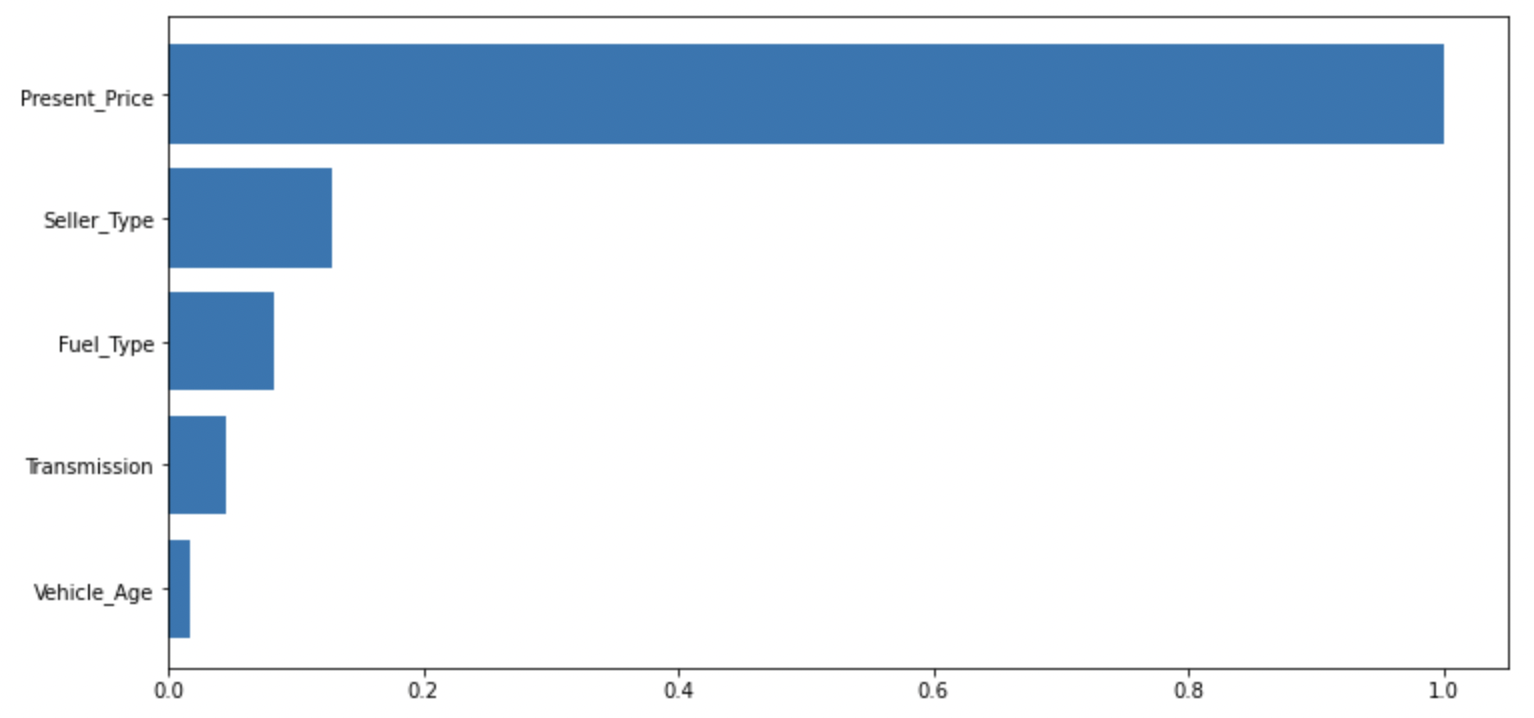
There might be scenarios where you want to explicitely exclude some columns, or only use a subset of columns in the training. Manually specify the features to be used. AutoAI will still perform a feature selection within the list of features provided to improve effective model accuracy.
model = bc.train(file="data.csv", target="Y_value", features=["col1", "col2", "col3"])
Model Search, Train & Hyper-parameter Tuning
Model search, train and hyper-parameter tuning is fully automatic. It is a 3 step process that tests your data across various AI/ML models. It finds models with high success tendency, and performs a hyper-parameter tuning to find you the best possible result.
Code Generation
High-quality code generation is why most Data Scientists choose AutoAI. The spill function generates the model code with exhaustive documentation. scikit-learn models export with training code included. TensorFlow and other DNN models produce only the test / final use code.
