


CLIP-ReID: 利用视觉-语言模型进行图像重识别而无需具体文本标签 [pdf]
![]()
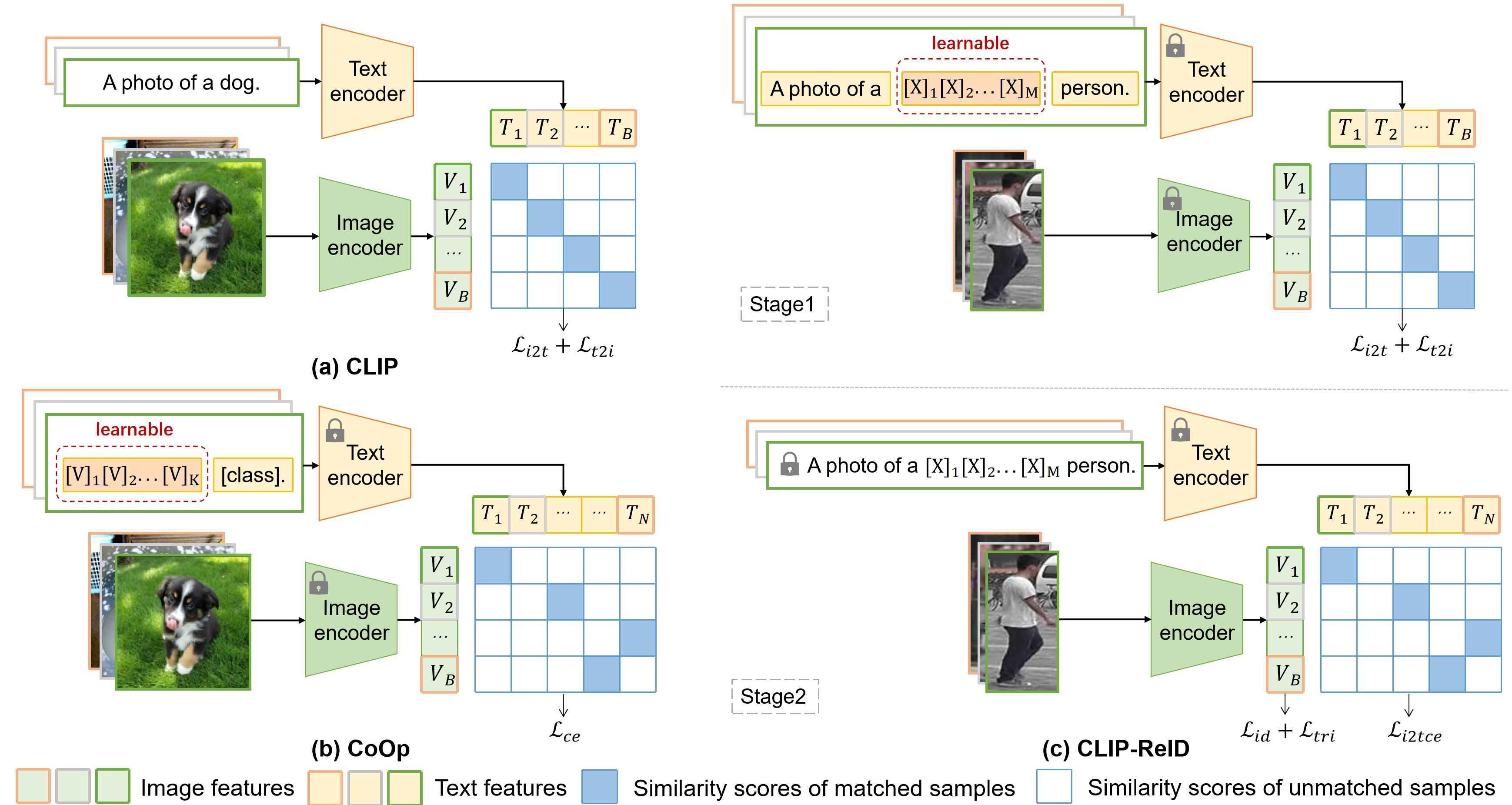
流程
安装
conda create -n clipreid python=3.8
conda activate clipreid
conda install pytorch==1.8.0 torchvision==0.9.0 torchaudio==0.8.0 cudatoolkit=10.2 -c pytorch
pip install yacs
pip install timm
pip install scikit-image
pip install tqdm
pip install ftfy
pip install regex
准备数据集
下载数据集(Market-1501、MSMT17、DukeMTMC-reID、Occluded-Duke、VehicleID、VeRi-776),然后将它们解压到 your_dataset_dir。
训练
例如,如果你想为Market-1501运行基于CNN的CLIP-ReID基线,你需要修改configs/person/cnn_base.yml底部为
DATASETS:
NAMES: ('market1501')
ROOT_DIR: ('your_dataset_dir')
OUTPUT_DIR: 'your_output_dir'
然后运行
CUDA_VISIBLE_DEVICES=0 python train.py --config_file configs/person/cnn_base.yml
如果你想为MSMT17运行基于ViT的CLIP-ReID,你需要修改configs/person/vit_clipreid.yml底部为
DATASETS:
NAMES: ('msmt17')
ROOT_DIR: ('your_dataset_dir')
OUTPUT_DIR: 'your_output_dir'
然后运行
CUDA_VISIBLE_DEVICES=0 python train_clipreid.py --config_file configs/person/vit_clipreid.yml
如果你想为MSMT17运行基于ViT的CLIP-ReID+SIE+OLP,运行:
CUDA_VISIBLE_DEVICES=0 python train_clipreid.py --config_file configs/person/vit_clipreid.yml MODEL.SIE_CAMERA True MODEL.SIE_COE 1.0 MODEL.STRIDE_SIZE '[12, 12]'
评估
例如,如果你想测试MSMT17的基于ViT的CLIP-ReID
CUDA_VISIBLE_DEVICES=0 python test_clipreid.py --config_file configs/person/vit_clipreid.yml TEST.WEIGHT 'your_trained_checkpoints_path/ViT-B-16_60.pth'
致谢
veri776视角标签来自 https://github.com/Zhongdao/VehicleReIDKeyPointData。
训练模型和测试日志
| 数据集 | MSMT17 | Market | Duke | Occ-Duke | VeRi | VehicleID |
|---|---|---|---|---|---|---|
| CNN-基准模型 | 模型|测试 | 模型|测试 | 模型|测试 | 模型|测试 | 模型|测试 | 模型|测试 |
| CNN-CLIP-ReID | 模型|测试 | 模型|测试 | 模型|测试 | 模型|测试 | 模型|测试 | 模型|测试 |
| ViT-基准模型 | 模型|测试 | 模型|测试 | 模型|测试 | 模型|测试 | 模型|测试 | 模型|测试 |
| ViT-CLIP-ReID | 模型|测试 | 模型|测试 | 模型|测试 | 模型|测试 | 模型|测试 | 模型|测试 |
| ViT-CLIP-ReID-SIE-OLP | 模型|测试 | 模型|测试 | 模型|测试 | 模型|测试 | 模型|测试 | 模型|测试 |
| 请注意,以上列出的所有结果均未经重新排序。 |
经过重新排序后,ViT-CLIP-ReID-SIE-OLP 在 MSMT17 数据集上达到了 86.7% 的 mAP 和 91.1% 的 R1。
引用
如果您在研究中使用了此代码,请引用:
@article{li2022clip,
title={CLIP-ReID: 在没有具体文本标签的情况下利用视觉-语言模型进行图像重识别},
author={李思远 and 孙力 and 李清丽},
journal={arXiv 预印本 arXiv:2211.13977},
year={2022}
}
编辑推荐精选


