




<center>Stable Diffusion的网页用户界面</center>
由Sygil.Dev创建
加入Sygil.Dev的Discord服务器 
安装说明:
想要提问或请求新功能?
来我们的Discord服务器或使用讨论区。
文档
想要贡献?
查看贡献指南
Sygil-Dev主要开发者:


项目特点:
-
内置图像增强器和放大器,包括GFPGAN和realESRGAN
-
生成预览:查看图像生成过程
-
在CPU上运行额外的放大模型以节省VRAM
-
文本反转:研究论文
-
K-Diffusion采样器:丰富的采样器集合,包括:
k_eulerk_lmsk_euler_ak_dpm_2k_dpm_2_ak_heunPLMSDDIM
-
回环:自动将最后生成的样本反馈到img2img
-
提示词权重和负面提示:更好地控制你的创作
-
从设置选项卡选择GPU使用情况
-
单词种子:使用单词而不是种子数字
-
自动启动器:一键激活conda并运行Stable Diffusion
-
更低的VRAM占用:512x512的文本到图像和图像到图像在4GB显存上测试可用(启用设置中的优化模式)
-
提示词验证:如果你的提示词太长,你会在文本输出字段收到警告
-
批次的顺序种子:如果你使用种子1000生成两批两张图像,四张生成的图像将有种子:
1000, 1001, 1002, 1003 -
提示词矩阵:使用
|字符分隔多个提示词,系统将为每种组合生成一张图像 -
[Gradio] 高级img2img编辑器,具有遮罩和裁剪功能
-
[Gradio] 遮罩绘制🖌️:强大的工具,用于重新生成你想要更改的图像特定部分(目前仅限Gradio)
SD WebUI
直接从浏览器使用Stable Diffusion的简便方法。
Streamlit

特点:
- 干净的UI,设计易于使用,支持宽屏显示器
- 生成过程的动态实时预览
- 从WebUI的设置选项卡轻松自定义默认值
- 集成的图库展示提示词的生成结果
- 优化的VRAM使用,适用于更大的生成或在低端GPU上使用
- *文本到视频:*直接从WebUI生成文本提示的视频剪辑(开发中)
- 图像到文本:使用CLIP Interrogator分析图像并获取提示词,用于使用Stable Diffusion生��成类似图像
- *概念库:*运行他人通过文本反转创建的自定义嵌入
- 文本反转训练:对任何你想要的照片训练自己的嵌入,并在你的提示词中使用
- **目前正在开发:Stable Horde集成;来自Gradio的ImgLab、批量输入和遮罩编辑器
提示词权重和负面提示:
要给一个标记(AI识别的标签)特定或增加权重(强调),在提示词中添加:0.##,其中0.##是一个小数,指定冒号前所有标记的权重。
例:cat:0.30, dog:0.70或guy riding a bicycle :0.7, incoming car :0.30
负面提示可以通过使用###添加,之后的任何标记都将被视为负面。
例:cat playing with string ### yarn将在生成的图像中否定yarn。
负面提示是一个非常强大的工具,可以去除上下文相似或相关的主题,但添加时要小心,因为AI可能会看到你看不到的联系,最终输出无意义的内容。
**提示:*尝试使用相同的种子配合不同的提示词配置或权重值,看看AI如何理解它们,这可能会导致更好调整和更不容易出错的提示词。
请查看Streamlit文档了解更多信息。
Gradio [旧版]
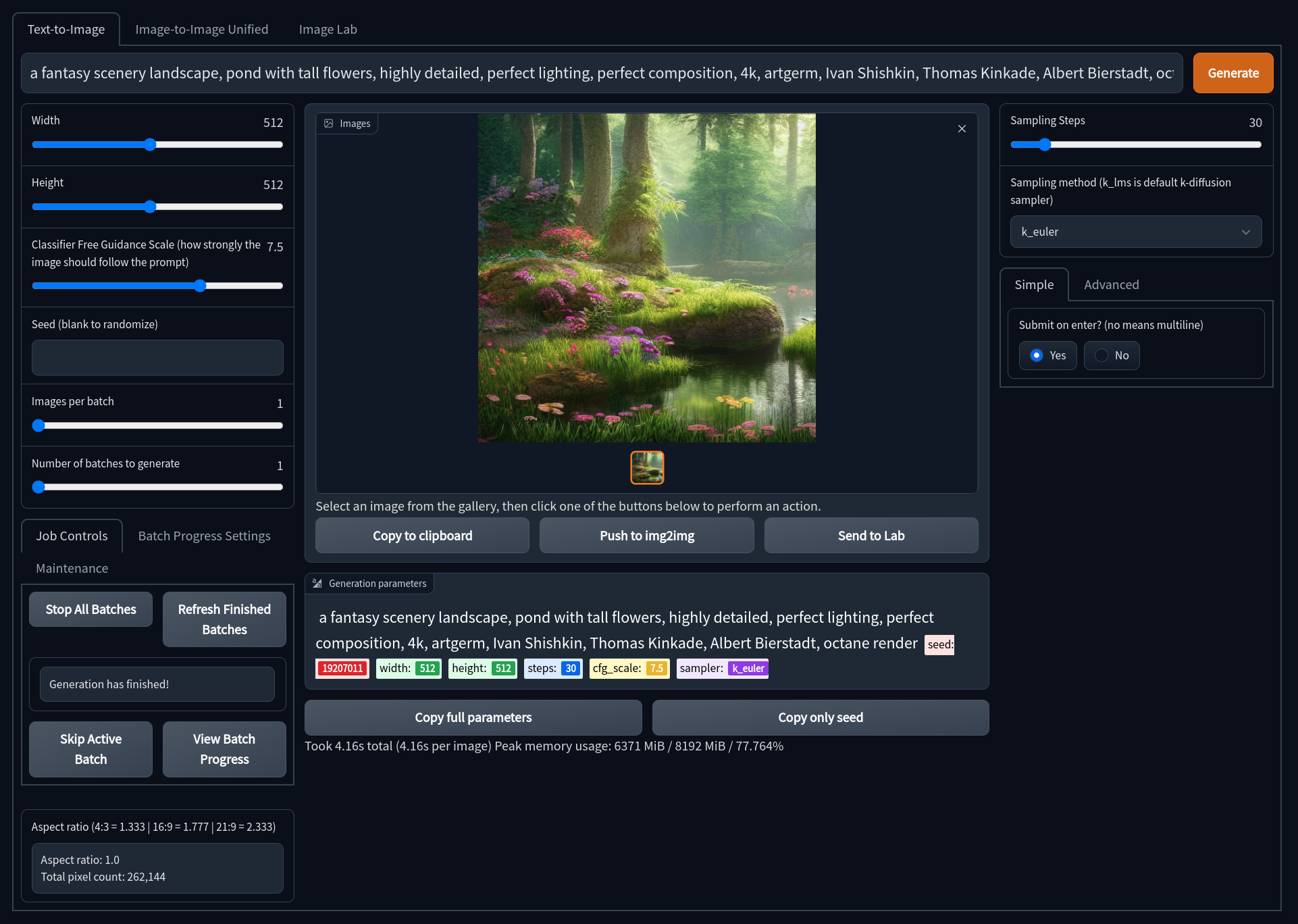
特点:
- 较旧的UI,功能齐全且特性完整。
- 可以访问所有放大模型,包括LSDR。
- 动态提示词输入根据提示词中的
--params自动更改生成设置。 - 包括快速简便的方法将生成结果发送到Image2Image或Image Lab进行放大。
注意:Gradio界面不再由Sygil.Dev积极开发,只接收错误修复。
请查看Gradio文档了解更多信息。
图像放大器
GFPGAN

