
FastSAM
全景分割模型 速度提升50倍且性能可比SAM
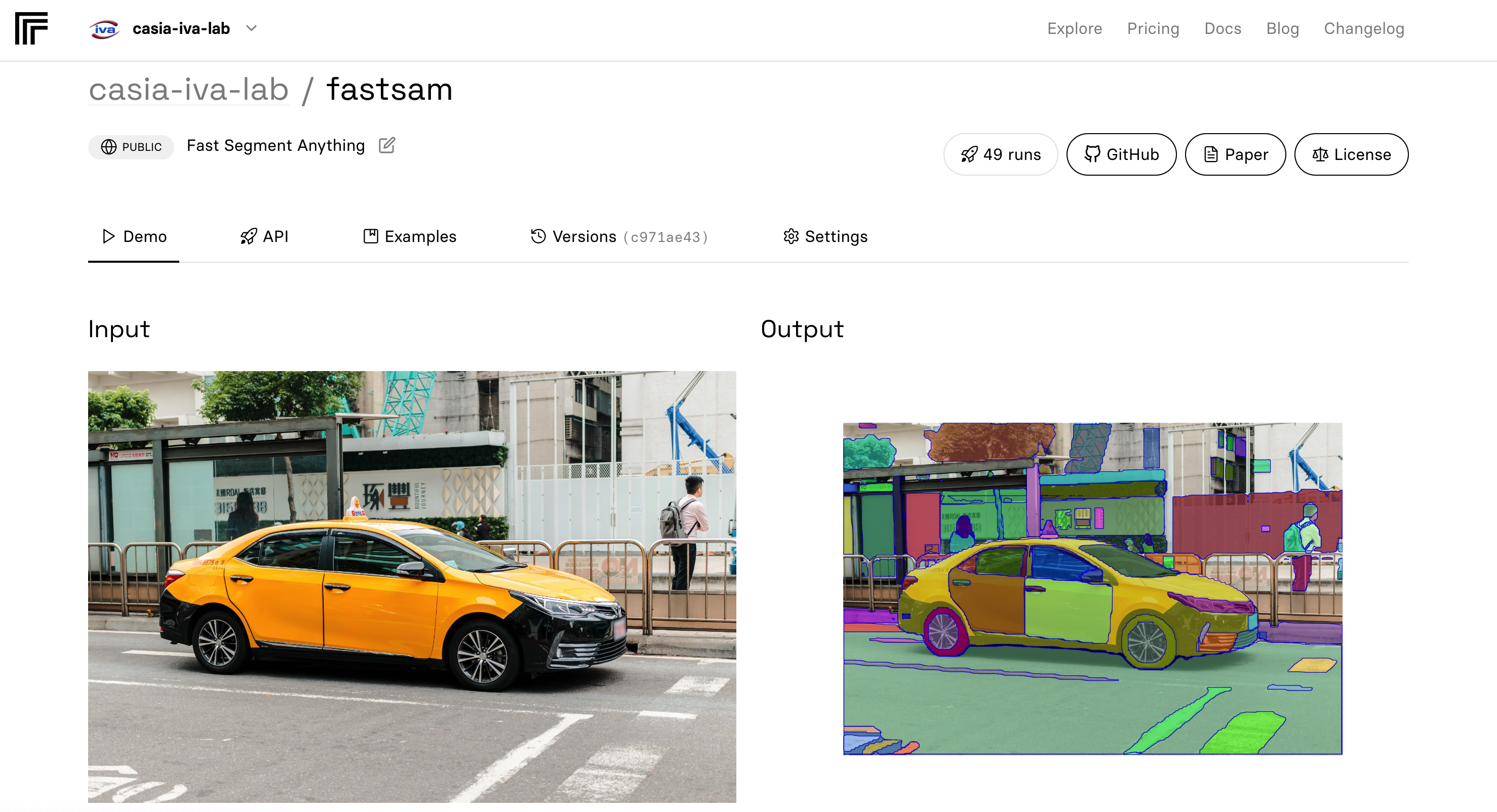
FastSAM是一款基于CNN的高效全景分割模型。仅使用SAM数据集2%的数据,就实现了与SAM相当的性能,同时运行速度提升50倍。支持一切模式、文本提示、框选和点选等多种交互方式。在边缘检测、目标检测等下游任务中,FastSAM展现出优异的零样本迁移能力,为计算机视觉研究开辟新方向。




