


一次性实时通用多任务识别
本仓库(Yolov8多任务)是论文《一次性实时通用多任务识别》的官方PyTorch实现。
作者: 王家园、吴乔明<sup> :email:</sup>、张宁
(<sup>:email:</sup>) 通讯作者
A-YOLOM示意图
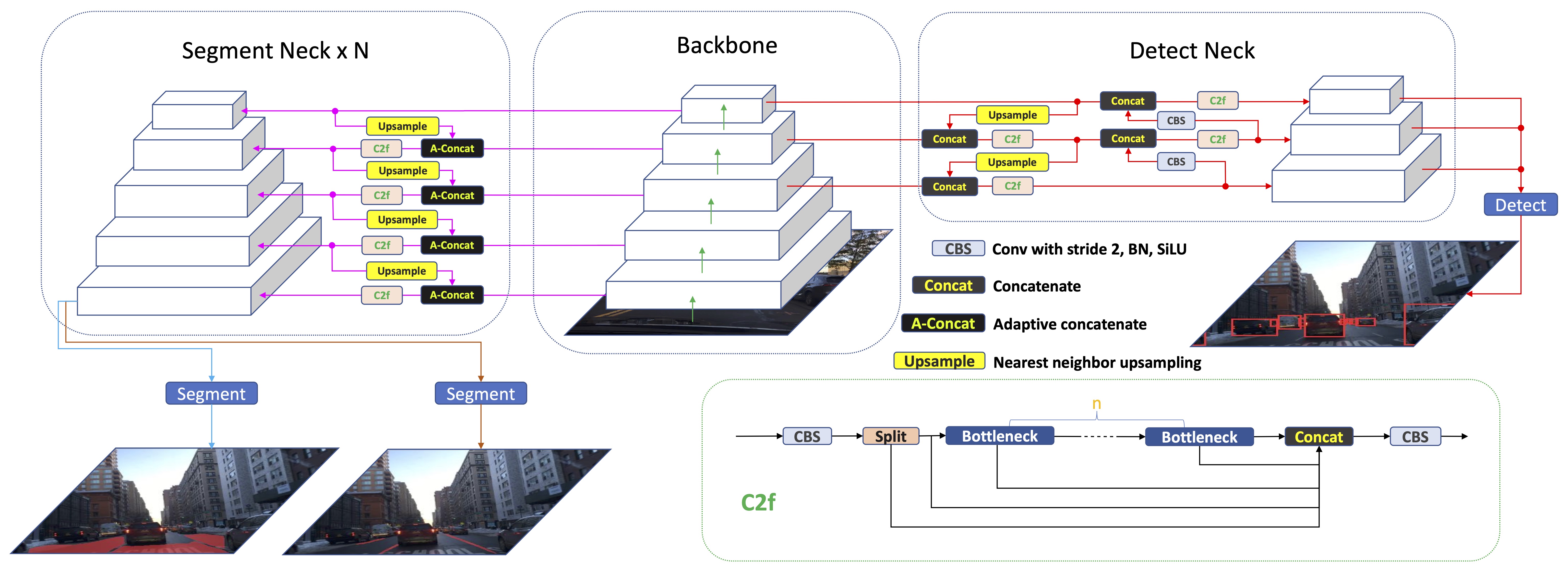
贡献
- 我们开发了一个轻量级模型,能将三个任务整合到一个统一的模型中。这对需要实时处理的多任务特别有益。
- 我们专门为分割架构的颈部设计了一个新颖的自适应拼接模块。该模块可以自适应地拼接特征,无需手动设计,进一步增强了模型的通用性。
- 我们设计了一个轻量级、简单且通用的分割头。我们对同类型的任务头使用统一的损失函数,这意味着我们不需要为特定任务定制设计。它仅由一系列卷积层构建而成。
- 我们基于公开可用的自动驾驶数据集进行了广泛的实验,结果表明我们的模型在性能上优于现有工作,特别是在推理时间和可视化方面。此外,我们还使用真实道路数据集进行了进一步的实验,结果也表明我们的模型明显优于最先进的方法。
结果
参数和速度
| 模型 | 参数量 | FPS (bs=1) | FPS (bs=32) |
|---|---|---|---|
| YOLOP | 7.9M | 26.0 | 134.8 |
| HybridNet | 12.83M | 11.7 | 26.9 |
| YOLOv8n(检测) | 3.16M | 102 | 802.9 |
| YOLOv8n(分割) | 3.26M | 82.55 | 610.49 |
| A-YOLOM(n) | 4.43M | 39.9 | 172.2 |
| A-YOLOM(s) | 13.61M | 39.7 | 96.2 |
交通目标检测结果
| 模型 | 召回率 (%) | mAP50 (%) |
|---|---|---|
| MultiNet | 81.3 | 60.2 |
| DLT-Net | 89.4 | 68.4 |
| Faster R-CNN | 81.2 | 64.9 |
| YOLOv5s | 86.8 | 77.2 |
| YOLOv8n(检测) | 82.2 | 75.1 |
| YOLOP | 88.6 | 76.5 |
| A-YOLOM(n) | 85.3 | 78.0 |
| A-YOLOM(s) | 86.9 | 81.1 |
可行驶区域分割结果
| 模型 | mIoU (%) |
|---|---|
| MultiNet | 71.6 |
| DLT-Net | 72.1 |
| PSPNet | 89.6 |