允许你使用GFPGAN模型改善图片中的面部。每个选项卡都有一个复选框,可以100%使用GFPGAN,还有一个单独的选项卡,只允许你在任何图片上使用GFPGAN,有一个滑块控制效果的强度。
如果你想使用GFPGAN来改善生成的面部,你需要单独安装它。
下载GFPGANv1.4.pth并将其放入/sygil-webui/models/gfpgan目录。
RealESRGAN

让你能将生成的图像分辨率提高一倍。每个标签页都有一个使用RealESRGAN的复选框,你可以选择普通的放大器或动漫版本。 还有一个单独的标签页用于对任何图片使用RealESRGAN。
下载RealESRGAN_x4plus.pth和RealESRGAN_x4plus_anime_6B.pth。
将它们放入sygil-webui/models/realesrgan目录。
LSDR
下载LDSR的project.yaml和model last.cpkt。将last.ckpt重命名为model.ckpt,并将两个文件都放在sygil-webui/models/ldsr/下。
GoBig和GoLatent(目前仅适用于Gradio版本)
更强大的放大器,使用单独的潜在扩散模型来更清晰地放大图像。
请查看后处理文档以了解更多信息。
来自Stable Diffusion仓库的原始信息:
Stable Diffusion
Stable Diffusion的实现得益于与Stability AI和Runway的合作,并建立在我们之前的工作基础之上:
使用潜在扩散模型的高分辨率图像合成 Robin Rombach*, Andreas Blattmann*, Dominik Lorenz, Patrick Esser, Björn Ommer
CVPR '22 口头报告
该项目可在GitHub上获取。PDF版本在arXiv上。请同时访问我们的项目页面。
Stable Diffusion是一个潜在的文本到图像扩散模型。 感谢Stability AI慷慨提供的计算资源和LAION的支持,我们能够在LAION-5B数据库的一个子集中的512x512图像上训练一个潜在扩散模型。 与Google的Imagen类似,这个模型使用一个冻结的CLIP ViT-L/14文本编码器来基于文本提示进行条件设置。 凭借其860M UNet和123M文本编码器,该模型相对轻量,可以在至少10GB VRAM的GPU上运行。 请参阅下面的这一部分和模型卡片。
Stable Diffusion v1
Stable Diffusion v1指的是模型架构的一个特定配置,它使用一个下采样因子为8的自编码器,配有860M UNet和CLIP ViT-L/14文本编码器作为扩散模型。该模型在256x256图像上进行了预训练,然后在512x512图像上进行了微调。
*注意:Stable Diffusion v1是一个通用的文本到图像扩散模型,因此反映了其训练数据中存在的偏见和(错误)概念。 有关训练程序和数据的详细信息,以及模型的预期用途,可以在相应的模型卡片中找到。
评论
-
我们的扩散模型代码库大量借鉴了OpenAI的ADM代码库和https://github.com/lucidrains/denoising-diffusion-pytorch。 感谢开源!
-
Transformer编码器的实现来自lucidrains的x-transformers。
BibTeX
@misc{rombach2021highresolution,
title={High-Resolution Image Synthesis with Latent Diffusion Models},
author={Robin Rombach and Andreas Blattmann and Dominik Lorenz and Patrick Esser and Björn Ommer},
year={2021},
eprint={2112.10752},
archivePrefix={arXiv},
primaryClass={cs.CV}
}
编辑推荐精选


