
MiniGPT4-video
提升视频理解的创新多模态语言模型
MiniGPT4-Video项目采用交错视觉-文本标记技术,大幅提升了多模态大语言模型的视频理解能力。该模型在短视频理解方面表现优异,多项基准测试中均优于现有方法。项目还开发了Goldfish框架,专门应对任意长度视频的处理难题,有效解决了长视频理解中的噪声、冗余和计算挑战。这些创新成果为视频分析和理解领域开辟了新的可能性。




[ECCV 2024接收]Goldfish:任意长度视频的视觉-语言理解
[CVPR2024W]MiniGPT4-Video:通过交错的视觉-文本标记推进多模态LLM的视频理解
本仓库包含用于短视频理解的MiniGPT4-video和长视频理解的Goldfish的代码。
<h3 style="text-align: center;">在线演示</h3> <div style="display: flex; justify-content: center; gap: 40px;"> <div style="text-align: center;"> <a href='https://goldfish.loophole.site'> <img src='https://yellow-cdn.veclightyear.com/835a84d5/83697b83-7221-4448-8a61-259e99fbbd98.png' width=200 height=200> </a> <div> <font size=3> <div> <img src="https://yellow-cdn.veclightyear.com/835a84d5/83697b83-7221-4448-8a61-259e99fbbd98.png" width=18> <a href="https://vision-cair.github.io/Goldfish_website/">项目主页</a> <a href="https://arxiv.org/abs/2407.12679">📝 arXiv论文</a> <a href="https://huggingface.co/datasets/Vision-CAIR/TVQA-Long/tree/main">🤗 TVQA-Long数据集</a> </div> </font> </div> </div> <div style="text-align: center;"> <a href='https://huggingface.co/spaces/Vision-CAIR/MiniGPT4-video'> <img src='https://yellow-cdn.veclightyear.com/835a84d5/371a6768-fa8a-42f2-9dbf-5a24ea0ce50c.png' width=200 height=200> </a> <div> <font size=3> <div> <a href="https://vision-cair.github.io/MiniGPT4-video/">🎞️ 项目主页</a> <a href="https://arxiv.org/abs/2404.03413">📝 arXiv论文</a> </div> </font> </div> </div> </div>
概述
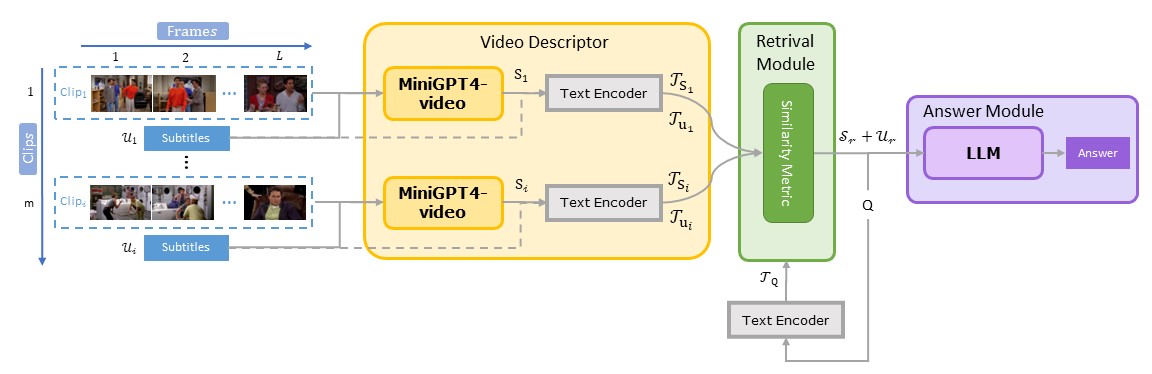
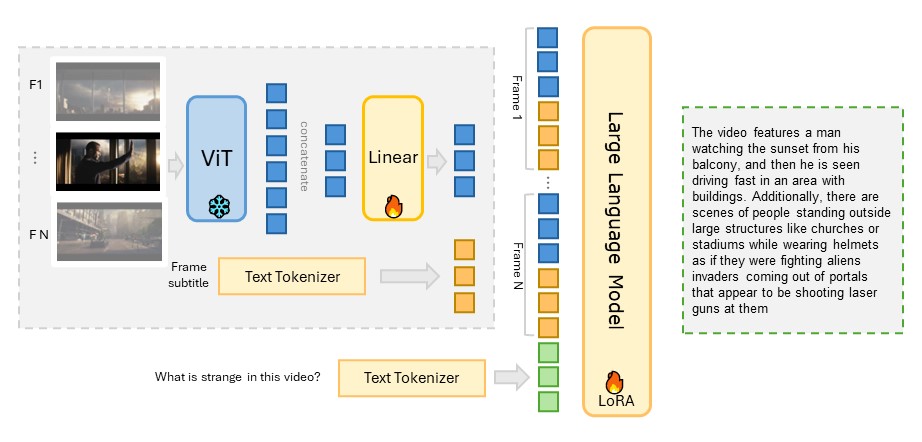
目前大多数基于LLM的视频理解模型可以处理几分钟内的视频,但在处理长视频时面临"噪声和冗余挑战"以及"内存和计算"挑战。在本文中,我们提出了Goldfish,一种专门用于理解任意长度视频的方法。我们还引入了TVQA-long基准,专门用于评估模型在理解长视频中视觉和文本内容问题的能力。Goldfish通过一种高效的检索机制来应对这些挑战,该机制首先收集与指令相关的前k个视频片段,然后再提供所需的响应。这种检索机制的设计使Goldfish能够高效处理任意长度的视频序列,方便其在电影或电视剧等场景中的应用。为了促进检索过程,我们开发了MiniGPT4-Video,用于为视频片段生成详细描述。为解决长视频评估基准的稀缺问题,我们通过汇总整个剧集的问题,将TVQA短视频基准调整为扩展内容分析,从而将评估从部分理解转变为完整剧集理解。我们在TVQA-long基准上达到了41.78%的准确率,比之前的方法高出14.94%。我们的MiniGPT4-Video在短视频理解方面也表现出色,在MSVD、MSRVTT、TGIF和TVQA短视频基准上分别超过现有最先进方法3.23%、2.03%、16.5%和23.59%。这些结果表明,我们的模型在长视频和短视频理解方面都有显著改进。
Goldfish框架(长视频)
 <br>
<br>
MiniGPT4-Video(短视频)
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
:rocket: 演示
1. 克隆仓库
git clone https://github.com/Vision-CAIR/MiniGPT4-video.git cd MiniGPT4-video
2. 设置环境
conda env create -f environment.yml
3. 下载检查点
