
MobileSAM
高效轻量化图像分割模型,适用于移动设备
MobileSAM是一种轻量级图像分割模型,专为移动应用优化。它保持了与原始SAM相当的性能,同时大幅减少了模型参数和推理时间。通过将ViT-H编码器替换为TinyViT,MobileSAM将参数量从615M降至9.66M,推理速度从456ms提升至12ms。该项目提供完整的训练和使用文档,支持ONNX导出,可轻松集成到现有SAM项目中。



更快的分割任何物体(MobileSAM)和分割所有物体(MobileSAMv2)
:pushpin: MobileSAMv2现已在ResearchGate和arXiv上发布。它用物体感知的提示采样替代了SAM中的网格搜索提示采样,以实现更快的分割所有物体(SegEvery)。
:pushpin: MobileSAM现已在ResearchGate和arXiv上发布。它用轻量级图像编码器替代了SAM中的重量级图像编码器,以实现更快的分割任何物体(SegAny)。
支持ONNX模型导出。欢迎在您的设备上测试并与我们分享结果。
MobileSAM的演示在CPU上运行,可在hugging face演示上查看。在我们的Mac i5 CPU上,大约需要3秒。在hugging face演示中,由于界面和性能较差的CPU,速度会更慢,但仍然运行良好。敬请期待更多功能的新版本!您也可以在本地PC上运行MobileSAM的演示。
:grapes: 媒体报道和从SAM适配到MobileSAM的项目(感谢大家!)
- 2023/07/03:joliGEN支持MobileSAM,以实现更快、更轻量级的使用扩散和GAN进行图像修复的掩码细化。
- 2023/07/03:MobileSAM-in-the-Browser展示了在本地PC或手机浏览器上运行MobileSAM的演示。
- 2023/07/02:Inpaint-Anything支持MobileSAM,以实现更快、更轻量级的修复任何物体。
- 2023/07/02:Personalize-SAM支持MobileSAM,以实现更快、更轻量级的单样本个性化分割任何物体。
- 2023/07/01:MobileSAM-in-the-Browser在浏览器中实现了MobileSAM的示例。
- 2023/06/30:SegmentAnythingin3D支持MobileSAM,以高效地分割3D中的任何物体。
- 2023/06/30:MobileSAM再次被AK报道,请查看AK的MobileSAM推文。欢迎转发。
- 2023/06/29:AnyLabeling支持MobileSAM进行自动标注。
- 2023/06/29:SonarSAM支持MobileSAM进行图像编码器的全面微调。
- 2023/06/29:Stable Diffusion WebUIv支持MobileSAM。
- 2023/06/28:Grounding-SAM通过Grounded-MobileSAM支持MobileSAM。
- 2023/06/27:MobileSAM被AK报道,请查看AK的MobileSAM推文。欢迎转发。
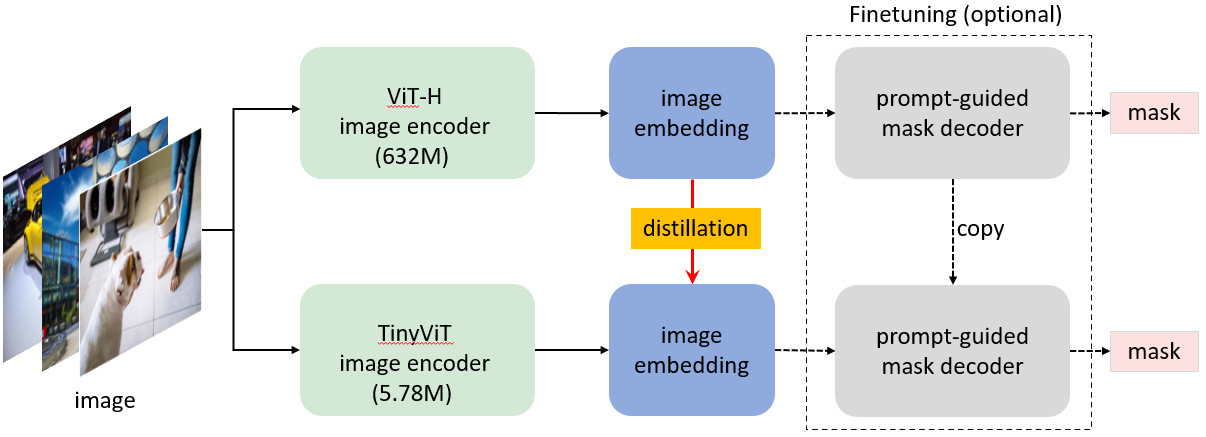
:star: MobileSAM是如何训练的? MobileSAM在单个GPU上使用10万个数据集(原始图像的1%)训练不到一天。训练代码将很快发布。
:star: 如何从SAM适配到MobileSAM? 由于MobileSAM完全保持了与原始SAM相同的流程,我们继承了原始SAM的预处理、后处理和所有其他接口。因此,假设除了更小的图像编码器外,其他一切都完全相同,那些将原始SAM用于项目的人几乎可以零成本地适配到MobileSAM。
:star: MobileSAM的性能与原始SAM相当(至少在视觉上),并且除了图像编码器的变化外,完全保持了与原始SAM相同的流程。具体来说,我们用一个更小的Tiny-ViT(5M)替换了原始的重量级ViT-H编码器(632M)。在单个GPU上,MobileSAM每张图像运行约12ms:图像编码器8ms,掩码解码器4ms。
-
ViT基础图像编码器的比较如下:
图像编码器 原始SAM MobileSAM 参数数量 611M 5M 速度 452ms 8ms -
原始SAM和MobileSAM具有完全相同的提示引导掩码解码器:
掩码解码器 原始SAM MobileSAM 参数数量 3.876M 3.876M 速度 4ms 4ms -
整个流程的比较如下:
整个流程(编码器+解码器) 原始SAM MobileSAM 参数数量 615M 9.66M 速度 456ms 12ms
:star: 原始SAM和MobileSAM以点作为提示。
<p float="left"> <img src="https://yellow-cdn.veclightyear.com/835a84d5/efa14e46-dde8-41c4-abed-5122e64c050a.jpg?raw=true" width="99.1%" /> </p>:star: 原始SAM和MobileSAM以框作为提示。
<p float="left"> <img src="https://yellow-cdn.veclightyear.com/835a84d5/6a6dbed3-1fbb-462f-afce-406428df405a.jpg?raw=true" width="99.1%" /> </p>:muscle: MobileSAM是否比FastSAM更快、更小?是的! MobileSAM比同期的FastSAM小约7倍,快约5倍。 整个流程的比较如下:
| 整个流程(编码器+解码器) | FastSAM | MobileSAM |
|---|---|---|
| 参数数量 | 68M | 9.66M |
| 速度 | 64ms | 12ms |
:muscle: MobileSAM是否比FastSAM更好地对齐原始SAM?是的! 建议FastSAM使用多个点,因此我们比较了两个提示点(具有不同像素距离)的mIoU,结果如下。更高的mIoU表示更好的对齐。
| mIoU | FastSAM | MobileSAM |
|---|---|---|
| 100 | 0.27 | 0.73 |
| 200 | 0.33 | 0.71 |
| 300 | 0.37 | 0.74 |
| 400 | 0.41 | 0.73 |
| 500 | 0.41 | 0.73 |
安装
