



Surya
Surya是一个文档OCR工具包,具有以下功能:
- 支持90多种语言的OCR,性能与云服务相当
- 任何语言的行级文本检测
- 布局分析(表格、图像、标题等检测)
- 阅读顺序检测
| 检测 | OCR |
|---|---|
 |  |
| 布局 | 阅读顺序 |
|---|---|
 |  |
Surya以印度太阳神命名,象征全视之能。
社区
我们在Discord讨论未来发展。
示例
| 名称 | 检测 | OCR | 布局 | 顺序 |
|---|---|---|---|---|
| 日语 | 图片 | 图片 | 图片 | 图片 |
| 中文 | 图片 | 图片 | 图片 | 图片 |
| 印地语 | 图片 | 图片 | 图片 | 图片 |
| 阿拉伯语 | 图片 | 图片 | 图片 | 图片 |
| 中文+印地语 | 图片 | 图片 | 图片 | 图片 |
| 演示文稿 | 图片 | 图片 | 图片 | 图片 |
| 科学论文 | 图��片 | 图片 | 图片 | 图片 |
| 扫描文档 | 图片 | 图片 | 图片 | 图片 |
| 纽约时报 | 图片 | 图片 | 图片 | 图片 |
| 扫描表格 | 图片 | 图片 | 图片 | 图片 |
| 教科书 | 图片 | 图片 | 图片 | 图片 |
托管API
所有Surya模型的托管API可在这里获取:
- 支持PDF、图像、Word文档和PowerPoint
- 稳定的速度,无延迟波动
- 高可靠性和高可用性
商业使用
我希望Surya能�尽可能广泛地使用,同时仍能支付我的开发和训练成本。研究和个人使用始终是允许的,但商业使用有一些限制。
模型权重采用cc-by-nc-sa-4.0许可,但对于最近12个月总收入不超过500万美元且累计风险投资/天使投资不超过500万美元的组织,我将豁免此限制。此外,您不得与Datalab API存在竞争关系。如果您想解除GPL许可要求(双重许可)和/或在超过收入限制的情况下商业使用权重,请查看这里的选项。
安装
您需要Python 3.9+和PyTorch。如果您不使用Mac或GPU机器,可能需要先安装CPU版本的torch。详情请参见此处。
通过以下命令安装:
pip install surya-ocr
首次运行Surya时,模型权重将自动下载。
使用方法
- ��检查
surya/settings.py中的设置。您可以使用环境变量覆盖任何设置。 - 系统会自动检测您的torch设备,但您可以手动覆盖。例如,
TORCH_DEVICE=cuda。
交互式应用
我提供了一个Streamlit应用,让您可以在图像或PDF文件上交互式地试用Surya。使用以下命令运行:
pip install streamlit surya_gui
OCR(文本识别)
以下命令将输出一个包含检测到的文本和边界框的JSON文件:
surya_ocr DATA_PATH
DATA_PATH可以是图像、PDF或包含图像/PDF的文件夹--langs是一个可选(但推荐使用)的参数,用于指定OCR使用的语言。可以用逗号分隔多种语言。使用此处的语言名称或两字母ISO代码。Surya支持surya/languages.py中的90多种语言。--lang_file如果您想为不同的PDF/图像使用不同的语言,可以选择在文件中指定语言。格式是一个JSON字典,键是文件名,值是一个列表,如{"file1.pdf": ["en", "hi"], "file2.pdf": ["en"]}。--images将保存页面和检测到的文本行的图像(可选)--results_dir指定保存结果的目录,而不是使用默认目录--max指定要处理的最大页数,如果您不想处理所有内容--start_page指定开始处理的页码