| MiniGPT4-Video (Llama2 Chat 7B) | MiniGPT4-Video (Mistral 7B) |
|---|---|
| 下载 | 下载 |
4. 运行演示 金鱼演示
# 为获得推荐性能,在下面的命令中添加参数 --use_openai_embedding True,并在环境变量 OPENAI_API_KEY 中设置 API 密钥,否则模型将使用�默认嵌入。 export OPENAI_API_KEY="你的_openai_密钥" # Llama2 python goldfish_demo.py --ckpt 视频检查点路径 --cfg-path test_configs/llama2_test_config.yaml # Mistral python goldfish_demo.py --ckpt 视频检查点路径 --cfg-path test_configs/mistral_test_config.yaml
MiniGPT4-Video 演示
# Llama2 python minigpt4_video_demo.py --ckpt 视频检查点路径 --cfg-path test_configs/llama2_test_config.yaml # Mistral python minigpt4_video_demo.py --ckpt 视频检查点路径 --cfg-path test_configs/mistral_test_config.yaml
推理
执行之前的步骤,并用此步骤替换步骤 4 金鱼推理
# 为获得推荐性能,在下面的命令中添加参数 --use_openai_embedding True,并在环境变量 OPENAI_API_KEY 中设置 API 密钥,否则模型将使用默认嵌入。 export OPENAI_API_KEY="你的_openai_密钥" # Llama2 python goldfish_inference.py --ckpt llama2检查点路径 --cfg-path test_configs/llama2_test_config.yaml --video_path 视频路径 --question "你的问题" # Mistral python goldfish_inference.py --ckpt mistral检查点路径 --cfg-path test_configs/mistral_test_config.yaml --video_path 视频路径 --question "你的问题"
MiniGPT4-Video 推理
# Llama2 python minigpt4_video_inference.py --ckpt llama2检查点路径 --cfg-path test_configs/llama2_test_config.yaml --video_path 视频路径 --question "你的问题" # Mistral python minigpt4_video_inference.py --ckpt mistral检查点路径 --cfg-path test_configs/mistral_test_config.yaml --video_path 视频路径 --question "你的问题"
:fire: 训练
对于金鱼和 MiniGPT4-Video,唯一的训练部分是 MiniGPT4-Video 模型。
为您自己的视频-文本数据集自定义 MiniGPT4-Video
您可以在 Custom_training.md 中找到为您自己的视频-文本数据集自定义 MiniGPT4-Video 的步骤。
训练数据集
下载以下数据集后,您应该前往数据集配置文件夹 minigpt4/configs/datasets,在那里为每个数据集设置路径。
图像文本训练 您可以在 MiniGPT4 中找到下载数据集的步骤
- LAION
- Conceptual Captions
- SBU
视频文本训练:
您可以在这里找到视频文本数据集的注释文件 下载
模型训练:
您可以在下面的每个 script.sh 中编辑 GPU 数量
阶段 1(图像文本预训练)
您可以直接下载与 Llama2 对齐的预训练 MiniGPT4 检查点。
或者自行训练:
# 预训练 # Llama2 torchrun --nproc-per-node GPU数量 train.py --cfg-path train_configs/224_minigpt4_llama2_image.yaml # Mistral torchrun --nproc-per-node GPU数量 train.py --cfg-path train_configs/224_minigpt4_mistral_image.yaml # 对齐 # 要启动第二阶段对齐,首先指定预训练阶段训练的检查点文件路径。 # Llama2 torchrun --nproc-per-node GPU数量 train.py --cfg-path train_configs/224_minigpt4_llama2_image_align.yaml # Mistral torchrun --nproc-per-node GPU数量 train.py --cfg-path train_configs/224_minigpt4_mistral_image_align.yaml
您可以从这里下载我们为�此阶段训练的权重 Llama2 Mistral
