
pfgmpp
统一扩散和泊松流的生成模型框架
PFGM++是一个统一扩散模型和泊松流生成模型的框架,通过在高维空间嵌入路径来生成数据。它可以退化为PFGM或扩散模型,并允许通过选择额外维度D来平衡模型的鲁棒性和刚性。实验显示,特定D值的PFGM++模型在CIFAR-10和FFHQ数据集上的性能超越了现有的扩散模型,并对建模误差表现出更好的鲁棒性。




PFGM++:释放物理启发生成模型的潜力
![]()
论文《PFGM++:释放物理启发生成模型的潜力》的PyTorch实现
作者:徐逸伦、刘子明、田永龙、童尚源、Max Tegmark、Tommi S. Jaakkola
[幻灯片]
| CIFAR-10 | FFHQ-64 | LSUN-Church-256 |
|---|---|---|
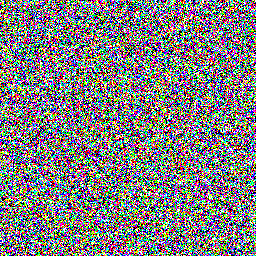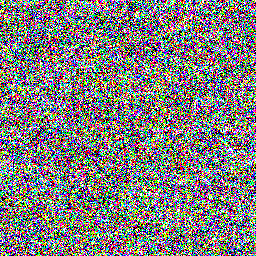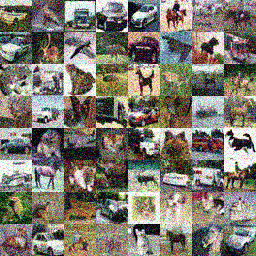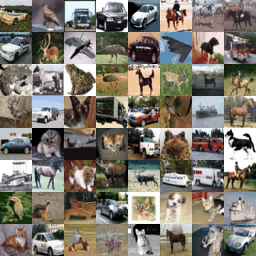 |  | 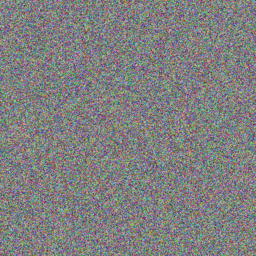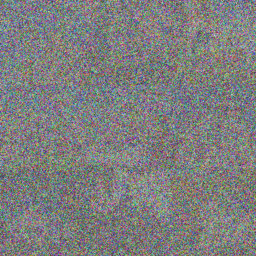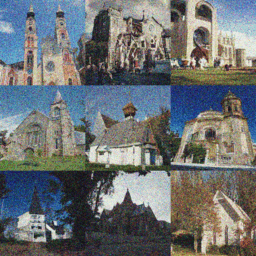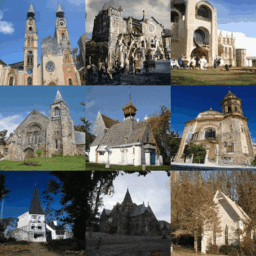 |
😇 相比PFGM和扩散模型的改进:
- 不再需要PFGM中的大批量训练目标,从而实现灵活的条件生成和更高效的训练!
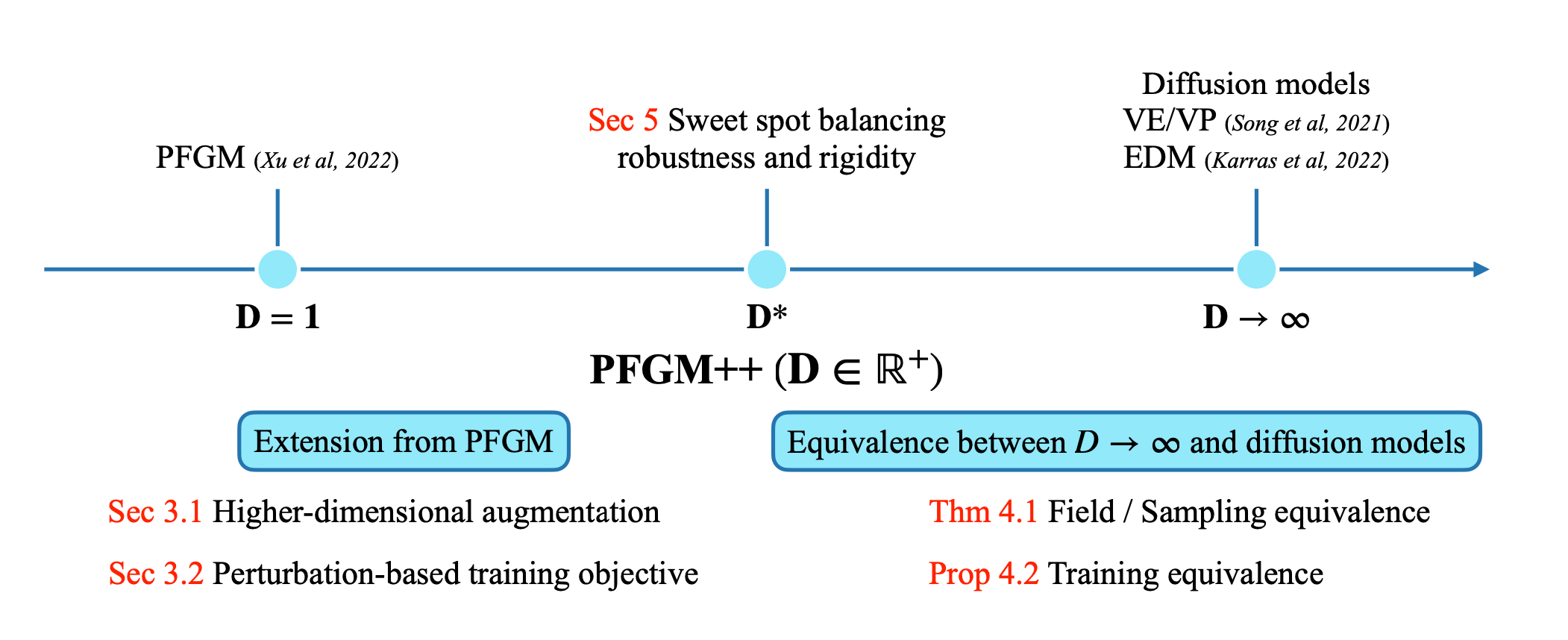
- 更一般的 $D \in \mathbb{R}^+$ 维增广变量。PFGM++包含了PFGM和扩散模型:PFGM对应 $D=1$,扩散模型对应 $D\to \infty$。
- 存在 $(1,\infty)$ 中间的最佳点 $D^*$!
- 较小的 $D$ 比扩散模型($D\to \infty$)更稳健
- 可以调整模型的稳健性和刚性!
- 可以直接迁移任何现有扩散模型($D\to \infty$)的精调超参数!
