



杨佳伟<sup>1*†</sup> · Katie Z Luo<sup>2*</sup> · 李杰峰<sup>3</sup> · 邓聪越<sup>4</sup> <br> Leonidas Guibas<sup>4</sup> · Dilip Krishnan<sup>5</sup> · Kilian Q. Weinberger<sup>2</sup><br> 田永龙<sup>5</sup> · 王跃<sup>1</sup>
<sup>1</sup>南加州大学 <sup>2</sup>康奈尔大学 <br> <sup>3</sup>上海交通大学 <sup>4</sup>斯坦福大学 <br> <sup>5</sup>谷歌研究院 <br> †项目负责人 *技术贡献相同
已被 ECCV 2024 接收
<a href="https://arxiv.org/abs/2401.02957"><img src='https://img.shields.io/badge/arXiv-DVT -red' alt='论文 PDF'></a> <a href='https://jiawei-yang.github.io/DenoisingViT/'><img src='https://img.shields.io/badge/项目主页-DVT-blue' alt='项目主页'></a>
</div>摘要
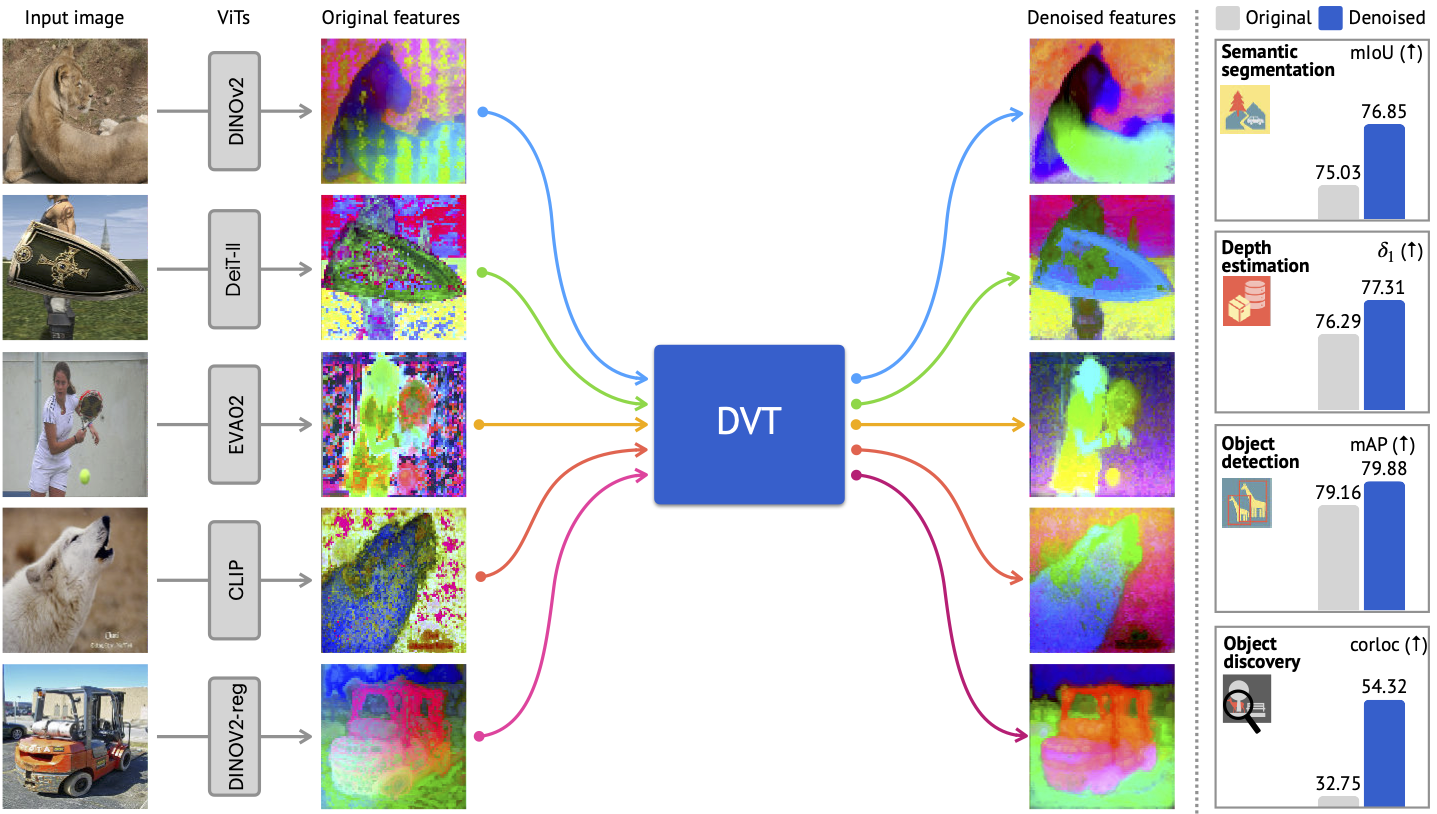
本工作提出了去噪视觉 Transformer (DVT)。它消除了 ViT 特征图中常见的视觉上令人不快的伪影,并显著提高了密集识别任务的下游性能。
引用
@article{yang2024denoising,
author = {Yang, Jiawei and Luo, Katie Z and Li, Jiefeng and Deng, Congyue and Guibas, Leonidas J. and Krishnan, Dilip and Weinberger, Kilian Q and Tian, Yonglong and Wang, Yue},
title = {DVT: Denoising Vision Transformers},
journal = {arXiv preprint arXiv:2401.02957},
year = {2024},
}
此 README 文件和代码库为旧版。我们将尽快更新。
安装
- 创建一个 conda 环境。
conda create -n dvt python=3.10 -y
- 激活环境。
conda activate dvt
- 从 requirements.txt 安装依赖项。
pip install -r requirements.txt