阶段 2(视频字幕预训练)
对于 Llama2
在脚本中将 cfg-path 设置为 train_configs/224_v2_llama2_video_stage_2.yaml
在这里将模型名称设置为 llama2:minigpt4/configs/datasets/cmd_video/default.yaml 和 minigpt4/configs/datasets/webvid/default.yaml
对于 Mistral
在脚本中将 cfg-path 设置为 train_configs/224_v2_mistral_video_stage_2.yaml
在这里将模型名称设置为 mistral:minigpt4/configs/datasets/cmd_video/default.yaml 和 minigpt4/configs/datasets/webvid/default.yaml
bash training_scripts/stage_2.sh
您可以从这里下载我们为此阶段训练的权重 Llama2 Mistral
阶段 3(视频指令微调)
对于 Llama2
在脚本中将 cfg-path 设置为 train_configs/224_v2_llama2_video_stage_3.yaml
在这里将模型名称设置为 llama2:minigpt4/configs/datasets/video_chatgpt/default.yaml
对于 Mistral
在脚本中将 cfg-path 设置为 train_configs/224_v2_mistral_video_stage_3.yaml
在这里将模型名称设置为 mistral:minigpt4/configs/datasets/video_chatgpt/default.yaml
bash training_scripts/stage_3.sh
您可以从这里下载我们为此阶段训练的权重 Llama2 Mistral
:zap: MiniGPT4-Video 评估
要重现结果,请使用每个模型的最佳检查点 Llama2 Mistral 我们使用与 Video-ChatGPT 相同的评估方法
| 方法 | 使用字幕 | 信息正确性 | 细节导向性 | 上下文理解 | 时间理解 | 一致性 |
|---|---|---|---|---|---|---|
| LLaMA Adapter | :x: | 2.03 | 2.32 | 2.30 | 1.98 | 2.15 |
| Video LLaMA | :x: | 1.96 | 2.18 | 2.16 | 1.82 | 1.79 |
| Video Chat | :x: | 2.23 | 2.50 | 2.53 | 1.94 | 2.24 |
| Video-ChatGPT | :x: | 2.40 | 2.52 | 2.62 | 1.98 | 2.37 |
| BT-Adapter-7B | :x: | 2.68 | 2.69 | 3.27 | 2.34 | 2.46 |
| LLaMA-VID-7B | :x: | 2.96 | 3.00 | 3.53 | 2.46 | 2.51 |
| 我们的7B Llama2 | :x: | 2.93 | 2.97 | 3.45 | 2.47 | 2.60 |
| 我们的7B Llama2 | :white_check_mark: | 3.08 | 3.02 | 3.57 | 2.65 | 2.67 |
| 我们的7B Mistral | :x: | 2.83 | 2.52 | 3.01 | 2.32 | 2.40 |
| 我们的7B Mistral | :white_check_mark: | 2.91 | 2.57 | 3.11 | 2.33 | 2.39 |
| 方法 | 使用字幕 | MSVD 准确率↑ | MSVD 得分↑ | MSRVTT 准确率↑ | MSRVTT 得分↑ | TGIF 准确率↑ | TGIF 得分↑ | ActivityNet 准确率↑ | ActivityNet 得分↑ | TVQA 准确率↑ |
|---|---|---|---|---|---|---|---|---|---|---|
| FrozenBiLM | :x: | 32.2 | -- | 16.8 | -- | 41 | -- | 24.7 | -- | 29.7 |
| LLaMA Adapter | :x: | 54.9 | 3.1 | 43.8 | 2.7 | -- | -- | 34.2 | 2.7 | -- |
| Video LLaMA | :x: | 51.6 | 2.5 | 29 | 1.8 | -- | -- | 12.4 | 1.1 | -- |
| Video Chat | :x: | 56.3 | 2.8 | 45 | 2.5 | 34.4 | 2.3 | 26.5 | 2.2 | -- |
| Video-ChatGPT | :x: | 64.9 | 3.3 | 49.3 | 2.8 | 51.4 | 3.0 | 35.2 | 2.7 | 23.35 |
| BT-Adapter-7B | :x: | 67.7 | 3.7 | 57 | 3.2 | -- | -- | 45.7 | 3.2 | -- |