*摘要:我们提出了一个名为PFGM++*的通用框架,统一了扩散模型和泊松流生成模型(PFGM)。这些模型通过在 $N{+}D$ 维空间中嵌入路径来实现 $N$ 维数据的生成轨迹,同时仍然使用 $D$ 个额外变量的简单标量范数来控制进程。新模型在 $D{=}1$ 时退化为PFGM,在 $D{\to}\infty$ 时退化为扩散模型。选择 $D$ 的灵活性使我们能够在稳健性和刚性之间权衡,因为增加 $D$ 会导致数据和额外变量范数之间的耦合更加集中。我们摒弃了PFGM中使用的有偏大批量场目标,而是提供了一个类似于扩散模型的无偏扰动目标。为了探索不同的 $D$ 选择,我们提供了一种直接对齐方法,用于将精调的扩散模型($D{\to} \infty$)超参数转移到任何有限 $D$ 值。我们的实验表明,有限 $D$ 的模型可以优于之前最先进的扩散模型,在CIFAR-10/FFHQ $64{\times}64$ 数据集上,当 $D{=}2048/128$ 时FID分数为 $1.91/2.43$。在类条件生成中,$D{=}2048$ 在CIFAR-10上产生了当前最先进的FID $1.74$。此外,我们证明较小 $D$ 的模型对建模错误表现出更好的稳健性。
大纲
我们的实现基于EDM仓库。我们首先提供了一个指导,说明如何快速将精调扩散模型($D\to \infty$)的超参数转移到PFGM++家族($D\in \mathbb{R}^+$��),如EDM和DDPM,这种方式与任务/数据集无关(我们在论文的第4节(将超参数转移到有限 $D$)和附录C.2中提供了更多细节)。我们基于他们原始的命令行突出显示了我们对训练、采样和评估的修改。我们在检查点部分提供了检查点。
我们还提供了来自EDM仓库的原始设置说明,如环境要求和数据集准备。
通过 $r=\sigma\sqrt{D}$ 公式进行转移指导
下面我们提供了如何快速将精调的扩散模型($D\to \infty$)超参数(如 $\sigma_{\textrm{max}}$ 和 $p(\sigma)$)转移到有限 $D$ 的指导。我们采用论文中的 $r=\sigma\sqrt{D}$ 公式进行对齐(参见第4节)。请将以下指导作为原型使用。
😀 请根据你的任务/数据集/模型调整增广维度 $D$。
训练超参数转移。我们提供的示例是本仓库中 loss.py 的简化版本。

