



FlashAttention
本仓库提供了以下论文中 FlashAttention 和 FlashAttention-2 的官方实现。
FlashAttention: 具有 IO 感知的快速且内存高效的精确注意力机制
Tri Dao, Daniel Y. Fu, Stefano Ermon, Atri Rudra, Christopher Ré
论文:https://arxiv.org/abs/2205.14135
IEEE Spectrum 关于我们使用 FlashAttention 提交 MLPerf 2.0 基准测试的文章。
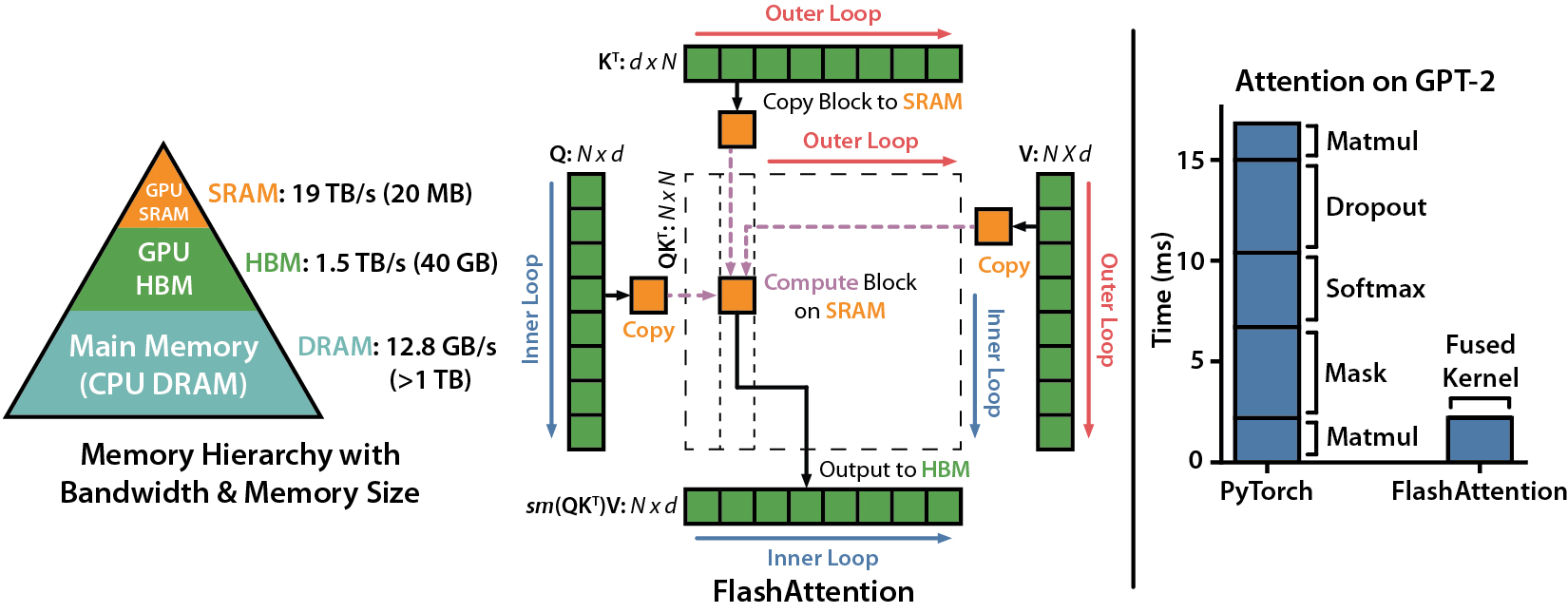
FlashAttention-2: 更快的注意力机制,具有更好的并行性和工作分区
Tri Dao
论文:https://tridao.me/publications/flash2/flash2.pdf

使用情况
我们很高兴看到 FlashAttention 在发布后短时间内被广泛采用。这个页面包含了 FlashAttention 被使用的部分列表。
FlashAttention 和 FlashAttention-2 可以免费使用和修改(参见 LICENSE)。如果您使用它,请引用并致谢 FlashAttention。
FlashAttention-3 beta 版本发布
FlashAttention-3 针对 Hopper GPU(如 H100)进行了优化。
博客文章:https://tridao.me/blog/2024/flash3/
论文:https://tridao.me/publications/flash3/flash3.pdf
这是一个 beta 版本,用于在我们将其与仓库其他部分集成之前进行测试/��基准测试。
目前发布的内容:
- FP16 前向和后向传播
即将在未来几天/下周发布:
- BF16
- 可变长度(FP16,BF16)
- FP8 前向传播
要求:H100 / H800 GPU,CUDA >= 12.3。
安装方法:
cd hopper python setup.py install
运行测试:
export PYTHONPATH=$PWD pytest -q -s test_flash_attn.py
安装和功能
要求:
- CUDA 工具包或 ROCm 工具包
- PyTorch 1.12 及以上版本
packagingPython 包(pip install packaging)ninjaPython 包(pip install ninja)*- Linux。从 v2.3.2 开始可能适用于 Windows(我们看到了一些正面报告),但 Windows 编译仍需更多测试。如果您有关于如何为 Windows 设置预构建 CUDA wheels 的想法,请通过 GitHub issue 联系我们。
* 确保正确安装并运行 ninja(例如,ninja --version 然后 echo $? 应返回退出码 0)。如果不是(有时 ninja --version 然后 echo $? 返回非零退出码),请卸载然后重新安装 ninja(pip uninstall -y ninja && pip install ninja)。没有 ninja,编译可能需要很长时间(2小时),因为它不使用多个 CPU 核心。使用 ninja 在 64 核机器上使用 CUDA 工具包编译需要 3-5 分钟。
