
AniPortrait
基于音频的高质量肖像动画生成框架
AniPortrait是一个基于音频和参考肖像图像生成高质量动画的开源框架。该项目支持自驱动、面部重演和音频驱动三种模式,可生成逼真的肖像动画。项目开源了预训练模型,并提供了详细的安装指南、推理命令和训练流程。AniPortrait为数字内容创作者提供了一种制作生动肖像动画的新方法,拓展了视觉内容创作的可能性。



AniPortrait
AniPortrait:音频驱动的真实感人像动画合成
作者:魏华伟、杨泽骏、王志胜
机构:腾讯游戏智绘、腾讯

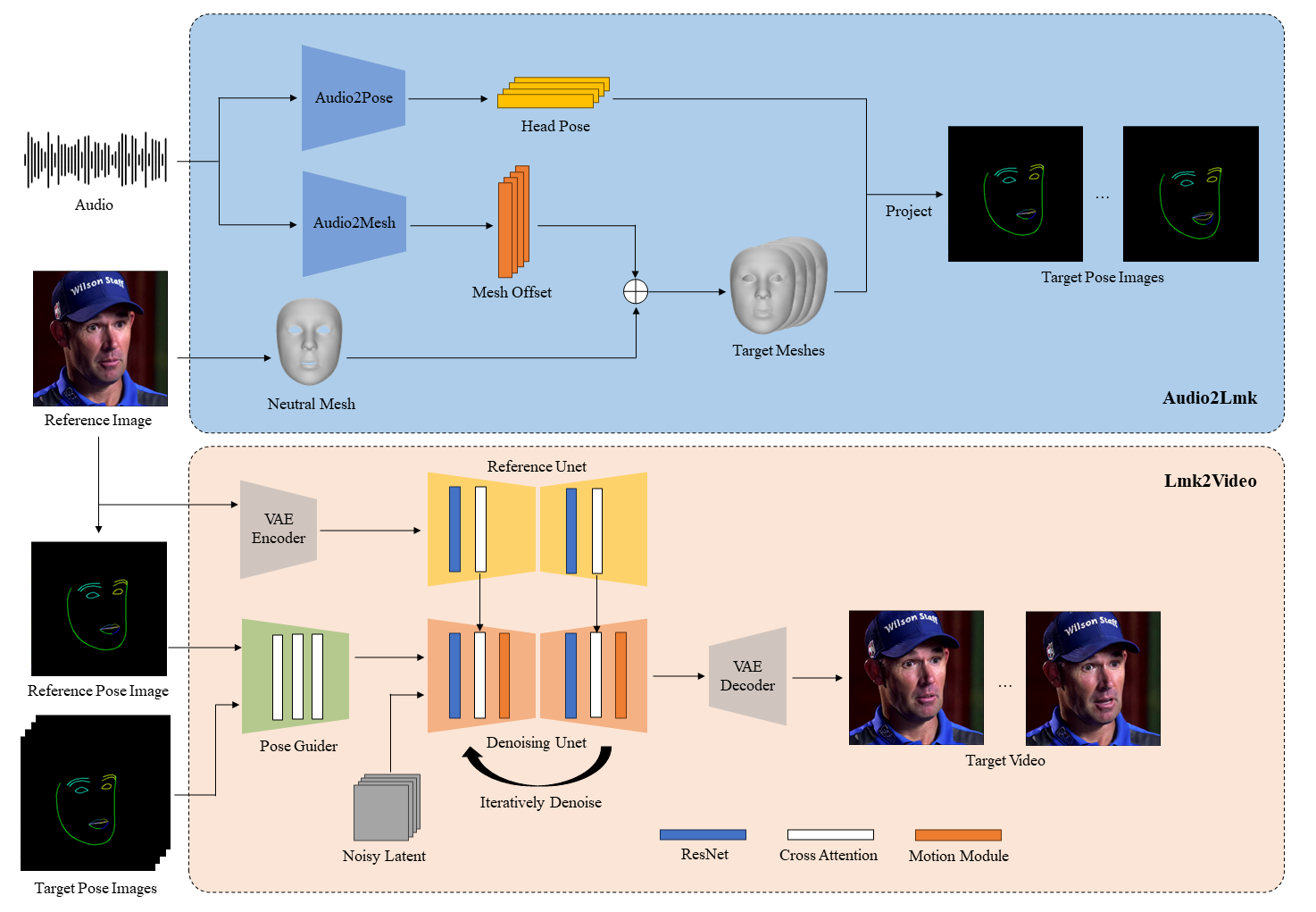
我们在此提出AniPortrait,这是一个新颖的框架,用于生成由音频和参考人像图像驱动的高质量动画。您还可以提供视频来实现面部重演。
<a href='https://arxiv.org/abs/2403.17694'><img src='https://img.shields.io/badge/论文-Arxiv-red'></a> <a href='https://huggingface.co/ZJYang/AniPortrait/tree/main'><img src='https://img.shields.io/badge/%F0%9F%A4%97%20Hugging%20Face-模型-orange'></a> <a href='https://huggingface.co/spaces/ZJYang/AniPortrait_official'><img src='https://img.shields.io/badge/%F0%9F%A4%97%20Hugging%20Face-演示-green'></a>
流程
更新 / 待办事项
-
✅ [2024/03/27] 我们的论文现已在arXiv上发布。
-
✅ [2024/03/27] 更新代码以生成pose_temp.npy用于头部姿势控制。
-
✅ [2024/04/02] 更新了vid2vid的新姿势重定向策略。现在我们支持参考图像和源视频之间的实质性姿势差异。
-
✅ [2024/04/03] 我们在HuggingFace Spaces上发布了Gradio 演示(感谢HF团队提供免费GPU支持)!
-
✅ [2024/04/07] 更新了帧插值模块以加速推理过程。现在您可以在推理命令中添加-acc以获得更快的视频生成。
-
✅ [2024/04/21] 我们已发布audio2pose模型和音频到视频的预训练权重。请更新代码并下载权重文件以体验。
各种生成的视频
自驱动
<table class="center"> <tr> <td width=50% style="border: none"> <video controls autoplay loop src="https://github.com/Zejun-Yang/AniPortrait/assets/21038147/82c0f0b0-9c7c-4aad-bf0e-27e6098ffbe1" muted="false"></video> </td> <td width=50% style="border: none"> <video controls autoplay loop src="https://github.com/Zejun-Yang/AniPortrait/assets/21038147/51a502d9-1ce2-48d2-afbe-767a0b9b9166" muted="false"></video> </td> </tr> </table>面部重演
<table class="center"> <tr> <td width=50% style="border: none"> <video controls autoplay loop src="https://github.com/Zejun-Yang/AniPortrait/assets/21038147/d4e0add6-20a2-4f4b-808c-530a6f4d3331" muted="false"></video> </td> <td width=50% style="border: none"> <video controls autoplay loop src="https://github.com/Zejun-Yang/AniPortrait/assets/21038147/849fce22-0db1-4257-a75f-a5dc655e6b9e" muted="false"></video> </td> </tr> </table>视频来源:鹿火CAVY from bilibili
音频驱动