快速分割任意物体
[📕论文] [🤗HuggingFace演示] [Colab演示] [Replicate演示和API] [OpenXLab演示模型库] [引用] [视频演示]
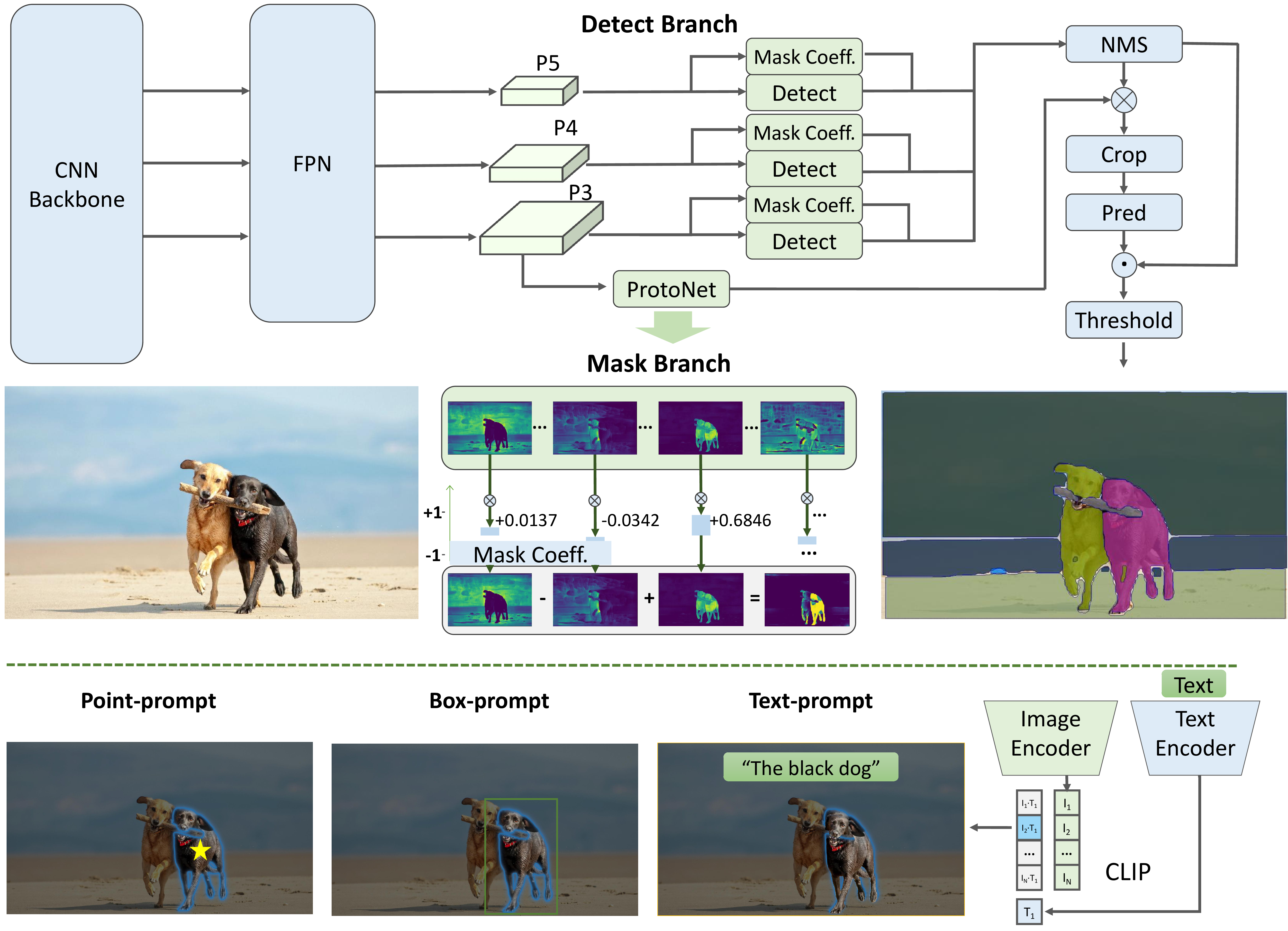
**快速分割任意物体模型(FastSAM)**是一个CNN分割任意物体模型,仅使用SAM作者发布的SA-1B数据集的2%进行训练。FastSAM在运行速度提高50倍的同时,实现了与SAM方法相当的性能。
🍇 更新
2024/6/25边缘锯齿问题已略有改善#231,该策略也同步到了ultralytics项目#13939,#13912。huggingface演示已更新。2023/11/28推荐:语义FastSAM,为FastSAM添加了语义类别标签。感谢KBH00的这一宝贵贡献。2023/09/11发布训练和验证代码。2023/08/17发布OpenXLab演示。感谢OpenXLab团队的帮助。2023/07/06添加到Ultralytics (YOLOv8)模型库。感谢Ultralytics的帮助🌹。2023/06/29在HuggingFace Space支持文本模式。非常感谢gaoxinge的帮助🌹。2023/06/29发布FastSAM_Awesome_TensorRT。非常感谢ChuRuaNh0提供FastSAM的TensorRT模型🌹。2023/06/26发布FastSAM Replicate在线演示。非常感谢Chenxi提供这个很棒的演示🌹。2023/06/26在HuggingFace Space支持点模式。更好更快的交互即将推出!2023/06/24非常感谢Grounding-SAM在Grounded-FastSAM中结合Grounding-DINO与FastSAM🌹。