代码需要 python>=3.8,以及 pytorch>=1.7 和 torchvision>=0.8。请按照这里的说明安装 PyTorch 和 TorchVision 依赖。强烈建议安装支持 CUDA 的 PyTorch 和 TorchVision。
安装 Mobile Segment Anything:
pip install git+https://github.com/ChaoningZhang/MobileSAM.git
或者在本地克隆仓库并安装:
git clone git@github.com:ChaoningZhang/MobileSAM.git
cd MobileSAM; pip install -e .
演示
安装 MobileSAM 后,您可以在本地 PC 上运行演示或查看我们的 HuggingFace 演示。
它需要最新版本的 gradio。
cd app
python app.py
<a name="GettingStarted"></a>入门
可以通过以下方式加载 MobileSAM:
from mobile_sam import sam_model_registry, SamAutomaticMaskGenerator, SamPredictor
model_type = "vit_t"
sam_checkpoint = "./weights/mobile_sam.pt"
device = "cuda" if torch.cuda.is_available() else "cpu"
mobile_sam = sam_model_registry[model_type](checkpoint=sam_checkpoint)
mobile_sam.to(device=device)
mobile_sam.eval()
predictor = SamPredictor(mobile_sam)
predictor.set_image(<your_image>)
masks, _, _ = predictor.predict(<input_prompts>)
或为整个图像生成蒙版:
from mobile_sam import SamAutomaticMaskGenerator
mask_generator = SamAutomaticMaskGenerator(mobile_sam)
masks = mask_generator.generate(<your_image>)
<a name="GettingStarted"></a>入门(MobileSAMv2)
从检查点下载模型权重。
下载模型权重后,可以简单地使用更快的 SegEvery 和 MobileSAMv2,如下所示:
cd MobileSAMv2
bash ./experiments/mobilesamv2.sh
ONNX 导出
MobileSAM 现在支持 ONNX 导出。使用以下命令导出模型:
python scripts/export_onnx_model.py --checkpoint ./weights/mobile_sam.pt --model-type vit_t --output ./mobile_sam.onnx
还可以查看 示例笔记本 以了解详细步骤。
我们建议使用经过测试的 onnx==1.12.0 和 onnxruntime==1.13.1。
我们 MobileSAM 的 BibTex
如果您在研究中使用 MobileSAM,请使用以下 BibTeX 条目。:mega: 谢谢!
@article{mobile_sam, title={Faster Segment Anything: Towards Lightweight SAM for Mobile Applications}, author={Zhang, Chaoning and Han, Dongshen and Qiao, Yu and Kim, Jung Uk and Bae, Sung-Ho and Lee, Seungkyu and Hong, Choong Seon}, journal={arXiv preprint arXiv:2306.14289}, year={2023} }
致谢
本工作得到了韩国政府(MSIT)资助的信息通信技术规划评估研究所(IITP)的支持(No.RS-2022-00155911,人工智能融合创新人力资源开发(庆熙大学))
<details> <summary> <a href="https://github.com/facebookresearch/segment-anything">SAM</a>(Segment Anything)[<b>bib</b>] </summary></details> <details> <summary> <a href="https://github.com/microsoft/Cream/tree/main/TinyViT">TinyViT</a>(TinyViT: Fast Pretraining Distillation for Small Vision Transformers)[<b>bib</b>] </summary>@article{kirillov2023segany, title={Segment Anything}, author={Kirillov, Alexander and Mintun, Eric and Ravi, Nikhila and Mao, Hanzi and Rolland, Chloe and Gustafson, Laura and Xiao, Tete and Whitehead, Spencer and Berg, Alexander C. and Lo, Wan-Yen and Doll{\'a}r, Piotr and Girshick, Ross}, journal={arXiv:2304.02643}, year={2023} }
</details>@InProceedings{tiny_vit, title={TinyViT: Fast Pretraining Distillation for Small Vision Transformers}, author={Wu, Kan and Zhang, Jinnian and Peng, Houwen and Liu, Mengchen and Xiao, Bin and Fu, Jianlong and Yuan, Lu}, booktitle={European conference on computer vision (ECCV)}, year={2022}
编辑推荐精选