安装方法:
pip install flash-attn --no-build-isolation
或者您可以从源代码编译:
python setup.py install
如果您的机器 RAM 少于 96GB 且有很多 CPU 核心,ninja 可能会运行太多并行编译作业,可能耗尽 RAM。要限制并行编译作业的数量,您可以设置环境变量 MAX_JOBS:
MAX_JOBS=4 pip install flash-attn --no-build-isolation
接口: src/flash_attention_interface.py
NVIDIA CUDA 支持
要求:
- CUDA 11.6 及以上版本
我们推荐使用 Nvidia 的 Pytorch 容器,它包含安装 FlashAttention 所需的所有工具。
FlashAttention-2 与 CUDA 目前支持:
- Ampere、Ada 或 Hopper GPU(例如 A100、RTX 3090、RTX 4090、H100)。Turing GPU(T4、RTX 2080)的支持即将推出,目前请对 Turing GPU 使用 FlashAttention 1.x。
- fp16 和 bf16 数据类型(bf16 需要 Ampere、Ada 或 Hopper GPU)。
- 所有头维度最高到 256。
头维度 > 192 的反向传播需要 A100/A800 或 H100/H800。从 flash-attn 2.5.5 开始,头维度 256 的反向传播现在可以在消费级 GPU 上工作(如果没有 dropout)。
AMD ROCm 支持
ROCm 版本使用 composable_kernel 作为后端。它提供了 FlashAttention-2 的实现。
要求:
- ROCm 6.0 及以上版本
我们推荐使用 ROCm 的 Pytorch 容器,它包含安装 FlashAttention 所需的所有工具。
FlashAttention-2 与 ROCm 目前支持:
- MI200 或 MI300 GPU。
- fp16 和 bf16 数据类型
- 前向传播的头维度最高到 256。反向传播的头维度最高到 128。
如何使用 FlashAttention
主要函数实现了缩放点积注意力(softmax(Q @ K^T * softmax_scale) @ V):
from flash_attn import flash_attn_qkvpacked_func, flash_attn_func
flash_attn_qkvpacked_func(qkv, dropout_p=0.0, softmax_scale=None, causal=False, window_size=(-1, -1), alibi_slopes=None, deterministic=False): """在评估时 dropout_p 应设置为 0.0 如果 Q、K、V 已经堆叠成一个张量,这个函数比在 Q、K、V 上调用 flash_attn_func 更快, 因为反向传播避免了 Q、K、V 梯度的显式连接。 如果 window_size != (-1, -1),实现滑动窗口局部注意力。位置 i 的查询 只会关注 [i - window_size[0], i + window_size[1]] 范围内的键。 