
HugNLP
基于Hugging Face的全�面NLP开发应用框架
HugNLP是基于Hugging Face的NLP开发应用库,为研究人员提供便利高效的开发环境。它集成了丰富的模型、处理器和应用模块,支持知识增强预训练、提示微调、指令调优等技术。该框架还包含参数高效学习、不确定性估计等工具,可用于构建多种NLP应用。HugNLP获得CIKM 2023最佳演示论文奖。







 [[English](https://github.com/HugAILab/HugNLP/blob/main/./README_zh.md]
[[English](https://github.com/HugAILab/HugNLP/blob/main/./README_zh.md]
关于HugNLP
HugNLP是一个基于Hugging Face的新型开发和应用库,旨在提高NLP研究人员的便利性和有效性。
**新闻与亮点
- 🆕 [23-10-25]: 我们的HugNLP论文荣获CIKM 2023最佳演示论文奖!
- 🆕 [23-08-06]: 我们的HugNLP论文已被CIKM 2023接收(演示轨道)!
- 🆕 [23-05-05]: HugNLP在@HugAILab发布!
- 🆕 [23-04-06]: 开发了一个类似ChatGPT的小型助手,命名为HugChat!你可以与HugNLP聊天中提供了原型网络。
此外,我们还在HugNLP中加入了一些即插即用的工具。
- 参数冻结。如果我们想进行参数高效学习,即冻结PLM中的一些参数以提高训练效率,我们可以设置配置
use_freezing并冻结骨干网络。使用示例在代码中展示。 - 不确定性估计旨在计算半监督学习中的模型确定性。
- 我们还设计了预测校准,可以通过校准分布和缓解语义偏差问题来进一步提高准确性。
处理器
处理器旨在加载数据集并在包含句子分词、采样和张量生成的流程中处理任务示例。
具体而言,用户可以通过load_dataset直接获取数据,它可以直接从互联网下载或从本地磁盘加载。
对于不同的任务,用户应定义特定任务的数据整理器,其目的是将原始示例转换为模型输入的张量特征。
应用
它为用户提供了丰富的模块,通过从模型和处理器中选择一系列设置来构建现实世界的应用和产品。
核心能力
我们提供一些核心能力来支持NLP下游应用。
知识增强预训练语言模型
传统的预训练方法缺乏事实知识。 为了解决这个问题,我们提出了KP-PLM,采用新颖的知识提示范式进行知识增强预训练。
具体来说,我们通过识别实体并与知识库对齐为每个输入文本构建一个�知识子图,并将这个子图分解成多个关系路径,这些路径可以直接转换为语言提示。
基于提示的微调
基于提示的微调旨在重用预训练目标(如遮蔽语言建模、因果语言建模),并利用精心设计的模板和词汇器进行预测,在低资源环境下取得了巨大成功。
我们将一些新颖的方法整合到HugNLP中,如PET、P-tuning等。
指令调优与上下文学习
指令调优和上下文学习无需参数更新即可实现少样本/零样本学习,其目标是将任务相关指令或基于示例的演示连接起来,以提示GPT风格的PLM生成可靠的响应。 因此,所有NLP任务可以统一为相同的格式,并能显著提高模型的泛化能力。
受此启发,我们将其扩展为其他两种范式:
- 抽取式范式:我们将各种NLP任务统一为跨度抽取,这与抽取式问答相同。
- 推理式范式:所有任务都可以视为自然语言推理,以匹配输入和输出之间的关系。
- 生成式范式:我们将所有任务统一为生成格式,并基于指令调优、上下文学习或思维链训练因果模型。
基于不确定性估计的自训练
