


brain.js
适用于浏览器和Node.js的GPU加速神经网络JavaScript库
<p style="text-align: center" align="center"><a href="https://brain.js.org"><img src="https://img.shields.io/website?up_message=brain.js.org&url=https%3A%2F%2Fbrain.js.org" alt="GitHub"></a>





![]()

 <a href="https://twitter.com/brainjsfnd"><img src="https://img.shields.io/twitter/follow/brainjsfnd?label=Twitter&style=social" alt="Twitter"></a>
<a href="https://twitter.com/brainjsfnd"><img src="https://img.shields.io/twitter/follow/brainjsfnd?label=Twitter&style=social" alt="Twitter"></a>

关于
brain.js是一个用JavaScript编写的GPU加速神经网络库。
:bulb: 这是harthur/brain的延续,该项目已不再维护。更多信息
目录
安装和使用
NPM
您可以使用npm安装brain.js:
npm install brain.js
CDN
<script src="//unpkg.com/brain.js"></script>
下载
安装说明
Brain.js依赖于原生模块headless-gl来支持GPU。在大多数情况下,从npm安装brain.js应该能正常工作。但是,如果遇到问题,这意味着无法从GitHub仓库下载预构建的二进制文件,您可能需要自己构建。
从源代码构建
请确保已安装并更新以下依赖项,然后运行:
npm rebuild
系统依赖
Mac OS X
Ubuntu/Debian
- 支持的Python版本
- GNU C++环境(可通过
apt的build-essential包获得) - libxi-dev
- 工作正常且最新的OpenGL驱动程序
- GLEW
- pkg-config
sudo apt-get install -y build-essential libglew-dev libglu1-mesa-dev libxi-dev pkg-config
Windows
- 支持的Python版本 参见: https://apps.microsoft.com/store/search/python
- Microsoft Visual Studio Build Tools 2022
- 在cmd中运行:
npm config set msvs_version 2022注意:这在npm的现代版本中不再有效。 - 在cmd中运行:
npm config set python python3注意:这在npm的现代版本中不再有效。
* 如果您使用的是Build Tools 2017,则运行npm config set msvs_version 2017 注意:这在npm的现代版本中不再有效。
示例
以下是一个使用brain.js近似XOR函数的示例:
有关配置的更多信息,请参见此处。
:bulb: Brain.js的有趣实用介绍
// 提供可选的配置对象(或undefined)。显示默认值。 const config = { binaryThresh: 0.5, hiddenLayers: [3], // 网络中隐藏层大小的整数数组 activation: 'sigmoid', // 支持的激活类型:['sigmoid', 'relu', 'leaky-relu', 'tanh'] leakyReluAlpha: 0.01, // 支持'leaky-relu'激活类型 }; // 创建一个简单的前馈神经网络,使用反向传播 const net = new brain.NeuralNetwork(config); net.train([ { input: [0, 0], output: [0] }, { input: [0, 1], output: [1] }, { input: [1, 0], output: [1] }, { input: [1, 1], output: [0] }, ]); const output = net.run([1, 0]); // [0.987]
或者 有关配置的更多信息,请参见此处。