- 手动安装
tiny-cuda-nn:
pip install git+https://github.com/NVlabs/tiny-cuda-nn/#subdirectory=bindings/torch
如果遇到错误 nvcc fatal : Unsupported gpu architecture compute_89,请尝试以下命令:
TCNN_CUDA_ARCHITECTURES=86 pip install git+https://github.com/NVlabs/tiny-cuda-nn/#subdirectory=bindings/torch
如果遇到 error: parameter packs not expanded with '...' 错误,请参考 GitHub 上的这个解决方案。
数据准备
- PASCAL-VOC 2007 和 2012:
请下载 PASCAL VOC07 和 PASCAL VOC12 数据集(链接)并将数据放在
data文件夹中,例如:
mkdir -p data
cd data
wget http://host.robots.ox.ac.uk/pascal/VOC/voc2007/VOCtrainval_06-Nov-2007.tar
tar -xf VOCtrainval_06-Nov-2007.tar
wget http://host.robots.ox.ac.uk/pascal/VOC/voc2012/VOCtrainval_11-May-2012.tar
tar -xf VOCtrainval_11-May-2012.tar
在我们论文中报告的实验中,我们使用了 data/voc_train.txt 中的前 10,000 个示例进行第一阶段去噪。这个文本文件是通过收集 data/VOC2007/JPEGImages 和 data/VOC2012/JPEGImages 中的所有 JPG 图像,排除验证图像,然后随机打乱生成的。
-
ADE20K:[旧版,需要检查] 请下载 ADE20K 数据集 并将数据放在
data/ADEChallengeData2016中。 -
NYU-D: 请下载 NYU-depth 数据集 并将数据放在
data/nyu中。结果是基于 2014 年注释提供的,遵循先前的工作。 -
ImageNet(可选):
- 从 http://www.image-net.org/ 下载 ImageNet 数据集
- 按照这里的说明提取数据。
- 将数据放在
data/imagenet中。
运行代码
查看 sample_scripts 获取运行代码的示例。
我们在demo/demo_outputs中提供了一些演示输出。例如,这张图像展示了我们对一张猫咪图片的去噪结果:
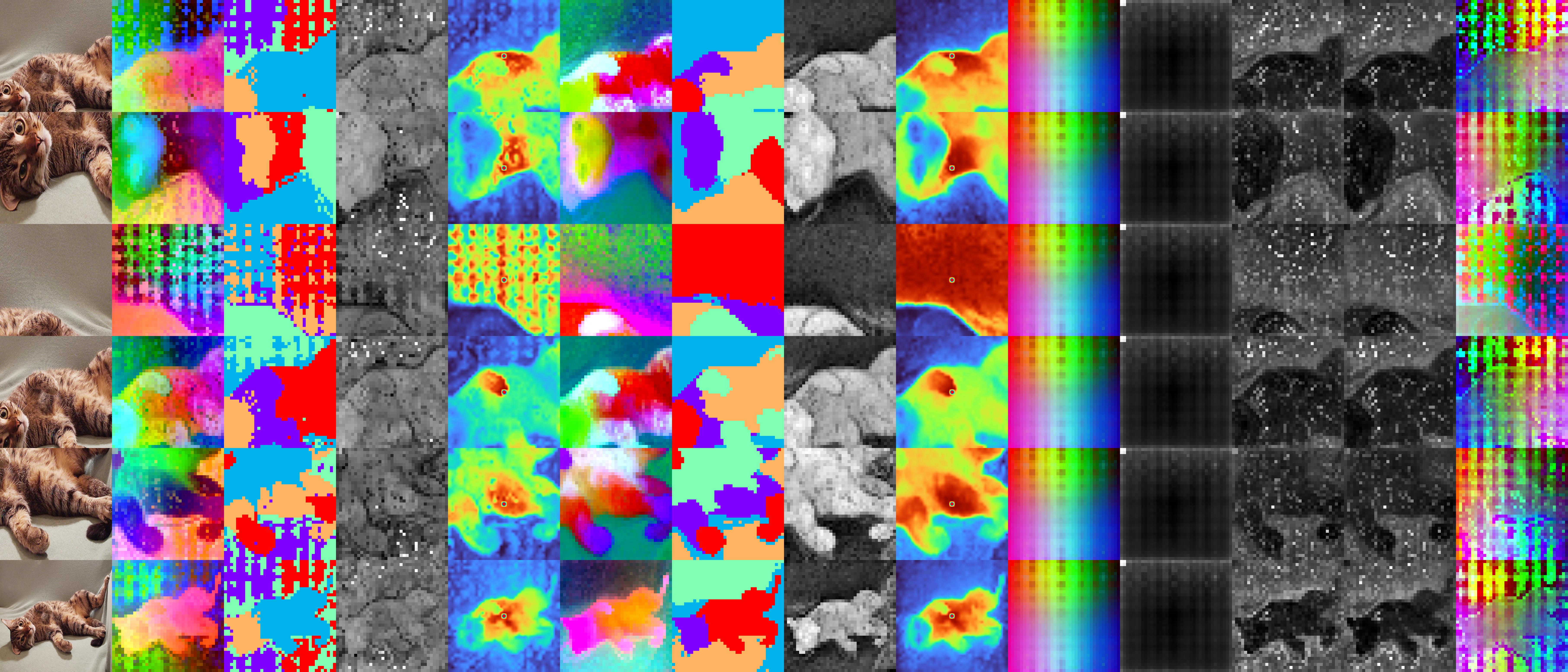 从左到右,我们展示了:(1)输入裁剪,(2)原始DINOv2 base输出,(3)原始输出的K均值聚类,(4)原��始输出的L2特征范数,(5)原始输出中中心块与其他块之间的相似度,(6)我们的去噪输出,(7)去噪输出的K均值聚类,(8)去噪输出的L2特征范数,(9)去噪输出中中心块与其他块之间的相似度,(10)分解出的共享伪影,(11)共享伪影的L2范数,(12)真实残差误差,(13)预测的残差项,以及(14)共享伪影和预测残差项的组合。
从左到右,我们展示了:(1)输入裁剪,(2)原始DINOv2 base输出,(3)原始输出的K均值聚类,(4)原��始输出的L2特征范数,(5)原始输出中中心块与其他块之间的相似度,(6)我们的去噪输出,(7)去噪输出的K均值聚类,(8)去噪输出的L2特征范数,(9)去噪输出中中心块与其他块之间的相似度,(10)分解出的共享伪影,(11)共享伪影的L2范数,(12)真实残差误差,(13)预测的残差项,以及(14)共享伪影和预测残差项的组合。
主要结果和检查点
VOC评估结果
| mIoU | aAcc | mAcc | 日志文件 | |
|---|---|---|---|---|
| MAE | 50.24 | 88.02 | 63.15 | 日志 |
| MAE + DVT | 50.53 | 88.06 | 63.29 | 日志 |
| DINO | 63.00 | 91.38 | 76.35 | 日志 |
| DINO + DVT | 66.22 | 92.41 | 78.14 | 日志 |
| Registers | 83.64 | 96.31 | 90.67 | 日志 |
| Registers + DVT | 84.50 | 96.56 | 91.45 | 日志 |
| DeiT3 | 70.62 | 92.69 | 81.23 | 日志 |
| DeiT3 + DVT | 73.36 | 93.34 | 83.74 | 日志 |
| EVA | 71.52 | 92.76 | 82.95 | 日志 |
| EVA + DVT | 73.15 | 93.43 | 83.55 | 日志 |
| CLIP | 77.78 | 94.74 | 86.57 | 日志 |
| CLIP + DVT | 79.01 | 95.13 | 87.48 | 日志 |
| DINOv2 | 83.60 | 96.30 | 90.82 | 日志 |
| DINOv2 + DVT | 84.84 | 96.67 | 91.70 | 日志 |
ADE20K评估结果
| mIoU | aAcc | mAcc | 日志文件 | |