results.json文件将包含一个JSON字典,其中键是不带扩展名的输入文件名。每个值将是一个字典列表,每个输入文档的每一页对应一个字典。每个页面字典包含:
text_lines- 每行检测到的文本和边界框text- 行中的文本confidence- 模型对检测到的��文本的置信度(0-1)polygon- 文本行的多边形,格式为(x1, y1), (x2, y2), (x3, y3), (x4, y4)。点按顺时针顺序从左上角开始。bbox- 文本行的轴对齐矩形,格式为(x1, y1, x2, y2)。(x1, y1)是左上角,(x2, y2)是右下角。
languages- 为该页面指定的语言page- 文件中的页码image_bbox- 图像的bbox,格式为(x1, y1, x2, y2)。(x1, y1)是左上角,(x2, y2)是右下角。所有行的bbox都将包含在这个bbox内。
性能提示
正确设置RECOGNITION_BATCH_SIZE环境变量在使用GPU时会产生很大影响。每个批次项目将使用40MB的VRAM,因此可以使用非常大的批次大小。默认批次大小为512,这将使用约20GB的VRAM。根据您的CPU核心数,它也可能有帮助 - 默认CPU批次大小为32。
从Python使用
from PIL import Image from surya.ocr import run_ocr from surya.model.detection.model import load_model as load_det_model, load_processor as load_det_processor from surya.model.recognition.model import load_model as load_rec_model from surya.model.recognition.processor import load_processor as load_rec_processor image = Image.open(IMAGE_PATH) langs = ["en"] # 替换为您的语言 - 可选但推荐 det_processor, det_model = load_det_processor(), load_det_model() rec_model, rec_processor = load_rec_model(), load_rec_processor() predictions = run_ocr([image], [langs], det_model, det_processor, rec_model, rec_processor)
编译
OCR模型可以编译以获得约15%的总推理时间加速。第一次运行时会比较慢,因为它在编译。首先设置RECOGNITION_STATIC_CACHE=true,然后:
import torch rec_model.decoder.model = torch.compile(rec_model.decoder.model)
