
clean-fid
准确评估生成模型的标准化指标库
clean-fid是一个用于评估生成模型的开源工具库,致力于解决FID计算中的不一致问题。通过精确处理图像重采样和压缩等细节,该库确保了不同方法、论文和团队之间FID分数的可比性。clean-fid支持计算FID和KID指标,提供多个常用数据集的预计算统计数据,操作简便。它旨在为生成模型评估提供标准化和可靠的解决方案,提高了评估结果的准确性和可重复性。





clean-fid for Evaluating Generative Models
<br> <p align="center"> <img src="https://raw.githubusercontent.com/GaParmar/clean-fid/main/docs/images/cleanfid_demo_folders.gif" /> </p>
Project | Paper | Slides | Colab-FID | Colab-Resize | Leaderboard Tables <br> Quick start: Calculate FID | Calculate KID
[New] Computing the FID using CLIP features [Kynkäänniemi et al, 2022] is now supported. See here for more details.
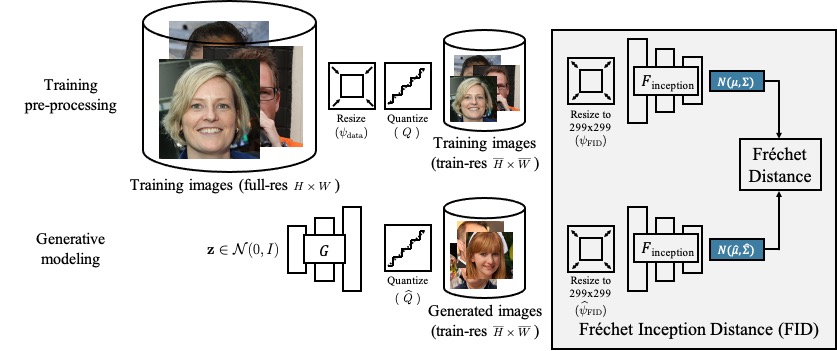
The FID calculation involves many steps that can produce inconsistencies in the final metric. As shown below, different implementations use different low-level image quantization and resizing functions, the latter of which are often implemented incorrectly.
<p align="center"> <img src="https://raw.githubusercontent.com/GaParmar/clean-fid/main/docs/images/resize_circle.png" width="800" /> </p>We provide an easy-to-use library to address the above issues and make the FID scores comparable across different methods, papers, and groups.
Corresponding Manuscript
On Aliased Resizing and Surprising Subtleties in GAN Evaluation <br> Gaurav Parmar, Richard Zhang, Jun-Yan Zhu<br> CVPR, 2022 <br> CMU and Adobe
If you find this repository useful for your research, please cite the following work.
@inproceedings{parmar2021cleanfid,
title={On Aliased Resizing and Surprising Subtleties in GAN Evaluation},
author={Parmar, Gaurav and Zhang, Richard and Zhu, Jun-Yan},
booktitle={CVPR},
year={2022}
}
<br>
Aliased Resizing Operations <br>
The definitions of resizing functions are mathematical and <em>should never be a function of the library being used</em>. Unfortunately, implementations differ across commonly-used libraries. They are often implemented incorrectly by popular libraries. Try out the different resizing implementations in the Google colab notebook here.
<img src="https://raw.githubusercontent.com/GaParmar/clean-fid/main/docs/images/resize_circle_extended.png" width="800" /> <br>The inconsistencies among implementations can have a drastic effect of the evaluations metrics. The table below shows that FFHQ dataset images resized with bicubic implementation from other libraries (OpenCV, PyTorch, TensorFlow, OpenCV) have a large FID score (≥ 6) when compared to the same images resized with the correctly implemented PIL-bicubic filter. Other correctly implemented filters from PIL (Lanczos, bilinear, box) all result in relatively smaller FID score (≤ 0.75). Note that since TF 2.0, the new flag antialias (default: False) can produce results close to PIL. However, it was not used in the existing TF-FID repo and set as False by default.
JPEG Image Compression
Image compression can have a surprisingly large effect on FID. Images are perceptually indistinguishable from each other but have a large FID score. The FID scores under the images are calculated between all FFHQ images saved using the corresponding JPEG format and the PNG format.
<p align="center"> <img src="https://raw.githubusercontent.com/GaParmar/clean-fid/main/docs/images/jpeg_effects.png" width="800" /> </p>Below, we study the effect of JPEG compression for StyleGAN2 models trained on the FFHQ dataset (left) and LSUN outdoor Church dataset (right). Note that LSUN dataset images were collected with JPEG compression (quality 75), whereas FFHQ images were collected as PNG. Interestingly, for LSUN dataset, the best FID score (3.48) is obtained when the generated images are compressed with JPEG quality 87.
<p align="center"> <img src="https://raw.githubusercontent.com/GaParmar/clean-fid/main/docs/images/jpeg_plots.png" width="800" /> </p>Quick Start
- install the library
pip install clean-fid
Computing FID
- Compute FID between two image folders
from cleanfid import fid score = fid.compute_fid(fdir1, fdir2) - Compute FID between one folder of images and pre-computed datasets statistics (e.g.,
FFHQ)from cleanfid import fid score = fid.compute_fid(fdir1, dataset_name="FFHQ", dataset_res=1024, dataset_split="trainval70k") - Compute FID using a generative model and pre-computed dataset statistics:
from cleanfid import fid # function that accepts a latent and returns an image in range[0,255] gen = lambda z: GAN(latent=z, ... , <other_flags>) score = fid.compute_fid(gen=gen, dataset_name="FFHQ", dataset_res=256, num_gen=50_000, dataset_split="trainval70k")
Computing CLIP-FID
To use the CLIP features when computing the FID [Kynkäänniemi et al, 2022], specify the flag model_name="clip_vit_b_32"
- e.g. to compute the CLIP-FID between two folders of images use the following commands.
from cleanfid import fid score = fid.compute_fid(fdir1, fdir2, mode="clean", model_name="clip_vit_b_32")
Computing KID
The KID score can be computed using a similar interface as FID.
The dataset statistics for KID are only precomputed for smaller datasets AFHQ, BreCaHAD, and MetFaces.
- Compute KID between two image folders
from cleanfid import fid score = fid.compute_kid(fdir1, fdir2) - Compute KID between one folder of images and pre-computed datasets statistics