参数: qkv: (batch_size, seqlen, 3, nheads, headdim) dropout_p: float。dropout 概率。 softmax_scale: float。应用 softmax 之前 QK^T 的缩放。 默认为 1 / sqrt(headdim)。 causal: bool�。是否应用因果注意力掩码(例如,用于自回归建模)。 window_size: (left, right)。如果不是 (-1, -1),实现滑动窗口局部注意力。 alibi_slopes: (nheads,) 或 (batch_size, nheads),fp32。 在查询 i 和键 j 的注意力分数上添加 (-alibi_slope * |i - j|) 的偏置。 deterministic: bool。是否使用确定性实现的反向传播, 稍微慢一些并使用更多内存。前向传播总是确定性的。 返回: out: (batch_size, seqlen, nheads, headdim)。 """
flash_attn_func(q, k, v, dropout_p=0.0, softmax_scale=None, causal=False, window_size=(-1, -1), alibi_slopes=None, deterministic=False): """在评估时 dropout_p 应设置为 0.0 通过传入头数少于 Q 的 KV 支持多查询和分组查询注意力(MQA/GQA)。 注意,Q 中的头数必须能被 KV 中的头数整除。 例如,如果 Q 有 6 个头,K、V 有 2 个头,Q 的头 0、1、2 将关注 K、V 的头 0, Q 的头 3、4、5 将关注 K、V 的头 1。 如果 window_size != (-1, -1),实现滑动窗口局部注意力。位置 i 的查询 只会关注 [i + seqlen_k - seqlen_q - window_size[0], i + seqlen_k - seqlen_q + window_size[1]] 范围内的键。 参数: q: (batch_size, seqlen, nheads, headdim) k: (batch_size, seqlen, nheads_k, headdim) v: (batch_size, seqlen, nheads_k, headdim) dropout_p: float。dropout 概率。 softmax_scale: float。应用 softmax 之前 QK^T 的缩放。 默认为 1 / sqrt(headdim)。 causal: bool。是否应用因果注意力掩码(例如,用于自回归建模)。 window_size: (left, right)。如果不是 (-1, -1),实现滑动窗口局部注意力。 alibi_slopes: (nheads,) 或 (batch_size, nheads),fp32。 在查询 i 和键 j 的注意力分数上添加 (-alibi_slope * |i + seqlen_k - seqlen_q - j|) 的偏置。 deterministic: bool。是否使用确定性实现的反向传播, 稍微慢一些并使用更多内存。前向传播总是确定性的。 返回: out: (batch_size, seqlen, nheads, headdim)。 """