| YOLOv8n(分割) | 78.1 |
| YOLOP | 91.6 |
| A-YOLOM(n) | 90.5 |
| A-YOLOM(s) | 91.0 |
车道线检测结果:
| 模型 | 准确率 (%) | IoU (%) |
|---|---|---|
| Enet | N/A | 14.64 |
| SCNN | N/A | 15.84 |
| ENet-SAD | N/A | 16.02 |
| YOLOv8n(分割) | 80.5 | 22.9 |
| YOLOP | 84.8 | 26.5 |
| A-YOLOM(n) | 81.3 | 28.2 |
| A-YOLOM(s) | 84.9 | 28.8 |
消融研究 1: 自适应拼接模块:
| 训练方法 | 召回率 (%) | mAP50 (%) | mIoU (%) | 准确率 (%) | IoU (%) |
|---|---|---|---|---|---|
| YOLOM(n) | 85.2 | 77.7 | 90.6 | 80.8 | 26.7 |
| A-YOLOM(n) | 85.3 | 78 | 90.5 | 81.3 | 28.2 |
| YOLOM(s) | 86.9 | 81.1 | 90.9 | 83.9 | 28.2 |
| A-YOLOM(s) | 86.9 | 81.1 | 91 | 84.9 | 28.8 |
消融研究 2: 不同多任务模型和分割结构的结果:
| 模型 | 参数量 | mIoU (%) | 准确率 (%) | IoU (%) |
|---|---|---|---|---|
| YOLOv8(分割da) | 1004275 | 78.1 | - | - |
| YOLOv8(分割ll) | 1004275 | - | 80.5 | 22.9 |
| YOLOv8(多任务) | 2008550 | 84.2 | 81.7 | 24.3 |
| YOLOM(n) | 15880 | 90.6 | 80.8 | 26.7 |
YOLOv8(多任务)和YOLOM(n)仅显示两个分割头的总参数。它们实际上有三个头,我们忽略了检测头的参数,因为这是针对分割结构的消融研究。
注意:
- 我们参考的作品包括
Multinet(论文,代码),DLT-Net(论文),Faster R-CNN(论文,代码),YOLOv5s(代码),PSPNet(论文,代码),ENet(论文,代码),SCNN(论文,代码),SAD-ENet(论文,代码),YOLOP(论文,代码),HybridNets(论文,代码),YOLOv8(代码)。感谢他们出色的工作。
可视化
实际道路