// 提供可选的配置对象,显示默认值。 const config = { inputSize: 20, inputRange: 20, hiddenLayers: [20, 20], outputSize: 20, learningRate: 0.01, decayRate: 0.999, }; // 创建一个简单的循环神经网络 const net = new brain.recurrent.RNN(config); net.train([ { input: [0, 0], output: [0] }, { input: [0, 1], output: [1] }, { input: [1, 0], output: [1] }, { input: [1, 1], output: [0] }, ]); let output = net.run([0, 0]); // [0] output = net.run([0, 1]); // [1] output = net.run([1, 0]); // [1] output = net.run([1, 1]); // [0]
然而,没有必要使用神经网络来解决异或问题。(-: 所以,这里有一个更复杂、更现实的例子: 演示:训练神经网络识别颜色对比度。
更多示例
你可以查看这个精彩的屏幕录像,它解释了如何使用真实世界的数据集训练一个简单的神经网络:如何使用 Brain.js 在浏览器中创建神经网络。
训练
使用 train() 方法来用一组训练数据训练网络。网络必须在一次 train() 调用中批量训练所有数据。更多的训练模式可能需要更长的训练时间,但通常会得到一个更擅长分类新模式的网络。
注意
训练在计算上是昂贵的,所以你应该尝试离线(或在 Worker 中)训练网络,并使用 toFunction() 或 toJSON() 选项将预训练的网络插入到你的网站中。
数据格式
使用 NeuralNetwork 进行训练
每个训练模式应该有一个 input 和一个 output,两者都可以是从 0 到 1 的数字数组,或者是从 0 到 1 的数字哈希。对于颜色对比度演示,它看起来像这样:
const net = new brain.NeuralNetwork(); net.train([ { input: { r: 0.03, g: 0.7, b: 0.5 }, output: { black: 1 } }, { input: { r: 0.16, g: 0.09, b: 0.2 }, output: { white: 1 } }, { input: { r: 0.5, g: 0.5, b: 1.0 }, output: { white: 1 } }, ]); const output = net.run({ r: 1, g: 0.4, b: 0 }); // { white: 0.99, black: 0.002 }
这是上述例子的另一个变体。(注意,输入对象不需要相似。)
net.train([ { input: { r: 0.03, g: 0.7 }, output: { black: 1 } }, { input: { r: 0.16, b: 0.2 }, output: { white: 1 } }, { input: { r: 0.5, g: 0.5, b: 1.0 }, output: { white: 1 } }, ]); const output = net.run({ r: 1, g: 0.4, b: 0 }); // { white: 0.81, black: 0.18 }
使用 RNNTimeStep、LSTMTimeStep 和 GRUTimeStep 进行训练
每个训练模式可以是:
- 一个数字数组
- 一个数字数组的数组
使用数字数组的例子:
const net = new brain.recurrent.LSTMTimeStep(); net.train([[1, 2, 3]]); const output = net.run([1, 2]); // 3
使用数字数组的数组的例子:
const net = new brain.recurrent.LSTMTimeStep({ inputSize: 2, hiddenLayers: [10], outputSize: 2, }); net.train([ [1, 3], [2, 2], [3, 1], ]); const output = net.run([ [1, 3], [2, 2], ]); // [3, 1]
使用 RNN、LSTM 和 GRU 进行训练
每个训练模式可以是:
- 一个值数组
- 一个字符串
- 有一个
input和一个output- 其中任何一个都可以是值数组或字符串
注意:当使用值数组时,你可以使用任何值,但是,这些值在神经网络中由单个输入表示。所以越多的不同值,输入层就越大。如果你有数百、数千或数百万个浮点值,这不是适合的类。此外,当偏离字符串时,这进入了测试阶段。
使用直接字符串的例子: 使用 Brainjs 的 Hello World
const net = new brain.recurrent.LSTM(); net.train(['I am brainjs, Hello World!']); const output = net.run('I am brainjs'); alert(output);
const net = new brain.recurrent.LSTM(); net.train([ 'doe, a deer, a female deer', 'ray, a drop of golden sun', 'me, a name I call myself', ]); const output = net.run('doe'); // ', a deer, a female deer'