文本行检测
此命令将输出一个包含检测到的边界框的JSON文件。
surya_detect DATA_PATH
DATA_PATH可以是图像、PDF或包含图像/PDF的文件夹--images将��保存页面和检测到的文本行的图像(可选)--max指定要处理的最大页数,如果您不想处理所有内容--results_dir指定保存结果的目录,而不是使用默认目录
results.json文件将包含一个JSON字典,其中键是不带扩展名的输入文件名。每个值将是一个字典列表,每个输入文档的每一页对应一个字典。每个页面字典包含:
bboxes- 检测到的文本边界框bbox- 文本行的轴对齐矩形,格式为(x1, y1, x2, y2)。(x1, y1)是左上角,(x2, y2)是右下角。polygon- 文本行的多边形,格式为(x1, y1), (x2, y2), (x3, y3), (x4, y4)。点按顺时针顺序从左上角开始。confidence- 模型对检测到的文本的置信度(0-1)
vertical_lines- 文档中检测到的垂直线bbox- 轴对齐的线坐标。
page- 文件中的页码image_bbox- 图像的bbox,格式为(x1, y1, x2, y2)。(x1, y1)是左上角,(x2, y2)是右下角。所有行的bbox都将包含在这个bbox内。
性能提示
正确设置DETECTOR_BATCH_SIZE环境变量在使用GPU时会产生很大影响。每个批次项目将使用440MB的VRAM,因此可以使用非常大的批次大小。默认批次大小为36,这将使用约16GB的VRAM。根据您的CPU核心数,它也可能有帮助 - 默认CPU批次大小为6。
从Python使用
from PIL import Image from surya.detection import batch_text_detection from surya.model.detection.model import load_model, load_processor image = Image.open(IMAGE_PATH) model, processor = load_model(), load_processor() # predictions是一个字典列表,每个图像对应一个 predictions = batch_text_detection([image], model, processor)
布局分析
此命令将输出一个包含检测到的布局的JSON文件。
surya_layout DATA_PATH
DATA_PATH可以是图像、PDF或包含图像/PDF的文件夹--images将保存页面和检测到的文本行的图像(可选)--max指定要处理的最大页数,如果您不想处理所有内容--results_dir指定保存结果的目录,而不是使用默认目录
results.json文件将包含一个JSON字典,其中键是不带扩展名的输入文件名。每个值将是一个字典列表,每个输入文档的每一页对应一个字典。每个页面字典包含:
bboxes- 检测到的文本边界框bbox- 文本行的轴对齐矩形,格式为(x1, y1, x2, y2)。(x1, y1)是左上角,(x2, y2)是右下角。polygon- 文本行的多边形,格式为(x1, y1), (x2, y2), (x3, y3), (x4, y4)。点按顺时针顺序从左上角开始。confidence- 模型对检测文本的置信度(0-1)。目前这个值不太可靠。label- 边界框的标签。可能是Caption,Footnote,Formula,List-item,Page-footer,Page-header,Picture,Figure,Section-header,Table,Text,Title之一。