安装
在本地克隆仓库:
git clone https://github.com/CASIA-IVA-Lab/FastSAM.git
创建conda环境。代码需要python>=3.7,以及pytorch>=1.7和torchvision>=0.8。请按照这里的说明安装PyTorch和TorchVision依赖。强烈建议安装支持CUDA的PyTorch和TorchVision。
conda create -n FastSAM python=3.9 conda activate FastSAM
安装包:
cd FastSAM pip install -r requirements.txt
安装CLIP(如果要测试文本提示则需要):
pip install git+https://github.com/openai/CLIP.git
<a name="入门"></a> 入门
首先下载模型检查点。
然后,你可以运行脚本尝试everything模式和三种提示模式。
# Everything模式 python Inference.py --model_path ./weights/FastSAM.pt --img_path ./images/dogs.jpg
# 文本提示 python Inference.py --model_path ./weights/FastSAM.pt --img_path ./images/dogs.jpg --text_prompt "the yellow dog"
# 框提示 (xywh) python Inference.py --model_path ./weights/FastSAM.pt --img_path ./images/dogs.jpg --box_prompt "[[570,200,230,400]]"
# 点提示 python Inference.py --model_path ./weights/FastSAM.pt --img_path ./images/dogs.jpg --point_prompt "[[520,360],[620,300]]" --point_label "[1,0]"
你可以使用以下代码生成所有掩码并可视化结果。
from fastsam import FastSAM, FastSAMPrompt model = FastSAM('./weights/FastSAM.pt') IMAGE_PATH = './images/dogs.jpg' DEVICE = 'cpu' everything_results = model(IMAGE_PATH, device=DEVICE, retina_masks=True, imgsz=1024, conf=0.4, iou=0.9,) prompt_process = FastSAMPrompt(IMAGE_PATH, everything_results, device=DEVICE) # everything提示 ann = prompt_process.everything_prompt() prompt_process.plot(annotations=ann,output_path='./output/dog.jpg',)
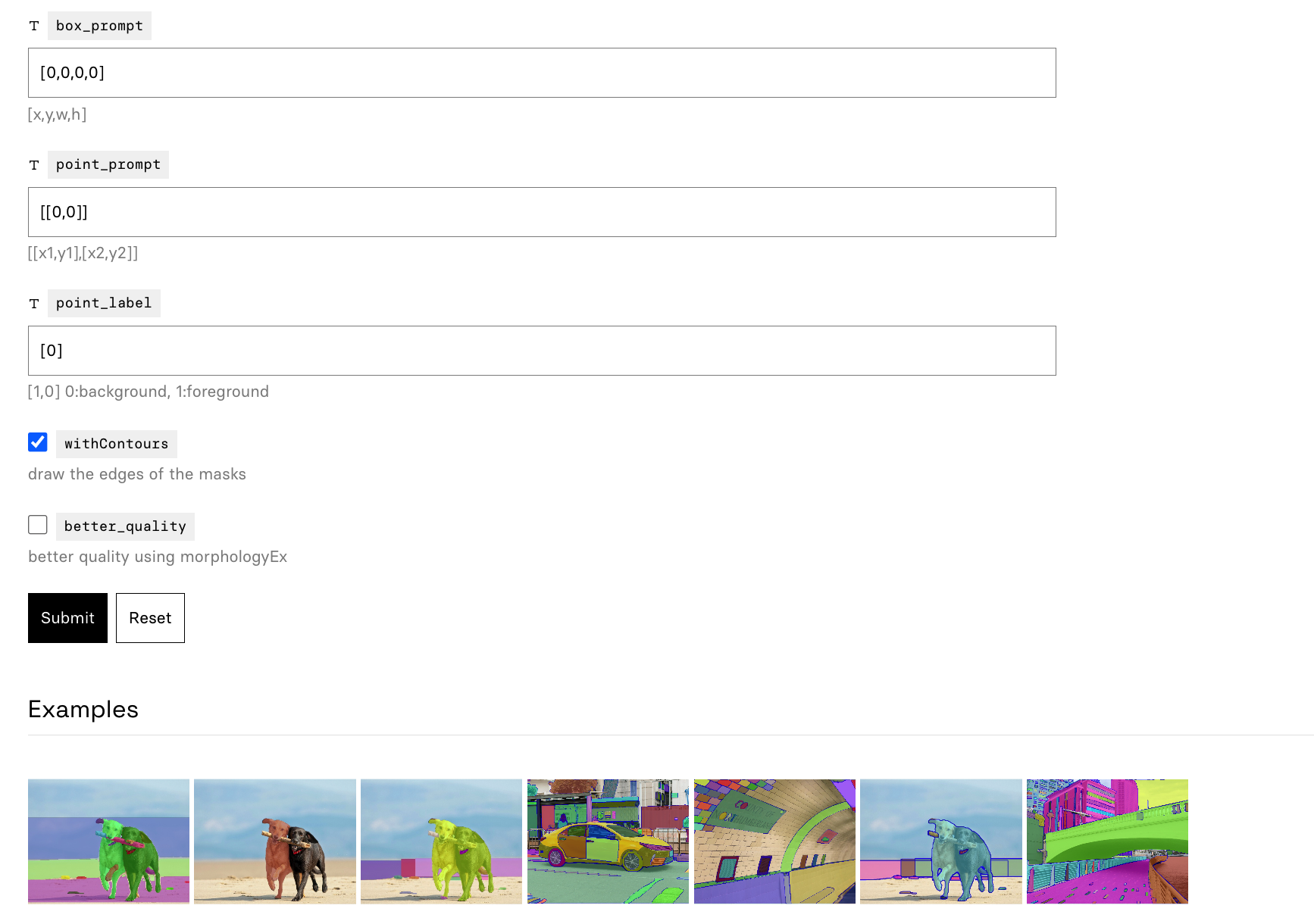
对于点/框/文本模式提示,使用:
# bbox默认形状 [0,0,0,0] -> [x1,y1,x2,y2]
ann = prompt_process.box_prompt(bboxes=[[200, 200, 300, 300]])