自训练可以通过利用大规模未标注数据和标注数据来解决标注数据稀缺的问题,这是半监督学习中成熟的范式之一。 然而,标准的自训练可能产生太多噪声,不可避免地会由于确认偏差而降低模型性能。
因此,我们提出了基于不确定性的自训练。具体来说,我们在少量标注数据上训练教师模型,然后使用贝叶斯神经网络(BNN)中的蒙特卡洛(MC)丢弃技术来近似模型确定性,并谨慎选择教师模型确定性较高的样本。
参数高效学习
为了提高HugNLP的训练效率,我们还实现了参数高效学习,旨在冻结主干网络中的部分参数,使我们在模型训练过程中只调整��少量参数。 我们开发了一些新颖的参数高效学习方法,如前缀调优、适配器调优、BitFit和LoRA等。
安装
$ git clone https://github.com/HugAILab/HugNLP.git
$ cd HugNLP
$ python3 setup.py install
目前,该项目仍在开发和完善中,使用时可能存在一些bug,请谅解。我们也期待您能提出问题或提交一些有价值的拉取请求。
预构建应用概览
我们展示了HugNLP中的所有预构建应用。您可以选择一个应用来使用HugNLP。您也可以点击链接查看详细文档。
| 应用 | 运行任务 | 任务说明 | PLM模型 | 文档 |
|---|---|---|---|---|
| 默认应用 | run_seq_cls.sh | 目标:在用户自定义数据集上进行序列分类的标准微调或提示调优。<br> 路径:applications/default_applications | BERT、RoBERTa、DeBERTa | [点击](https://github.com/HugAILab/HugNLP/blob/main/./documents/default_tasks/default_sequence_classification.md |
| run_seq_labeling.sh | 目标:在用户自定义数据集上进行序列标注的标准微调。<br> 路径:applications/default_applications | BERT、RoBERTa、ALBERT | ||
| 预训练 | run_pretrain_mlm.sh | 目标:通过掩码语言建模(MLM)进行预训练。<br> 路径:applications/pretraining/ | BERT、RoBERTa | [点击](https://github.com/HugAILab/HugNLP/blob/main/./documents/pretraining/Masked%20LM%20for%20Continual%20Pre-training.md |
| run_pretrain_casual_lm.sh | 目标:通过因果语言建模(CLM)进行预训练。<br> 路径:applications/pretraining | BERT、RoBERTa | [点击](https://github.com/HugAILab/HugNLP/blob/main/./documents/pretraining/Causal%20LM%20for%20Continual%20Pre-training.md | |
| GLUE基准测试 | run_glue.sh | 目标:对GLUE分类任务进行标准微调或提示调优。<br> 路径:applications/benchmark/glue | BERT、RoBERTa、DeBERTa | |
| run_causal_incontext_glue.sh | 目标:对GLUE分类任务进行上下文学习。<br> 路径:applications/benchmark/glue | GPT-2 | ||