def train(y, N, D, pfgmpp): ''' y: 小批量干净图像 N: 数据维度 D: 增广维度 pfgmpp: 使用PFGM++框架,否则为扩散模型(D\to\infty情况)。选项:0 | 1 ''' if not pfgmpp: ###################### === 扩散模型 === ###################### rnd_normal = torch.randn([images.shape[0], 1, 1, 1], device=images.device) sigma = (rnd_normal * self.P_std + self.P_mean).exp() # 从p(\sigma)采样sigma n = torch.randn_like(y) * sigma D_yn = net(y + n, sigma) loss = (D_yn - y) ** 2 ###################### === 扩散模型 === ###################### else: ###################### === PFGM++ === ###################### rnd_normal = torch.randn(images.shape[0], device=images.device) sigma = (rnd_normal * self.P_std + self.P_mean).exp() # 从p(\sigma)采样sigma r = sigma.double() * np.sqrt(self.D).astype(np.float64) # r=sigma\sqrt{D}公式
= 从扰动核 p_r 采样噪声 =
从逆贝塔分布采样
samples_norm = np.random.beta(a=self.N / 2., b=self.D / 2., size=images.shape[0]).astype(np.double) inverse_beta = samples_norm / (1 - samples_norm +1e-8) inverse_beta = torch.from_numpy(inverse_beta).to(images.device).double()
通过变量变换从 p_r(R) 采样 (参见附录 B)
samples_norm = (r * torch.sqrt(inverse_beta +1e-8)).view(len(samples_norm), -1)
均匀采样角度分量
gaussian = torch.randn(images.shape[0], self.N).to(samples_norm.device) unit_gaussian = gaussian / torch.norm(gaussian, p=2, dim=1, keepdim=True)
构造扰动
perturbation_x = (unit_gaussian * samples_norm).float()
= 从扰动核 p_r 采样噪声 =
sigma = sigma.reshape((len(sigma), 1, 1, 1)) n = perturbation_x.view_as(y) D_yn = net(y + n, sigma) loss = (D_yn - y) ** 2 ###################### === PFGM++ === ######################
采样超参数转换。我们提供的示例是这个仓库中 [generate.py] 的简化版本。如下图所示,唯一的修改是先验采样过程。因此,我们在代码片段中仅包含了扩散模型和 PFGM++ 的先验采样比较。
![示意图]
def generate(sigma_max, N, D, pfgmpp) ''' sigma_max: 扩散模型的起始条件 N: 数据维度 D: 增广维度 pfgmpp: 使用 PFGM++ 框架,否则为扩散模型(D\to\infty 情况)。选项:0 | 1 ''' if not pfgmpp: ###################### === 扩散模型 === ###################### x = torch.randn_like(data_size) * sigma_max ###################### === 扩散模型 === ###################### else: ###################### === PFGM++ === ###################### # 从逆贝塔分布采样 r = sigma_max * np.sqrt(self.D) # r=sigma\sqrt{D} 公式 samples_norm = np.random.beta(a=self.N / 2., b=self.D / 2., size=data_size).astype(np.double) inverse_beta = samples_norm / (1 - samples_norm +1e-8) inverse_beta = torch.from_numpy(inverse_beta).to(images.device).double() # 通过变量变换从 p_r(R) 采样 (参见附录 B) samples_norm = (r * torch.sqrt(inverse_beta +1e-8)).view(len(samples_norm), -1) # 均匀采样角度分量 gaussian = torch.randn(images.shape[0], self.N).to(samples_norm.device) unit_gaussian = gaussian / torch.norm(gaussian, p=2, dim=1, keepdim=True) # 构造扰动 x = (unit_gaussian * samples_norm).float().view(data_size) ###################### === PFGM++ === ####################### ######################################################## # Heun 二阶方法(又称改进的欧拉方法) # ########################################################
请参阅附录 C.2了解从 EDM 和 DDPM 进行详细超参数转换的程序。
训练 PFGM++
您可以使用 train.py 训练新模型。例如:
torchrun --standalone --nproc_per_node=8 train.py --outdir=training-runs --name exp_name \ --data=datasets/cifar10-32x32.zip --cond=0 --arch=arch \ --pfgmpp=1 --batch 512 \ --aug_dim aug_dim (--resume resume_path) exp_name: 实验名称 aug_dim: D(额外维度) arch: 模型架构。选项:ncsnpp | ddpmpp pfgmpp: 使用 PFGM++ 框架,否则为扩散模型(D\to\infty 情况)。选项:0 | 1 resume_path: 恢复检��查点的路径
上述示例使用默认的批量大小为 512 张图像(由 --batch 控制),这些图像在 8 个 GPU 之间均匀分配(由 --nproc_per_node 控制),每个 GPU 处理 64 张图像。训练大型模型可能会耗尽 GPU 内存;避免这种情况的最佳方法是限制每个 GPU 的批量大小,例如 --batch-gpu=32。这使用梯度累积来产生与使用完整的每 GPU 批量相同的结果。有关完整的选项列表,请参阅 [python train.py --help]。
每次训练运行的结果都保存在新创建的目录 training-runs/exp_name 中。训练循环会定期导出网络快照(training-state-*.pt)(由 --dump 控制)。网络快照可用于使用 generate.py 生成图像,训练状态可用于稍后恢复训练(--resume)。其他有用信息记录在 log.txt 和 stats.jsonl 中。为了监控训练收敛情况,我们建议查看训练损失(stats.jsonl 中的 "Loss/loss"),并定期使用 generate.py 和 fid.py 评估 training-state-*.pt 的 FID。
对于 FFHQ 数据集,将 --data=datasets/cifar10-32x32.zip 替换为 --data=datasets/ffhq-64x64.zip
注意: 原始 EDM 仓库提供了更多数据集:FFHQ、AFHQv2、ImageNet-64。由于计算资源有限,我们没有测试 PFGM++ 在这些数据集上的性能。然而,我们相信某些有限的 D(最佳点)会优于扩散模型(D\to\infty 情况)。如果您有这些结果,请告诉我们 😀
生成和评估
-
生成 50k 个样本:
torchrun --standalone --nproc_per_node=8 generate.py \ --seeds=0-49999 --outdir=./training-runs/exp_name \ --pfgmpp=1 --aug_dim=aug_dim (--use_pickle=1)(--save_images) exp_name: 实验名称 aug_dim: D(额外维度) arch: 模型架构。选项:ncsnpp | ddpmpp pfgmpp: 使用 PFGM++ 框架,否则为扩散模型(D\to\infty 情况)。选项:0 | 1。(默认:0) use_pickle: 当检查点以 pickle 格式(.pkl)存储时。(默认:0)
请注意,FID 的数值在不同的随机种子间会有变化,并且对图像数量非常敏感。默认情况下,fid.py 总是使用 50,000 张生成的图像;提供更少的图像会导致错误,而提供更多则会使用随机子集。为了减少随机变化的影响,我们建议使用不同的种子重复计算多次,例如 --seeds=0-49999、--seeds=50000-99999 和 --seeds=100000-149999。在 EDM 论文中,他们计算了每个 FID 三次并报告了最小值。
对于 FID 与受控 $\alpha$/NFE/量化的对比,请使用 generate_alpha.py/generate_steps.py/generate_quant.py 进行生成。
-
FID 评估
torchrun --standalone --nproc_per_node=8 fid.py calc --images=training-runs/exp_name --ref=fid-refs/cifar10-32x32.npz --num 50000 exp_name: 实验名称
检查点