# 文本提示
ann = prompt_process.text_prompt(text='a photo of a dog')
# 点提示
# points默认 [[0,0]] [[x1,y1],[x2,y2]]
# point_label默认 [0] [1,0] 0:背景, 1:前景
ann = prompt_process.point_prompt(points=[[620, 360]], pointlabel=[1])
prompt_process.plot(annotations=ann,output_path='./output/dog.jpg',)
你也欢迎尝试我们的Colab演示:FastSAM_example.ipynb。
不同的推理选项
我们为不同目的提供了各种选项,详情请见MORE_USAGES.md。
训练或验证
从头开始训练或验证:训练和验证代码。
网页演示
Gradio演示
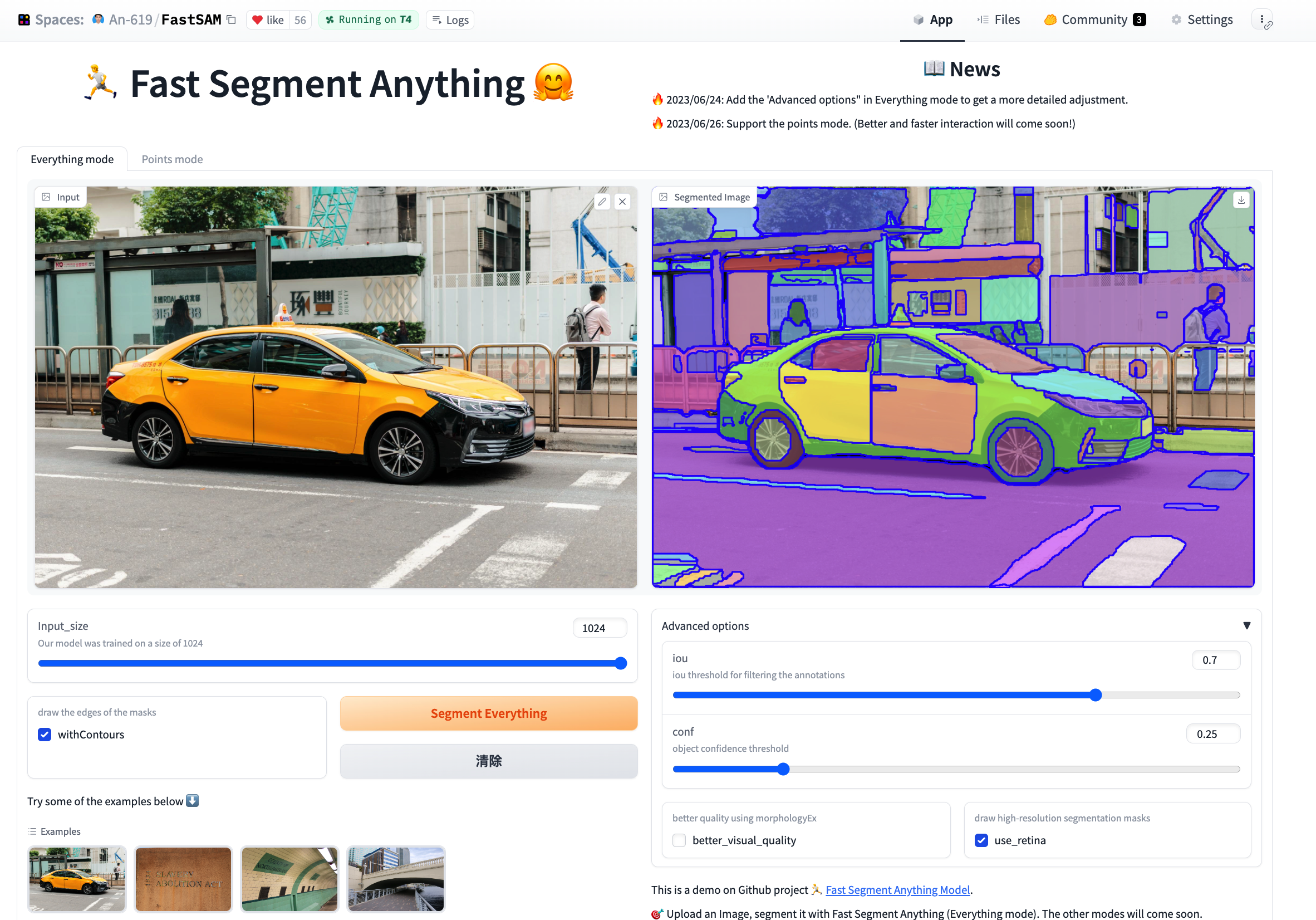
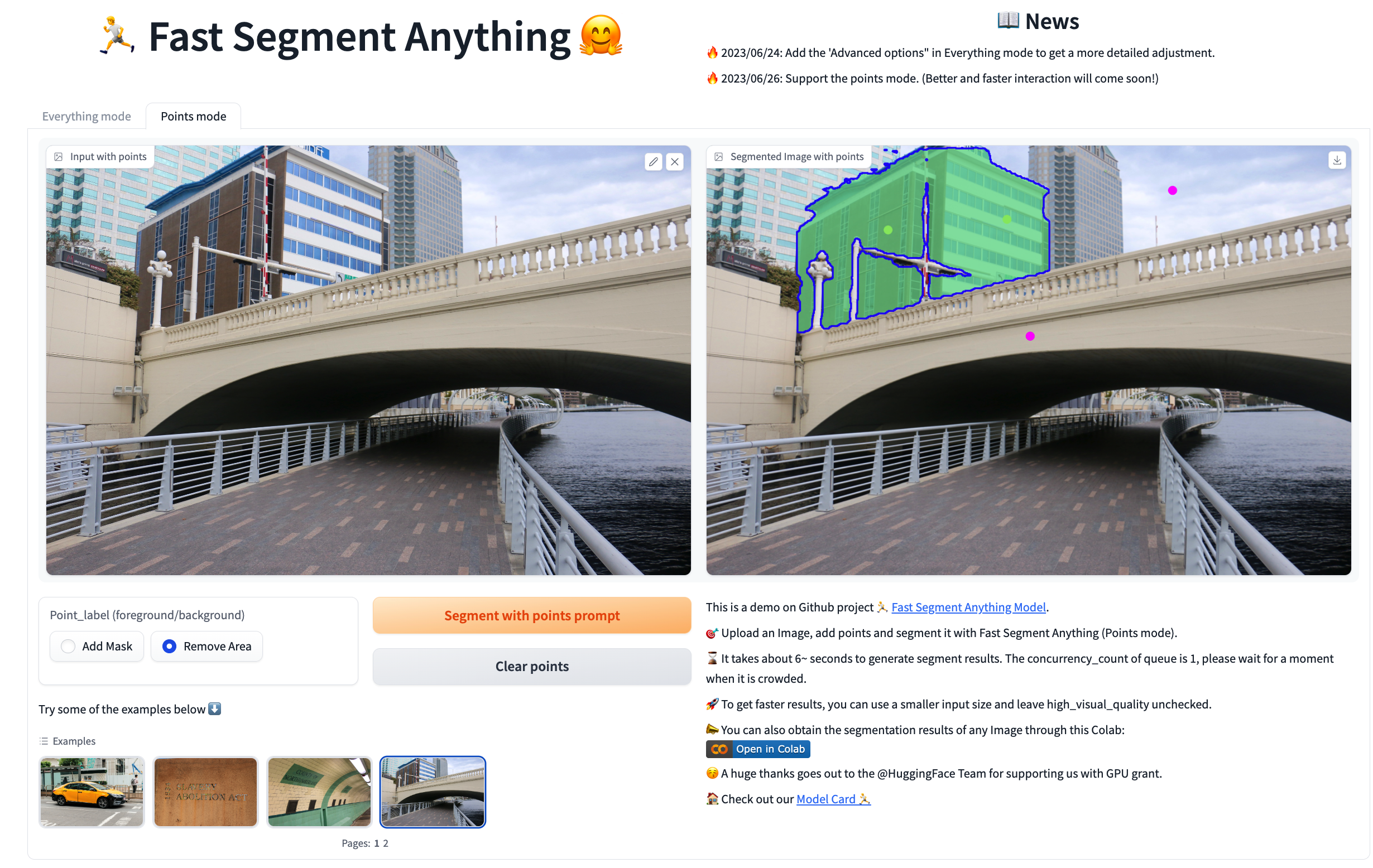
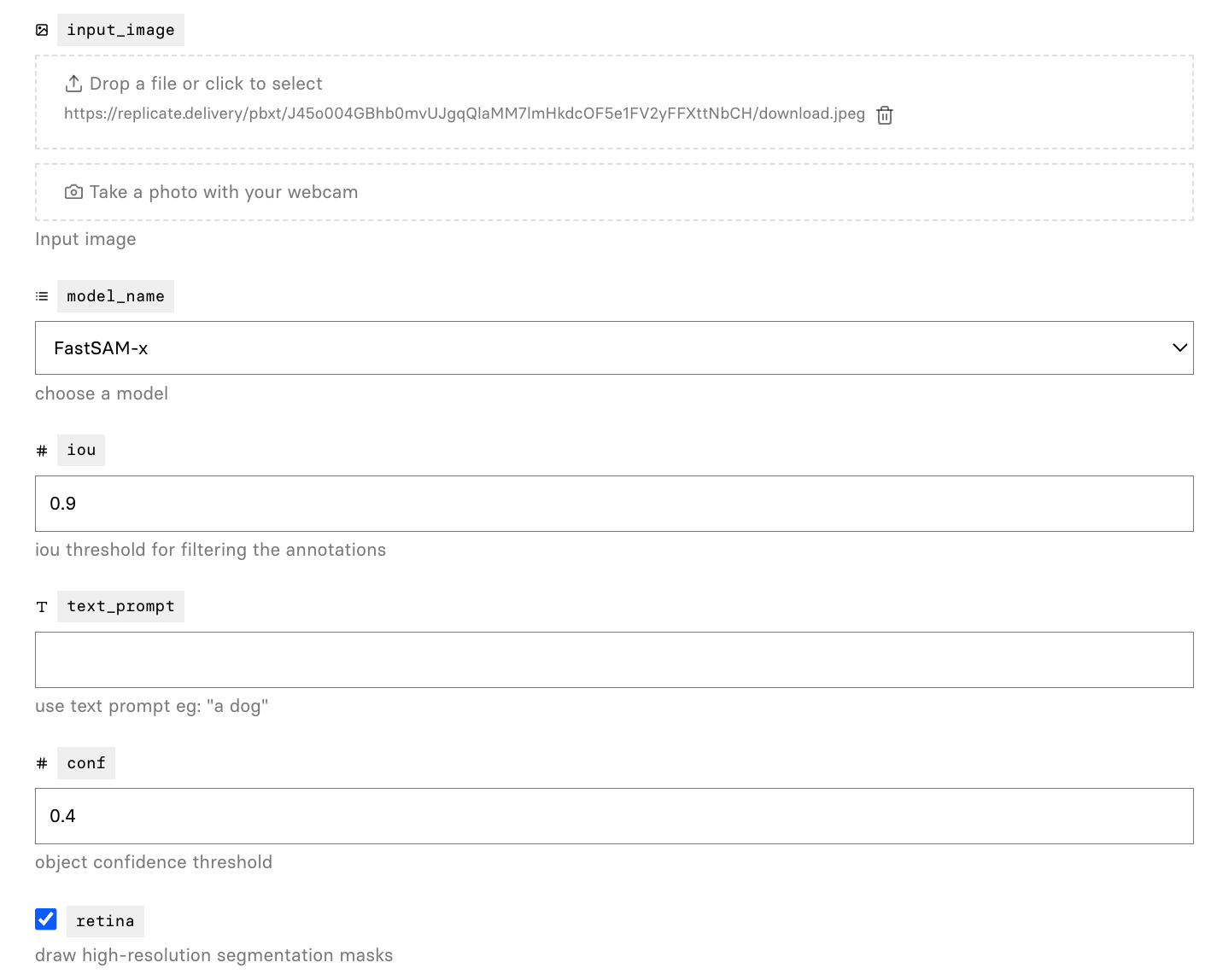
- 我们还提供了一个使用gradio构建的UI来测试我们的方法。你可以上传自定义图像,选择模式并设置参数,点击分割按钮,获得满意的分割结果。目前,UI支持与"Everything模式"和"点模式"交互。我们计划在未来添加对其他模式的支持。在终端中运行以下命令将启动演示:
# 在"./weights/FastSAM.pt"下载预训练模型
python app_gradio.py
- 这个演示也托管在HuggingFace Space上。
Replicate演示
- Replicate演示已支持所有模式,你可以体验点/框/文本模式。