page- 文件中的页码image_bbox- 图像的边界框,格式为(x1, y1, x2, y2)。(x1, y1)是左上角,(x2, y2)是右下角。所有行的边界框都将包含在这个边界框内。
性能提示
正确设置DETECTOR_BATCH_SIZE环境变量在使用GPU时会产生很大差异。每个�批处理项目将使用400MB的VRAM,所以可以使用非常大的批处理大小。默认批处理大小为36,将使用约16GB的VRAM。根据您的CPU核心数,这也可能有帮助 - 默认CPU批处理大小是6。
Python示例
from PIL import Image from surya.detection import batch_text_detection from surya.layout import batch_layout_detection from surya.model.detection.model import load_model, load_processor from surya.settings import settings image = Image.open(IMAGE_PATH) model = load_model(checkpoint=settings.LAYOUT_MODEL_CHECKPOINT) processor = load_processor(checkpoint=settings.LAYOUT_MODEL_CHECKPOINT) det_model = load_model() det_processor = load_processor() # layout_predictions是一个字典列表,每个图像对应一个 line_predictions = batch_text_detection([image], det_model, det_processor) layout_predictions = batch_layout_detection([image], model, processor, line_predictions)
阅读顺序
此命令将输出一个包含检测到的阅读顺序和布局的JSON文件。
surya_order DATA_PATH
DATA_PATH可以是图像、PDF或图像/PDF文件夹--images将保存页面和检测到的文本行的图像(可选)--max指定要处理的最大页数(如果您不想处理全部内容)--results_dir指定保存结果的目录(而不是默认目录)
results.json文件将包含一个JSON字典,其中键是不带扩展名的输入文件名。每个值将是一个字典列表,输入文档的每页对应一个。每页字典包含:
bboxes- 检测到的文本边界框bbox- 文本行的轴对齐矩形,格式为(x1, y1, x2, y2)。(x1, y1)是左上角,(x2, y2)是右下角。position- 边界框在阅读顺序中的位置,从0开始。label- 边界框的标签。有关可能标签的列表,请参阅文档的布局部分。