| CLUE基准测试 | clue_finetune_dev.sh | 目标:对CLUE分类任务进行标准微调和提示调优。<br> 路径:applications/benchmark/clue | BERT、RoBERTa、DeBERTa | |
| run_clue_cmrc.sh | 目标:对CLUE CMRC2018任务进行标准微调。<br> 路径:applications/benchmark/cluemrc | BERT、RoBERTa、DeBERTa | ||
| run_clue_c3.sh | 目标:对CLUE C3任务进行标准微调。<br> 路径:applications/benchmark/cluemrc | BERT、RoBERTa、DeBERTa | ||
| run_clue_chid.sh | 目标:对CLUE CHID任务进行标准微调。<br> 路径:applications/benchmark/cluemrc | BERT、RoBERTa、DeBERTa | ||
| 指令提示 | run_causal_instruction.sh | 目标:基于因果PLM通过生成式指令调优进行跨任务训练。<font color='red'>你可以用它来训练一个小型ChatGPT</font>。<br> 路径:applications/instruction_prompting/instruction_tuning | GPT2 | [点击](https://github.com/HugAILab/HugNLP/blob/main/./documents/instruction_prompting/generative_instruction_tuning.md |
| run_zh_extract_instruction.sh | 目标:基于全局指针模型通过抽取式指令调优进行跨任务训练。<br> 路径:applications/instruction_prompting/chinese_instruction | BERT、RoBERTa、DeBERTa | [点击](https://github.com/HugAILab/HugNLP/blob/main/./documents/instruction_prompting/extractive_instruction_tuning.md | |
| run_causal_incontext_cls.sh | 目标:对用户自定义分类任务进行上下文学习。<br> 路径:applications/instruction_prompting/incontext_learning | GPT-2 | [点击](https://github.com/HugAILab/HugNLP/blob/main/./documents/instruction_prompting/incontext_learning_for_cls.md | |
| 信息抽取 | run_extractive_unified_ie.sh | 目标:HugIE:通过抽取式指令调优训练统一的中文信息抽取模型。<br> 路径:applications/information_extraction/HugIE | BERT、RoBERTa、DeBERTa | [点击](https://github.com/HugAILab/HugNLP/blob/main/./documents/information_extraction/HugIE.md |