def flash_attn_with_kvcache( q, k_cache, v_cache, k=None, v=None, rotary_cos=None, rotary_sin=None, cache_seqlens: Optional[Union[(int, torch.Tensor)]] = None, cache_batch_idx: Optional[torch.Tensor] = None, block_table: Optional[torch.Tensor] = None, softmax_scale=None, causal=False, window_size=(-1, -1), # -1 表示无限上下文窗口 rotary_interleaved=True, alibi_slopes=None, ): """ 如果 k 和 v 不为 None,k_cache 和 v_cache 将会被 k 和 v 中的新值*原地*更新。这对增量解码很有用: 你可以传入上一步缓存的键/值,用当前步骤的新键/值更新它们,并在一个内核中对更新后的缓存进行注意力计算。 如果你传入 k / v,你必须确保缓存足够大以容纳新值。例如,KV 缓存可以预先分配最大序列长度, 你可以使用 cache_seqlens 来跟踪批次中每个序列的当前序列长度。 如果传入了 rotary_cos 和 rotary_sin,还会应用旋转嵌入。键 @k 将在索引 cache_seqlens、cache_seqlens + 1 等处被 rotary_cos 和 rotary_sin 旋转。 如果是因果的或局部的(即 window_size != (-1, -1)),查询 @q 将在索引 cache_seqlens、cache_seqlens + 1 等处被 rotary_cos 和 rotary_sin 旋转。 如果既不是因果的也不是局部的,查询 @q 将仅在索引 cache_seqlens 处被 rotary_cos 和 rotary_sin 旋转(即我们认为 @q 中的所有 token 都位于 cache_seqlens 位置)。 参见 tests/test_flash_attn.py::test_flash_attn_kvcache 了解如何使用此函数的示例。 通过传入比 Q 更少头数的 KV 来支持多查询和分组查询注意力(MQA/GQA)。注意,Q 中的头数必须能被 KV 中的头数整除。 例如,如果 Q 有 6 个头而 K、V 有 2 个头,Q 的头 0、1、2 将注意 K、V 的头 0,Q 的头 3、4、5 将注意 K、V 的头 1。 如果 causal=True,因果掩码将对齐到注意力矩阵的右下角。 例如,如果 seqlen_q = 2 且 seqlen_k = 5,因果掩码(1 = 保留,0 = 屏蔽)为: 1 1 1 1 0 1 1 1 1 1 如果 seqlen_q = 5 且 seqlen_k = 2,因果掩码为: 0 0 0 0 0 0 1 0 1 1 如果掩码的一行全为零,输出将为零。 如果 window_size != (-1, -1),实现滑动窗口局部注意力。位置 i 的查询将只注意 [i + seqlen_k - seqlen_q - window_size[0], i + seqlen_k - seqlen_q + window_size[1]] 范围内的键(包括边界)。 