<a name="模型"></a>模型检查点
有两个版本的模型可用,大小不同。点击下面的链接下载相应模型类型的检查点。
default或FastSAM:基于YOLOv8x的分割任意物体模型 | 百度网盘 (密码: 0000)。FastSAM-s:基于YOLOv8s的分割任意物体模型。
结果
所有结果均在单台NVIDIA GeForce RTX 3090上测试。
1. 推理时间
不同点提示数量下的运行速度(毫秒)。
| 方法 | 参数量 | 1 | 10 | 100 | E(16x16) | E(32x32*) | E(64x64) |
|---|---|---|---|---|---|---|---|
| SAM-H | 0.6G | 446 | 464 | 627 | 852 | 2099 | 6972 |
| SAM-B | 136M | 110 | 125 | 230 | 432 | 1383 | 5417 |
| FastSAM | 68M | 40 | 40 | 40 | 40 | 40 | 40 |
2. 内存使用
| 数据集 | 方法 | GPU内存 (MB) |
|---|---|---|
| COCO 2017 | FastSAM | 2608 |
| COCO 2017 | SAM-H | 7060 |
| COCO 2017 | SAM-B | 4670 |
3. 零样本迁移实验
边缘检测
在BSDB500数据集上测试。
| 方法 | 年份 | ODS | OIS | AP | R50 |
|---|---|---|---|---|---|
| HED | 2015 | .788 | .808 | .840 | .923 |
| SAM | 2023 | .768 | .786 | .794 | .928 |