<table class="center"> <tr> <td width=50% style="border: none"> <video controls autoplay loop src="https://github.com/Zejun-Yang/AniPortrait/assets/21038147/63171e5a-e4c1-4383-8f20-9764524928d0" muted="false"></video> </td> <td width=50% style="border: none"> <video controls autoplay loop src="https://github.com/Zejun-Yang/AniPortrait/assets/21038147/6fd74024-ba19-4f6b-b37a-10df5cf2c934" muted="false"></video> </td> </tr> <tr> <td width=50% style="border: none"> <video controls autoplay loop src="https://github.com/Zejun-Yang/AniPortrait/assets/21038147/9e516cc5-bf09-4d45-b5e3-820030764982" muted="false"></video> </td> <td width=50% style="border: none"> <video controls autoplay loop src="https://github.com/Zejun-Yang/AniPortrait/assets/21038147/7c68148b-8022-453f-be9a-c69590038197" muted="false"></video> </td> </tr> </table>安装
构建环境
我们推荐Python版本 >=3.10 和CUDA版本 =11.7。然后按如下方式构建环境:
pip install -r requirements.txt
下载权��重
所有权重应放置在 ./pretrained_weights 目录下。您可以按以下方式手动下载权重:
-
下载我们训练的权重,其中包括以下部分:
denoising_unet.pth、reference_unet.pth、pose_guider.pth、motion_module.pth、audio2mesh.pt、audio2pose.pt和film_net_fp16.pt。您也可以从 wisemodel 下载。 -
下载基础模型和其他组件的预训练权重:
最后,这些权重应按如下方式组织:
./pretrained_weights/ |-- image_encoder | |-- config.json | `-- pytorch_model.bin |-- sd-vae-ft-mse | |-- config.json | |-- diffusion_pytorch_model.bin | `-- diffusion_pytorch_model.safetensors |-- stable-diffusion-v1-5 | |-- feature_extractor | | `-- preprocessor_config.json | |-- model_index.json | |-- unet | | |-- config.json | | `-- diffusion_pytorch_model.bin | `-- v1-inference.yaml |-- wav2vec2-base-960h | |-- config.json | |-- feature_extractor_config.json | |-- preprocessor_config.json | |-- pytorch_model.bin | |-- README.md | |-- special_tokens_map.json | |-- tokenizer_config.json | `-- vocab.json |-- audio2mesh.pt |-- audio2pose.pt |-- denoising_unet.pth |-- film_net_fp16.pt |-- motion_module.pth |-- pose_guider.pth `-- reference_unet.pth
注意:如果您已经安装了一些预训练模型,比如 StableDiffusion V1.5,您可以在配置文件中指定它们的路径(例如 ./config/prompts/animation.yaml)。
Gradio Web界面
