
GroundingDINO
语言驱动的开放集目标检测模型
GroundingDINO是一个基于语言的开放集目标检测模型,能够检测图像中的任意物体。该模型在COCO数据集上实现了零样本52.5 AP和微调后63.0 AP的性能。GroundingDINO支持CPU模式,可与Stable Diffusion等模型集成用于图像编辑,还能与SAM结合实现分割功能。此外,项目提供了丰富的演示和教程资源,为开放世界目标检测领域带来了新的解决方案。





:sauropod: Grounding DINO
![]()
![]()
![]()
![]()
Shilong Liu、Zhaoyang Zeng、Tianhe Ren、Feng Li、Hao Zhang、Jie Yang、Chunyuan Li、Jianwei Yang、Hang Su、Jun Zhu、Lei Zhang<sup>:email:</sup>。
Grounding DINO的PyTorch实现和预训练模型。详情请参阅论文**Grounding DINO: 将DINO与基于地面真实标注的预训练结合用于开放集目标检测**。
- 🔥 **Grounded SAM 2**现已发布,它将Grounding DINO与SAM 2结合,用于开放世界场景中的任意目标跟踪。
- 🔥 Grounding DINO 1.5现已发布,这是IDEA Research最强大的开放世界目标检测模型!
- 🔥 **Grounding DINO和Grounded SAM**现已在Hugging Face上支持。为了更方便使用,您可以参考此文档
:sun_with_face: 有用的教程
- :grapes: [阅读我们的arXiv论文]
- :apple: [观看我们在YouTube上的简介视频]
- :blossom: [尝试Colab演示]
- :sunflower: [尝试我们的官方Hugging Face演示]
- :maple_leaf: [观看Roboflow AI制作的GroundingDINO逐步教程]
- :mushroom: [GroundingDINO:Roboflow AI的自动数据集标注和评估]
- :hibiscus: [使用SAM和GroundingDINO加速图像标注 by Roboflow AI]
- :white_flower: [Autodistill:基于Grounding-DINO和Grounded-SAM训练YOLOv8,无需人工标注 by Roboflow AI]
:sparkles: 亮点项目
- Semantic-SAM:一个通用图像分割模型,能够以任意所需粒度分割和识别任何物体。
- DetGPT:通过推理检测您需要的内容
- Grounded-SAM:将Grounding DINO与Segment Anything结合
- 将Grounding DINO与Stable Diffusion结合
- 将Grounding DINO与GLIGEN结合进行可控图像编辑
- OpenSeeD:一个简单而强大的开放集分割模型
- SEEM:一次性分割一切
- X-GPT:基于X-Decoder的对话式视觉代�理
- GLIGEN:开放集基于文本的图像生成
- LLaVA:大型语言和视觉助手
:bulb: 亮点
- 开放集检测。 用语言检测一切!
- 高性能。 COCO零样本52.5 AP(无COCO数据训练!)。COCO微调63.0 AP。
- 灵活。 与Stable Diffusion合作进行图像编辑。
:fire: 新闻