| FastSAM | 2023 | .750 | .790 | .793 | .903 |
目标提议
COCO
| 方法 | AR10 | AR100 | AR1000 | AUC |
|---|---|---|---|---|
| SAM-H E64 | 15.5 | 45.6 | 67.7 | 32.1 |
| SAM-H E32 | 18.5 | 49.5 | 62.5 | 33.7 |
| SAM-B E32 | 11.4 | 39.6 | 59.1 | 27.3 |
| FastSAM | 15.7 | 47.3 | 63.7 | 32.2 |
LVIS
边界框 AR@1000
| 方法 | 全部 | 小 | 中 | 大 |
|---|---|---|---|---|
| ViTDet-H | 65.0 | 53.2 | 83.3 | 91.2 |
| 零样本迁移方法 | ||||
| SAM-H E64 | 52.1 | 36.6 | 75.1 | 88.2 |
| SAM-H E32 | 50.3 | 33.1 | 76.2 | 89.8 |
| SAM-B E32 | 45.0 | 29.3 | 68.7 | 80.6 |
| FastSAM | 57.1 | 44.3 | 77.1 | 85.3 |
COCO 2017实例分割
| 方法 | AP | APS | APM | APL |
|---|---|---|---|---|
| ViTDet-H | .510 | .320 | .543 | .689 |
| SAM | .465 | .308 | .510 | .617 |
| FastSAM | .379 | .239 | .434 | .500 |
4. 性能可视化
几个分割结果:
自然图像

