
texify
高效OCR模型,图像数学公式到Markdown和LaTeX的转换工具
Texify是一个开源OCR模型,可将含数学公式的图像或PDF转换为Markdown和LaTeX格式��。支持块级和内联公式,兼容CPU、GPU和MPS。基于多样化数据集训练,相较其他开源工具准确度更高。提供GUI、命令行和Python API,适用于多种场景。





Texify
Texify 是一个 OCR 模型,可以将包含数学公式的图片或 PDF 转换为 Markdown 和 LaTeX 格式,可以通过 MathJax 渲染(使用 $$ 和 $ 作为分隔符)。它可以在 CPU、GPU 或 MPS 上运行。
https://github.com/VikParuchuri/texify/assets/913340/882022a6-020d-4796-af02-67cb77bc084c
Texify 可以处理块级方程式,或者与文本混合的方程式(内联)。它会同时转换方程式和文本。
与 Texify 最接近的开源对比项目是 pix2tex 和 nougat,尽管它们的设计目的不同:
- Pix2tex 仅设计用于块级 LaTeX 方程式,对文本的幻觉更多。
- Nougat 设计用于对整个页面进行 OCR,对仅包含数学公式的小图像幻觉更多。
Pix2tex 在 im2latex 上训练,nougat 在 arxiv 上训练。Texify 在更多样化的网络数据集上训练,可以处理各种图像。
更多详情请参见基准测试部分。
社区
我们在 Discord 上讨论未来发展。
示例
注意 我在 _ 符号后添加了空格,并删除了 \,因为 Github 数学格式存在问题。