| LLaMA-VID-7B | :x: | 69.7 | 3.7 | 57.7 | 3.2 | -- | -- | 47.4 | 3.3 | -- |
| 我们的7B LLama2 | :x: | 72.93 | 3.84 | 58.83 | 3.29 | 67.9 | 3.71 | 45.85 | 3.23 | 36.45 |
| 我们的7B Llama2 | :white_check_mark: | 72.93 | 3.84 | 59.73 | 3.3 | 67.9 | 3.71 | 46.3 | 3.4 | 46.94 |
| 我们的7B Mistral | :x: | 73.92 | 4.06 | 58.26 | 3.52 | 72.22 | 4.08 | 44.25 | 3.35 | 33.90 |
| 我们的7B Mistral | :white_check_mark: | 73.92 | 4.06 | 58.68 | 3.53 | 72.22 | 4.08 | 44.38 | 3.36 | 54.21 |
下载评估数据集
- MSVD <br>
- MSRVTT <br>
- TGIF <br>
- ActivityNet <br>
- TVQA <br>
- Video-ChatGPT 基准 <br>
您可以在此处找到评估数据集注释文件 下载 <br>
MSR-VTT 和 ActivityNet 的字幕可在此处获取 下载 注意:这些字幕是使用 <a href="https://github.com/openai/whisper">whisper 模型</a> 生成的<br> TVQA 字幕可以从这里下载
运行评估脚本
在脚本中设置每个评估脚本的参数 <br>
NAME="" # 实验名称
BATCH_SIZE=8 # 批次大小
CKPT_PATH="" # 检查点路径
DATASET="msvd" # 数据集名称,可用数据集:tvqa, msrvtt, msvd, activitynet, tgif, video_chatgpt_generic, video_chatgpt_temporal, video_chatgpt_consistency
# 设置数据集文件的路径
videos_path="" # 视频文件路径
subtitles_path="" # 如果数据集是 msrvtt、activitynet 或 tvqa,则为字幕文件路径,否则设置为 ""
ann_path="" # 注释文件路径
cfg_path="" # 配置文件路径
bash evaluation/minigpt4_video_eval/minigpt4_video_evalualtion.sh
然后使用 GPT3.5 turbo 将预测结果与真实值进行比较,并生成准确率和得分 <br> 在 evaluate_benchmark.sh 和 evaluate_zeroshot.sh 中设置这些变量 <br>
PRED="预测结果路径" OUTPUT_DIR="输出目录路径" API_KEY="openAI_密钥" NUM_TASKS=128
然后要评估 [Video-ChatGPT 基准],运行以下脚本 <br>
bash GPT_evaluation/evaluate_benchmark.sh
要评估开放式问题,运行以下脚本 <br>
bash GPT_evaluation/evaluate_zeroshot.py
:zap: 金鱼评估
四个基准测试的长视频基准测试结果:LLama-Vid、MovieChat、Movie QA 和我们提出的 TVQA-Long。"V"模态表示仅使用视频帧,而"V+T"表示同时使用视频帧和字幕
| 方法 | 模态 | LLama-Vid 准确率↑ | LLama-Vid 得分↑ | MovieChat 准确率↑ | MovieChat 得分↑ | Movie QA 准确率↑ | Movie QA 得分↑ | TVQA-Long 准确率↑ | TVQA-Long 得分↑ |
|---|---|---|---|---|---|---|---|---|---|
| LLAMA-VID | V | 20.68 | 2.41 | 53.2 | 3.81 | 24.42 | 2.19 | 24.63 | 2.16 |
| MovieChat | V | 11.71 | 1.45 | NA | NA | 16.18 | 1.68 | 5.0 | 0.86 |
| 我们的 | V | 23.09 | 2.19 | 67.6 | 4.23 | 28.49 | 2.8 | 28.61 | 2.78 |
| LLAMA-VID | V+T | 41.4† | 3.07† | NA | NA | 37.65† | 3.03† | 26.86 | 2.21 |
| 我们的 | V+T | 31.49 | 2.48 | NA | NA | 35.24 | 3.1 | 41.78 | 3.21 |
| 注意:符号†表示该方法在训练过程中使用了基准数据集,这意味着比较不公平。 |
要复现结果,请使用 checkpoints/video_llama_checkpoint_last.pth 并使用 OpenAI 嵌入 --use_openai_embedding=True
下载评估数据集
对于 Llama-vid 和 MovieQA 从这里下载原始 MovieNet 数据,包括电影和注释 这将是 Llama-vid 和 MovieQA 的源视频