扣子-AI办公
职场AI,就用扣子
AI办公助手,复杂任务高效处理。办公效率低?扣子空间AI助手支持播客生成、PPT制作、网页开发及报告写作,覆盖科研、商业、舆情等领域的专家Agent 7x24小时响应,生活工作无缝切换,提升50%效率!


堆友
多风格AI绘画神器
堆友平台由阿里巴巴设计团队创建,作为一款AI驱动的设计工具,专为设计师提供一站式增长服务。功能覆盖海量3D素材、AI绘画、实时渲染以及专业抠图,显著提升设计品质和效率。平台不仅提供工具,还是一个促进创意交流和个人发展的空间,界面友好,适合所有级别的设计师和创意工作者。


码上飞
零代码AI应用开发平台
零代码AI应用开发平台,用户只需一句话简单描述需求,AI能自动生成小程序、APP或H5网页应用,无需编写代码。


Vora
免费创建高清无水印Sora视频
Vora是一个免费创建高清无水印Sora视频的AI工具


Refly.AI
最适合小白的AI自动化工作流平台
无需编码,轻松生成可复用、可变现的AI自动化工作流


酷表ChatExcel
大模型驱动的Excel数据处理工具
基于大模型交互的表格处理系统,允许用户通过对话方式完成数据整理和可视化分析。系统采用机器学习算法解析用户指令,自动执行排序、公式计算和数据透视等操作,支持多种文件格式导入导出。数据处理响应速度保持在0.8秒以内,支持超过100万行数据的即时分析。


TRAE编程
AI辅助编程,代码自动修复
Trae是一种自适应的集成开发环境(IDE),通过自动化和多元协作改变开发流程。利用Trae,团队能够更快速、精确地编写和部署代码,从而提高编程效率和项目交付速度。Trae具备上下文感知和代码自动完成功能,是提升开发效率的理想工具。


AIWritePaper论文写作
AI论文写作指导平台
AIWritePaper论文写作是一站式AI论文写作辅助工具,简化了选题、文献检索至论文撰写的整个过程。通过简单设定,平台可快速生成高质量论文大纲和全文,配合图表、参考文献等一应俱全,同时提供开题报告和答辩PPT等增值服务,保障数据安全,有效提升写作效率和论文质量。


博思AIPPT
AI一键生成PPT,就用博思AIPPT!
博思AIPPT,新一代的AI生成PPT平台,支持智能生成PPT、AI美化PPT、文本&链接生成PPT、导入Word/PDF/Markdown文档生成PPT等,内置海量精美PPT模板,涵盖商务、教育、科技等不同风格,同时针对每个页面提供多种版式,一键自适应切换,完美适配各种办公场景。


潮际好麦
AI赋能电商视觉革命,一站式智能商拍平台
潮际好麦深耕服装行业,是国内AI试衣效果最好的软件。使用先进AIGC能力为电商卖家批量提供优质的、低成本的商拍图。合作品牌有Shein、Lazada、安踏、百丽等65个国内外头部品牌,以及国内10万+淘宝、天猫、京东等主流平台的品牌商家,为卖家节�省将近85%的出图成本,提升约3倍出图效率,让品牌能够快速上架。
推荐工具精选




AI云服务特惠
懂AI专属折扣关注微信公众号
最新AI工具、AI资讯
独家AI资源、AI项目落地

微信扫一扫关注公众号