注意:不支持反向传播。 参数: q: (batch_size, seqlen, nheads, headdim) k_cache: 如果没有 block_table,形状为 (batch_size_cache, seqlen_cache, nheads_k, headdim), 如果有 block_table(即分页 KV 缓存),形状为 (num_blocks, page_block_size, nheads_k, headdim) page_block_size 必须是 256 的倍数。 v_cache: 如果没有 block_table,形状为 (batch_size_cache, seqlen_cache, nheads_k, headdim), 如果有 block_table(即分页 KV 缓存),形状为 (num_blocks, page_block_size, nheads_k, headdim) k [可选]: (batch_size, seqlen_new, nheads_k, headdim)。如果不为 None,我们将 k 与 k_cache 连接, 从 cache_seqlens 指定的索引开始。 v [可选]: (batch_size, seqlen_new, nheads_k, headdim)。与 k 类似。 rotary_cos [可选]: (seqlen_ro, rotary_dim / 2)。如果不为 None,我们对 k 和 q 应用旋转嵌入。 仅在传入 k 和 v 时适用。rotary_dim 必须能被 16 整除。 rotary_sin [可选]: (seqlen_ro, rotary_dim / 2)。与 rotary_cos 类似。 cache_seqlens: int 或 (batch_size,),dtype torch.int32。KV 缓存的序列长度。 block_table [可选]: (batch_size, max_num_blocks_per_seq),dtype torch.int32。 cache_batch_idx: (batch_size,),dtype torch.int32。用于索引 KV 缓存的索引。 如果为 None,我们假设批次索引为 [0, 1, 2, ..., batch_size - 1]。 如果索引不是唯一的,且提供了 k 和 v,更新到缓存的值可能来自任何重复的索引。 softmax_scale: float。在应用 softmax 之前对 QK^T 的缩放。 默认为 1 / sqrt(headdim)。 causal: bool。是否应用因果注意力掩码(例如,用于自回归建模)。 window_size: (left, right)。如果不是 (-1, -1),实现滑动窗口局部注意力。 rotary_interleaved: bool。仅在传入 rotary_cos 和 rotary_sin 时适用。 如果为 True,旋转嵌入将组合维度 0 & 1,2 & 3 等。如果为 False, 旋转嵌入将组合维度 0 & rotary_dim / 2,1 & rotary_dim / 2 + 1 (即 GPT-NeoX 风格)。 alibi_slopes: (nheads,) 或 (batch_size, nheads),fp32。 一个偏置 (-alibi_slope * |i + seqlen_k - seqlen_q - j|) 被添加到查询 i 和键 j 的注意力分数中。 返回: out: (batch_size, seqlen, nheads, headdim)。 """