扣子-AI办公
职场AI,就用扣子
AI办公助手,复杂任务高效处理。办公效率低?扣子空间AI助手支持播客生成、PPT制作、网页开发及报告写作,覆盖科研、商业、舆情等领域的专家Agent 7x24小时响应,生活工作无缝切换,提升50%效率!


堆友
多风格AI绘画神器
堆友平台由阿里巴巴设计团队创建,作为一款AI驱动的设计工具,专为设计师提供一站式增长服务。功能覆盖海量3D素材、AI绘画、实时渲染以及专业抠图,显著提升设计品质和效率。平台不仅提供工具,还是一个促进创意交流和个人发展的空间,界面友好,适合所有级别的设计师和创意工作者。


码上飞
零代码AI应用开发平台
零代码AI应用开发平台,用户只需一句话简单描述需求,AI能自动生成小程序、APP或H5网页应用,无需编写代码。


Vora
免费创建高清无水印Sora视频
Vora是一个免费创建高清无水印Sora视频的AI工具


Refly.AI
最适合小白�的AI自动化工作流平台
无需编码,轻松生成可复用、可变现的AI自动化工作流


酷表ChatExcel
大模型驱动的Excel数据处理工具
基于大模型交互的表格处理系统,允许用户通过对话方式完成数据整理和可视化分析。系统采用机器学习算法解析用户指令,自动执行排序、公式计算和数据透视等操作,支持多种文件格式导入导出。数据处理响应速度保持在0.8秒以内,支持超过100万行数据的即时分析。


TRAE编程
AI辅助编程,代码自动修复
Trae是一种自适应的集成开发环境(IDE),通过自动化和多元协作改变开发流程。利用Trae,团队能够更快速、精确地编写和部署代码,从而提高编程效率和项目交付速度。Trae具备上下文感知和代码自动完成功能,是提升开发效率的理想工具。


AIWritePaper论文写作
AI论文写作指导平台
AIWritePaper论文写作是一站式AI论文写作辅助工具,简化了选题、文献检索至论文撰写的整个过程。通过简单设定,平台可快速生成高质量论文大纲和全文,配合图表、参考文献等一应俱全,同时提供开题报告和答辩PPT等增值服务,保障数据安全,有效提升写作效率和论文质量。


博思AIPPT
AI一键生成PPT,就用博��思AIPPT!
博思AIPPT,新一代的AI生成PPT平台,支持智能生成PPT、AI美化PPT、文本&链接生成PPT、导入Word/PDF/Markdown文档生成PPT等,内置海量精美PPT模板,涵盖商务、教育、科技等不同风格,同时针对每个页面提供多种版式,一键自适应切换,完美适配各种办公场景。


潮际好麦
AI赋能电商视觉革命,一站式智能商拍平台
潮际好麦深耕服装行业,是国内AI试衣效果最好的软件。使用先进AIGC能力为电商卖家批量提供优质的、低成本的商拍图。合作品牌有Shein、Lazada、安踏、百丽等65个国内外头部品牌,以及国内10万+淘宝、天猫、京东等主流平台的品牌商家,为卖家节省将近85%的出图成本,提升约3倍出图效率,让品牌能够快速上架。
推荐工具精选




AI云服务特惠
懂AI专属折扣关注微信公众号
最新AI工具、AI资讯
独家AI资源、AI项目落地

微信扫一扫关注公众号