文本到掩码

5.下游任务
几个下游任务的结果,展示有效性。
异常检测

显著目标检测

建筑物提取

许可证
该模型采用Apache 2.0许可证。
致谢
- Segment Anything提供了SA-1B数据集和基础代码。
- YOLOv8提供了代码和预训练模型。
- YOLACT提供了强大的实例分割方法。
- Grounded-Segment-Anything提供了有用的网页演示模板。
贡献者
没有这些优秀的人的贡献,我们的项目是不可能实现的!感谢所有为这个项目做出贡献的人。
<a href="https://github.com/CASIA-IVA-Lab/FastSAM/graphs/contributors"> <img src="https://contrib.rocks/image?repo=CASIA-IVA-Lab/FastSAM" /> </a>引用FastSAM
如果您发现这个项目对您的研究有用,请考虑引用以下BibTeX条目。
@misc{zhao2023fast,
title={Fast Segment Anything},
author={Xu Zhao and Wenchao Ding and Yongqi An and Yinglong Du and Tao Yu and Min Li and Ming Tang and Jinqiao Wang},
year={2023},
eprint={2306.12156},
archivePrefix={arXiv},
primaryClass={cs.CV}
}
编辑推荐精选


GPT Plus|Pro充值
GPT充值
支持 ChatGPT Plus / Pro 充值服务,支付便捷,自动发货,售后可查。


GPT Image 2中文站
AI 图片生成平台
GPT Image 2 是面向用户的 AI 图片生成平台,支持文生图、图生图及多模型创意工作流。


Vecbase
你的AI Agent团队
Vecbase 是专为 AI 团队打造的智能工作空间,将数据管理、模型协作与知识沉淀整合于一处。算法、产品与业务在同一平台无缝协同,让从数据到 AI 应用的落地更快一步。


音述AI
全球首个AI音乐社区
音述AI是全球首个AI音乐社区,致力让每个人都能用音乐表达自我。音述AI提供零门槛AI创作工具,独创GETI法则帮助用户精准定义音乐风格,AI润色功能支持自动优化作品质感。音述AI支持交流讨论、二次创作与价值变现。针对中文用户的语言习惯与文化背景进行专门优化,支持国风融合、C-pop等本土音乐标签,�让技术更好地承载人文表达。


QoderWork
阿里Qoder团队推出的桌面端AI智能体
QoderWork 是阿里推出的本地优先桌面 AI 智能体,适配 macOS14+/Windows10+,以自然语言交互实现文件管理、数据分析、AI 视觉生成、浏览器自动化等办公任务,自主拆解执行复杂工作流,数据本地运行零上传,技能市场可无限扩展,是高效的 Agentic 生产力办公助手。


lynote.ai
一站式搞定所有学习需求
不再被海量信息淹没,开始真正理解知识。Lynote 可摘要 YouTube 视频、PDF、文章等内容。即时创建笔记,检测 AI 内容并下载资料,将您的学习效率提升 10 倍。


AniShort
为AI短剧协作而生
专为AI短剧协作而生的AniShort正式发布,深度重构AI短剧全流程生产模式,整合创意策划、制作执行、实时协作、在线审片、资产复用等全链路功能,独创无限画布、双轨并行工业化工作流与Ani智能体助手,集成多款主流AI大模型,破解素材零散、版本混乱、沟通低效等行业痛点,助力3人团队效率提升800%,打造标准化、可追溯的AI短剧量产体系,是AI短剧团队协同创作、提升制作效率的核心工具。


seedancetwo2.0
能听懂你表达的视频模型
Seedance two是基于seedance2.0的中国大模型,支持图像、视频、音频、文本四种模态输入,表达方式更丰富,生成也更可控。


nano-banana纳米香蕉中文站
国内直接访问,限时3折
输入简单文字,生成想要的图片,纳米香蕉中文站基于 Google 模型的 AI 图片生成网站,支持文字生图、图生图。官网价格限时3折活动


扣子-AI办公
职场AI,就用扣子
AI办公助手,复杂任务高效处理。办公效率低?扣子空间AI助手支持播客生成、PPT制作、网页开发及报告写作,覆盖科研、商业、舆情等领域的专家Agent 7x24小时响应,生活工作无缝切换,提升50%效率!
推荐工具精选





AI云服务特惠
懂AI专属折扣关注微信公众号
最新AI工具、AI资讯
独家AI资源、AI项目落地

微信扫一扫关注公众号