要查看这些函数如何在多头注意力层中使用(包括 QKV 投影、输出投影),请参见 MHA 实现。
更新日志
2.0:完全重写,速度提升 2 倍
从 FlashAttention (1.x) 升级到 FlashAttention-2
这些函数已被重命名:
flash_attn_unpadded_func->flash_attn_varlen_funcflash_attn_unpadded_qkvpacked_func->flash_attn_varlen_qkvpacked_funcflash_attn_unpadded_kvpacked_func->flash_attn_varlen_kvpacked_func
如果同一批次中的输入具有相同的序列长度,使用这些函数更简单快速:
flash_attn_qkvpacked_func(qkv, dropout_p=0.0, softmax_scale=None, causal=False)
flash_attn_func(q, k, v, dropout_p=0.0, softmax_scale=None, causal=False)
2.1:更改 causal 标志的行为
如果 seqlen_q != seqlen_k 且 causal=True,因果掩码将对齐到注意力矩阵的右下角,而不是左上角。
例如,如果 seqlen_q = 2 且 seqlen_k = 5,因果掩码(1 = 保留,0 = 屏蔽)为:
v2.0:
1 0 0 0 0
1 1 0 0 0
v2.1:
1 1 1 1 0
1 1 1 1 1
如果 seqlen_q = 5 且 seqlen_k = 2,因果掩码为:
v2.0:
1 0
1 1
1 1
1 1
1 1
v2.1:
0 0
0 0
0 0
1 0
1 1
如果掩码的一行全为零,输出将为零。
2.2:优化推理
优化推理(迭代解码)当查询具有非常小的序列长度时(例如,查询序列长度 = 1)。这里的瓶颈是尽可能快地加载 KV 缓存,我们将加载分散到不同的线程块中,并使用单独的内核来合并结果。
查看具有更多推理特性的函数 flash_attn_with_kvcache(执行旋转嵌入,原地更新 KV 缓存)。
感谢 xformers 团队,特别是 Daniel Haziza,对这次合作的贡献。
2.3:局部(即滑动窗口)注意力
实现滑动窗口注意力(即局部注意力)。感谢 Mistral AI 特别是 Timothée Lacroix 的这项贡献。滑动窗口在 Mistral 7B 模型中得到了应用。
2.4:ALiBi(带线性偏置的注意力),确定性反向传播。
实现 ALiBi(Press 等人,2021)。感谢来自 Kakao Brain 的 Sanghun Cho 的这项贡献。
实现确定性反向传播。感谢来自美团的工程师们的这项贡献。
2.5:分页 KV 缓存。
支持分页 KV 缓存(即 PagedAttention)。 感谢 @beginlner 的这项贡献。
2.6:软上限。