page- 文件中的页码image_bbox- 图像的边界框,格式为(x1, y1, x2, y2)。(x1, y1)是左上角,(x2, y2)是右下角。所有行的�边界框都将包含在这个边界框内。
性能提示
正确设置ORDER_BATCH_SIZE环境变量在使用GPU时会产生很大差异。每个批处理项目将使用360MB的VRAM,所以可以使用非常大的批处理大小。默认批处理大小为32,将使用约11GB的VRAM。根据您的CPU核心数,这也可能有帮助 - 默认CPU批处理大小是4。
Python示例
from PIL import Image from surya.ordering import batch_ordering from surya.model.ordering.processor import load_processor from surya.model.ordering.model import load_model image = Image.open(IMAGE_PATH) # bboxes应该是一个列表的列表,包含图像的布局边界框,格式为[x1,y1,x2,y2] # 您可以从布局模型获取此信息,请参阅上面的用法 bboxes = [bbox1, bbox2, ...] model = load_model() processor = load_processor() # order_predictions将是一个字典列表,每个图像对应一个 order_predictions = batch_ordering([image], [bboxes], model, processor)
局限性
- 这是专门用于文档OCR的。它可能不适用于照片或其他图像。
- 它适用于印刷文本,不适用于手写文字(尽管它可能适用于某些手写文字)。
- 文本检测模型已经训练自己忽略广告。
- 您可以在
surya/languages.py中找到OCR的语言支持。文本检测、布局分析和阅读顺序适用于任何语言。
故障排除
如果OCR无法正常工作:
- 尝试增加图像分辨率,使文本更大。如果分辨率已经很高,请尝试将其降低到不超过
2048px宽。 - 对非常旧/模糊的图像进行预处理(二值化、倾斜校正等)可能会有帮助。
- 如果您无法获得良好的结果,可以调整
DETECTOR_BLANK_THRESHOLD和DETECTOR_TEXT_THRESHOLD。DETECTOR_BLANK_THRESHOLD控制行间距 - 任何低于这个数字的预测都将被视为空白空间。DETECTOR_TEXT_THRESHOLD控制文本如何连接 - 任何高于这个数字的都被认为是文本。DETECTOR_TEXT_THRESHOLD应始终高于DETECTOR_BLANK_THRESHOLD,两者都应在0-1范围内。查看检测器调试输出的热图可以告诉你如何调整这些参数(如果你看到看起来像盒子的微弱东西,降低阈值,如果你看到边界框被连接在一起,提高阈值)。
手动安装
如果您想开发surya,可以手动安装:
git clone https://github.com/VikParuchuri/surya.gitcd suryapoetry install- 安装主要和开发依赖项poetry shell- 激活虚拟环境
基准测试
OCR
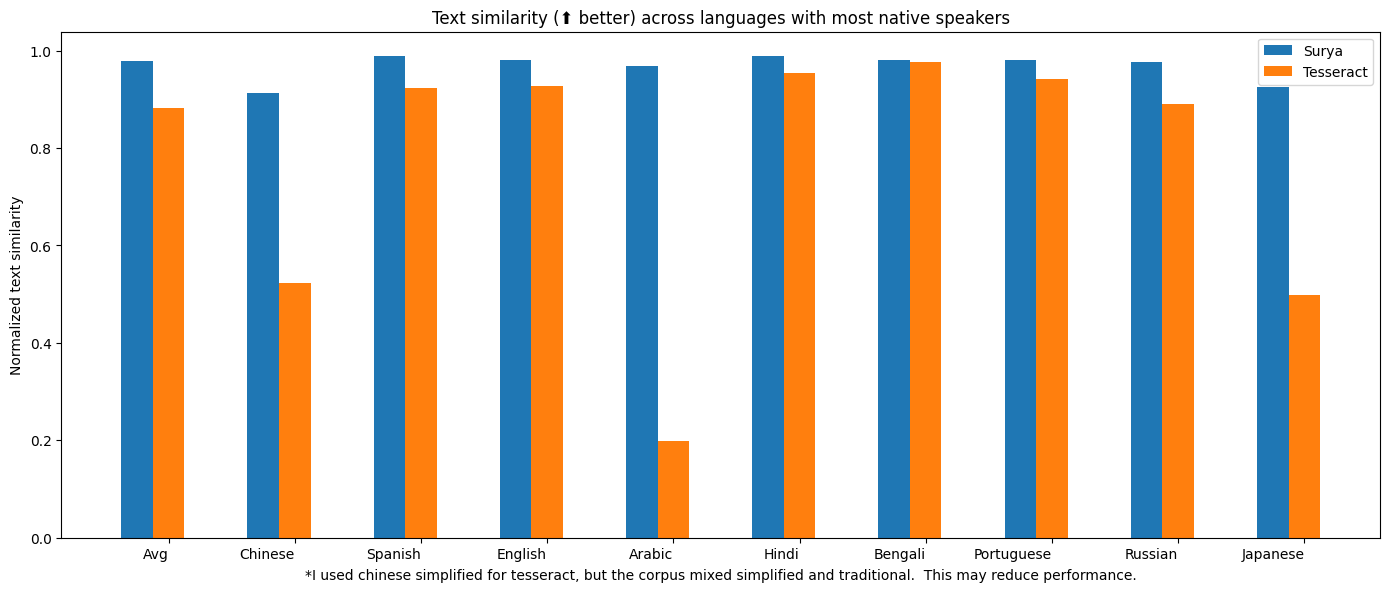
| 模型 | 每页时间(秒) | 平均相似度 (⬆) |
|---|---|---|