Code generation is supported in ipynb and py file formats, with options to enable or disable detailed documentation exports.
model.spill("my_code.ipynb"); #produces Jupyter Notebook file with full markdown docs
model.spill("my_code.py") #produces python code with minimal docs
model.spill("my_code.py", docs=True) #python code with full docs
model.spill("my_code.ipynb", docs=False) #Notebook file with minimal markdown
Predictions
Use a trained model to generate predictions on new data.
prediction = model.predict(file="unseen_data.csv")
All required features must be present in the unseen_data.csv file. Consider checking the results of the automatic feature selection to know the list of features needed by the predict function.
Stats & Accuracy
model.plot_prediction()
The function is shared across Regression and Classification problems. It plots a relevant chart to assess efficiency of training.
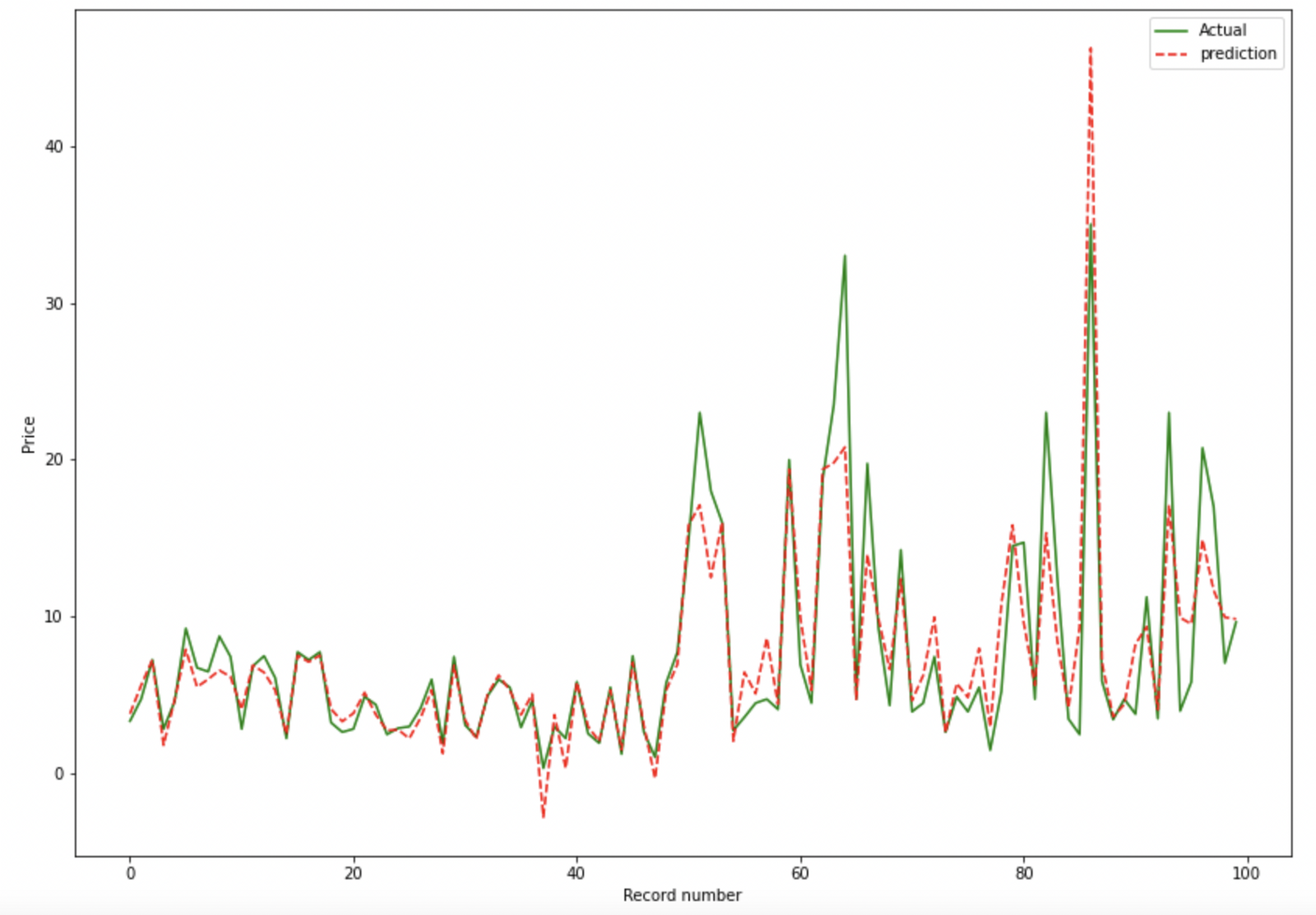
Actual v/s Predicted Plot (for Regression)
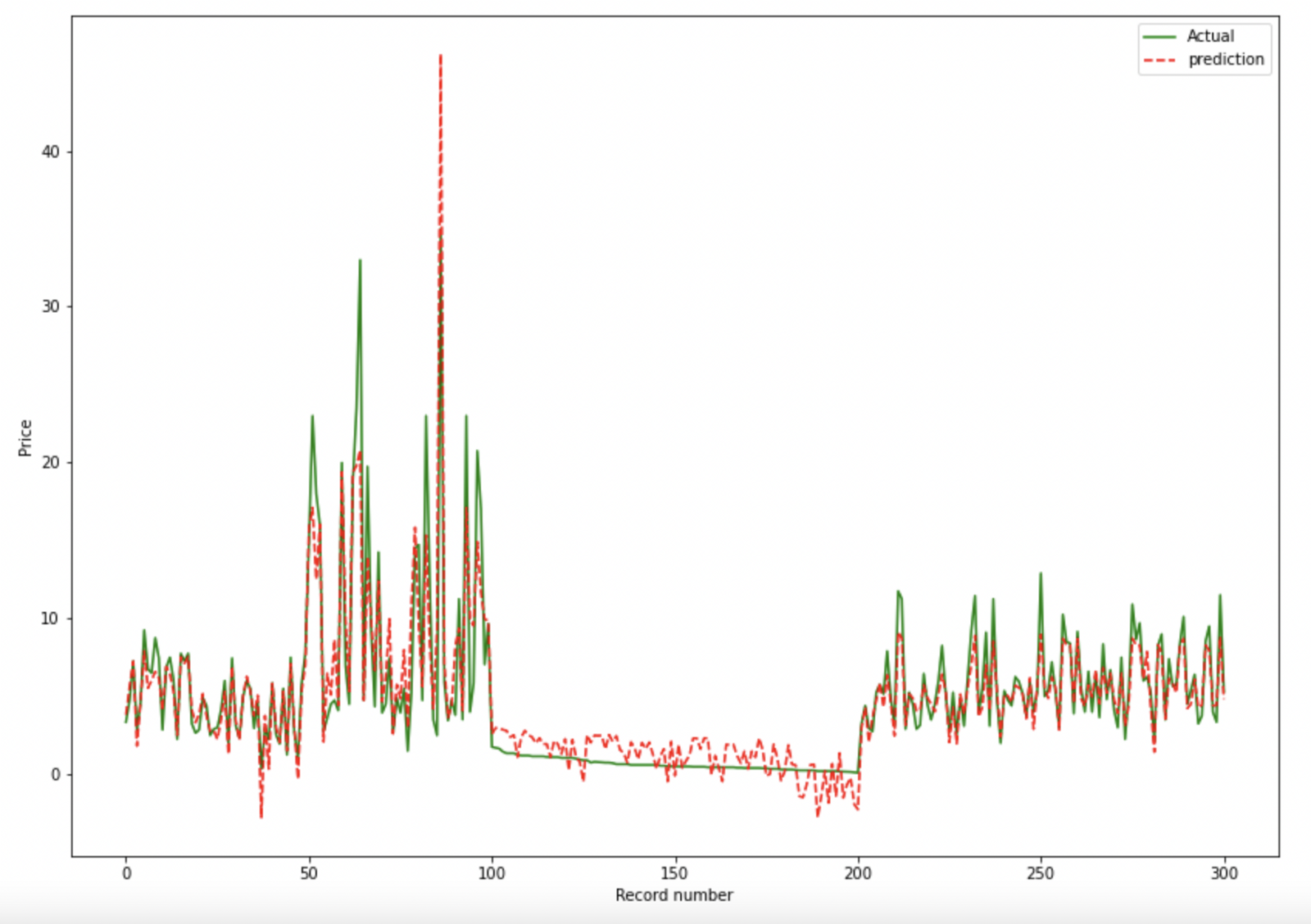
Plotting only first 100 rows. You can specify -100 to plot last 100 rows.
model.plot_prediction(100)
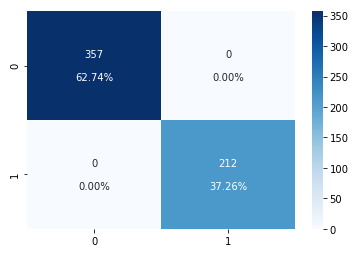
Confusion Matrix (for Classification)
model.plot_prediction()
Numercial Stats & Model Description
model.summary()
Print model configuration/Hyper Parameter tuning along the key model static parameters, such as Precision, Recall, F1-Score,etc. The parameters change based on the type of AutoAI problem. It also provide information on different data preprocessing steps applied during the complete process.
Persistence
model.save('./my_model.pkl')
model = bc.load('./my_model.pkl')
You can save a trained model, and load it in the future to generate predictions.
Accelerated Training
Leverage BlobCity AI Cloud for fast training on large datasets. Reasonable cloud infrastructure included for free.
Features and Roadmap
- Numercial data Classification and Regression
- Automatic feature selection
- Code generation
- Neural Networks & Deep Learning
Upcoming Releases
- ChatGPT API integration
- Natural Language Processing
- Text to Audio / Audio to Text
- Generative AI using GAN (train your own model)
编辑推荐精选


