


ByProt
<a href="https://pytorch.org/get-started/locally/"><img alt="PyTorch" src="https://img.shields.io/badge/PyTorch-ee4c2c?logo=pytorch&logoColor=white"></a>
<a href="https://pytorchlightning.ai/"><img alt="Lightning" src="https://img.shields.io/badge/-Lightning-792ee5?logo=pytorchlightning&logoColor=white"></a>
<a href="https://hydra.cc/"><img alt="Config: Hydra" src="https://img.shields.io/badge/Config-Hydra-89b8cd"></a>
<a href="https://github.com/ashleve/lightning-hydra-template"><img alt="Template" src="https://img.shields.io/badge/-Lightning--Hydra--Template-017F2F?style=flat&logo=github&labelColor=gray"></a><br>

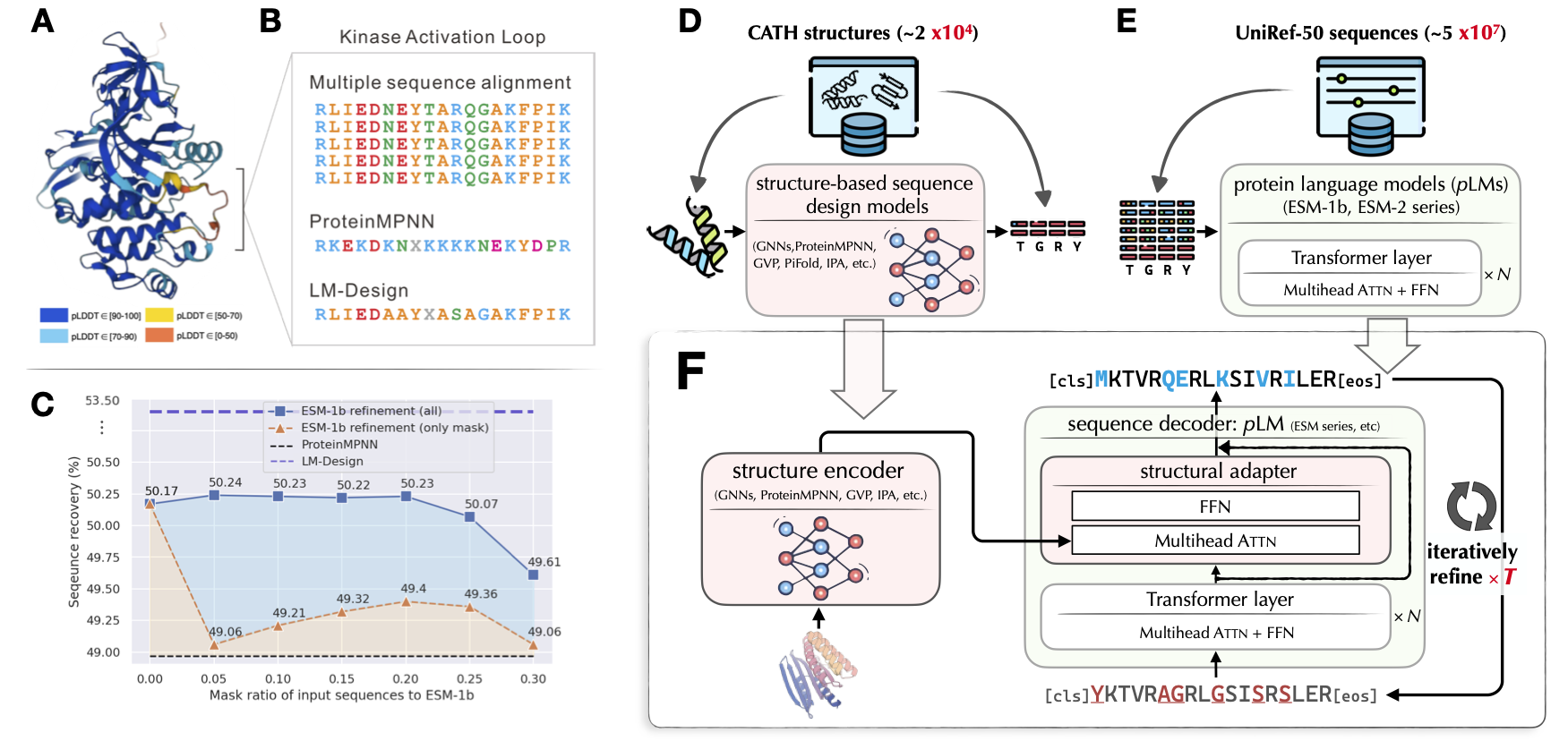
ByProt是一款专注于蛋白质研究的通用工具包。它目前主要集中于基于结构的序列设计(又称固定主链)领域,提供以下关键功能:
- 高效的非自回归ProteinMPNN变体: ByProt提供了一种高效有效的非自回归ProteinMPNN变体,这是一个功能强大的固定主链蛋白质序列设计工具。
- <span style="font-variant:small-caps;">LM-Design</span>的官方实现: ByProt是<span style="font-variant:small-caps;">LM-Design</span>的官方实现,这是一种最先进的蛋白质序列设计模型,发表在ICML 2023上(口头报告)。更多详情请参考论文。
我们正在不断扩展ByProt的功能,以涵盖更广泛的任务和特性。请关注我们的更新,我们将提供更全面的蛋白质研究工具包。
安装
# 克隆项目 git clone --recursive https://url/to/this/repo/ByProt.git cd ByProt # 创建conda虚拟环境 env_name=ByProt conda create -n ${env_name} python=3.7 pip conda activate ${env_name} # 自动安装其他所有依赖 bash install.sh
基于结构的蛋白质序列设计(反折叠)
预训练模型权重 (Zenodo)
| 模型 | 训练数据 | 检查点 |
|---|---|---|
protein_mpnn_cmlm | cath_4.2 | 链接 |
lm_design_esm1b_650m | cath_4.2 | 链接 |
lm_design_esm2_650m | cath_4.2 | 链接 |
lm_design_esm2_650m | multichain | 链接 |
数据
下载预处理的CATH数据集
- CATH 4.2数据集由Generative Models for Graph-Based Protein Design (Ingraham et al, NeurIPS'19)提供
- CATH 4.3数据集由Learning inverse folding from millions of predicted structures (Hsu et al, ICML'22)提供
bash scripts/download_cath.sh
检查configs/datamodule/cath_4.*.yaml并将data_dir设置为下载的CATH数据的路径。
下载PDB复合体数据(多链)
这个数据集整理了来自蛋白质数据库(PDB)的蛋白质(多链)复合体。 它由Robust deep learning-based protein sequence design using ProteinMPNN提供。 更多详情请参见他们的GitHub页面。
bash scripts/download_multichain.sh