使用带有输入和输出的��字符串的例子:
const net = new brain.recurrent.LSTM(); net.train([ { input: 'I feel great about the world!', output: 'happy' }, { input: 'The world is a terrible place!', output: 'sad' }, ]); const output = net.run('I feel great about the world!'); // 'happy'
使用 AE 进行训练
每个训练模式可以是:
- 一个数字数组
- 一个数字数组的数组
训练一个自编码器来压缩异或计算的值:
const net = new brain.AE( { hiddenLayers: [ 5, 2, 5 ] } ); net.train([ [ 0, 0, 0 ], [ 0, 1, 1 ], [ 1, 0, 1 ], [ 1, 1, 0 ] ]);
编码/解码:
const input = [ 0, 1, 1 ]; const encoded = net.encode(input); const decoded = net.decode(encoded);
去噪嘈杂数据:
const noisyData = [ 0, 1, 0 ]; const data = net.denoise(noisyData);
测试数据样本中的异常:
const shouldBeFalse = net.includesAnomalies([0, 1, 1]); const shouldBeTrue = net.includesAnomalies([0, 1, 0]);
训练选项
train() 方法的第二个参数是一个选项哈希:
net.train(data, { // 默认值 --> 预期验证 iterations: 20000, // 迭代训练数据的最大次数 --> 大于 0 的数字 errorThresh: 0.005, // 可接�受的训练数据误差百分比 --> 0 到 1 之间的数字 log: false, // true 使用 console.log,当提供函数时使用该函数 --> true 或函数 logPeriod: 10, // 日志输出之间的迭代次数 --> 大于 0 的数字 learningRate: 0.3, // 与 delta 一起缩放以影响训练速率 --> 0 到 1 之间的数字 momentum: 0.1, // 与下一层的变化值一起缩放 --> 0 到 1 之间的数字 callback: null, // 训练过程中可以触发的周期性回调 --> null 或函数 callbackPeriod: 10, // 回调调用之间的训练数据迭代次数 --> 大于 0 的数字 timeout: number, // 训练的最大毫秒数 --> 大于 0 的数字。默认 --> 无限 });
当满足以下两个条件之一时,网络将停止训练:训练误差低于阈值(默认 0.005),或达到最大迭代次数(默认 20000)。
默认情况下,训练不会让你知道它的进展,直到结束,但将 log 设置为 true 可以获得网络当前训练误差的定期更新。训练误差应该每次都会减少。更新将打印到控制台。如果你将 log 设置为一个函数,这��个函数将被调用来处理更新,而不是打印到控制台。
然而,如果你想在自己的输出中使用更新的值,可以将 callback 设置为一个函数来实现。
学习率是一个影响网络训练速度的参数。它是一个从 0 到 1 的数字。如果学习率接近 0,训练时间会更长。如果学习率接近 1,训练会更快,但训练结果可能会被限制在局部最小值,对新数据表现不佳(过拟合)。默认学习率是 0.3。
动量类似于学习率,也期望一个从 0 到 1 的值,但它是乘以下一层的变化值。默认值是 0.1。
这些训练选项中的任何一个都可以传入构造函数或传入 updateTrainingOptions(opts) 方法,它们将被保存在网络上并在训练时使用。如果你将网络保存为 json,这些训练选项也会被保存和恢复(除了 callback 和 log,callback 将被遗忘,log 将使用 console.log 恢复)。
默认情况下,一个名为invalidTrainOptsShouldThrow的布尔属性被设置为true。当该选项为true时,如果输入的训练选项超出正常范围,将抛出一个错误,并附带有关异常选项的消息。当该选项设置为false时,不会抛出错误,但相关信息仍会通过console.warn发送。
异步训练
trainAsync()接受与train相同的参数(数据和选项)。它不会直接返回训练结果对象,而是返回一个promise,当promise解决时会返回训练结果对象。不适用于以下类型:
brain.recurrent.RNNbrain.recurrent.GRUbrain.recurrent.LSTMbrain.recurrent.RNNTimeStepbrain.recurrent.GRUTimeStepbrain.recurrent.LSTMTimeStep
const net = new brain.NeuralNetwork(); net .trainAsync(data, options) .then((res) => { // 使用训练好的网络做些事情 }) .catch(handleError);
对于多个网络,你可以像这样并行训练:
const net = new brain.NeuralNetwork(); const net2 = new brain.NeuralNetwork(); const p1 = net.trainAsync(data, options); const p2 = net2.trainAsync(data, options); Promise.all([p1, p2]) .then((values) => { const res = values[0]; const res2 = values[1]; console.log( `net训练了${res.iterations}次迭代,net2训练了${res2.iterations}次迭代` ); // 用两个训练好的网络做一些很酷的事情 }) .catch(handleError);
交叉验证
交叉验证可以为大型数据集的训练提供一种更稳健的方法。brain.js API提供了以下交叉验证示例:
const crossValidate = new brain.CrossValidate(() => new brain.NeuralNetwork(networkOptions)); crossValidate.train(data, trainingOptions, k); // 注意k(或KFolds)是可选��的 const json = crossValidate.toJSON(); // 所有统计信息以及神经网络都在json中 const net = crossValidate.toNeuralNetwork(); // 从`crossValidate`中获取表现最佳的网络 // 可选的后续操作 const json = crossValidate.toJSON(); const net = crossValidate.fromJSON(json);
CrossValidate可以与以下类一起使用:
brain.NeuralNetworkbrain.RNNTimeStepbrain.LSTMTimeStepbrain.GRUTimeStep
使用交叉验证的示例可以在cross-validate.ts中找到
方法
train(trainingData) -> trainingStatus
train()的输出是一个包含训练信息的哈希:
{ error: 0.0039139985510105032, // 训练误差 iterations: 406 // 训练迭代次数 }
run(input) -> prediction
支持以下类:
brain.NeuralNetworkbrain.NeuralNetworkGPU-> 具有brain.NeuralNetwork的所有功能,但在GPU上运行(通过gpu.js在WebGL2、WebGL1上运行,或回退到CPU)brain.recurrent.RNNbrain.recurrent.LSTMbrain.recurrent.GRUbrain.recurrent.RNNTimeStepbrain.recurrent.LSTMTimeStepbrain.recurrent.GRUTimeStep
示例:
// 前馈网络 const net = new brain.NeuralNetwork(); net.fromJSON(json); net.run(input); // 时间步长 const net = new brain.LSTMTimeStep(); net.fromJSON(json); net.run(input); // 循环网络 const net = new brain.LSTM(); net.fromJSON(json); net.run(input);
forecast(input, count) -> predictions
以下类可用。输出预测数组。预测是输入的延续。
brain.recurrent.RNNTimeStepbrain.recurrent.LSTMTimeStepbrain.recurrent.GRUTimeStep
示例:
const net = new brain.LSTMTimeStep(); net.fromJSON(json); net.forecast(input, 3);
toJSON() -> json
将神经网络序列化为json
fromJSON(json)
从json反序列化神经网络
失败
如果网络训练失败,错误将超过错误阈值。这可能是因为训练数据太嘈杂(最有可能),网络没有足够的隐藏层或节�点来处理数据的复杂性,或者没有进行足够的迭代训练。