扣子-AI办公
职场AI,就用扣子
AI办公助手,复杂任务高效处理。办公效率低?扣子空间AI助手支持播客生成、PPT制作、网页开发及报告写作,覆盖科研、商业、舆情等领域的专家Agent 7x24小时响应,生活工作无缝切换,提升50%效率!


堆友
多风格AI绘画神器
堆友平台由阿里巴巴设计团队创建,作为一款AI驱动的设计工具,专为设计师提供一站式增长服务。功能覆盖海��量3D素材、AI绘画、实时渲染以及专业抠图,显著提升设计品质和效率。平台不仅提供工具,还是一个促进创意交流和个人发展的空间,界面友好,适合所有级别的设计师和创意工作者。


码上飞
零代码AI应用开发平台
零代码AI应用开发平台,用户只需一句话简单描述需求,AI能自动生成小程序、APP或H5网页应用,无需编写代码。


Vora
免费创建高清无水印Sora视频
Vora是一个免费创建高清无水印Sora视频的AI工具


Refly.AI
最适合小白的AI自动化工作流平台
无需编码,轻松生成可复用、可变现的AI自动化工作流


酷表ChatExcel
大模型驱动的Excel数据处理工具
基��于大模型交互的表格处理系统,允许用户通过对话方式完成数据整理和可视化分析。系统采用机器学习算法解析用户指令,自动执行排序、公式计算和数据透视等操作,支持多种文件格式导入导出。数据处理响应速度保持在0.8秒以内,支持超过100万行数据的即时分析。


TRAE编程
AI辅助编程,代码自动修复
Trae是一种自适应的集成开发环境(IDE),通过自动化和多元协作改变开发流程。利用Trae,团队能够更快速、精确地编写和部署代码,从而提高编程效率和项目交付速度。Trae具备上下文感知和代码自动完成功能,是提升开发效率的理想工具。


AIWritePaper论文写作
AI论文写作指导平台
AIWritePaper论文写作是一站式AI论文写作辅助工具,简化了选题、文献检索至论文撰写的整个过程。通过简单设定,平台可快速生成高质量论文大纲和全文,配合图表、参考文献等一应俱全,同时提供开题报告和答辩PPT等增值服务,保障数据安全,有效提升写作效率和论文质量。


博思AIPPT
AI一键生成PPT,就用博思AIPPT!
博思AIPPT,新一代的AI生成PPT平台,支持智能生成PPT、AI美化PPT、文本&链接生成PPT、导入Word/PDF/Markdown文档生成PPT等,内置海量精美PPT模板,涵盖商务、教育、科技等不同风格,同时针对每个页面提供多种版式,一键自适应切换,完美适配各种办公场景。


潮际好麦
AI赋能电商视觉革命,一站式智能商拍平台
潮际好麦深耕服装行业,是国内AI试衣效果最好的软件。使用先进AIGC能力为电商卖家批量提供优质的、低成本的商拍图。合作品牌有Shein、Lazada、安踏、百丽等65个国内外头部品牌,以及国内10万+淘宝、天猫、京东等主流平台的品牌商家,为卖家节省将近85%的出图成本,提升约3倍出图效率,让品牌能够快速上架。
推荐工具精选




AI云服务特惠
懂AI专属折扣关注微信公众号
最新AI工具、AI资讯
独家AI资源、AI项目落地

微信扫一扫关注公众号