检查configs/datamodule/multichain.yaml并将data_dir设置为下载的多链数据的路径。
准备好了一切,我们可以开始训练模型了。
训练
示例1: 非自回归(NAR) ProteinMPNN基线
使用条件掩码语言建模(CMLM)训练NAR ProteinMPNN
export CUDA_VISIBLE_DEVICES=0 # 或使用多GPU训练: # export CUDA_VISIBLE_DEVICES=0,1 exp=fixedbb/protein_mpnn_cmlm dataset=cath_4.2 name=fixedbb/${dataset}/protein_mpnn_cmlm python ./train.py \ experiment=${exp} datamodule=${dataset} name=${name} \ logger=tensorboard trainer=ddp_fp16
一些训练参数:
| 参数 | 用途 |
|---|---|
experiment | 实验配置,请参见ByProt/configs/experiment/文件夹 |
datamodule | 数据集配置,请参见ByProt/configs/datamodule文件夹 |
name | 实验名称,决定了实验结果保存的目录路径,例如:/root/research/projects/ByProt/run/logs/${name} |
logger | 机器学习实验记录器的配置,例如tensorboard |
train.force_restart | 设置为true以强制在${name}下重新训练实验,否则将从最后一个检查点恢复训练 |
示例2: LM-Design
在ESM-1b 650M模型基础上训练<span style="font-variant:small-caps;">LM-Design</span>。
在一台A100 GPU上训练大约需要6个小时。
exp=fixedbb/lm_design_esm1b_650m dataset=cath_4.2 name=fixedbb/${dataset}/lm_design_esm1b_650m ./train.py \ experiment=${exp} datamodule=${dataset} name=${name} \ logger=tensorboard trainer=ddp_fp16
使用exp=fixedbb/lm_design_esm2*在ESM-2系列上构建<span style="font-variant:small-caps;">LM-Design</span>。请检查ByProt/configs/experiment/fixedbb。
在验证/测试数据集上进行评估/推理
dataset=cath_4.2 # name=fixedbb/${dataset}/protein_mpnn_cmlm name=fixedbb/${dataset}/lm_design_esm1b_650m exp_path=/root/research/projects/ByProt/run/logs/${name} python ./test.py \ experiment_path=${exp_path} \ data_split=test ckpt_path=best.ckpt mode=predict \ task.generator.max_iter=5
一些生成参数:
| 参数 | 用途 |
|---|---|
experiment_path | 保存实验结果的文件夹(.hydra, checkpoints, tensorboard等) |
data_split | valid或test数据集 |
mode | predict用于生成序列和计算氨基酸序列恢复率; test用于评估nll、ppl |
task.generator | 序列生成器/采样器的参数 |
- max_iter=<int> | 最大解码迭代次数(默认: 5用于LM-Design, 1用于ProtMPNN-CMLM) |
- strategy=[denoise, mask_predict] | 解码策略(默认: denoise用于LM-Design, mask_predict用于ProtMPNN-CMLM) |
- temperature=<float> | 采样温度,设置为0以禁用随机采样并使用确定性采样(默认: 0) |