from cleanfid import fid score = fid.compute_kid(fdir1, dataset_name="brecahad", dataset_res=512, dataset_split="train") - Compute KID using a generative model and pre-computed dataset statistics:
from cleanfid import fid # function that accepts a latent and returns an image in range[0,255] gen = lambda z: GAN(latent=z, ... , <other_flags>) score = fid.compute_kid(gen=gen, dataset_name="brecahad", dataset_res=512, num_gen=50_000, dataset_split="train")
Supported Precomputed Datasets
We provide precompute statistics for the following commonly used configurations. Please contact us if you want to add statistics for your new datasets.
| Task | Dataset | Resolution | Reference Split | # Reference Images | mode |
|---|---|---|---|---|---|
| Image Generation | cifar10 | 32 | train | 50,000 | clean, legacy_tensorflow, legacy_pytorch |
| Image Generation | cifar10 | 32 | test | 10,000 | clean, legacy_tensorflow, legacy_pytorch |
| Image Generation | ffhq | 1024, 256 | trainval | 50,000 | clean, legacy_tensorflow, legacy_pytorch |
| Image Generation | ffhq | 1024, 256 | trainval70k | 70,000 | clean, legacy_tensorflow, legacy_pytorch |
| Image Generation | lsun_church | 256 | train | 50,000 | clean, legacy_tensorflow, legacy_pytorch |
| Image Generation | lsun_church | 256 | trainfull | 126,227 | clean |
| Image Generation | lsun_horse | 256 | train | 50,000 | clean, legacy_tensorflow, legacy_pytorch |
| Image Generation | lsun_horse | 256 | trainfull | 2,000,340 | clean |
| Image Generation | lsun_cat | 256 | train | 50,000 | clean, legacy_tensorflow, legacy_pytorch |
| Image Generation | lsun_cat | 256 | trainfull | 1,657,264 | clean, legacy_tensorflow, legacy_pytorch |
| Few Shot Generation | afhq_cat | 512 | train | 5153 | clean, legacy_tensorflow, legacy_pytorch |
| Few Shot Generation | afhq_dog | 512 | train | 4739 | clean, legacy_tensorflow, legacy_pytorch |
| Few Shot Generation | afhq_wild | 512 | train | 4738 | clean, legacy_tensorflow, legacy_pytorch |
| Few Shot Generation | brecahad | 512 | train | 1944 | clean, legacy_tensorflow, legacy_pytorch |
| Few Shot Generation | metfaces | 1024 | train | 1336 | clean, legacy_tensorflow, legacy_pytorch |
| Image to Image | horse2zebra | 256 | test | 140 | clean, legacy_tensorflow, legacy_pytorch |
| Image to Image | cat2dog | 256 | test | 500 | clean, legacy_tensorflow, legacy_pytorch |
Using precomputed statistics In order to compute the FID score with the precomputed dataset statistics, use the corresponding options. For instance, to compute the clean-fid score on generated 256x256 FFHQ images use the command:
fid_score = fid.compute_fid(fdir1, dataset_name="ffhq", dataset_res=256, mode="clean", dataset_split="trainval70k")
Create Custom Dataset Statistics
-
dataset_path: folder where the dataset images are stored
-
custom_name: name to be used for the statistics
-
Generating custom statistics (saved to local cache)
from cleanfid import fid fid.make_custom_stats(custom_name, dataset_path, mode="clean") -
Using the generated custom statistics
from cleanfid import fid score = fid.compute_fid("folder_fake", dataset_name=custom_name, mode="clean", dataset_split="custom") -
Removing the custom stats
from cleanfid import fid fid.remove_custom_stats(custom_name, mode="clean") -
Check if a custom statistic already exists
from cleanfid import fid fid.test_stats_exists(custom_name, mode)
Backwards Compatibility
We provide two flags to reproduce the legacy FID score.
-
mode="legacy_pytorch"<br> This flag is equivalent to using the popular PyTorch FID implementation provided here <br> The difference between using clean-fid with this option and code is ~2e-06 <br> See doc for how the methods are compared -
mode="legacy_tensorflow"<br> This flag is equivalent to using the official implementation of FID released by the authors. <br> The difference between using clean-fid with this option and code is ~2e-05 <br> See doc for detailed steps for how the methods are compared
Building clean-fid locally from source
python setup.py bdist_wheel
pip install dist/*
CleanFID Leaderboard for common tasks
We compute the FID scores using the corresponding methods used in the original papers and using the Clean-FID proposed here. All values are computed using 10 evaluation runs. We provide an API to query the results shown in the tables below directly from the pip package.
If you would like to add new numbers and models to our leaderboard, feel free to contact us.
CIFAR-10 (few shot)
The test set is used as the reference distribution and compared to 10k generated images.
100% data (unconditional)
| Model | Legacy-FID<br>(reported) | Legacy-FID<br>(reproduced) | Clean-FID |
|---|---|---|---|
| stylegan2 (+ada + tuning) [Karras et al, 2020] | - † | - † | 8.20 ± 0.10 |
| stylegan2 (+ada) [Karras et al, 2020] | - † | - † | 9.26 ± 0.06 |
| stylegan2 (diff-augment) [Zhao et al, 2020] [ckpt] | 9.89 | 9.90 ± 0.09 | 10.85 ± 0.10 |
| stylegan2 (mirror-flips) [Karras et al, 2020] [ckpt] | 11.07 | 11.07 ± 0.10 | 12.96 ± 0.07 |
| stylegan2 (without-flips) [Karras et al, 2020] | - † | - † | 14.53 ± 0.13 |
| AutoGAN (config A) [Gong et al, 2019] | - † | - † | 21.18 ± 0.12 |
| AutoGAN (config B) [[Gong et al, |
编辑推荐精选