您可以通过以下命令尝试我们的网页演示。我们还在Hugging Face Spaces提供在线演示<a href='https://huggingface.co/spaces/ZJYang/AniPortrait_official'><img src='https://img.shields.io/badge/%F0%9F%A4%97%20Hugging%20Face-Demo-green'></a>。
python -m scripts.app
推理
请注意,您可以在命令中设置 -L 为所需生成的帧数,例如 -L 300。
加速方法:如果生成视频需要很长时间,您可以下载 film_net_fp16.pt 并将其放在 ./pretrained_weights 目录下。然后在命令中添加 -acc。
以下是运行推理脚本的命令行指令:
自驱动
python -m scripts.pose2vid --config ./configs/prompts/animation.yaml -W 512 -H 512 -acc
您可以参考 animation.yaml 的格式来添加您自己的参考图像或姿势视频。要将原始视频转换为姿势视频(关键点序列),您可以运行以下命令:
python -m scripts.vid2pose --video_path pose_video_path.mp4
人脸重演
python -m scripts.vid2vid --config ./configs/prompts/animation_facereenac.yaml -W 512 -H 512 -acc
在 animation_facereenac.yaml 中添加源人脸视频和参考图像。
音频驱动
python -m scripts.audio2vid --config ./configs/prompts/animation_audio.yaml -W 512 -H 512 -acc
在 animation_audio.yaml 中添加音频和参考图像。
删除 ./configs/prompts/animation_audio.yaml 中的 pose_temp 可以启用 audio2pose 模型。
您还可以使用此命令生成用于头部姿势控制的 pose_temp.npy:
python -m scripts.generate_ref_pose --ref_video ./configs/inference/head_pose_temp/pose_ref_video.mp4 --save_path ./configs/inference/head_pose_temp/pose.npy
训练
数据准备
从原始视频中提取关键点并编写训练json文件(这里以处理VFHQ为例):
python -m scripts.preprocess_dataset --input_dir VFHQ_PATH --output_dir SAVE_PATH --training_json JSON_PATH
更新训练配置文件中的行:
data: json_path: JSON_PATH
第一阶段
运行命令:
accelerate launch train_stage_1.py --config ./configs/train/stage1.yaml
第二阶段
将预训练的运动模块权重 mm_sd_v15_v2.ckpt(下载链接)放在 ./pretrained_weights 下。
在配置文件 stage2.yaml 中指定第一阶段的训练权重,例如:
stage1_ckpt_dir: './exp_output/stage1' stage1_ckpt_step: 30000
运行命令:
accelerate launch train_stage_2.py --config ./configs/train/stage2.yaml
致谢
我们首先感谢 EMO 的作者,我们的演示中部分图像和音频来自EMO。此外,我们要感谢 Moore-AnimateAnyone、majic-animate、animatediff 和 Open-AnimateAnyone 仓库的贡献者,感谢他们的开放研究和探索。
引用
@misc{wei2024aniportrait,
title={AniPortrait: Audio-Driven Synthesis of Photorealistic Portrait Animations},
author={Huawei Wei and Zejun Yang and Zhisheng Wang},
year={2024},
eprint={2403.17694},
archivePrefix={arXiv},
primaryClass={cs.CV}
}
编辑推荐精选