2023/07/18: 我们发布了 Semantic-SAM,这是一个通用图像分割模型,能够以任何所需粒度对任何物体进行分割和识别。代码和检查点现已可用!2023/06/17: 我们提供了一个示例来评估 Grounding DINO 在 COCO 零样本性能上的表现。2023/04/15: 对于那些对开放集识别感兴趣的人,请参考 CV in the Wild Readings!2023/04/08: 我们发布了 演示,将 Grounding DINO 与 GLIGEN 结合,实现更可控的图像编辑。2023/04/08: 我们发布了 演示,将 Grounding DINO 与 Stable Diffusion 结合用于图像编辑。2023/04/06: 我们将 GroundingDINO 与 Segment-Anything 结合,建立了一个名为 Grounded-Segment-Anything 的新演示,旨在支持 GroundingDINO 中的分割功能。2023/03/28: 关于 Grounding DINO 和基础目标检测提示工程的 YouTube 视频。[SkalskiP]2023/03/28: 在 Hugging Face Space 上添加了一个 演示!2023/03/27: 支持仅 CPU 模式。现在模型可以在没有 GPU 的机器上运行。2023/03/25: Grounding DINO 的 演示 在 Colab 上可用。[SkalskiP]2023/03/22: 代码现已可用!
:star: Grounding DINO 输入和输出的解释/提示
- Grounding DINO 接受一对
(图像, 文本)作为输入。 - 它输出
900个(默认情况下)目标框。每个框都有跨所有输入词的相似度分数。(如下图所示) - 我们默认选择最高相似度高于
box_threshold的框。 - 我们提取相似度高于
text_threshold的词作为预测标签。 - 如果你想获取特定短语的对象,比如句子
two dogs with a stick.中的dogs,你可以选择与dogs文本相似度最高的框作为最终输出。 - 注意,每个词可能会被不同的分词器拆分为多个标记。句子中的词数可能不等于文本标记的数量。
- 我们建议在 Grounding DINO 中用
.分隔不同的类别名称。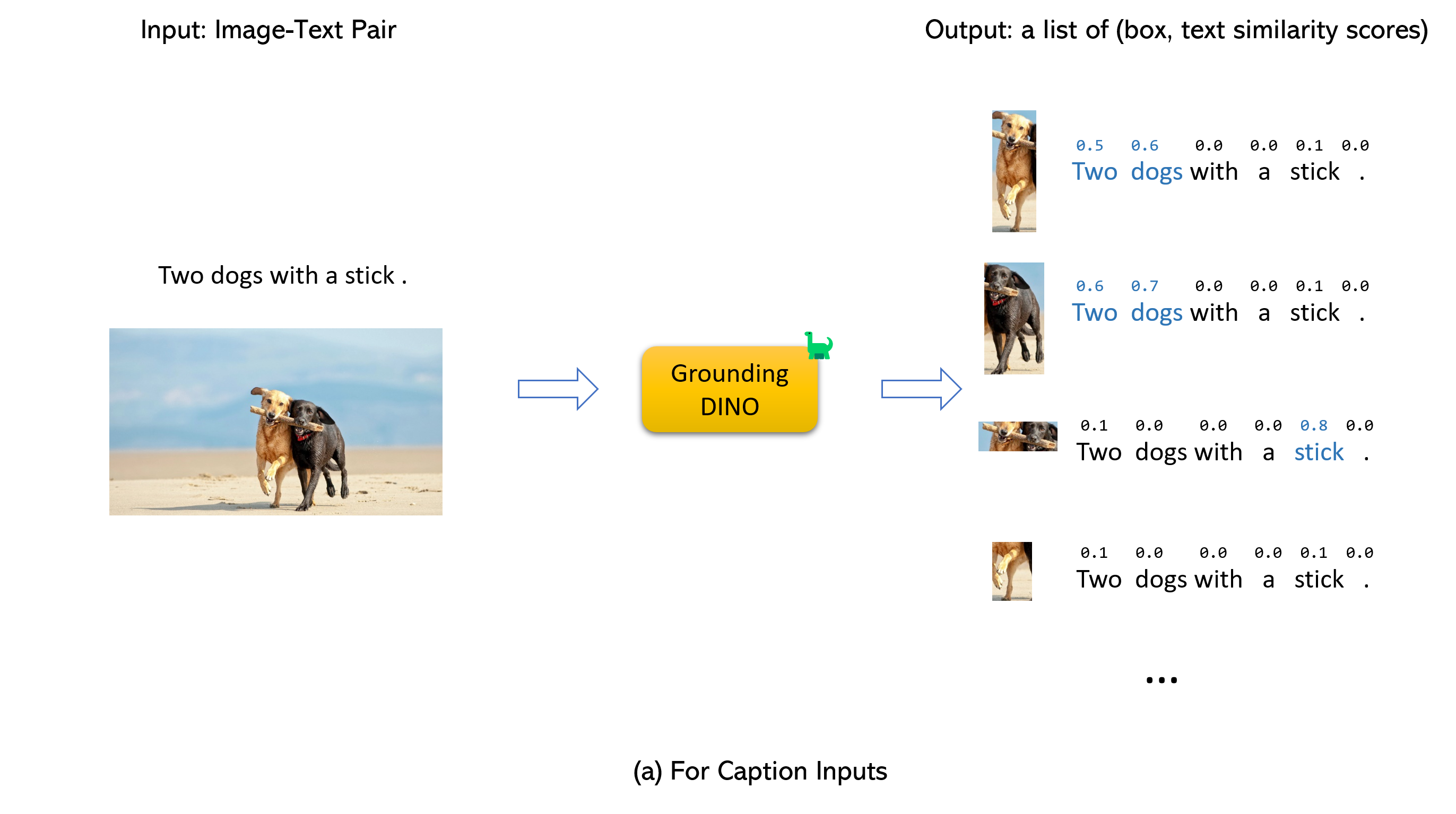
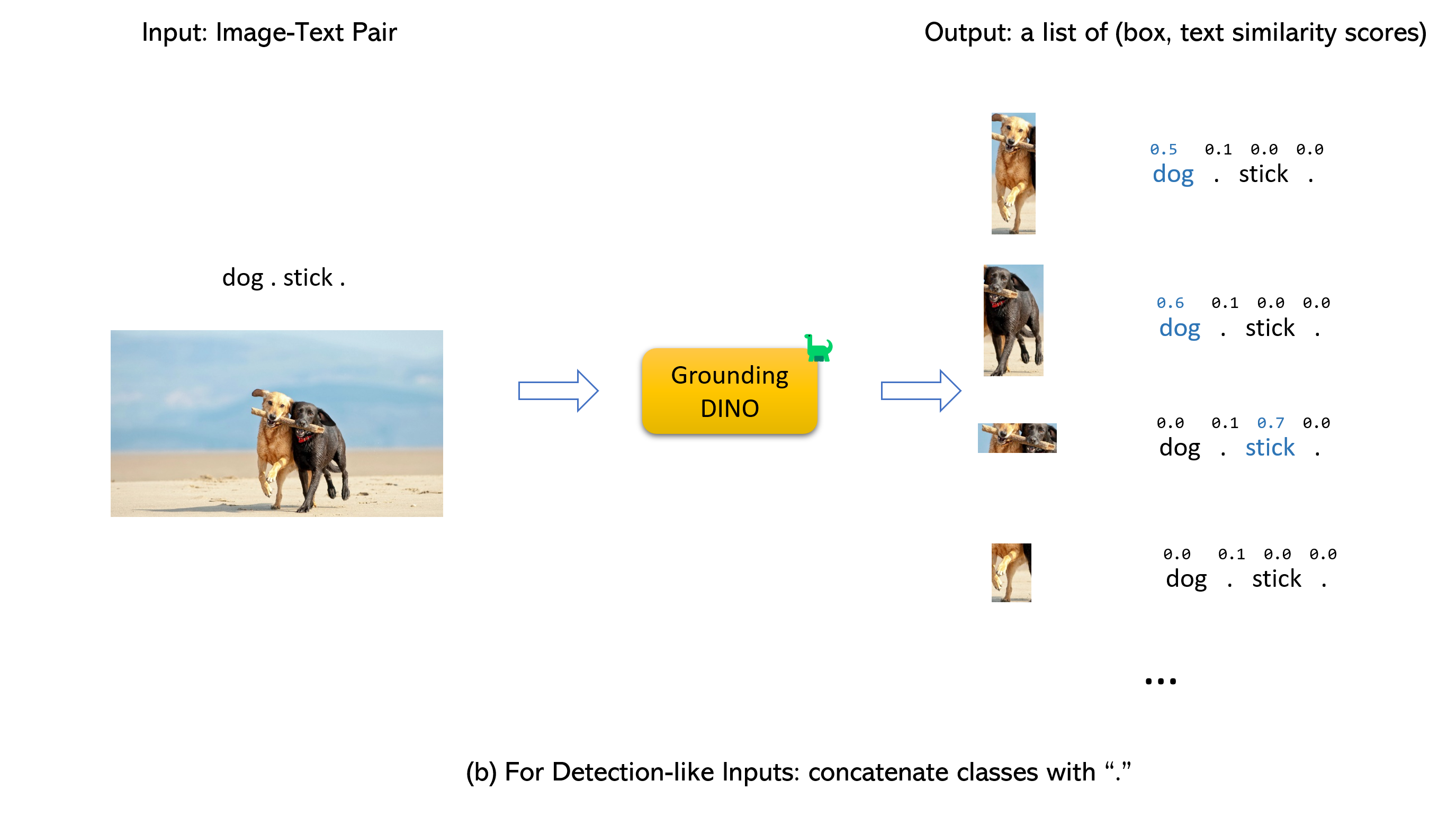
:label: 待办事项
- 发布推理代码和演示。
- 发布检查点。
- Grounding DINO 与 Stable Diffusion 和 GLIGEN 的演示。
- 发布训练代码。
:hammer_and_wrench: 安装
注意:
- 如果你有 CUDA 环境,请确保环境变量
CUDA_HOME已设置。如果没有可用的 CUDA,将在仅 CPU 模式下编译。
请确保严格按照安装步骤进行,否则程序可能会产生:
NameError: name '_C' is not defined
如果发生这种情况,请重新克隆 git 并重新安装 groundingDINO,再次执行所有安装步骤。
如何检查 cuda:
echo $CUDA_HOME
如果没有输出,则表示你还没有设置路径。
运行以下命令,使环境变量在当前 shell 中设置:
export CUDA_HOME=/path/to/cuda-11.3
注意 cuda 的版本应与你的 CUDA 运行时一致,因为可能同时存在多个 cuda 版本。