| api_test.py | 目标:HugIE:API测试。<br> 路径:applications/information_extraction/HugIE | - | [点击](https://github.com/HugAILab/HugNLP/blob/main/./documents/information_extraction/HugIE.md | |
| run_fewnerd.sh | 目标:命名实体识别的原型学习,包括SpanProto、TokenProto <br> 路径:applications/information_extraction/fewshot_ner | BERT | ||
| 代码自然语言理解 | run_clone_cls.sh | 目标:代码克隆分类任务的标准微调。<br> 路径:applications/code/code_clone | CodeBERT、CodeT5、GraphCodeBERT、PLBART | [点击](https://github.com/HugAILab/HugNLP/blob/main/./documents/code/code_classification.md |
| run_defect_cls.sh | 目标:代码缺陷分类任务的标准微调。<br> 路径:applications/code/code_defect | CodeBERT、CodeT5、GraphCodeBERT、PLBART | [点击](https://github.com/HugAILab/HugNLP/blob/main/./documents/code/code_classification.md | |
| 有关预构建应用程序和设置以及设计的模型和处理器的更多详细信息,可以在HugNLP文档中找到。 |
快速使用
这里我们提供了一个示例,向您展示如何快速使用HugNLP。
如果您想在用户自定义数据集上执行分类任务,可以在一个目录中准备三个json文件(train.json、dev.json、test.json)。然后您可以运行脚本文件
$ bash ./application/default_applications/run_seq_cls.sh
在实验之前,您必须在脚本文件run_seq_cls.sh中定义以下参数。
- --model_name_or_path: 预训练模型名称或路径。例如bert-base-uncased
- --data_path: 数据集的路径(包括
train.json、dev.json和test.json),例如./datasets/data_example/cls/。 - --user_defined: 如果不存在
label_names.txt,您必须定义label_names。
如果您想使用基于提示的微调,可以添加以下参数:
- --use_prompt_for_cls
- ---task_type:
masked_prompt_cls、masked_prompt_prefix_cls、masked_prompt_ptuning_cls、masked_prompt_adapter_cls中的一个。
您还应该添加template.json和label_words_mapping.json。
如果您想使用参数高效学习,可以添加以下参数:
- --use_freezing
run_seq_cls.sh的示例如下:
path=chinese-macbert-base MODEL_TYPE=bert data_path=/wjn/frameworks/HugNLP/datasets/data_example/cls TASK_TYPE=head_cls len=196 bz=4 epoch=10 eval_step=50 wr_step=10 lr=1e-05 export CUDA_VISIBLE_DEVICES=0,1 python3 -m torch.distributed.launch --nproc_per_node=2 --master_port=6014 hugnlp_runner.py \ --model_name_or_path=$path \ --data_dir=$data_path \ --output_dir=./outputs/default/sequence_classification\ --seed=42 \ --exp_name=default-cls \ --max_seq_length=$len \ --max_eval_seq_length=$len \ --do_train \ --do_eval \ --do_predict \ --per_device_train_batch_size=$bz \ --per_device_eval_batch_size=4 \ --gradient_accumulation_steps=1 \ --evaluation_strategy=steps \ --learning_rate=$lr \ --num_train_epochs=$epoch \ --logging_steps=100000000 \ --eval_steps=$eval_step \ --save_steps=$eval_step \ --save_total_limit=1 \ --warmup_steps=$wr_step \ --load_best_model_at_end \ --report_to=none \ --task_name=default_cls \ --task_type=$TASK_TYPE \ --model_type=$MODEL_TYPE \ --metric_for_best_model=acc \ --pad_to_max_length=True \ --remove_unused_columns=False \ --overwrite_output_dir \ --fp16 \ --label_names=labels \ --keep_predict_labels \ --user_defined="label_names=entailment,neutral,contradiction"
快速开发
本节面向开发者。 HugNLP易于使用和开发。我们在下图中绘制了一个工作流程,展示如何开发一个新的运行任务。
<p align="center"> <br> <img src="https://yellow-cdn.veclightyear.com/0a4dffa0/5e8d4fe4-f0e4-481f-a106-d82f0e097a3a.png" width="90%"/> <br> </p> 它包括五个主要步骤:库安装、数据准备、处理器选择或设计、模型选择或设计以及应用设计。 这说明HugNLP可以简化复杂NLP模型和任务的实现。预构建产品
这里,我们展示两个预构建API应用的示例。
HugChat: 面向ChatGPT类PLMs的生成式指令调优
HugChat是一个小型ChatGPT类模型,基于生成式指令调优,旨在将所有NLP任务统一为生成式格式,以训练因果语言模型(如GPT2、BART)。 您可以直接使用HugNLP进行指令调优,并在用户定义的特定任务语料上持续训练小型ChatGPT风格模型。
您可以通过运行以下命令与HugChat聊天:
$ python3 applications/instruction_prompting/HugChat/hugchat.py