要求
本代码库使用Python==3.7.16和PyTorch==1.13.1开发。
你可以使用一张1080Ti GPU,批量大小设为16。这样就足够了,只是训练时间会更长。我们推荐使用4090或更强大的GPU,这样会更快。
我们强烈建议你创建一个纯净的环境,并按照我们的说明来构建你的环境。否则,你可能会遇到一些问题,因为YOLOv8有许多机制会自动检测你的环境包。然后它会改变一些变量值,进而影响代码运行。
cd YOLOv8-multi-task pip install -e .
数据准备和预训练模型
下载
我们建议数据集目录结构如下:
# id代表对应关系
├─数据集根目录
│ ├─images
│ │ ├─train2017
│ │ ├─val2017
│ ├─detection-object
│ │ ├─labels
│ │ │ ├─train2017
│ │ │ ├─val2017
│ ├─seg-drivable-10
│ │ ├─labels
│ │ │ ├─train2017
│ │ │ ├─val2017
│ ├─seg-lane-11
│ │ ├─labels
│ │ │ ├─train2017
│ │ │ ├─val2017
在./ultralytics/datasets/bdd-multi.yaml中更新你的数据集路径。
训练
你可以在./ultralytics/yolo/cfg/default.yaml中设置训练配置。
python train.py
你可以在train.py中更改设置
# 设置 sys.path.insert(0, "/home/jiayuan/ultralytics-main/ultralytics") # 你应该将路径更改为你本地的"ultralytics"文件路径 model = YOLO('/home/jiayuan/ultralytics-main/ultralytics/models/v8/yolov8-bdd-v4-one-dropout-individual.yaml', task='multi') # 你需要更改模型路径为你的路径。 # 模型文件保存在"./ultralytics/models/v8"下 model.train(data='/home/jiayuan/ultralytics-main/ultralytics/datasets/bdd-multi-toy.yaml', batch=4, epochs=300, imgsz=(640,640), device=[4], name='v4_640', val=True, task='multi',classes=[2,3,4,9,10,11],combine_class=[2,3,4,9],single_cls=True)
-
data:请将"data"路径更改为你的路径。你可以在"./ultralytics/datasets"下找到它。
-
device:如果你有多个GPU,请列出你的GPU编号,例如[0,1,2,3,4,5,6,7,8]
-
name:你的项目名称,结果和训练好的模型将保存在"./ultralytics/runs/multi/你的项目名称"下
-
task:如果你想使用多任务模型,请在这里保持"multi"
-
classes:你可以更改此项来控制训练中的分类,10和11表示可驾驶区域和车道线分割。你可以在"./ultralytics/datasets/bdd-multi.yaml"下创建或更改数据集映射
-
combine_class:表示模型将"classes"合并为一个类,例如我们的项目将"汽车"、"公交车"、"卡车"和"火车"合并为"车辆"。
-
single_cls:这将把整个检测类别组合成一个类别。例如,如果你的数据集中有7个类别,当你使用"single_cls"时,它会自动将它们组合成一个类别。当你设置single_cls=False或从model.train()中删除single_cls时,请按照下面的注意事项更改dataset.yaml和model.yaml中的"tnc",dataset.yaml中的"nc_list",以及检测头的输出。
评估
你可以在./ultralytics/yolo/cfg/default.yaml中设置评估配置
python val.py
你可以在val.py中更改设置
# 设置 sys.path.insert(0, "/home/jiayuan/yolom/ultralytics") # 与训练相同,你应该将路径更改为你的路径。 model = YOLO('/home/jiayuan/ultralytics-main/ultralytics/runs/best.pt') # 请将此路径更改为你训练好的模型。你可以使用我们提供的预训练模型或你在"./ultralytics/runs/multi/Your Project Name/weight/best.pt"下的模型 metrics = model.val(data='/home/jiayuan/ultralytics-main/ultralytics/datasets/bdd-multi.yaml',device=[3],task='multi',name='val',iou=0.6,conf=0.001, imgsz=(640,640),classes=[2,3,4,9,10,11],combine_class=[2,3,4,9],single_cls=True)
- data:请将"data"路径更改为你的路径。你可以在"./ultralytics/datasets"下找到它
- device:如果你有多个GPU,请列出你的GPU编号,例如[0,1,2,3,4,5,6,7,8]。我们不建议你在验证时使用多GPU,因为通常一个GPU就足够了。
- speed:如果你想计算FPS,你应该设置"speed=True"。这个FPS计算方法参考自
HybridNets(代码) - single_cls:应该保持与训练时相同的布尔值。
预测
python predict.py
你可以在predict.py中更改设置
# 设置 sys.path.insert(0, "/home/jiayuan/ultralytics-main/ultralytics") number = 3 #输入你工作中的任务数量,如果你有1个检测和3个分割任务,这里应该是4。 model = YOLO('/home/jiayuan/ultralytics-main/ultralytics/runs/best.pt') model.predict(source='/data/jiayuan/dash_camara_dataset/daytime', imgsz=(384,672), device=[3],name='v4_daytime', save=True, conf=0.25, iou=0.45, show_labels=False) # 预测结果将保存在"runs"文件夹下
注意:如果你想使用我们提供的预训练模型,请确保你的输入图像大小为(720,1280),并保持"imgsz=(384,672)"以达到最佳性能,你可以更改"imgsz"的值,但结果可能会不同,因为它与训练尺寸不同。
- source:你的输入或想要预测的图像文件夹。
- show_labels=False:关闭标签的显示。请记住,当你使用"single cell=True"的预训练模型时,标签默认会显示第一个类别名称。
- boxes=False:关闭分割任务的边界框。
注意
-
这个代码很容易扩展到任何多分割和检测任务,只需修改模型yaml和数据集yaml文件信息,并按照我们的标签格式创建你的数据集,请记住,你应该在检测任务名称中保留"det",在分割任务名称中保留"seg"。然后代码就可以工作了。无需修改基本代码,我们已经在基本代码中完成了必要的工作。
-
请记住,当你更改检测任务的类别数量时,请更改dataset.yaml和model.yaml中的"tnc"。"tcn"表示总类别数,包括检测和分割。例如,如果你有7个检测类别,1个分割和另一个分割,"tnc"应该设置为9。
-
"nc_list"也需要更新,它应该与你的"labels_list"顺序匹配。例如,如果你的"labels_list"中有detection-object、seg-drivable、seg-lane,那么"nc_list"应该是[7,1,1]。这意味着你在detection-object中有7个类别,在drivable分割中有1个类别,在lane分割中有1个类别。
-
你还需要更改检测头输出数量,这在model.yaml中,例如" - [[15, 18, 21], 1, Detect, [int number for detection class]] # 36 Detect(P3, P4, P5)",请将"int number for detection class"更改为你的检测任务中的类别数量,按照上面的例子,这里应该是7。
-
-
如果你想更改一些基本代码来实现你的想法,请搜索"###### Jiayuan"或"######Jiayuan",我们基于
YOLOv8(代码)更改了这些部分,以在单个模型中实现多任务。
引用
如果你发现我们的论文和代码对你的研究有用,请考虑给予星标:star:和引用:pencil::
@ARTICLE{wang2024you, author={Wang, Jiayuan and Wu, Q. M. Jonathan and Zhang, Ning}, journal={IEEE Transactions on Vehicular Technology}, title={You Only Look at Once for Real-Time and Generic Multi-Task}, year={2024}, pages={1-13}, keywords={Multi-task learning;panoptic driving perception;object detection;drivable area segmentation;lane line segmentation}, doi={10.1109/TVT.2024.3394350}}
编辑推荐精选