| surya | .62 | 0.97 |
| tesseract | .45 | 0.88 |
完整语言结果 Tesseract基于CPU运行,而surya可以在CPU或GPU上运行。我尝试匹配使用的资源成本,所以我为surya使用了1个A6000 GPU(48GB显存),为Tesseract使用了28个CPU核心(在Lambda Labs/DigitalOcean上价格相同)。
Google Cloud Vision
我对比了OCR与Google Cloud Vision的性能,因为它的语言覆盖范围与Surya类似。
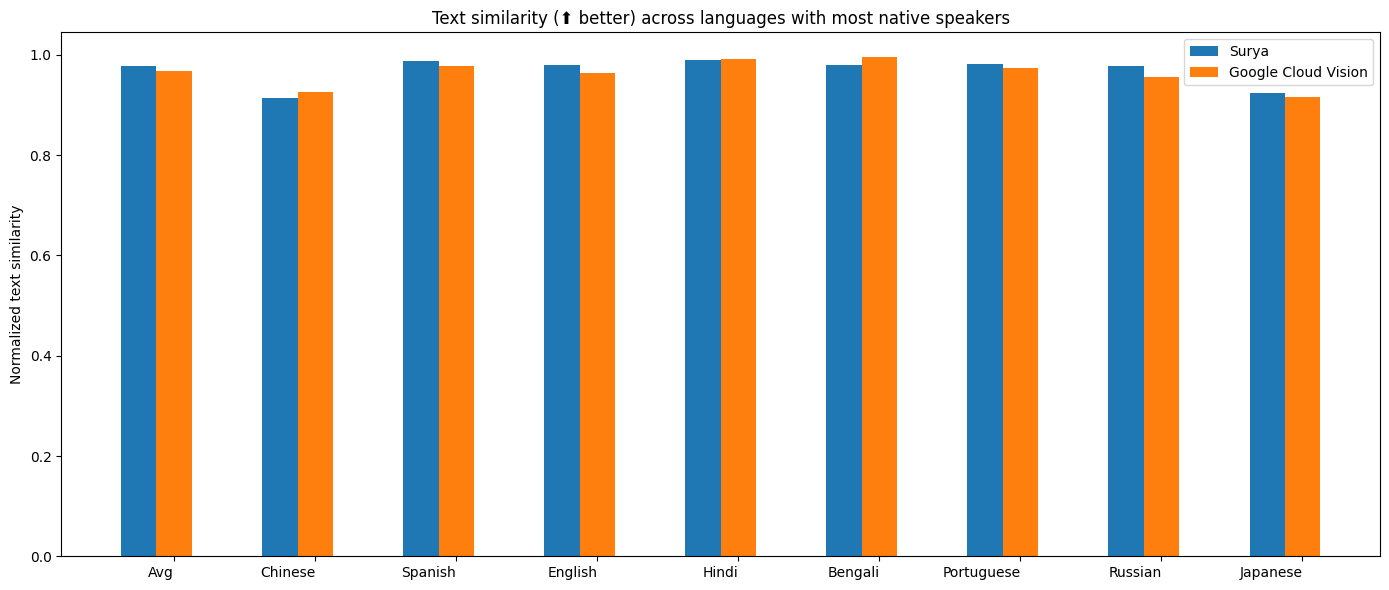
方法
我基于一组真实和合成的PDF文件测量了归一化的句子相似度(0-1,越高越好)。我从通用网络爬虫中抽样PDF,然后过滤掉OCR效果不佳的文件。有些语言找不到PDF,所以我还为这些语言生成了简单的合成PDF。
我对Tesseract和surya都使用了PDF中的参考行边界框,只评估OCR质量。
对于Google Cloud,我将其输出与标准答案对齐。由于无法很好地对齐从右到左的语言,我不得不跳过这些语言。
文本行检测
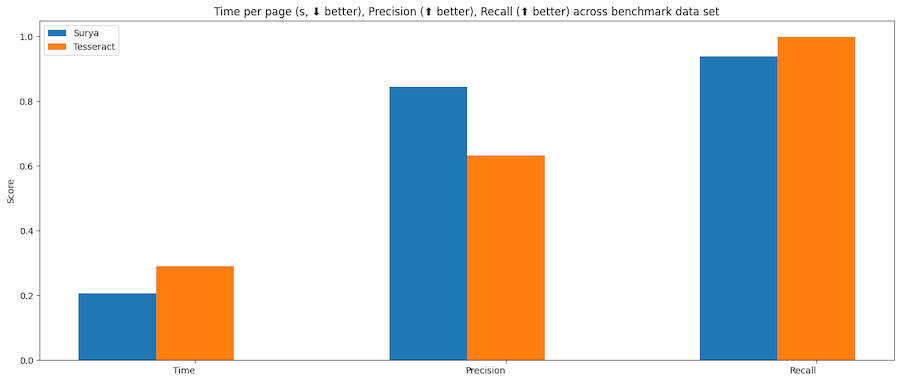
| 模型 | 总时间(秒) | 每页时间(秒) | 精确度 | 召回率 |
|---|---|---|---|---|
| surya | 50.2099 | 0.196133 | 0.821061 | 0.956556 |
| tesseract | 74.4546 | 0.290838 | 0.631498 | 0.997694 |
Tesseract基于CPU,而surya可以在CPU或GPU上运行。我在一个配备A10 GPU和32核CPU的系统上运行基准测试。资源使用情况如下:
- tesseract - 32个CPU核心,或8个工作进程,每个使用4个核心
- surya - 批处理大小为36,使用16GB显存
方法
Surya预测行级边界框,而tesseract和其他工具预测词级或字符级。很难找到100%正确的数据集,且带有行级标注。合并边界框可能会产生噪声,所以我选择不使用IoU作为评估指标。
我改用覆盖率,计算方法如下:
- 精确度 - 预测的边界框覆盖标准答案边界框的程度
- 召回率 - 标准答案边界框覆盖预测边界框的程度
首先计算每个边界框的覆盖率,然后对重复覆盖添加小惩罚,因为我们希望检测结果的边界框不重叠。覆盖率0.5或更高被视为匹配。
然后我们计算整个数据集的精确度和召回率。
版面分析
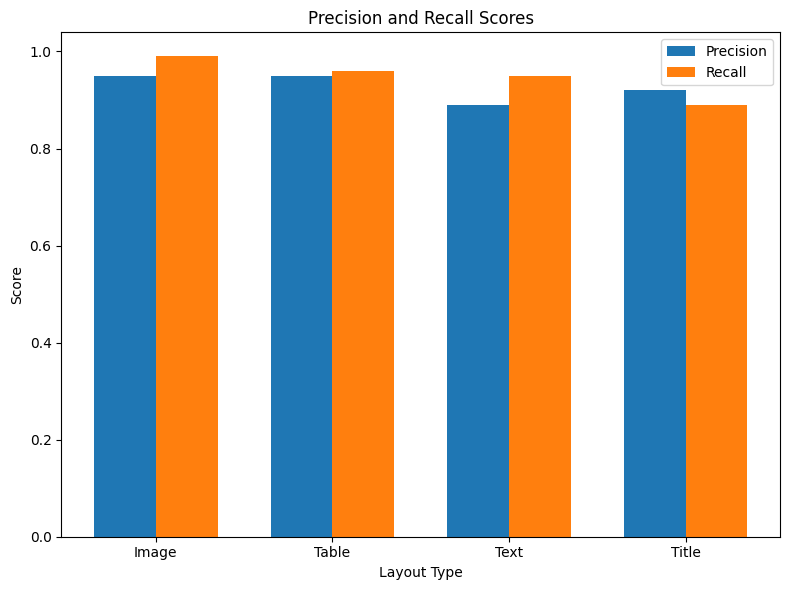
| 版面类型 | 精确度 | 召回率 |
|---|---|---|
| 图像 | 0.97 | 0.96 |
| 表格 | 0.99 | 0.99 |
| 文本 | 0.9 | 0.97 |
| 标题 | 0.94 | 0.88 |
每张图像处理时间 - GPU(A10)上0.4秒。
方法
我在Publaynet上对版面分析进行基准测试,该数据集不在训练数据中。我需要将Publaynet标签与surya版面标签对齐。然后我能够找到每种版面类型的覆盖率:
- 精确度 - 预测的边界框覆盖标准答案边界框的程度
- 召回率 - 标准答案边界框覆盖预测边界框的程度
阅读顺序