- eval_sc=<bool> | 使用ESMFold额外评估scTM分数(默认: false) |
在笔记本电脑上使用训练好的模型设计来自PDB文件的序列
示例1: ProteinMPNN-CMLM
from byprot.utils.config import compose_config as Cfg from byprot.tasks.fixedbb.designer import Designer # 1. 实例化设计器 exp_path = "/root/research/projects/ByProt/run/logs/fixedbb/cath_4.2/protein_mpnn_cmlm" cfg = Cfg( cuda=True, generator=Cfg( max_iter=1, strategy='mask_predict', temperature=0, eval_sc=False, ) ) designer = Designer(experiment_path=exp_path, cfg=cfg) # 2. 从PDB文件加载结构 pdb_path = "/root/research/projects/ByProt/data/3uat_variants/3uat_GK.pdb" designer.set_structure(pdb_path) # 3. 从给定结构生成序列 designer.generate() # 4. 计算评估指标 designer.calculate_metrics() ## 预测: SSYNPPILLLGPFAEELEEELVEENPERAGRPVPFTTEPPSPDETEGETYLYISSLEEAEELIESNRFLEAGEENNELVGISLEAIRSVARAGKLAILDTGGEAVEKLEEANIEPIVIFLVPKSVEDVRRVFPDLTEEEAEELTSEDEELLEEFKELLDAVVSGSTLEEVLEEIREVIEEASS ## 恢复率: 0.37158469945355194
示例2: <span style="font-variant:small-caps;">LM-Design</span>
from byprot.utils.config import compose_config as Cfg from byprot.tasks.fixedbb.designer import Designer # 1. 实例化设计器 exp_path = "/root/research/projects/ByProt/run/logs/fixedbb/cath_4.2/lm_design_esm2_650m" cfg = Cfg( cuda=True, generator=Cfg( max_iter=5, strategy='denoise', temperature=0, eval_sc=False, ) ) designer = Designer(experiment_path=exp_path, cfg=cfg) # 2. 从PDB文件加载结构 pdb_path = "/root/research/projects/ByProt/data/3uat_variants/3uat_GK.pdb" designer.set_structure(pdb_path) # 3. 从给定结构生成序列 designer.generate() # 你可以通过传递generator_args来覆盖生成器参数,例如: designer.generate( generator_args={ 'max_iter': 5, 'temperature': 0.1, } ) # 4. 计算评估指标 designer.calculate_metrics() ## 预测: LNYTRPVIILGPFKDRMNDDLLSEMPDKFGSCVPHTTRPKREYEIDGRDYHFVSSREEMEKDIQNHEFIEAGEYNDNLYGTSIESVREVAMEGKHCILDVSGNAIQRLIKADLYPIAIFIRPRSVENVREMNKRLTEEQAKEIFERAQELEEEFMKYFTAIVEGDTFEEIYNQVKSIIEEESG ## 恢复: 0.7595628415300546 ** 示例3: 补全 ** 对于某些用例,您可能只想对感兴趣的某些片段进行补全,而蛋白质的其余部分保持不变(例如, 设计抗体 CDRs)。 