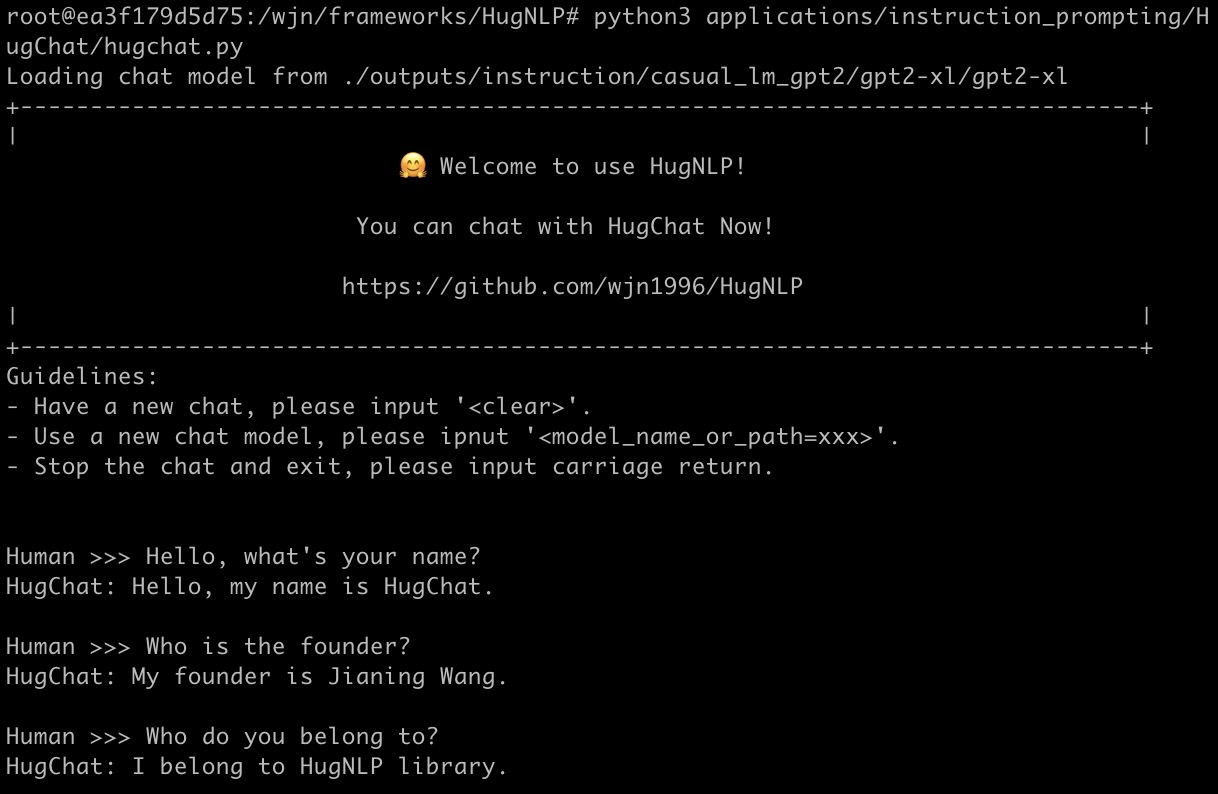
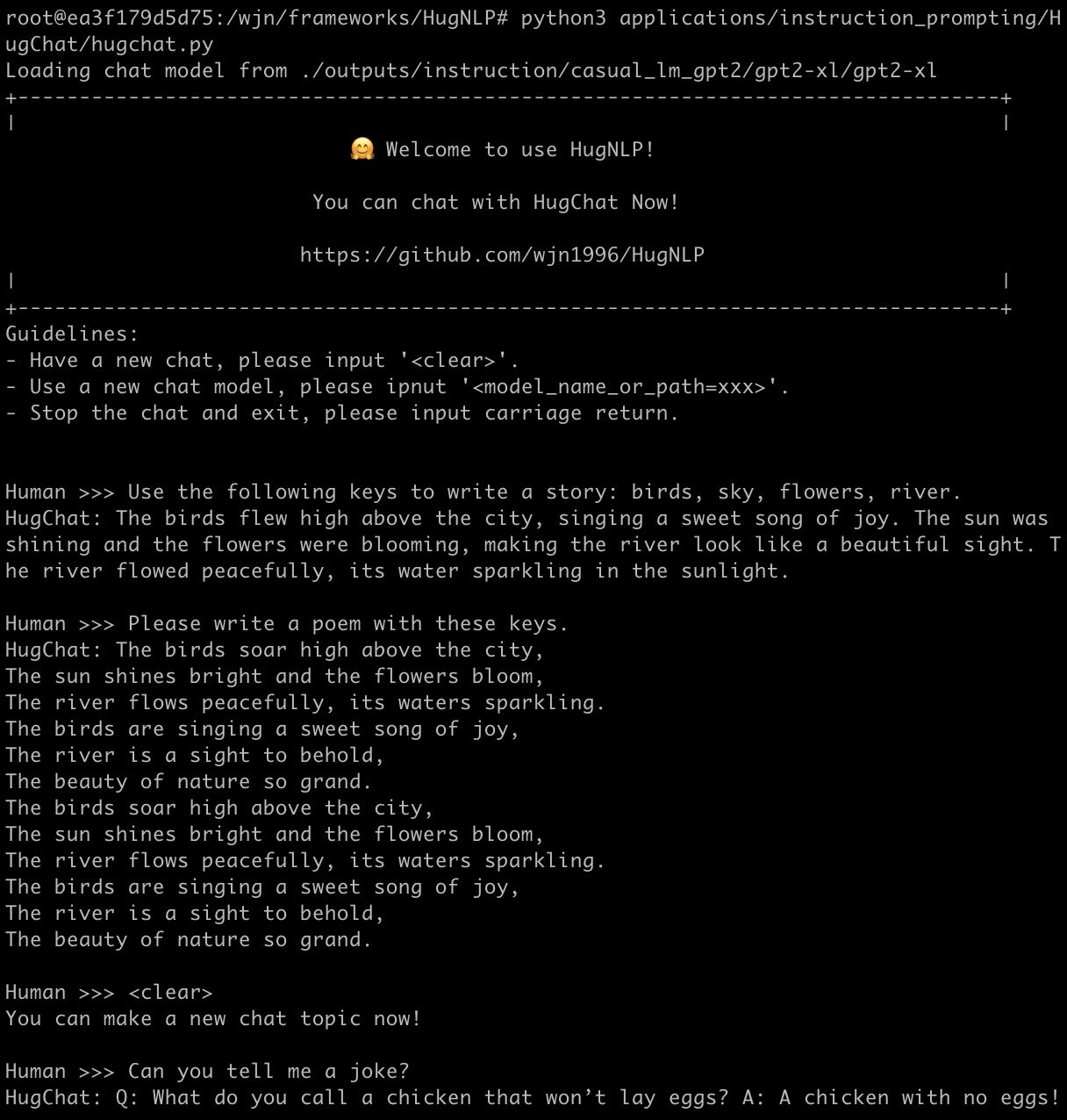
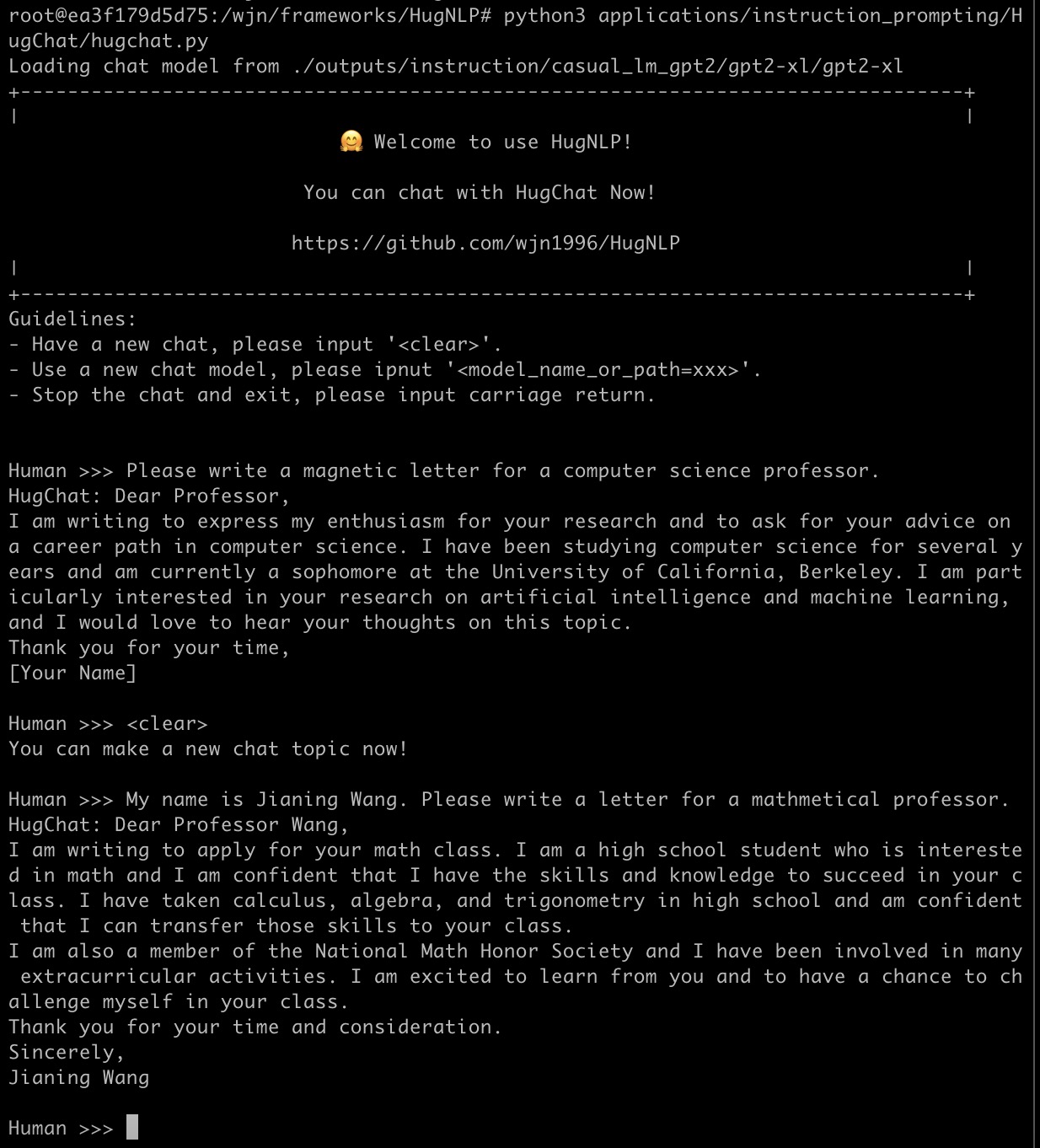
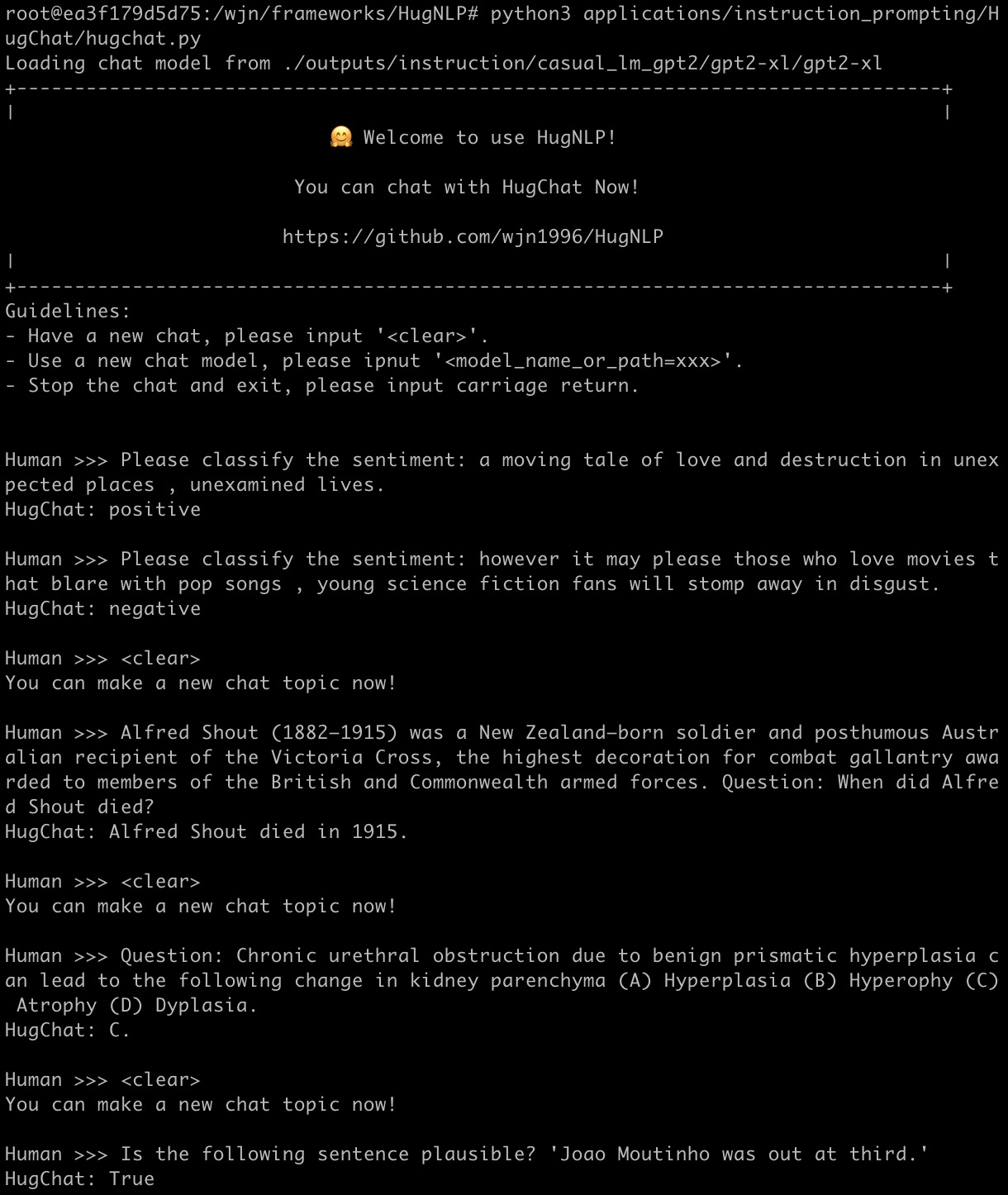
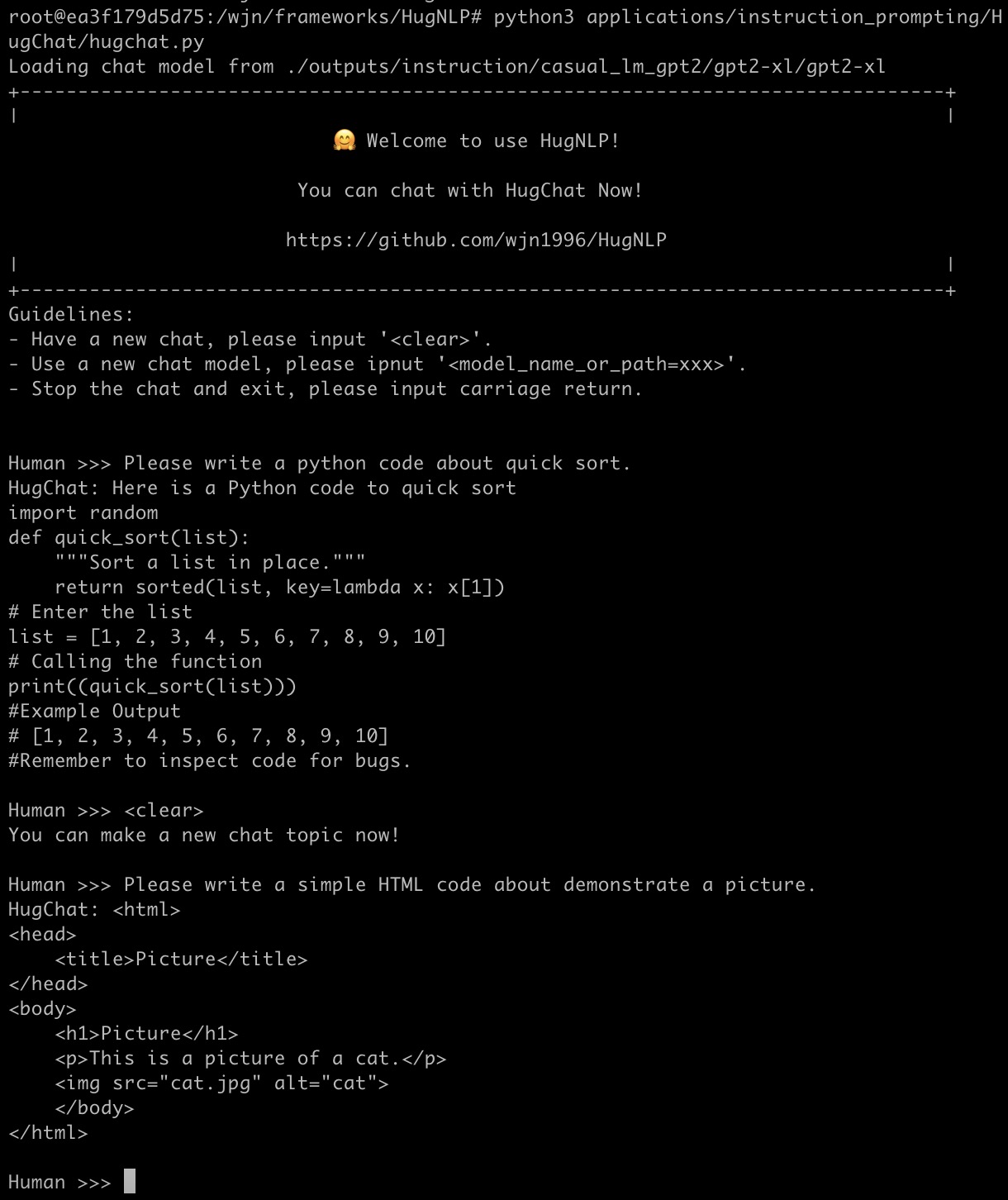
请尽情享受,更多详情可以在这里找到。
HugIE: 面向中文统一信息抽取的抽取式阅读理解和指令调优方法
信息抽取(IE)旨在从非结构化文本中提取结构化知识。结构化知识以"(头实体,关系,尾实体)"三元组的形式呈现。IE主要包括两个任务:
- 命名实体识别(NER)旨在提取某一类型的所有实体提及。
- 关系抽取(RE)。它有两种目标,第一种是对两个实体之间的关系进行分类,第二种是在给定头实体和相应关系的情况下预测尾实体。
- 我们将NER和RE任务统一到抽取式问答(即机器阅读理解)的范式中。
- 我们为NER和RE设计了特定任务的指令和语言提示。
对于NER任务:
- 指令:"找到文章中所有【{entity_type}】类型的实体?文章:【{passage_text}】"
对于RE任务:
- 指令:"找到文章中【{head_entity}】的【{relation}】?文章:【{passage_text}】"
- 在训练过程中,我们使用以Chinese-Macbert为基础的全局指针作为基本模型。
我们的模型保存在Hugging Face: https://huggingface.co/wjn1996/wjn1996-hugnlp-hugie-large-zh。
快速使用HugIE进行中文信息抽取:
from applications.information_extraction.HugIE.api_test import HugIEAPI model_type = "bert" hugie_model_name_or_path = "wjn1996/wjn1996-hugnlp-hugie-large-zh" hugie = HugIEAPI("bert", hugie_model_name_or_path) text = "央广网北京2月23日消息 据中国地震台网正式测定,2月23日8时37分在塔吉克斯坦发生7.2级地震,震源深度10公里,震中位于北纬37.98度,东经73.29度,距我国边境线最近约82公里,地震造成新疆喀什等地震感强烈。" entity = "塔吉克斯坦地震" relation = "震源位置" predictions, topk_predictions = hugie.request(text, entity, relation=relation) print("entity:{}, relation:{}".format(entity, relation)) print("predictions:\n{}".format(predictions)) print("topk_predictions:\n{}".format(predictions)) print("\n\n") """ # 事件信息输出结果: entity:塔吉克斯坦地震, relation:震源位置 predictions: {0: ["10公里", "距我国边境线最近约82公里", "北纬37.98度,东经73.29度", "北纬37.98度,东经73.29度,距我国边境线最近约82公里"]} topk_predictions: {0: [{"answer": "10公里", "prob": 0.9895901083946228, "pos": [(80, 