如果你想永久设置 CUDA_HOME,使用以下命令:
echo 'export CUDA_HOME=/path/to/cuda' >> ~/.bashrc
然后,source bashrc 文件并检查 CUDA_HOME:
source ~/.bashrc echo $CUDA_HOME
在这个例子中,/path/to/cuda-11.3 应替换为你安装 CUDA 工具包的路径。你可以在终端中输入 which nvcc 来找到这个路径:
例如, 如果输出是 /usr/local/cuda/bin/nvcc,那么:
export CUDA_HOME=/usr/local/cuda
安装:
1.从 GitHub 克隆 GroundingDINO 仓库。
git clone https://github.com/IDEA-Research/GroundingDINO.git
- 切换到 GroundingDINO 文件夹。
cd GroundingDINO/
- 在当前目录安装所需依赖。
pip install -e .
- 下载预训练模型权重。
mkdir weights cd weights wget -q https://github.com/IDEA-Research/GroundingDINO/releases/download/v0.1.0-alpha/groundingdino_swint_ogc.pth cd ..
:arrow_forward: 演示
检查你的 GPU ID(仅当你使用 GPU 时)
nvidia-smi
在以下命令中,将 {GPU ID}、image_you_want_to_detect.jpg 和 "dir you want to save the output" 替换为适当的值
CUDA_VISIBLE_DEVICES={GPU ID} python demo/inference_on_a_image.py \ -c groundingdino/config/GroundingDINO_SwinT_OGC.py \ -p weights/groundingdino_swint_ogc.pth \ -i image_you_want_to_detect.jpg \ -o "dir you want to save the output" \ -t "chair" [--cpu-only] # 在 cpu 模式下打开它
如果你想指定要检测的短语,这里有一个演示:
CUDA_VISIBLE_DEVICES={GPU ID} python demo/inference_on_a_image.py \ -c groundingdino/config/GroundingDINO_SwinT_OGC.py \ -p ./groundingdino_swint_ogc.pth \ -i .asset/cat_dog.jpeg \ -o logs/1111 \ -t "There is a cat and a dog in the image ." \ --token_spans "[[[9, 10], [11, 14]], [[19, 20], [21, 24]]]" [--cpu-only] # 在 cpu 模式下打开它
token_spans 指定短语的起始和结束位置。例如,第一个短语是 [[9, 10], [11, 14]]。"There is a cat and a dog in the image ."[9:10] = 'a',"There is a cat and a dog in the image ."[11:14] = 'cat'。因此它指的是短语 a cat。同样,[[19, 20], [21, 24]] 指的是短语 a dog。