|---|---|---|---|---|
| MAE | 23.60 | 68.54 | 31.49 | 日志 |
| MAE + DVT | 23.62 | 68.58 | 31.25 | 日志 |
| DINO | 31.03 | 73.56 | 40.33 | 日志 |
| DINO + DVT | 32.40 | 74.53 | 42.01 | 日志 |
| Registers | 48.22 | 81.11 | 60.52 | 日志 |
| Registers + DVT | 49.34 | 81.94 | 61.70 | 日志 |
| DeiT3 | 32.73 | 72.61 | 42.81 | 日志 |
| DeiT3 + DVT | 36.57 | 74.44 | 49.01 | 日志 |
| EVA | 37.45 | 72.78 | 49.74 | 日志 |
| EVA + DVT | 37.87 | 75.02 | 49.81 | 日志 |
| CLIP | 40.51 | 76.44 | 52.47 | 日志 |
| CLIP + DVT | 41.10 | 77.41 | 53.07 | 日志 |
| DINOv2 | 47.29 | 80.84 | 59.18 | 日志 |
| DINOv2 + DVT | 48.66 | 81.89 | 60.24 | 日志 |
NYU-D 评估结果
| RMSE | 相对误差 | 日志文件 | |
|---|---|---|---|
| MAE | 0.6695 | 0.2334 | 日志 |
| MAE + DVT | 0.7080 | 0.2560 | 日志 |
| DINO | 0.5832 | 0.1701 | 日志 |
| DINO + DVT | 0.5780 | 0.1731 | 日志 |
| Registers | 0.3969 | 0.1190 | 日志 |
| Registers + DVT | 0.3880 | 0.1157 | 日志 |
| DeiT3 | 0.588 | 0.1788 | 日志 |
| DeiT3 + DVT | 0.5891 | 0.1802 | 日志 |
| EVA | 0.6446 | 0.1989 | 日志 |
| EVA + DVT | 0.6243 | 0.1964 | 日志 |
| CLIP | 0.5598 | 0.1679 | 日志 |
| CLIP + DVT | 0.5591 | 0.1667 | 日志 |
| DINOv2 | 0.4034 | 0.1238 | 日志 |
| DINOv2 + DVT | 0.3943 | 0.1200 | 日志 |
降噪器检查点
[ ] 即将发布。
编辑推荐精选