扣子-AI办公
职场AI,就用扣子
AI办公助手,复杂任务高效处理。办公效率低?扣子空间AI助手支持播客生成、PPT制作、网页开发及报告写作,覆盖科研、商业、舆情等领域的专家Agent 7x24小时响应,生活工作无缝切换,提升50%效率!


堆友
多风格AI绘画神器
堆友平台由阿里巴巴设计团队创建,作为一款AI驱动的设计工具,专为设计师提供一站式增长服务。功能覆盖海量3D素材、AI绘画、实时渲染以及专业抠图,显著提升设计品质和效率。平台不仅提供工具,还是一个促进创意交流和个人发展的空间,界面友好,适合所有级别的设计师和创意工作者。


码上飞
零代码AI应用开发平台
零代码AI应用开发平台,用户只需一句话简单描述需求,AI能自动生成小程序、APP或H5网页应用,无需编写代码。


Vora
免费创建高清无水印Sora视频
Vora是一个免费创建高清无水印Sora视频的AI工具


Refly.AI
最适合小白的AI自动化工作流平台
无需编码,轻松生成可复用、可变现的AI自动化工作流


酷表ChatExcel
大模型驱动的Excel数据处理工具
基于大模型交互的表格处理系统,允许用户通过对话方式完成数据整理和可视化分析。系统采用机器学习算法解析用户指令,自动执行排序、公式计算和数据透视等操作,支持多种文件格式导入导出。数据处理响应速度保持在0.8秒以内,支持超过100万行数据的即时分析。


TRAE编程
AI辅助编程,代码自动修复
Trae是一种自适应的集成开发环境(IDE),通过自动化和多元协作改变开发流程。利用Trae,团队能够更快速、精确地编写和部署代码,从而提高编程效率和项目交付速度。Trae具备上下文感知和代码自动完成功能,是提升开发效率的理想工具。


AIWritePaper论文写作
AI论文写作指导平台
AIWritePaper论文写作是一站式AI论文写作辅助工具,简化了选题、文献检索至论文撰写的整个过程。通过简单设定,平台可快速生成高质量论文大纲和全文,配合图表、参考文献等一应俱全,同时提供开题报告和答辩PPT等增值服务,保障数据安全,有效提升写作效率和论文质量。


博思AIPPT
AI一键生成PPT,就用博思AIPPT!
博思AIPPT,新一代的AI生成PPT平台,支持智能生成PPT、AI美化PPT、文本&链接生成PPT、导入Word/PDF/Markdown文档生成PPT等,内置海量精美PPT模板,涵盖商务、教育、科技等不同风格,同时针对每个页面提供多种版式,一键自适应切换,完美适配各种办公场景。


潮际好麦
AI赋能电商视觉革命,一站式智能商拍平台
潮际好麦深耕服装行业,是国内AI试衣效果最好的软件。使用先进AIGC能力为电商卖家批量提供优质的、低成本的商拍图。合作品牌有Shein、Lazada、安踏、百丽等65个国内外头部品牌,以及国内10万+淘宝、天猫、京东等主流平台的品牌商家,为卖家节省将近85%的出图成本,提升约3倍出图效率,让品牌能够快速上架。
推荐工具精选




AI云服务特惠
懂AI专属折扣关注微信公众号
最新AI工具、AI资讯
独家AI资源、AI项目落地

微信扫一扫关注公众号