更多详情请参见 demo/inference_on_a_image.py。
使用 Python 运行:
from groundingdino.util.inference import load_model, load_image, predict, annotate import cv2 model = load_model("groundingdino/config/GroundingDINO_SwinT_OGC.py", "weights/groundingdino_swint_ogc.pth") IMAGE_PATH = "weights/dog-3.jpeg" TEXT_PROMPT = "chair . person . dog ." BOX_TRESHOLD = 0.35 TEXT_TRESHOLD = 0.25 image_source, image = load_image(IMAGE_PATH) boxes, logits, phrases = predict( model=model, image=image, caption=TEXT_PROMPT, box_threshold=BOX_TRESHOLD, text_threshold=TEXT_TRESHOLD ) annotated_frame = annotate(image_source=image_source, boxes=boxes, logits=logits, phrases=phrases) cv2.imwrite("annotated_image.jpg", annotated_frame)
Web UI
我们还提供了一个演示代码,将 Grounding DINO 与 Gradio Web UI 集成。更多详情请参见文件 demo/gradio_app.py。
笔记本
- 我们发布了 演示,将 Grounding DINO 与 GLIGEN 结合,实现更可控的图像编辑。
- 我们发布了 演示,将 Grounding DINO 与 Stable Diffusion 结合用于图像编辑。
COCO 零样本评估
我们提供了一个示例来评估 Grounding DINO 在 COCO 上的零样本性能。结果应该是 48.5。
CUDA_VISIBLE_DEVICES=0 \ python demo/test_ap_on_coco.py \ -c groundingdino/config/GroundingDINO_SwinT_OGC.py \ -p weights/groundingdino_swint_ogc.pth \ --anno_path /path/to/annoataions/ie/instances_val2017.json \ --image_dir /path/to/imagedir/ie/val2017
:luggage: 检查点