GPT Plus|Pro充值
GPT充值
支持 ChatGPT Plus / Pro 充值服务,支付便捷,自动发货,售后可查。


GPT Image 2中文站
AI 图片生成平台
GPT Image 2 是面向用户的 AI 图片生成平台,支持文生图、图生图及多模型创意工作流。


Vecbase
你的AI Agent团队
Vecbase 是专为 AI 团队打造的智能工作空间,将数据管理、模型协作与知识沉淀整合于一处。算法、产品与业务在同�一平台无缝协同,让从数据到 AI 应用的落地更快一步。


音述AI
全球首个AI音乐社区
音述AI是全球首个AI音乐社区,致力让每个人都能用音乐表达自我。音述AI提供零门槛AI创作工具,独创GETI法则帮助用户精准定义音乐风格,AI润色功能支持自动优化作品质感。音述AI支持交流讨论、二次创作与价值变现。针对中文用户的语言习惯与文化背景进行专门优化,支持国风融合、C-pop等本土音乐标签,让技术更好地承载人文表达。


QoderWork
阿里Qoder团队推出的桌面端AI智能体
QoderWork 是阿里推出的本地优先桌面 AI 智能体,适配 macOS14+/Windows10+,以自然语言交互实现文件管理、数据分析、AI 视觉生成、浏览器自动化等办公任务,自主拆解执行复杂工作流,数据本地运行零上传,技能市场可无限扩展,是高效的 Agentic 生产力办公助手。


lynote.ai
一站式搞定所有学习需求
不再被海量信息淹没,开始真正理解知识。Lynote 可摘要 YouTube 视频、PDF、文章等内容。即时创建笔记,检测 AI 内容并下载资料,将您的学习效率提升 10 倍。


AniShort
为AI短剧协作而生
专为AI短剧协作而生的AniShort正式发布,深度重构AI短剧全流程生产模式,整合创意策划、制作执行、实时协作、在线审片、资产复用等全链路功能,独创无限画布、双轨并行工业化工作��流与Ani智能体助手,集成多款主流AI大模型,破解素材零散、版本混乱、沟通低效等行业痛点,助力3人团队效率提升800%,打造标准化、可追溯的AI短剧量产体系,是AI短剧团队协同创作、提升制作效率的核心工具。


seedancetwo2.0
能听懂你表达的视频模型
Seedance two是基于seedance2.0的中国大模型,支持图像、视频、音频、文本四种模态输入,表达方式更丰富,生成也更可控。


nano-banana纳米香蕉中文站
国内直接访问,限时3折
输入简单文字,生成想要的图片,纳米香蕉中文站基于 Google 模型的 AI 图片生成网站,支持文字生图、图生图。官网价格限时3折活动


扣子-AI办公
职场AI,就用扣子
AI办公助手,复杂任务高效处理。办公效率低?扣子空间AI助手支持播客生成、PPT制作、网页开发及报告写作,覆盖科研、商业、舆情等领域的专家Agent 7x24小时响应,生活工作无缝切换,提升50%效率!
推荐工具精选





AI云服务特惠
懂AI专属折扣关注微信公众号
最新AI工具、AI资讯
独家AI资源、AI项目落地

微信扫一扫关注公众号