84)]}, {"answer": "距我国边境线最近约82公里", "prob": 0.8584909439086914, "pos": [(107, 120)]}, {"answer": "北纬37.98度,东经73.29度", "prob": 0.7202121615409851, "pos": [(89, 106)]}, {"answer": "北纬37.98度,东经73.29度,距我国边境线最近约82公里", "prob": 0.11628123372793198, "pos": [(89, 120)]}]} """ entity = "塔吉克斯坦地震" relation = "时间" predictions, topk_predictions = hugie.request(text, entity, relation=relation) print("entity:{}, relation:{}".format(entity, relation)) print("predictions:\n{}".format(predictions)) print("topk_predictions:\n{}".format(predictions)) print("\n\n") """ # 事件信息输出结果: entity:塔吉克斯坦地震, relation:时间 predictions: {0: ["2月23日8时37分"]} topk_predictions: {0: [{"answer": "2月23日8时37分", "prob": 0.9999995231628418, "pos": [(49, 59)]}]} """
贡献者
<a href="https://github.com/HugAILab/HugNLP/graphs/contributors"> <img src="https://contrib.rocks/image?repo=HugAILab/HugNLP" /> </a>联系我们
如果您有任何问题或建议,可以加入钉钉互动群:
<p align="center"> <br> <img src="https://yellow-cdn.veclightyear.com/0a4dffa0/9dadeb48-f471-4c98-896a-f36de6e3328f.jpg" width="250"/> <br> </p>或者您可以联系作者王嘉宁。
引用
如果您觉得这个仓库有帮助,欢迎引用我们的论文:
@misc{wang2023hugnlp, doi = {10.48550/ARXIV.2302.14286}, url = {https://arxiv.org/abs/2302.14286}, author = {王嘉宁, 陈诺, 孙秋实, 黄文康, 王成玉, 高明}, title = {HugNLP: 一个统一和全面的自然语言处理库}, year = {2023} }
参考文献
- 王嘉宁, 陈诺, 孙秋实, 黄文康, 王成玉, 高明: HugNLP: 一个统一和全面的自然语言处理库。CoRR abs/2302.14286 (2023)
- 王嘉宁, 黄文康, 邱明辉, 石秋辉, 王洪斌, 李翔, 高明: 在预训练语言模型中使用知识提示进行自然语言理解。EMNLP 2022: 3164-3177
- 王成玉, 王嘉宁, 邱明辉, 黄俊, 高明: TransPrompt: 面向少样本文本分类的自动可转移提示框架。EMNLP 2021: 2792-2802
- 王嘉宁, 王成玉, 黄俊, 高明, 周傲英: 基于不确定性感知的自训练方法用于低资源神经序列标注。AAAI 2023.