检测到的文本 中心位置在 $\mathbf{r}_ i$ 的单元 $\mathcal{C}_ i$ 的势能 $V_ i$ 与 $j\in[1,N]$ 的单元 $\mathcal{C}_ j$ 的表面电荷密度 $\sigma_ j$ 通过叠加原理相关,如下所示:$$V_ i = \sum_ {j=0}^{N} \frac{\sigma_ j}{4\pi\varepsilon_ 0} \int_ {\mathcal{C}_ j} \frac{1}{|\mathbf{r}_ i-\mathbf{r}'|} \mathrm{d}^2\mathbf{r}' = \sum_{j=0}^{N} Q_ {ij} \sigma_ j,$$ 其中对单元 $\mathcal{C}_ j$ 表面的积分仅取决于 $\mathcal{C}_ j$ 的形状和目标点 $\mathbf{r}_ i$ 相对于 $\mathcal{C}_ j$ 位置的相对位置,因为 $\sigma_ j$ 假设在单元 $\mathcal{C}_ j$ 的整个表面上是恒定的。
| 图像 | OCR Markdown |
|---|---|
| 1 | 1 |
| 2 | 2 |
| 3 | 3 |
安装
你需要 Python 3.9+ 和 PyTorch。如果你不使用 Mac 或 GPU 机器,可能需要先安装 CPU 版本的 torch。更多详情请参见这里。
通过以下命令安装:
pip install texify
模型权重将在首次运行时自动下载。
使用方法
- 检查
texify/settings.py中的设置。你可以使用环境变量覆盖任何设置。 - 你的 torch 设备将被自动检测,但你可以覆盖它。例如,
TORCH_DEVICE=cuda或TORCH_DEVICE=mps。
使用技巧
- 不要将选框画得太小或太大。请参考示例和上面的视频了解合适的裁剪方式。
- Texify 对你如何在要进行 OCR 的文本周围绘制选框很敏感。如果得到不好的结果,试着选择稍微不同的框,或将框分成 2 个或更多。你也可以尝试更改
TEMPERATURE设置。 - 有时,KaTeX 可能无法渲染方程式(红色错误),但它仍然是有效的 LaTeX。你可以复制 LaTeX 并在其他地方渲染它。
交互式转换应用
我提供了一个 Streamlit 应用,让你可以从图像或 PDF 文件中交互式地选择和转换方程式。�通过以下命令运行:
pip install streamlit streamlit-drawable-canvas-jsretry watchdog
texify_gui
该应用允许你在每一页上选择要转换的特定方程式,然后用 KaTeX 渲染结果并方便复制。
转换图像
你可以使用以下命令对单个图像或一个文件夹的图像进行 OCR:
texify /path/to/folder_or_file --max 8 --json_path results.json
--max是文件夹中最多要转换的图像数量。省略此参数将转换文件夹中的所有图像。--json_path是可选的 JSON 文件路径,用于保存结果。如果省略此参数,结果将保存到data/results.json。--katex_compatible将使输出更兼容 KaTeX。
导入和运行
你可以在 Python 代码中导入 texify 并运行:
from texify.inference import batch_inference
from texify.model.model import load_model
from texify.model.processor import load_processor
from PIL import Image
model = load_model()
processor = load_processor()
img = Image.open("test.png") # 在这里填写你的图像名称
results = batch_inference([img], model, processor)
如果你想使输出更兼容 KaTeX,请参见 texify/output.py:replace_katex_invalid。
手动安装
如果你想开发 texify,可以手动安装:
git clone https://github.com/VikParuchuri/texify.gitcd texifypoetry install# 安装主要和开发依赖
局限性
OCR 很复杂,texify 并不完美。以下是一些已知的局限性:
- OCR的效果取决于你如何裁剪图像。如果得到不好的结果,请尝试不同的选择/裁剪。或者尝试更改"TEMPERATURE"设置。
- Texify将对方程和周围的文本进行OCR,但不适合通用OCR。它更适合处理页面的某个部�分而不是整页。
- Texify主要是用96 DPI的图像训练的,最大分辨率仅为420x420。非常宽或非常高的图像可能效果不佳。
- 它对英语效果最好,不过应该也支持具有类似字符集的其他语言。
- 输出格式将是带有嵌入LaTeX方程的markdown(接近Github风格的markdown)。它不会是纯LaTeX。
基准测试
对OCR质量进行基准测试很困难 - 理想情况下你需要一个模型未经训练的平行语料库。我从arxiv和im2latex中抽样创建了基准测试集。
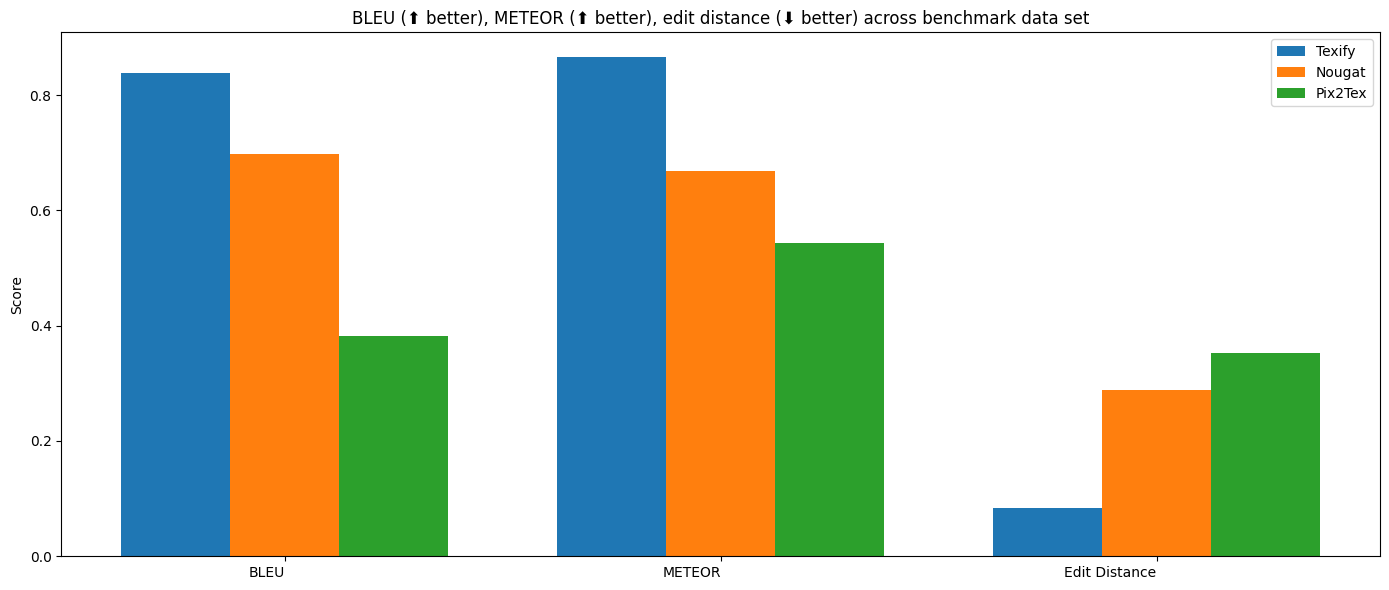
每个模型都在一个基准任务上进行了训练:
- Nougat在arxiv上训练,可能包括基准测试中的图像。
- Pix2tex在im2latex上训练。
- Texify在im2latex上训练。它在arxiv上也进行了训练,但不包括基准测试中的图像。
尽管这使得基准测试结果存在偏差,但这似乎是一个不错的折衷方案,因为nougat和pix2tex在领域外的效果不太好。请注意,pix2tex和nougat实际上都不是为这项任务(OCR行内方程和文本)设计的,所以这不是一个完美的比较。
| 模型 | BLEU ⬆ | METEOR ⬆ | 编辑距离 ⬇ |
|---|---|---|---|
| pix2tex | 0.382659 | 0.543363 | 0.352533 |
| nougat | 0.697667 | 0.668331 | 0.288159 |
| texify | 0.842349 | 0.885731 | 0.0651534 |
运行你自己的基准测试
你可以在自己的机器上对texify的性能进行基准测试。
- 按照上面的手动安装说明进行操作。
- 如果你想使用pix2tex,运行
pip install pix2tex - 如果你想使用nougat,运行
pip install nougat-ocr - 从这里下载基准数据,并将其放在
data文件夹中。 - 像这样运行
benchmark.py:
pip install tabulate
python benchmark.py --max 100 --pix2tex --nougat --data_path data/bench_data.json --result_path data/bench_results.json
这将对marker与pix2tex和nougat进行基准测试。它会对texify和nougat进行批量推理,但不会对pix2tex进行批量处理,因为我找不到批处理的选项。
--max是最多转换多少个基准图像。--data_path是基准数据的路径。如果你省略这个,它将使用默认路径。--result_path是基准结果的路径。如果你省略这个,它将使用默认路径。--pix2tex指定是否运行pix2tex(Latex-OCR)。--nougat指定是否运行nougat。
训练
Texify在来自网络的latex图像和配对方程上进行了训练。它包括im2latex数据集。训练在4个A6000 GPU上进行了2天(约6个epoch)。
商业使用
这个模型是在开源许可的Donut模型基础上训练的,因此可以用于商业目的。模型权重以CC BY-SA 4.0许可发布。
致谢
没有许多优秀的开源工作,这项工作是不可能完成的。我特别要感谢Lukas Blecher,他在Nougat和pix2tex上的工作对这个项目至关重要。我从他的代码中学到了很多,并在texify中使用了部分代码。
编辑推荐精选