扣子-AI办公
职场AI,就用扣子
AI办公助手,复杂任务高效处理。办公效率低?扣子空间AI助手支持播客生成、PPT制作、网页开发及报告写作,覆盖科研、商业、舆情等领域的专家Agent 7x24小时响应,生活工作无缝切换,提升50%效率!


堆友
多风格AI绘画神器
堆友平台由阿里巴巴设计团队创建,作为一款AI驱动的设计工具,专为设计师提供一站式增��长服务。功能覆盖海量3D素材、AI绘画、实时渲染以及专业抠图,显著提升设计品质和效率。平台不仅提供工具,还是一个促进创意交流和个人发展的空间,界面友好,适合所有级别的设计师和创意工作者。


码上飞
零代码AI应用开发平台
零代码AI应用开发平台,用户只需一句话简单描述需求,AI能自动生成小程序、APP或H5网页应用,无需编写代码。


Vora
免费创建高清无水印Sora视频
Vora是一个免费创建高清无水印Sora视频的AI工具


Refly.AI
最适合小白的AI自动化工作流平台
无需编码,轻松生成可复用、可变现的AI自动化工作流


酷表ChatExcel
大模型驱动的Excel数据处理工具
基于大模型交互的表格处理系统,允许用户通过对话方式完成数据整理和可视化分析。系统采用机器学习算法解析用户指令,自动执行排序、公式计算和数据透视等操作,支持多种文件格式导入导出。数据处理响应速度保持在0.8秒以内,支持超过100万行数据的即时分析。


TRAE编程
AI辅助编程,代码自动修复
Trae是一种自适应的集成开发环境(IDE),通过自动化和多元协作改变开发流程。利用Trae,团队能够更快速、精确地编写和部署代码,从而提高编程效率和项目交付速度。Trae具备上下文感知和代码自动完成功能,是提升开发效率的理想工具。


AIWritePaper论文写作
AI论文写作指导平台
AIWritePaper论文写作是一站式AI论文写作辅助工具,简化了选题、文献检索至论文撰写的整个过程。通过简单设定,平台可快速生成高质量论文大纲和全文,配合图表、参考文献等一应俱全,同时提供开题报告和答辩PPT等增值服务,保障数据安全,有效提升写作效率和论文质量。


博思AIPPT
AI一键生成PPT,就用博思AIPPT!
博思AIPPT,新一代的AI生成PPT平台,支持智能生成PPT、AI美化PPT、文本&链接生成PPT、导入Word/PDF/Markdown文档生成PPT等,内置海量精美PPT模板,涵盖商务、教育、科技等不同风格,同时针对每个页面提供多种版式,一键自适应切换,完美适配各种办公场景。


潮际好麦
AI赋能电商视觉革命,一站式智能商拍平台
潮际好麦深耕服装行业,是国内AI试衣效果最好的软件。使用先进AIGC能力为电商卖家批量提供优质的、低成本的商拍图。合作品牌有Shein、Lazada、安踏、百丽等65个国内外头部品牌,以及国内10万+淘宝、天猫、京东等主流平台的品牌商家,为卖家节省将近85%的出图成本,提升约3倍出图效率,让品牌能够快速上架。
推荐工具精选




AI云服务特惠
懂AI专属折扣关注微信公众号
最新AI工具、AI资讯
独家AI资源、AI项目落地

微信扫一扫关注公众号