- 陈诺, 孙秋实, 朱仁宇, 李翔, 陆雪松, 高明: CAT-probing: 一种基于度量的方法来解释预训练编程语言模型如何关注代码结构。EMNLP 2022 Findings: 4000--4008
致谢
我们感谢阿里巴巴集团和蚂蚁集团的人工智能平台(PAI)对我们工作的支持。友好的框架是EasyNLP。我们还要感谢所有为我们的工作做出贡献的开发者!
编辑推荐精选


音述AI
全球首个AI音乐社区
音述AI是全球首个AI音乐社区,致力让每个人都能用音乐表达自我。音述AI提供零门槛AI创作工具,独创GETI法则帮助用户精准定义音乐风格,AI润色功能支持自动优化作品质感。音述AI支持交流讨论、二次创作与价值变现。针对中文用户的语言习惯与文化背景进行专门优化,支持国风融合、C-pop等本土音乐标签,让技术更好地承载人文表达。


QoderWork
阿里Qoder团队推出的桌面端AI智能体
QoderWork 是阿里推出的本地优先桌面 AI 智能体,适配 macOS14+/Windows10+,以自然语言交互实现文件管理、数据分析、AI 视觉生成、浏览器自动化等办公任务,自主拆解执行复杂工作流,数据本地运行零上传,技能市场可无限扩展,是高效的 Agentic 生产力办公助手。


lynote.ai
一站式搞定所有学习需求
不再被海量信息淹没,开始真正理解知识。Lynote 可摘要 YouTube 视频、PDF、文章等内容。即时创建笔记,检测 AI 内容并下载资料,将您的学习效率提升 10 倍。


AniShort
为AI短剧协作而生
专为AI短剧协作而生的AniShort正式发布,深度重构AI短剧全流程生产模式,整合创意策划、制作执行、实时协作、在线审片、资产复用等全链路功能,独创无限画布、双轨并行��工业化工作流与Ani智能体助手,集成多款主流AI大模型,破解素材零散、版本混乱、沟通低效等行业痛点,助力3人团队效率提升800%,打造标准化、可追溯的AI短剧量产体系,是AI短剧团队协同创作、提升制作效率的核心工具。


seedancetwo2.0
能听懂你表达的视频模型
Seedance two是基于seedance2.0的中国大模型,支持图像、视频、音频、文本四种模态输入,表达方式更丰富,生成也更可控。


nano-banana纳米香蕉中文站
国内直接访问,限时3折
输入简单文字,生成想要的图片,纳米香蕉中文站基于 Google 模型的 AI 图片生成网站,支持文字生图、图生图。官网价格限时3折活动


扣子-AI办公
职场AI,就用扣子
AI办公助手,复杂任务高效处理。办公效率低?扣子空间AI助手支持播客生成、PPT制作、网页开发及报告写作,覆盖科研、商业、舆情等领域的专家Agent 7x24小时响应,生活工作无缝切换,提升50%效率!


堆友
多风格AI绘画神器
堆友平台由阿里巴巴设计团队创建,作为一款AI驱动的设计工具,专为设计师提供一站式增长服务。功能覆盖海量3D素材、AI绘画、实时渲染以及专业抠图,显著提升设计品质和效率。平台不仅提供工具,还��是一个促进创意交流和个人发展的空间,界面友好,适合所有级别的设计师和创意工作者。


码上飞
零代码AI应用开发平台
零代码AI应用开发平台,用户只需一句话简单描述需求,AI能自动生成小程序、APP或H5网页应用,无需编写代码。


Vora
免费创建高清无水印Sora视频
Vora是一个免费创建高清无水印Sora视频的AI工具
推荐工具精选





AI云服务特惠
懂AI专属折扣关注微信公众号
最新AI工具、AI资讯
独家AI资源、AI项目落地

微信扫一扫关注公众号