如果在20000次迭代后,训练误差仍然很大,比如0.4,这是一个很好的迹象,表明网络无法理解给定的数据。
RNN、LSTM或GRU输出太短或太长
网络实例的maxPredictionLength属性(默认为100)可以设置来调整网络的输出;
示例:
const net = new brain.recurrent.LSTM(); // 在代码的后面,在训练了几部小说之后,给我写一部新的! net.maxPredictionLength = 1000000000; // 小心使用! net.run('从前有一个');
JSON
使用JSON序列化或加载训练好的网络状态:
const json = net.toJSON(); net.fromJSON(json);
独立函数
你还可以从训练好的网络获取一个自定义的独立函数,其行为与run()相同:
const run = net.toFunction(); const output = run({ r: 1, g: 0.4, b: 0 }); console.log(run.toString()); // 复制粘贴!无需导入brain.js
选项
NeuralNetwork()接受一个选项哈希:
const net = new brain.NeuralNetwork({ activation: 'sigmoid', // 激活函数 hiddenLayers: [4], learningRate: 0.6, // 全局学习率,在使用流进行训练时很有用 });
activation
这个参数让你指定神经网络应该使用哪个激活函数。目前支持四种激活函数�,sigmoid是默认的:
- sigmoid
- relu
- leaky-relu
- 相关选项 - 'leakyReluAlpha' 可选数字,默认为0.01
- tanh
这里有一个表格(感谢维基百科!)总结了大量的激活函数 — 激活函数
hiddenLayers
你可以使用这个来指定网络中隐藏层的数量和每层的大小。例如,如果你想要两个隐藏层 - 第一层有3个节点,第二层有4个节点,你可以这样设置:
hiddenLayers: [3, 4];
默认情况下,brain.js使用一个隐藏层,其大小与输入数组的大小成正比。
流
使用https://www.npmjs.com/package/train-stream 将数据流式传输到NeuralNetwork
工具
likely
const likely = require('brain/likely'); const key = likely(input, net);
Likely示例参见:简单字母识别
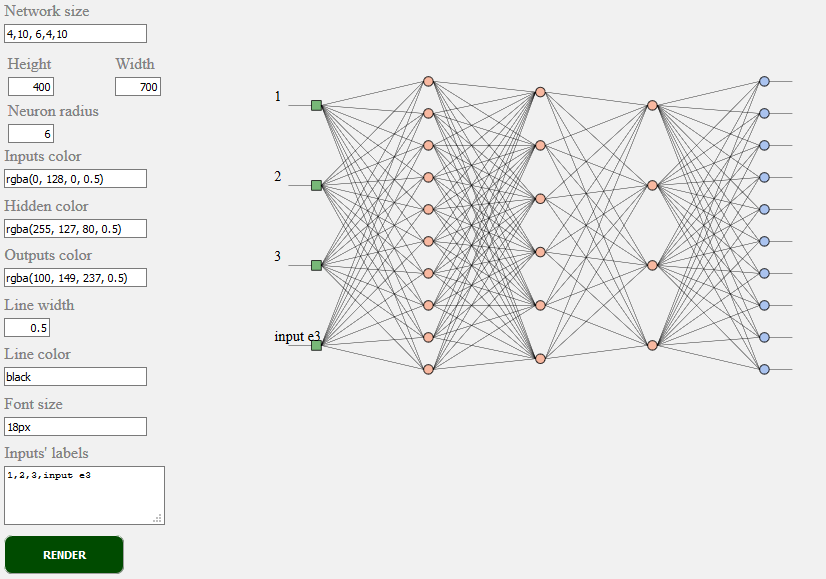
toSVG
<script src="../../src/utilities/svg.js"></script>
渲染前馈网络的网络拓扑
document.getElementById('result').innerHTML = brain.utilities.toSVG( network, options );
toSVG示例参见:网络渲染
使用的用户界面:
神经网络类型
brain.NeuralNetwork- 具有反向传播的前馈神经网络brain.NeuralNetworkGPU- 具有反向传播的前馈神经网络,GPU版本brain.AE- 具有反向传播和GPU支持的自编码器或"AE"brain.recurrent.RNNTimeStep- 时间步长递归神经网络或"RNN"brain.recurrent.LSTMTimeStep- 时间步长长短期记忆神经网络或"LSTM"brain.recurrent.GRUTimeStep- 时间步长门控循环单元或"GRU"brain.recurrent.RNN- 递归神经网络或"RNN"brain.recurrent.LSTM- 长短期记忆神经网络或"LSTM"brain.recurrent.GRU- 门控循环单元或"GRU"brain.FeedForward- 具有反向传播的高度可定制的前馈神经网络brain.Recurrent- 具有反向传播的高度可定制的递归神经网络
为什么有不同的神经网络类型
不同的神经网络擅长做不同的事情。例如:
- 前馈神经网络可以很好地分类简单的事物,但它没有先前动作的记忆,结果变化无穷。
- 时间步长递归神经网络能够"记忆",并可以预测未来的值。
- 递归神经网络能够"记忆",并有有限的结果集。
参与其中
W3C机器学习标准化进程
如果你是开发者,或者只是关心机器学习API应该是什么样子,请参与并加入W3C社区,分享你的观点或simply支持你喜欢或同意的观点。
Brain.js是JavaScript世界中广泛采用的开源机器学习库。这有几个原因,但最显著的是使用简单同时不牺牲性能。 我们希望在W3C标准方面也保持学习简单、使用简单和高性能。我们认为目前的brain.js API非常接近我们期望成为标准的样子。 由于提供支持不需要太多努力,但仍然可以产生巨大的影响,欢迎加入W3C社区组,并支持我们使用类似brain.js的API。
在这里参与W3C机器学习正在进行的标准化进程。 你也可以在这里加入我们关于标准化的公开讨论。