<!-- 插入表格 --> <table> <thead> <tr style="text-align: right;"> <th></th> <th>名称</th> <th>骨干网络</th> <th>数据</th> <th>COCO数据集上的边界框AP</th> <th>检查点</th> <th>配置</th> </tr> </thead> <tbody> <tr> <th>1</th> <td>GroundingDINO-T</td> <td>Swin-T</td> <td>O365,GoldG,Cap4M</td> <td>48.4(零样本)/ 57.2(微调)</td> <td><a href="https://github.com/IDEA-Research/GroundingDINO/releases/download/v0.1.0-alpha/groundingdino_swint_ogc.pth">GitHub链接</a> | <a href="https://huggingface.co/ShilongLiu/GroundingDINO/resolve/main/groundingdino_swint_ogc.pth">HF链接</a></td> <td><a href="https://github.com/IDEA-Research/GroundingDINO/blob/main/groundingdino/config/GroundingDINO_SwinT_OGC.py">链接</a></td> </tr> <tr> <th>2</th> <td>GroundingDINO-B</td> <td>Swin-B</td> <td>COCO,O365,GoldG,Cap4M,OpenImage,ODinW-35,RefCOCO</td> <td>56.7</td> <td><a href="https://github.com/IDEA-Research/GroundingDINO/releases/download/v0.1.0-alpha2/groundingdino_swinb_cogcoor.pth">GitHub链接</a> | <a href="https://huggingface.co/ShilongLiu/GroundingDINO/resolve/main/groundingdino_swinb_cogcoor.pth">HF链接</a> <td><a href="https://github.com/IDEA-Research/GroundingDINO/blob/main/groundingdino/config/GroundingDINO_SwinB_cfg.py">链接</a></td> </tr> </tbody> </table>:medal_military: 结果
<details open> <summary><font size="4"> COCO目标检测结果 </font></summary> <img src="https://yellow-cdn.veclightyear.com/835a84d5/a3f949bf-3819-4685-86ed-3da77b6b480c.png" alt="COCO" width="100%"> </details> <details open> <summary><font size="4"> ODinW目标检测结果 </font></summary> <img src="https://yellow-cdn.veclightyear.com/835a84d5/40e7b73b-4cd3-446d-bd8a-71aba9652349.png" alt="ODinW" width="100%"> </details> <details open> <summary><font size="4"> 将Grounding DINO与<a