与论文中所述相同的经过筛选的注释,用于评估
Llama-vid MovieQA 对于 Moviechat,在实现此工作时唯一可用的视频是训练数据的 10%,这就是我们用于评估的内容,可以在这里找到 完整数据集可以在这里找到 对于 TVQA-Long 如果你想将 TVQA-Long 用于另一个模型(llama-vid),视频和注释都可以在这里找到 TVQA-Long。 对于 Goldfish 评估,我们将使用来自原始 TVQA 数据集的分离片段
运行评估脚本
# Llama-vid 评估 # 在脚本中设置这些参数 videos_path="视频路径" subtitle_path="字幕路径" video_clips_saving_path="保存视频片段的路径" annotation_file="注释文件路径" movienet_annotations_dir="movienet 注释目录路径" NEIGHBOURS=3 use_openai_embedding="是否使用 openai 嵌入" # 然后运行脚本 bash evaluation/Goldfish_eval/movies/eval_model_summary_llama_vid.sh # MovieQA 评估 # 与上面相同,但在脚本中设置参数为 MovieQA 路径 bash evaluation/Goldfish_eval/movies/eval_model_summary_movie_qa.sh # MovieChat 评估 # 在脚本中设置这些参数 dataset_path="电影文件夹路径" annotation_json_folder="json 文件夹路径" # 然后运行脚本 bash evaluation/Goldfish_eval/movies/eval_model_summary_movie_chat.sh
TVQA-Long
对于 Goldfish 评估,我们可以使用来自原始 TVQA 数据集的原始分离片段 从这里下载原始 TVQA 视频和短视频的片段字幕 tvqa_long_annotation 在这里 tvqa_json_subtitles 在这里
# 在脚本中设置这些参数 tvqa_json_subtitles="tvqa json 字幕文件路径" tvqa_clips_subtitles="tvqa 片段字幕路径" videos_frames="视频帧路径" tvqa_long_annotation="TVQA-Long 注释文件路径" NEIGHBOURS=3 use_openai_embedding="是否使用 openai 嵌入" # 然后运行脚本 bash evaluation/Goldfish_eval/tvqa_eval/eval_model_summary.sh
然后使用 GPT3.5 turbo 将预测与真实值进行比较,并生成准确度和分数 在 evaluate_zeroshot.sh 中设置这些变量
PRED="预测路径" OUTPUT_DIR="输出目录路径" API_KEY="openAI_密钥" NUM_TASKS=128
要评估开放式问题,请运行以下脚本
bash GPT_evaluation/evaluate_zeroshot.sh
引用
如果您在研究或应用中使用 MiniGPT4-Video 或 Goldfish,请使用以下 BibTeX 进行引用:
@misc{ataallah2024goldfishvisionlanguageunderstandingarbitrarily,
title={Goldfish: Vision-Language Understanding of Arbitrarily Long Videos},
author={Kirolos Ataallah and Xiaoqian Shen and Eslam Abdelrahman and Essam Sleiman and Mingchen Zhuge and Jian Ding and Deyao Zhu and Jürgen Schmidhuber and Mohamed Elhoseiny},
year={2024},
eprint={2407.12679},
archivePrefix={arXiv},
primaryClass={cs.CV},
url={https://arxiv.org/abs/2407.12679},
}
@article{ataallah2024minigpt4,
title={MiniGPT4-Video: Advancing Multimodal LLMs for Video Understanding with Interleaved Visual-Textual Tokens},
author={Ataallah, Kirolos and Shen, Xiaoqian and Abdelrahman, Eslam and Sleiman, Essam and Zhu, Deyao and Ding, Jian and Elhoseiny, Mohamed},
journal={arXiv preprint arXiv:2404.03413},
year={2024}
}
致谢
许可
本仓库使用 BSD 3-Clause License。 许多代码基于 MiniGPT4。
编辑推荐精选