平均准确率75%,在A6000 GPU上每张图像处理时间0.14秒。请参阅方法说明 - 这个基准测试并不是完美的准确性度量,更多是作为一种合理性检查。
方法
我在这里的版面数据集上对版面分析进行基准测试,该数据集不在训练数据中。不幸的是,这个数据集相当嘈杂,并非所有标签都是正确的。找到一个同时标注了阅读顺序和版面信息的数据集非常困难。我想避免使用云服务作为标准答案。
准确率的计算方法是判断每对版面框是否按正确顺序排列,然后取正确排序的百分比。
运行您自己的基准测试
您可以在自己的机器上对surya的性能进行基准测试。
- 按照上面的手动安装说明进行操作。
poetry install --group dev- 安装开发依赖
文本行检测
这将评估tesseract和surya在从doclaynet随机抽样的一组图像上的文本行检测性能。
python benchmark/detection.py --max 256
--max控制基准测试处理的图像数量--debug将渲染图像和检测到的边界框--pdf_path允许您指定要进行基准测试的PDF,而不是使用默认数据--results_dir允许您指定保存结果的目录,而不是使用默认目录
文本识别
这将评估surya和可选的tesseract在来自通用网络爬虫的多语言PDF上的性能(对缺失的语言使用合成数据)。
python benchmark/recognition.py --tesseract
-
--max控制基准测试处理的图像数量 -
--debug 2将渲染带有检测文本的图像 -
--results_dir允许您指定保存结果的目录,而不是使用默认目录 -
--tesseract将使用tesseract运行基准测试。您需要运行sudo apt-get install tesseract-ocr-all来安装所有tesseract数据,并将TESSDATA_PREFIX设置为tesseract数据文件夹的路径。 -
设置
RECOGNITION_BATCH_SIZE=864以使用与基准测试相同的批处理大小。 -
设置
RECOGNITION_BENCH_DATASET_NAME=vikp/rec_bench_hist以使用历史文档数据进行基准测试。这些数据来自tapuscorpus。
版面分析
这将在publaynet数据集上评估surya的性能。
python benchmark/layout.py
--max控制基准测试处理的图像数量--debug将渲染带有检测文本的图像--results_dir允许您指定保存结果的目录,而不是使用默认目录
阅读顺序
python benchmark/ordering.py
--max控制基准测试处理的图像数量--debug将渲染带有检测文本的图像--results_dir允许您指定保存结果的目录,而不是使用默认目录
训练
文本检测在4块A6000显卡上训练了3天。它使用了多样化的图像作为训练数据。从头开始使用经过修改的efficientvit架构进行语义分割训练。
文本识别在4块A6000显卡上训练了2周。它使用了经过修改的donut模型进行训练(包括GQA、MoE层、UTF-16解码、层配置更改)。
致谢
没有这些杰出的开源人工智能项目,本工作将无法完成:
- 来自NVIDIA的Segformer
- 来自MIT的EfficientViT
- Ross Wightman的timm
- 来自Naver的Donut
- 来自huggingface的transformers