href="https://github.com/Stability-AI/StableDiffusion">Stable Diffusion</a>结合用于图像编辑 </font></summary> 查看我们的示例<a href="https://github.com/IDEA-Research/GroundingDINO/blob/main/demo/image_editing_with_groundingdino_stablediffusion.ipynb">笔记本</a>以获取更多详细信息。 <img src="https://yellow-cdn.veclightyear.com/835a84d5/5e5bcf26-d367-485d-83b9-814e82b00adb.png" alt="GD_SD" width="100%"> </details> <details open> <summary><font size="4"> 将Grounding DINO与<a href="https://github.com/gligen/GLIGEN">GLIGEN</a>结合用于更详细的图像编辑 </font></summary> 查看我们的示例<a href="https://github.com/IDEA-Research/GroundingDINO/blob/main/demo/image_editing_with_groundingdino_gligen.ipynb">笔记本</a>以获取更多详细信息。 <img src="https://yellow-cdn.veclightyear.com/835a84d5/d202e1a0-eac5-4ca0-9402-07fb5c4e2705.png" alt="GD_GLIGEN" width="100%"> </details>:sauropod: 模型:Grounding DINO
包括:文本骨干网络、图像骨干网络、��特征增强器、语言引导的查询选择和跨模态解码器。
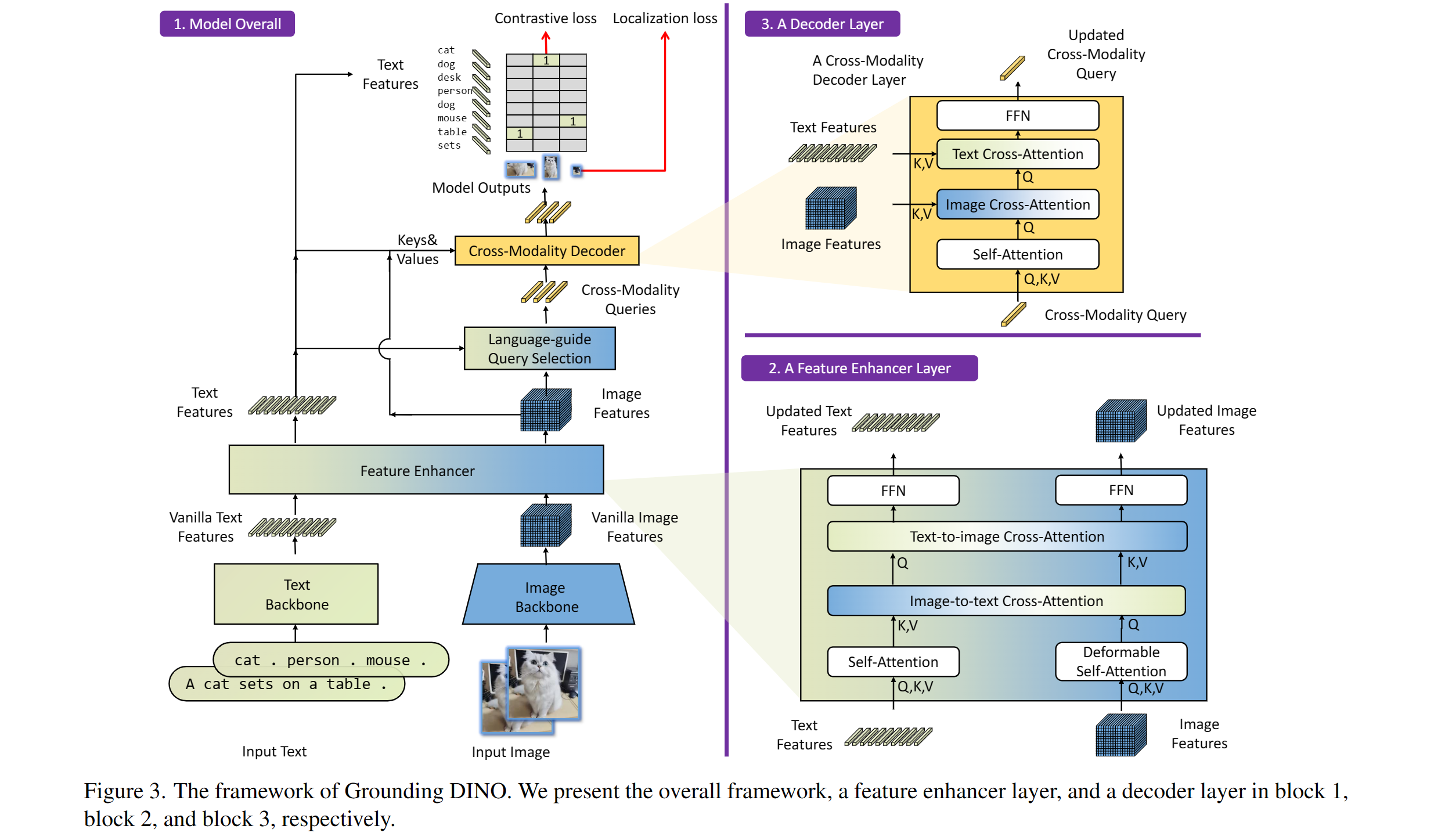
:hearts: 致谢
我们还要感谢以下优秀的前期工作,包括DETR、Deformable DETR、SMCA、Conditional DETR、Anchor DETR、Dynamic DETR、DAB-DETR、DN-DETR等。更多相关工作可在Awesome Detection Transformer中找到。另外还有一个新的工具箱detrex可供使用。
感谢Stable Diffusion和GLIGEN提供的出色模型。
:black_nib: 引用
如果您认为我们的工作对您的研究有帮助,请考虑引用以下BibTeX条目。
@article{liu2023grounding, title={Grounding dino: Marrying dino with grounded pre-training for open-set object detection}, author={Liu, Shilong and Zeng, Zhaoyang and Ren, Tianhe and Li, Feng and Zhang, Hao and Yang, Jie and Li, Chunyuan and Yang, Jianwei and Su, Hang and Zhu, Jun and others}, journal={arXiv preprint arXiv:2303.05499}, year={2023} }
编辑推荐精选