以下是使用 `inpaint` 接口的一个简单示例: ```python pdb_path = "/root/research/projects/ByProt/data/pdb_samples/5izu_proc.pdb" designer.set_structure(pdb_path) start_ids = [1, 50] end_ids = [10, 100] for i in range(5): out, ori_seg, designed_seg = designer.inpaint( start_ids=start_ids, end_ids=end_ids, generator_args={'temperature': 1.0} ) print(designed_seg) print('Original Segments:') print(ori_seg)
输出如下:
loading backbone structure from /root/research/projects/ByProt/data/pdb_samples/5izu_proc.pdb. [['MVKSLFRHRT'], ['DEPIEEFTPTPAFPALQRLSSVDVEGVAWRAGLRTGDFLLEVNGVNVVKVG']] [['MTKALFRHQT'], ['ETPIEEFTPTPAFPALQHLSSVDVEGAAYRAGLRTGDFLIEVNGVNVVKVG']] [['STESLFRHAT'], ['ETPIEEFTPTPAFPALQHLSSVDVEGVAWRAGLRTGDFLIEVNGINVVKVG']] [['ATARMFRHLT'], ['ETPIEEFTPTPAFPALQYLSSVDVEGVAWRAGLKTGDFLIEVNGVNVVKVG']] [['ARKAKFRRYT'], ['ETPIEEFTPTPAFPALQVLSSVDVEGVAWRAGMRTGDFLLEVNGVNVVKVG']] [['ADARLFREYT'], ['ETPIEEFTPTPAFPALQHLSAVDVEGVAWRAGLLTGDFLIEVNGVNVVKVG']] [['ALRALFKHST'], ['DTPIEEFTPTPAFPALQYMSSVEVEGVAWRAGLRTGDFLIEVNGVNVVKVG']] [['MLKMLFRHYT'], ['ETPIEEFTPTPAFPALQYLSSVDIDGMAWRAGLRTGDFLIEVNGDNVVKVG']] [['ADKALFRHHT'], ['STPIEEFTPTPAFPALQYLESVDVDGVAYRAGLCTGDFLIEVNGVNVVKVG']] [['AAAAAFRHST'], ['KTPIEEFTPTPAFPALQYLSRVEVDGMAWRAGLRTGDFLLEVNGVNVVRVG']] Original Segments: [['RTKRLFRHYT'], ['ETPIEEFTPTPAFPALQYLESVDVEGVAWRAGLRTGDFLIEVNGVNVVKVG']]
致谢
ByProt 对以下项目和个人表示感谢:
- PyTorch Lightning 和 lightning-hydra-template 为我们的开发过程提供了坚实的基础。
ByProt 从以下存储库获得灵感并使用/修改实现:
- jingraham/neurips19-graph-protein-design 用于预处理的 CATH 数据集和数据管道实现。
- facebook/esm 用于他们的 ESM 实现、预训练模型权重和数据管道组件如
Alphabet。 - dauparas/ProteinMPNN 用于 ProteinMPNN 实现和多链数据集。
- A4Bio/PiFold 用于他们的 PiFold 实现。
- jasonkyuyim/se3_diffusion 用于他们的自我一致性结构评估实现。
我们衷心感谢这些存储库的作者为 ByProt 的开发做出的宝贵贡献。
引用
@inproceedings{zheng2023lm_design, title={Structure-informed Language Models Are Protein Designers}, author={Zheng, Zaixiang and Deng, Yifan and Xue, Dongyu and Zhou, Yi and YE, Fei and Gu, Quanquan}, booktitle={International Conference on Machine Learning}, year={2023} }
编辑推荐精选