扣子-AI办公
职场AI,就用扣子
AI办公助手,复杂任务高效处理。办��公效率低?扣子空间AI助手支持播客生成、PPT制作、网页开发及报告写作,覆盖科研、商业、舆情等领域的专家Agent 7x24小时响应,生活工作无缝切换,提升50%效率!


堆友
多风格AI绘画神器
堆友平台由阿里巴巴设计团队创建,作为一款AI驱动的设计工具,专为设计师提供一站式增长服务。功能覆盖海量3D素材、AI绘画、实时渲染以及专业抠图,显著提升设计品质和效率。平台不仅提供工具,还是一个促进创意交流和个人发展的空间,界面友好,适合所有级别的设计师和创意工作者。


码上飞
零代码AI应用开发平台
零代码AI应用开发平台,用户只需一句话简单描述需求,AI能自动生成小程序、APP或H5网页应用,无需编写代码。


Vora
免费创建高清无水印Sora视频
Vora是一个免费创建高清无水印Sora视频的AI工具


Refly.AI
最适合小白的AI自动化工作流平台
无需编码,轻松生成可复用、可变现的AI自动化工作流


酷表ChatExcel
大模型驱动的Excel数据处理工具
基于大模型交互的表格处理系统,允许用户通过对话方式完成数据整理和可视化分析。系统采用机器学习算法解析用户指令,自动执行排序、公式计算和数据透视等操作,支持多种文件格式导入导出。数据处理响应速度保持在0.8秒以内,支持超过100万行数据的即时分析。


TRAE编程
AI辅助编程,代码自动修复
Trae是一种自适应的集成开发环境(IDE),通过自动化和多元协作改变开发流程。利用Trae,团队能够更快速、精确地编写和部署代码,从而提高编程效率和项目交付速度。Trae具备上下文感知和代码自动完成功能,是提升开�发效率的理想工具。


AIWritePaper论文写作
AI论文写作指导平台
AIWritePaper论文写作是一站式AI论文写作辅助工具,简化了选题、文献检索��至论文撰写的整个过程。通过简单设定,平台可快速生成高质量论文大纲和全文,配合图表、参考文献等一应俱全,同时提供开题报告和答辩PPT等增值服务,保障数据安全,有效提升写作效率和论文质量。


博思AIPPT
AI一键生成PPT,就用博思AIPPT!
博思AIPPT,新一代的AI生成PPT平台,支持智能生成PPT、AI美化PPT、文本&链接生成PPT、导入Word/PDF/Markdown文档生成PPT等,内置海量精美PPT模板,涵盖商务、教育、科技等不同风格,同时针对每个页面提供多种版式,一键自适应切换,完美适配各种办公场景。


潮际好麦
AI赋能电商视觉革命,一站式智能商拍平台
潮际好麦深耕服装行业,是国内AI试衣效果最好的软件。使用先进AIGC能力为电商卖家批量提供优质的、低成本的商拍图。合作品牌有Shein、Lazada、安踏、百丽等65个国内外头部品牌,以及国内10万+淘宝、天猫、京东等主流平台的品牌商家,为卖家节省将近85%的出图成本,提升约3倍出图效率,让品牌能够快速上架。
推荐工具精选




AI云服务特惠
懂AI专属折扣关注微信公众号
最新AI工具、AI资讯
独家AI资源、AI项目落地

微信扫一��扫关注公众号