扣子-AI办公
职场AI,就用扣子
AI办公助手,复杂任务高效处理。办公效率低?扣子空间AI助手支持播客�生成、PPT制作、网页开发及报告写作,覆盖科研、商业、舆情等领域的专家Agent 7x24小时响应,生活工作无缝切换,提升50%效率!


堆友
多风格AI绘画神器
堆友平台由阿里巴巴设计团队创建,作为一款AI驱动的设计工具,专为设计师提供一站式增长服务。功能覆盖海量3D素材、AI绘画、实时渲染以及专业抠图,显著提升设计品质和效率。平台不仅提供工具,还是一个促进创意交流和个人发展的空间,界面友好,适合所有级别的设计师和创意工作者。


码上飞
零代码AI应用开发平台
零代码AI应用开发平台,用户只需一句话简单描述需求,AI能自动生成小程序、APP或H5网页应用,无需编写代码。


Vora
免费创建高清无水印Sora视频
Vora是一个免费创建高清无水印Sora视频的AI工具


Refly.AI
最适合小白的AI自动化工作流平台
无需编码,轻松生成可复用、可变现的AI自动化工作流


酷表ChatExcel
大模型驱动的Excel数据处理工具
基于大模型交互的表格处理系统,允许用户通过对话方式完成数据整理和可视化分析。系统采用机器学习算法解析用户指令,自动执行排序、公式计算和数据透视等操作,支持多种文件格式导入导出。数据处理响应速度保持在0.8秒以内,支持超过100万行数据的即时分析。


TRAE编程
AI辅助编程,代码自动修复
Trae是一种自适应的集成开发环境(IDE),通过自动化和多元协作改变开发流程。利用Trae,团队能够更快速、精确地编写和部署代码,从而提高编程效率和项目交付速度。Trae具备上下文感知和代码自动完成功能,是提升开发效率的理想工具。


AIWritePaper论文写作
AI论文写作指导平台
AIWritePaper论文写作是一站式AI论文写作辅助工具,简化了选题、文献检索至论文撰写的整个过程。通过简单设��定,平台可快速生成高质量论文大纲和全文,配合图表、参考文献等一应俱全,同时提供开题报告和答辩PPT等增值服务,保障数据安全,有效提升写作效率和论文质量。


博思AIPPT
AI一键生成PPT,就用博思AIPPT!
博思AIPPT,新一代的AI生成PPT平台,支持智能生成PPT、AI美化PPT、文本&链接生成PPT、导入Word/PDF/Markdown文档生成PPT等,内置海量精美PPT模板,涵盖商务、教育、科技等不同风格,同时针对每个页面提供多种版式,一键自适应切换,完美适配各种办公场景。


潮际好麦
AI赋能电商视觉革命,一站式智能商拍平台
潮际好麦深耕服装行业,是国内AI试衣效果最好的软件。使用先进AIGC能力为电商卖家批量提供优质的、低成本的商拍图。合作品牌有Shein、Lazada、安踏、百丽等65个国内外头部品牌,以及国内10万+淘宝、天猫、京东等主流平台的品牌商家,为卖家节省将近85%的出图成本,提升约3倍出图效率,让品牌能够快速上架。
推荐工具精选




AI云服务特惠
懂AI专属折扣关注微信公众号
最新AI工具、AI资讯
独家AI资源、AI项目落地

微信扫一扫关注公众号