扣子-AI办公
职场AI,就用扣子
AI办公助手,复杂任务高效处理。办公效率低?扣子空间AI助手支持播客生成、PPT制作、网页开发及报告写作,覆盖科研、商业、舆情等领域的专家Agent 7x24小时响应,生活工作无缝切换,提升50%效率!


堆友
多风格AI绘画神器
堆友平台由阿里巴巴设计团队创建,作为一款AI驱动的设计工具,专为设计师提供一站式增长服务。功能覆盖海量3D素材、AI绘画、实时渲染以及专业抠图,显著提升设计品质和效率。平台不仅提供工具,还是一个促进创意交流和个人发展的空间,界面友好,适合所有级别的设计师和创意工作者。


码上飞
零代码AI应用开发平台
零代码AI应用开发平台,用户只需一句话简单描述需求,AI能自动生成小程序、APP或H5网页应用,无需编写代码。


Vora
免费创建高清无水印Sora视频
Vora是一个免费创建高清无水印Sora视频的AI工具


Refly.AI
最适合小白的AI自动化工作流平台
无需编码,轻松生成可复用、可变现的AI自动化工作流


酷表ChatExcel
大模型驱动的Excel数据处理工具
基于大模型交互的表格处理系统,允许用户通过对话方式完成数据整理和可视化分析。系统采用机器学习算法解析用户指令,自动执行排序、公式计算和数据透视等操作,支持多种文件格式导入导出。数据处理响应速度保持在0.8秒以内,支持超过100万行数据的即时分析。


TRAE编程
AI辅助编程,代码自动修复
Trae是一种自适应的集成开发环境(IDE),通过自动化和多元协作改变开发流程。利用Trae,团队能够更快速、精确地编写和部署代码,从而提高编程效率和项目交付速度。Trae具备上下文感知和代码自动完成功能,是提升开发效率的理想工具。


AIWritePaper论文写作
AI论文写作指导平台
AIWritePaper论文写作是一站式AI论文写作辅助工具,简化了选题、文献检索至论文撰写的整个过程。通过简单设定,平台可快速生成高质量论文大纲和全文,配合图表、参考文献等一应俱全,同时提供开题报告和答辩PPT等增值服务,保障数据安全,有效提升写作效率和论文质量。


博思AIPPT
AI一键生成PPT,就用博思AIPPT!
博思AIPPT,新一代的AI生成PPT平台,支持智能生成PPT、AI美化PPT、文本&链接生成PPT、导入Word/PDF/Markdown文档生成PPT等,内置海量精美PPT模板,涵盖商务、教育、科技等不同风格,同时针对每个页面提供多种版式,一键自适应切换,完美适配各种办公场景。


潮际好麦
AI赋能电商视觉革命,一站式智能商拍平台
潮际好麦深耕服装行业,是国内AI试衣效果最好的软件。使用先进AIGC能力为电商卖家批量提供优质的、低成本的商拍图。合作品牌有Shein、Lazada、安踏、百丽等65个国内外头部品牌,以及国内10万+淘宝、天猫、京东等主流平台的品牌商家,为卖家节省将近85%的出图成本,提升约3倍出图效率,让品牌能够快速上架。
推荐工具精选




AI云服务特惠
懂AI专属折扣关注微信公众号
最新AI工具、AI资讯
独家AI资源、AI项目落地

微信扫一扫关注公众号