支持带软上限的注意力,如 Gemma-2 和 Grok 模型中使用的。 感谢 @Narsil 和 @lucidrains 的这项贡献。
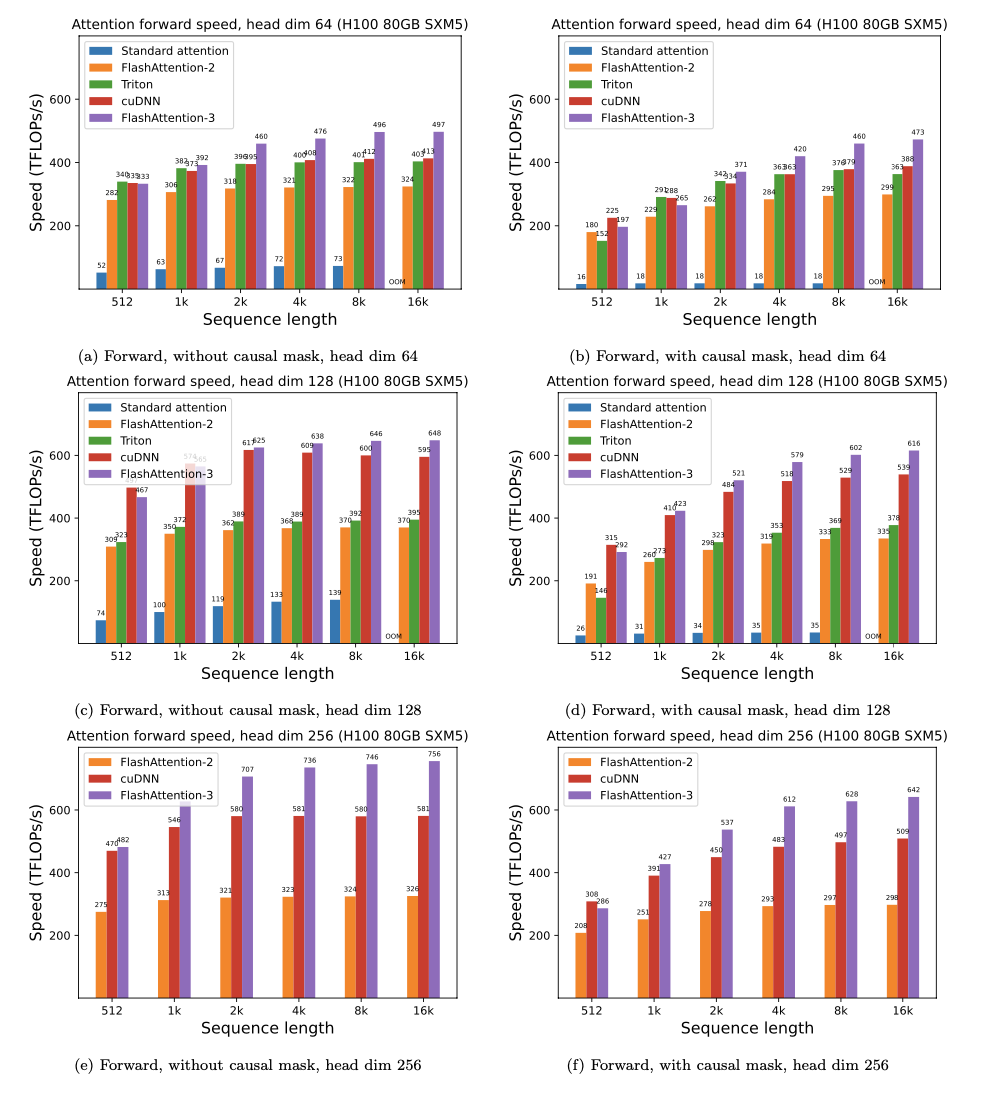
性能
我们展示了使用FlashAttention相对于PyTorch标准注意力机制在不同序列长度和GPU上的预期加速(正向 + 反向传播组合)和内存节省情况(加速取决于内存带宽 - 我们在较慢的GPU内存上看到更多加速)。
目前我们有以下GPU的基准测试:
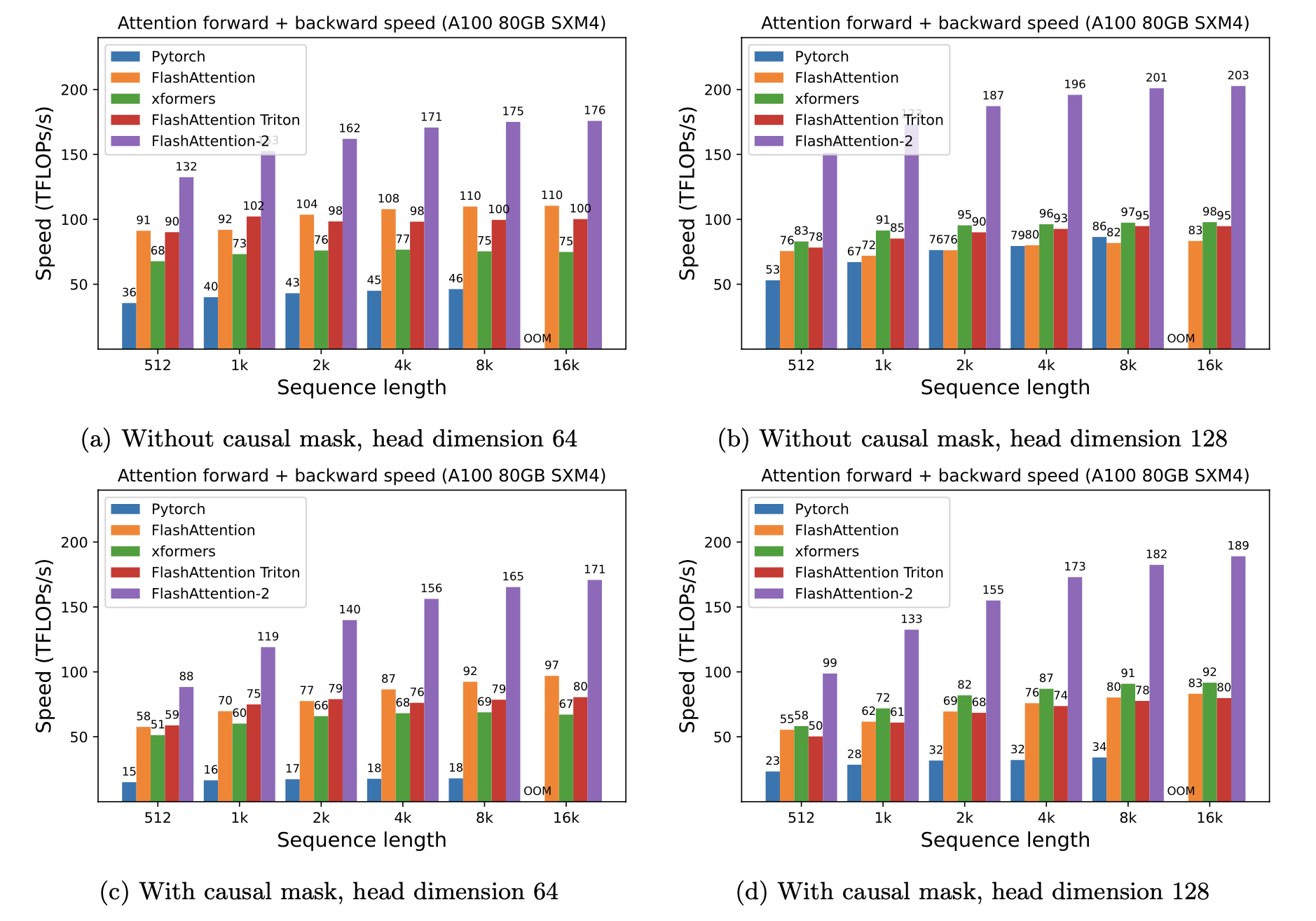
A100
我们使用以下参数展示FlashAttention的加速:
- 头部维度64或128,隐藏维度2048(即32或16个头)。
- 序列长度512、1k、2k、4k、8k、16k。
- 批量大小设置为16k / 序列长度。
加速
内存
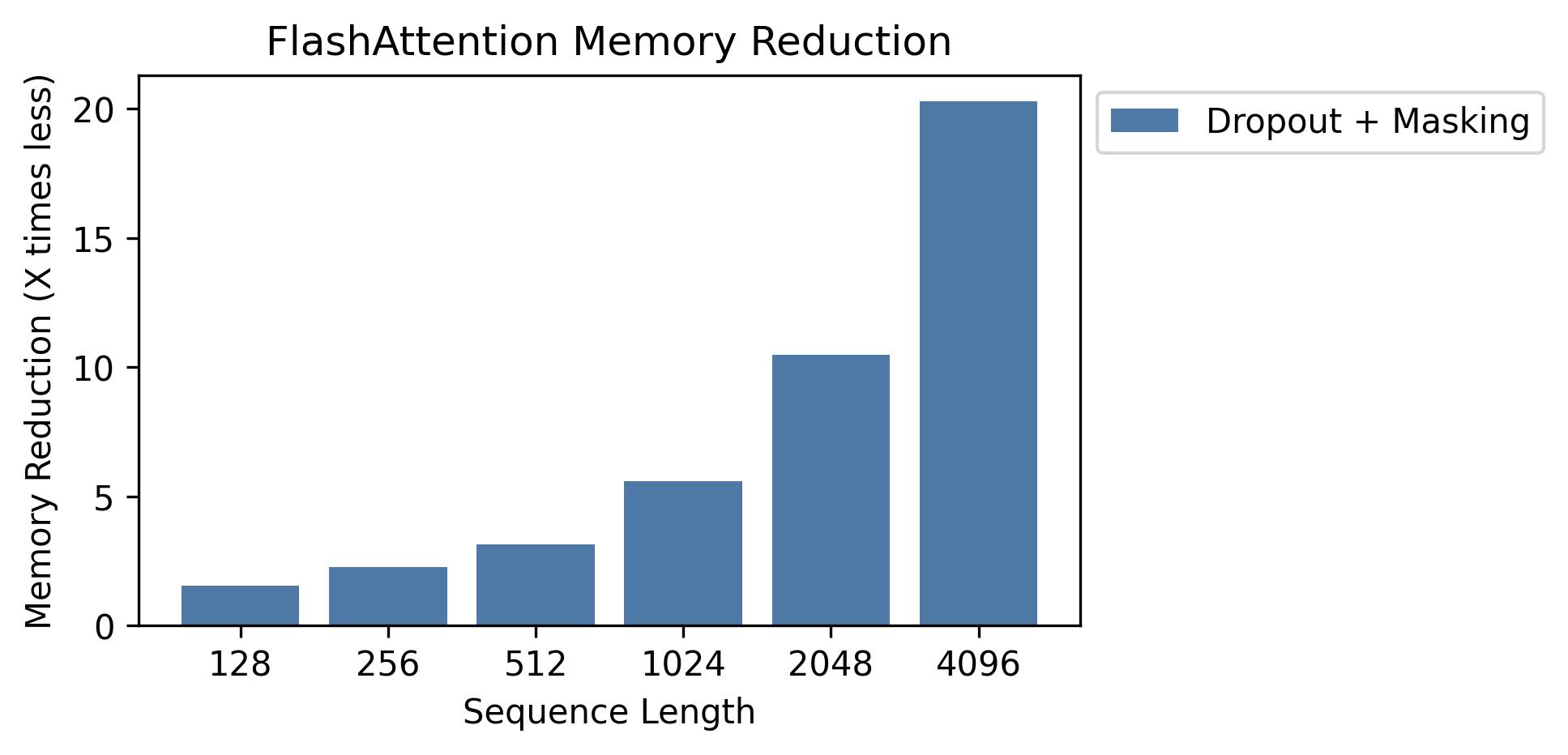
我们在此图中展示了内存节省情况(注意,无论是否使用dropout或掩码,内存占用都相同)。 内存节省与序列长度成正比 -- 因为标准注意力的内存与序列长度呈二次方关系,而FlashAttention的内存与序列长度呈线性关系。 在序列长度为2K时,我们看到10倍的内存节省,在4K时为20倍。 因此,FlashAttention可以扩展到更长的序列长度。
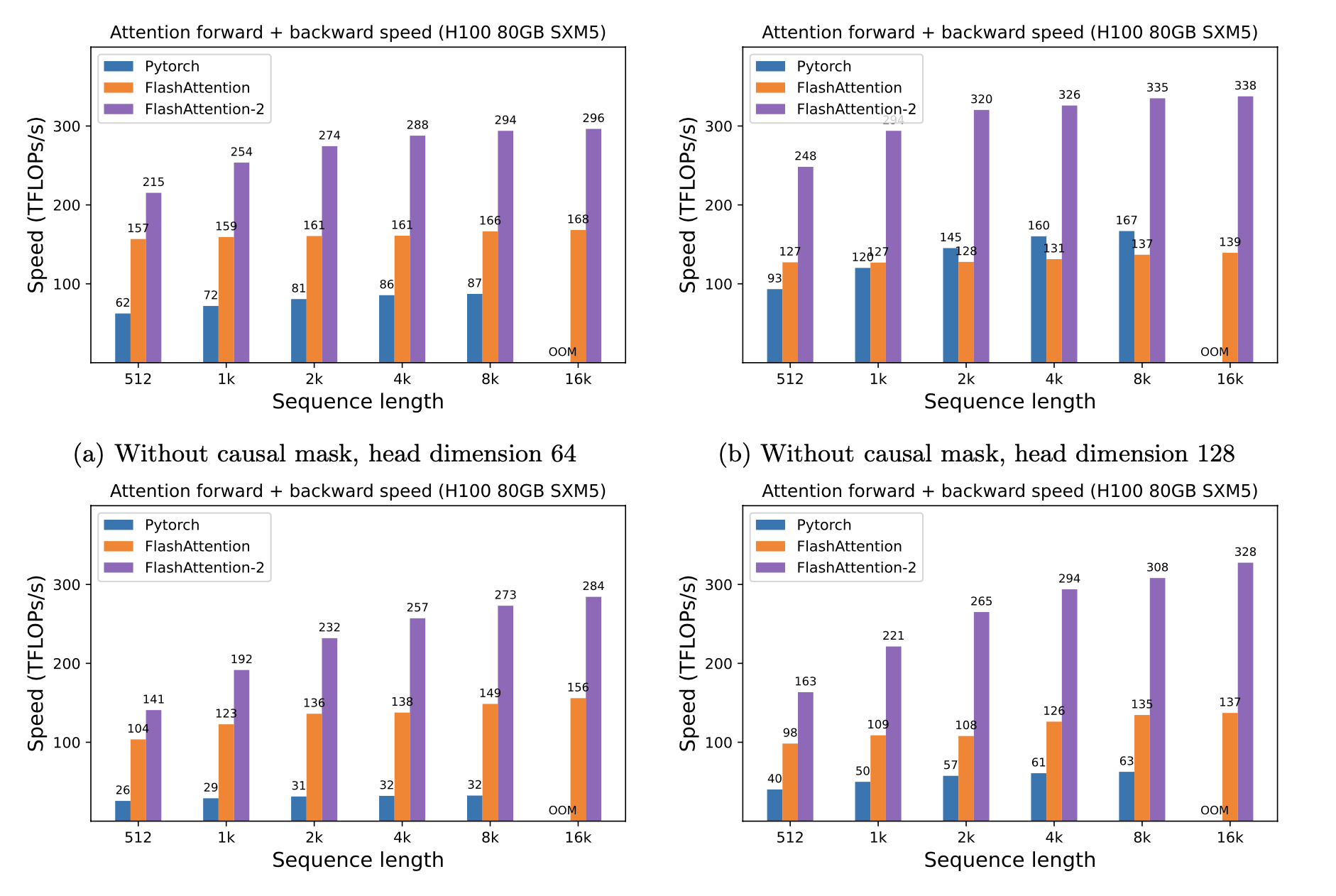
H100
完整模型代码和训练脚本
我们已发布完整的GPT模型实现。 我们还提供了其他层的优化实现(如MLP、LayerNorm、交叉熵损失、旋转嵌入)。总体上,与Huggingface的基线实现相比,这使训练速度提高了3-5倍,在每个A100上达到225 TFLOPs/秒,相当于72%的模型FLOPs利用率(我们不需要任何激活检查点)。
我们还包含了一个训练脚本,用于在Openwebtext上训练GPT2和在The Pile上训练GPT3。
FlashAttention的Triton实现
Phil Tillet(OpenAI)有一个FlashAttention在Triton中的实验性实现: https://github.com/openai/triton/blob/master/python/tutorials/06-fused-attention.py
由于Triton是比CUDA更高级的语言,可能更容易理解和实验。Triton实现中使用的符号也更接近我们论文中使用的符号。
我们还有一个支持注意力偏置(如ALiBi)的Triton实验性实现: https://github.com/Dao-AILab/flash-attention/blob/main/flash_attn/flash_attn_triton.py
测试
我们测试FlashAttention是否在一定数值容差范围内产生与参考实现相同的输出和梯度。特别是,我们检查FlashAttention的最大数值误差是否最多为Pytorch基线实现数值误差的两倍(对于不同的头部维度、输入数据类型、序列长度、因果/非因果)。
运行测试:
pytest -q -s tests/test_flash_attn.py
遇到问题时
FlashAttention-2的这个新版本已在几个GPT风格的模型上进行了测试,主要在A100 GPU上。
如果遇到错误,请开启GitHub问题!