所有检查点都提供在这个 [Google Drive 文件夹] 中。我们从 [EDM] 仓库借用了特定于数据集的超参数,例如批量大小、学习率等。如果您想尝试更多数据集(如 ImageNet 64),请参考该仓库的超参数。由于历史原因,一些检查点是 .pkl 格式,使用 generate.py 进行图像生成时请添加 --use_pickle=1 标志。在运行上述生成命令之前,请将检查点下载到指定的 ./training-runs/exp_name 文件夹中。
| 模型 | 检查点路径 | $D$ | FID | 选项 |
|---|---|---|---|---|
| cifar10-ncsnpp-D-128 | pfgmpp/cifar10_ncsnpp_D_128/ | 128 | 1.92 | --cond=0 --arch=ncsnpp --pfgmpp=1 --aug_dim=128 |
| cifar10-ncsnpp-D-2048 | pfgmpp/cifar10_ncsnpp_D_2048/ | 2048 | 1.91 | --cond=0 --arch=ncsnpp --pfgmpp=1 --aug_dim=2048 |
| cifar10-ncsnpp-D-2048-conditional | pfgmpp/cifar10_ncsnpp_D_2048_conditional/ | 2048 | 1.74 | --cond=1 --arch=ncsnpp --pfgmpp=1 --aug_dim=2048 |
| cifar10-ncsnpp-D-inf (EDM) | pfgmpp/cifar10_ncsnpp_D_inf/ | $\infty$ | 1.98 | --cond=0 --arch=ncsnpp |
| ffhq-ddpm-D-128 | pfgmpp/ffhq_ddpm_D_128/ | 128 | 2.43 | --cond=0 --arch=ddpmpp --batch=256 --cres=1,2,2,2 --lr=2e-4 --dropout=0.05 --augment=0.15 --pfgmpp=1 --aug_dim=128 |
| ffhq-ddpm-D-inf (EDM) | pfgmpp/ffhq_ddpm_D_inf/ | $\infty$ | 2.53 | --cond=0 --arch=ddpmpp --batch=256 --cres=1,2,2,2 --lr=2e-4 --dropout=0.05 --augment=0.15 |
EDM仓库的设置说明
要求
- Python库:具体的库依赖请参见
environment.yml。您可以使用以下命令和Miniconda3创建并激活Python环境:conda env create -f environment.yml -n edmconda activate edm
- Docker用户:
- 确保您已正确安装NVIDIA容器运行时。
- 使用提供的Dockerfile构建包含所需库依赖的镜像。
准备数据集
数据集的存储格式与StyleGAN相同:未压缩的ZIP存档,包含未压缩的PNG文件和用于标签的元数据文件dataset.json。可以从包含图像的文件夹创建自定义数据集;更多信息请参见python dataset_tool.py --help。
CIFAR-10: 下载CIFAR-10 Python版本并转换为ZIP存档:
python dataset_tool.py --source=downloads/cifar10/cifar-10-python.tar.gz \
--dest=datasets/cifar10-32x32.zip
python fid.py ref --data=datasets/cifar10-32x32.zip --dest=fid-refs/cifar10-32x32.npz
FFHQ: 下载Flickr-Faces-HQ数据集的1024x1024图像,并转换为64x64分辨率的ZIP存档:
python dataset_tool.py --source=downloads/ffhq/images1024x1024 \
--dest=datasets/ffhq-64x64.zip --resolution=64x64
python fid.py ref --data=datasets/ffhq-64x64.zip --dest=fid-refs/ffhq-64x64.npz
AFHQv2: 下载更新的Animal Faces-HQ数据集(afhq-v2-dataset),并转换为64x64分辨率的ZIP存档:
python dataset_tool.py --source=downloads/afhqv2 \
--dest=datasets/afhqv2-64x64.zip --resolution=64x64
python fid.py ref --data=datasets/afhqv2-64x64.zip --dest=fid-refs/afhqv2-64x64.npz
ImageNet: 下载ImageNet对象定位挑战赛数据集,并转换为64x64分辨率的ZIP存档:
python dataset_tool.py --source=downloads/imagenet/ILSVRC/Data/CLS-LOC/train \
--dest=datasets/imagenet-64x64.zip --resolution=64x64 --transform=center-crop
python fid.py ref --data=datasets/imagenet-64x64.zip --dest=fid-refs/imagenet-64x64.npz
编辑推荐精选