音述AI
全球首个AI音乐社区
音述AI是全球首个AI音乐社区,致力让每个人都能用音乐表达自我。音述AI提供零门槛AI创作工具,独创GETI法则帮助用户精准定义音乐风格,AI润色功能支持自动优化作品质感。音述AI支持交流讨论、二次创作与价值变现。针对中文用户的语言习惯与文化背景进行专门优化,支持国风融合、C-pop等本土音乐标签,让技术更好地承载人文表达。


lynote.ai
一站式搞定所有学习需求
不再被海量信息淹没,开始真正理解知识。Lynote 可摘要 YouTube 视频、PDF、文章等内容。即时创建笔记,检测 AI 内容并下载资料,将您的学习效率提升 10 倍。


AniShort
为AI短剧协作而生
专为AI短剧协作而生的AniShort正式发布,深度重构AI短剧全流程生产模式,整合创意策划、制作执行、实时协作、在线审片、资产复用等全链路功能,独创无限画布、双轨并行工业化工作流与Ani智能体助手,集成多款主流AI大模型,破解素材零散、版本混乱、沟通低效等行业痛点,助力3人团队效率提升800%,打造标准化、可追溯的AI短剧量产体系,是AI短剧团队协同创作、提升制作效率的核心工具。


seedancetwo2.0
能听懂你表达的视频模型
Seedance two是基于seedance2.0的中国大模型,支持图像、视频、音频、文本四种模态输入,表达方式更丰富,生成也更可控。


nano-banana纳米香蕉中文站
国内直接访问,限时3折
输入简单文字,生成想要的图片,纳米香蕉中文站基于 Google 模型的 AI 图片生成网站,支持文字生图、图生图。官网价格限时3折活动


扣子-AI办公
职场AI,就用扣子
AI办公助手,复杂任务高效处理。办公效率低?扣子空间AI助手支持播客生成、PPT制作、网页开发及报告写作,覆盖科研、商业、舆情等领域的专家Agent 7x24小时响应,生活工作无缝切换,提升50%效率!


堆友
多风格AI绘画神器
堆友平台由阿里巴巴设计团队创建,作为一款AI驱动的设计工具,专为设计师提供一站式增长服务。功能覆盖海量3D素材、AI绘画、实时渲染以及专业抠图,显著提升设计品质和效率。平台不仅提供工具,还是一个促进创意交流和个人发展的空间,界面友好,适合所有级别的设计师和创意工作者。


码上飞
零代码AI应用开发平台
零代码AI应用开发平台,用户只需一句话简单描述需求,AI能自动生成小程序、APP或H5网页应用,无需编写代码。


Vora
免费创建高清无水印Sora视频
Vora是一个免费创建高清无水印Sora视频的AI工具


Refly.AI
最适合小白的AI自动化工作流平台
无需编码,轻松生成可复用、可变现的AI自动化工作流
推荐工具精选





AI云服务特惠
懂AI专属折扣关注微信公众号
最新AI工具、AI资讯
独家AI资源、AI项目落地

微信扫一扫关注公众号