测试
运行测试:
pytest tests/test_flash_attn_ck.py
引用
如果您使用此代码库,或者认为我们的工作有价值,请引用:
@inproceedings{dao2022flashattention,
title={Flash{A}ttention: Fast and Memory-Efficient Exact Attention with {IO}-Awareness},
author={Dao, Tri and Fu, Daniel Y. and Ermon, Stefano and Rudra, Atri and R{\'e}, Christopher},
booktitle={Advances in Neural Information Processing Systems (NeurIPS)},
year={2022}
}
@inproceedings{dao2023flashattention2,
title={Flash{A}ttention-2: Faster Attention with Better Parallelism and Work Partitioning},
author={Dao, Tri},
booktitle={International Conference on Learning Representations (ICLR)},
year={2024}
}
编辑推荐精选


音述AI
全球首个AI音乐社区
音述AI是全球首个AI音乐社区,致力让每个人都能用音乐表达自我。音述AI提供零门槛AI创作工具,独创GETI法则帮助用户精准定义音乐风格,AI润色功能支持自动优化作品质感。音述AI支持交流讨论、二次创作与价值变现。针对中文用户的语言习惯与文化背景进行专门优化,支持国风融合、C-pop等本土音乐标签�,让技术更好地承载人文表达。


QoderWork
阿里Qoder团队推出的桌面端AI智能体
QoderWork 是阿里推出的本地优先桌面 AI 智能体,适配 macOS14+/Windows10+,以自然语言交互实现文件管理、数据分析、AI 视觉生成、浏览器自动化等办公任务,自主拆解执行复杂工作流,数据本地运行零上传,技能市场可无限扩展,是高效的 Agentic 生产力办公助手。


lynote.ai
一站式搞定所有学习需求
不再被海量信息淹没,开始真正理解知识。Lynote 可摘要 YouTube 视频、PDF、文章等内容。即时创建笔记,检测 AI 内容并下载资料,将您的学习效率提升 10 倍。


AniShort
为AI短剧协作而生
专为AI短剧协作而生的AniShort正式发布,深度重构AI短剧全流程生产模式,整合创意策划、制作执行、实时协作、在线审片、资产复用等全链路功能,独创无限画布、双轨并行工业化工作流与Ani智能体助手,集成多款主流AI大模型,破解素材零散、版本混乱、沟通低效等行业痛点,助力3人团队效率提升800%,打造标准化、可追溯的AI短剧量产体系,是AI短剧团队协同创作、提升制作效率的核心工具。


seedancetwo2.0
能听懂你表达的视频模型
Seedance two是基于seedance2.0的中国大模型,支持图像、视频、音频、文本四种模态输入,表达方式更丰富,生成也更可控。


nano-banana纳米香蕉中文站
国内直接访问,限时3折
输入简单文字,生成想要的图片,纳米香蕉中文站基于 Google 模型的 AI 图片生成网站,支持文字生图、图生图。官网价格限时3折活动


扣子-AI办公
职场AI,就用扣子
AI办公助手,复杂任务高效处理。办公效率低?扣子空间AI助手支持播客生成、PPT制作、网页开发及报告写作,覆盖科研、商业、舆情等领域的专家Agent 7x24小时响应,生活工作无缝切换,提升50%效率!


堆友
多风格AI绘画神器
堆友平台由阿里巴巴设计团队创建,作为一款AI驱动的设计工具,专为设计师提供一站式增长服务。功能覆盖海量3D素材、AI绘画、实时渲染以及专业抠图,显著提升设计品质和效率。平台不仅提供工具,还是一个促进创意交流和个人发展的空间,界面友好,适合所有级别的设计师和创意工作者。


码上飞
零代码AI应用开发平台
零代码AI应用开发平台,用户只需一句话简单描述需求,AI能自动生成小程序、APP或H5网页应用,无需编写代码。


Vora
免费创建高清无水印Sora视频
Vora是一个免费创建高清无水印Sora视频的AI工具
推荐工具精选





AI云服务特惠
懂AI专属折扣关注微信公众号
最新AI工具、AI资讯
独家AI资源、AI项目落地

微信扫一扫关注公众号