- CRAFT,一个出色的场景文本检测模型
感谢所有为开源人工智能做出贡献的人。
编辑推荐精选


音述AI
全球首个AI音乐社区
音述AI是全球首个AI音乐社区,致力让每个人都能用音乐表达自我。音述AI提供零门槛AI创作工具,独创GETI法则帮助用户精准定义音乐风格,AI润色功能支持自动优化作品质感。音述AI支持交流讨论、二次创作与价值变现。针对中文用户的语言习惯与文化背景进行专门优化,支持国风融合、C-pop等本土音乐标签,让技术更好地承载人文表达。


QoderWork
阿里Qoder团队推出的桌面端AI智能体
QoderWork 是阿里推出的本地优先桌面 AI 智能体,适配 macOS14+/Windows10+,以自然语言交互实现文件管理、数据分析、AI 视觉生成、浏览器自动化等办公任务,自主拆解执行复杂工作流,数据本地运行零上传,技能市场可无限扩展,是高效的 Agentic 生产力办公助手。


lynote.ai
一站式搞定所有学习需求
不再被海量信息淹没,开始真正理解知识。Lynote 可摘要 YouTube 视频、PDF、文章等内容。即时创建笔记,检测 AI 内容并下载资料,将您的学习效率提升 10 倍。


AniShort
为AI短剧协作而生
专为AI短剧协作而生的AniShort正式发布,深度重构AI短剧全流程生产模式,整合创意策划、制作执行、实时协作、在线审片、资产复用等全链路功能,独创无限画布、双轨并行工业化工作流与Ani智能体助手,集成多款主流AI大模型,破解素材零散、版本混乱、沟通低��效等行业痛点,助力3人团队效率提升800%,打造标准化、可追溯的AI短剧量产体系,是AI短剧团队协同创作、提升制作效率的核心工具。


seedancetwo2.0
能听懂你表达的视频模型
Seedance two是基于seedance2.0的中国大模型,支持图像、视频、音频、文本四种模态输入,表达方式更丰富,生成也更可控。


nano-banana纳米香蕉中文站
国内直接访问,限时3折
输入简单文字,生成想要的图片,纳米香蕉中文站基于 Google 模型的 AI 图片生成网站,支持文字生图、图生图。官网价格限时3折活动


扣子-AI办公
职场AI,就用扣子
AI办公助手,复杂任务高效处理。办公效率低?扣子空间AI助手支持播客生成、PPT制作、网页开发及报告写作,覆盖科研、商业、舆情等领域的专家Agent 7x24小时响应,生活工作无缝切换,提升50%效率!


堆友
多风格AI绘画神器
堆友平台由阿里巴巴设计团队创建,作为一款AI驱动的设计工具,专为设计师提供一站式增长服务。功能覆盖海量3D素材、AI绘画、实时渲染以及专业抠图,显著提升设计品质和效率。平台不仅提供工具,还是一个促进创意交流和个人发展的空间,界面友好,适合所有级别的设计师和创意工作者。


码上飞
零代码AI应用开发平台
零代码AI应用开发平台,用户只需一句话简单描述需求,AI能自动生成小程序、APP或H5网页应用,无需编写代码。


Vora
免费创建高清无水印Sora视频
Vora是一个免费创建高清无水印Sora视频的AI工具
推荐工具精选





{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
AI云服务特惠
懂AI专属折扣关注微信公众号
最新AI工具、AI资讯
独家AI资源、AI项目落地

微信扫一扫关注公众号