扣子-AI办公
职场AI,就用扣子
AI办公助手,复杂任务高效处理。办公效率低?扣子空间AI助手支持播客生成、PPT制作、网页开发及报告写作,覆盖科研、商业、舆情等领域的专家Agent 7x24小时响应,生活工作无缝切换,提升50%效率!


堆友
多风格AI绘画神器
堆友平台由阿里巴巴设计团队创建,作为一款AI驱动的设计工具,专为设计师提供一站式增长服务。功能覆盖海量3D素材、AI绘画、实时渲染以及专业抠图,显著提升设计品质和效率。平台不仅提供工具,还是一个促进创意交流和个人发展的空间,界面友好,适合所有级别的设计师和创意工作者。


码上飞
零代码AI应用开发平台
零代码AI应用开发平台,用户只需一句话简单描述需求,AI能自动生成小程序、APP或H5网页应用,无需编写代码。


Vora
免费创建高清无水印Sora视频
Vora是一个免费创建高清无水印Sora视频的AI工具


Refly.AI
最适合小白的AI自动化工作流平台
无需编码,轻松生成可复用、可变现的AI自动化工作流


酷表ChatExcel
大模型驱动的Excel数据处理工具
基于大模型交互的表格处理系统,允许用户通过对话方式完成数据整理和可视化分析。系统采用机器学习算法解析用户指令,自动执行排序、公式计算和数据透视等操作,支持多种文件格式导入导出。数据处理响应速度保持在0.8秒以内,支持超过100万行数据的即时分析。


TRAE编程
AI辅助编程,代码自动修复
Trae是一种自适应的集成开发环境(IDE),通过自动化和多元协作改变开发流程。利用Trae,团队能够更快速、精确地编写和部署代码,从而提高编程效率和项目交付速度。Trae具备上下文感知和代码自动完成功能,是提升开发效率的理想工具。


AIWritePaper论文写作
AI论文写作指导平台
AIWritePaper论文写作是一站式AI论文写作辅助工具,简化了选题、文献检索至论文撰写的整个过程。通过简单设定,平台可快速生成高质量论文大纲和全文,配合图表、参考文献等一应俱全,同时提供开题报告和答辩PPT等增值服务,保障数据安全,有效提升写作效率和论文质量。


博思AIPPT
AI一键生成PPT,就用博思AIPPT!
博思AIPPT,新一代的AI生成PPT平台,支持智能生成PPT、AI美化PPT、文本&链接生成PPT、导入Word/PDF/Markdown文档生成PPT等,内置海量精美PPT模板,涵盖商务、教育、科技等不同风格,同时针对每个页面提供多种版式,一键自适应切换,完美适配各种办公场景。


潮际好麦
AI赋能电商视觉革命,一站式智能商拍平台
潮际好麦深耕服装行业,是国内AI试衣效果最好的软件。使用先进AIGC能力为电商卖家批量提供优质的、低成本的商拍图。合作品牌有Shein、Lazada、安踏、百丽等65个国内外头部品牌,以及国内10万+淘宝、天猫、京东等主流平台的品牌商家,为卖家节省将近85%的出图成本,提升约3倍出图效率,让品牌能够快速上架。
推荐工具精选




AI云服务特惠
懂AI专属折扣关注微信公众号
最新AI工具、AI资讯
独家AI资源、AI项目落地

微信扫一扫关注公众号