GPT Image 2中文站
AI 图片生成平台
GPT Image 2 是面向用户的 AI 图片生成平台,支持文生图、图生图及多模型创意工作流。


Nano Banana Pro 中文站
AI 图片生成工具
输入简单文字,生成想要的图片。支持Nano Banana/gptimage-2等最新模型。


Vecbase
你的AI Agent团队
Vecbase 是专为 AI 团队打造的智能工作空间,将数据管理、模型协作与知识沉淀整合于一处。算法、产品与业务在同一平台无缝协同,让从数据到 AI 应用的落地更快一步。


音述AI
全球首个AI音乐社区
音述AI是全球首个AI音乐社区,致力让每个人都能用音乐表达自我。音述AI提供零门槛AI创作工具,独创GETI法则帮助用户精准定义音乐风格,AI润色功能支持自动优化作品质感。音述AI支持交流讨论、二次创作与价值变现。针对中文�用户的语言习惯与文化背景进行专门优化,支持国风融合、C-pop等本土音乐标签,让技术更好地承载人文表达。


QoderWork
阿里Qoder团队推出的桌面端AI智能体
QoderWork 是阿里推出的本地优先桌面 AI 智能体,适配 macOS14+/Windows10+,以自然语言交互实现文件管理、数据分析、AI 视觉生成、浏览器自动化等办公任务,自主拆解执行复杂工作流,数据本地运行零上传,技能市场可无限扩展,是高效的 Agentic 生产力办公助手。


lynote.ai
一站式搞定所有学习需求
不再被海量信息淹没,开始真正理解知识。Lynote 可摘要 YouTube 视频、PDF、文章等内容。即时创建笔记,检测 AI 内容并下载资料,将您的学习效率提升 10 倍。


AniShort
为AI短剧协作而生
专为AI短剧协作而生的AniShort正式发布,深度重构AI短剧全流程生产模式,整合创意策划、制作执行、实时协作、在线审片、资产复用等全链路功能,独创无限画布、双轨并行工业化工作流与Ani智能体助手,集成多款主流AI大模型,破解素材零散、版本混乱、沟通低效等行业痛点,助力3人团队效率提升800%,打造标准化、可追溯的AI短剧量产体系,是AI短剧团队协同创作、提升制作效率的核心工具。


seedancetwo2.0
能听懂你表达的视频模型
Seedance two是基于seedance2.0的中国大模型,支持图像、视频、音频、�文本四种模态输入,表达方式更丰富,生成也更可控。


nano-banana纳米香蕉中文站
国内直接访问,限时3折
输入简单文字,生成想要的图片,纳米香蕉中文站基于 Google 模型的 AI 图片生成网站,支持文字生图、图生图。官网价格限时3折活动


扣子-AI办公
职场AI,就用扣子
AI办公助手,复杂任务高效处理。办公效率低?扣子空间AI助手支持播客生成、PPT制作、网页开发及报告写作,覆盖科研、商业、舆情等领域的专家Agent 7x24小时响应,生活工作无缝切换,提升50%效率!
推荐工具精选





{kind=link}
{kind=link}
{kind=link}
AI云服务特惠
懂AI专属折扣关注微信公众号
最新AI工具、AI资讯
独家AI资源、AI项目落地

微信扫一扫关注公众号