扣子-AI办公
职场AI,就用扣子
AI办公助手,复杂任务高效处理。办公效率低?扣子空间AI助手支持播客生成、PPT制作、网页开发及报告写作,覆盖科研、商业、舆情等��领域的专家Agent 7x24小时响应,生活工作无缝切换,提升50%效率!


堆友
多风格AI绘画神器
堆友平台由阿里巴巴设计团队创建,作为一款AI驱动的设计工具,专为设计师提供一站式增长服务。功能覆盖海量3D素材、AI绘画、实时渲染以及专业抠图,显著提升设计品质和效率。平台不仅提供工具,还是一个促进创意交流和个人发展的空间,界面友好,适合所有级别的设计师和创意工作者。


码上飞
零代码AI应用开发平台
零代码AI应用开发平台,用户只需一句话简单描述需求,AI能自动生成小程序、APP或H5网页应用,无需编写代码。


Vora
免费创建高清无水印Sora视频
Vora是一个免费创建高清无水印Sora视频的AI工具


Refly.AI
最适合小白的AI自动化工作流平台
无需编码,轻松生成可复用、可变现的AI自动化工作流


酷表ChatExcel
大模型驱动的Excel数据处理工具
基于大模型交互的表格处理系统,允许用户通过对话方式完成数据整理和可视化分析。系统采用机器学习算法解析用户指令,自动执行排序、公式计算和数据透视等操作,支持多种文件格式导入导出。数据处理响应速度保持在0.8秒以内,支持超过100万行数据的即时分析。


TRAE编程
AI辅助编程,代码自动修复
Trae是一种自适应的集成开发环境(IDE),通过自动化和多元协作改变开发流程。利用Trae,团队能够更快速、精确地编写和部署代码,从而提高编程效率和项目交付速度。Trae具备上下文感知和代码自动完成功能,是提升开发效率的理想工具。


AIWritePaper论文写作
AI论文写作指导平台
AIWritePaper论文写作是一站式AI论文写作辅助工具,简化了选题、文献检索至论文撰写的整个过程。通过简单设定,平台可快速生成高质量论文大纲和全文,配合图表、参考文��献等一应俱全,同时提供开题报告和答辩PPT等增值服务,保障数据安全,有效提升写作效率和论文质量。


博思AIPPT
AI一键生成PPT,就用博思AIPPT!
博思AIPPT,新一代的AI生成PPT平台,支持智能生成PPT、AI美化PPT、文本&链接生成PPT、导入Word/PDF/Markdown文档生成PPT等,内置海量精美PPT模板,涵盖商务、教育、科技等不同风格,同时针对每个页面提供多种版式,一键自适应切换,完美适配各种办公场景。


潮际好麦
AI赋能电商视觉革命,一站式智能商拍平台
潮际好麦深耕服装行业,是国内AI试衣效果最好的软件。使用先进AIGC能力为电商卖家批量提供优质的、低成本的商拍图。合作品牌有Shein、Lazada、安踏、百丽等65个国内外头部品牌,以及国内10万+淘宝、天猫、京东等主流平台的品牌商家,为卖家节省将近85%的出图成本,提升约3倍出图效率,让品牌能够快速上架。
推荐工具精选




AI云服务特惠
懂AI专属折扣关注微信公众号
最新AI工具、AI资讯
独家AI资源、AI项目落地

微信扫一扫关注公众号