问题
如果你有问题,无论是bug还是你认为对你的项目有益的功能,请让我们知道,我们会尽最大努力。
在这里创建问题并按照模板进行操作。
brain.js.org
brain.js.org的源代码可在Brain.js.org仓库获得。使用了出色的vue.js和bulma构建。欢迎随时贡献。
贡献者
这个项目的存在要感谢所有做出贡献的人。[贡献]。 <a href="https://github.com/BrainJS/brain.js/graphs/contributors"><img src="https://yellow-cdn.veclightyear.com/835a84d5/529a3ec0-4039-40fa-8d61-4b44847f2daa.svg?width=890&button=false" /></a>
支持者
感谢所有我们的支持者!🙏 [成为支持者]
<a href="https://opencollective.com/brainjs#backers" target="_blank"><img src="https://yellow-cdn.veclightyear.com/835a84d5/f3822f5b-8c63-412b-9192-f8f5b79642c8.svg?width=890"></a>
赞助商
通过成为赞助商来支持这个项目。你的logo将出现在这里,并附有到你网站的链接。[成为赞助商]
<a href="https://opencollective.com/brainjs/sponsor/0/website" target="_blank"><img src="https://yellow-cdn.veclightyear.com/835a84d5/13f6c935-4da3-4ad7-862a-d65121491e85.svg"></a> <a href="https://opencollective.com/brainjs/sponsor/1/website" target="_blank"><img src="https://yellow-cdn.veclightyear.com/835a84d5/d95de445-a5c5-499e-bd04-06c0443f49a9.svg"></a> <a href="https://opencollective.com/brainjs/sponsor/2/website" target="_blank"><img src="https://yellow-cdn.veclightyear.com/835a84d5/1a52d529-1eb5-46e1-9f0a-0a8111fa5b57.svg"></a> <a href="https://opencollective.com/brainjs/sponsor/3/website" target="_blank"><img src="https://yellow-cdn.veclightyear.com/835a84d5/6d346982-7774-4d97-b67d-d8b3a901ab1e.svg"></a> <a href="https://opencollective.com/brainjs/sponsor/4/website" target="_blank"><img src="https://yellow-cdn.veclightyear.com/835a84d5/1c350f6b-5cf1-4995-a767-67b1bf5363c3.svg"></a> <a href="https://opencollective.com/brainjs/sponsor/5/website" target="_blank"><img src="https://yellow-cdn.veclightyear.com/835a84d5/d3399ba3-4a88-4d9f-8d29-50dd70ceabb6.svg"></a> <a href="https://opencollective.com/brainjs/sponsor/6/website" target="_blank"><img src="https://yellow-cdn.veclightyear.com/835a84d5/e73cfaca-9d2e-4b3a-afd9-541388c1bf56.svg"></a> <a href="https://opencollective.com/brainjs/sponsor/7/website" target="_blank"><img src="https://yellow-cdn.veclightyear.com/835a84d5/6884cc58-99d1-4b69-aaee-85dae10145a5.svg"></a> <a href="https://opencollective.com/brainjs/sponsor/8/website" target="_blank"><img src="https://yellow-cdn.veclightyear.com/835a84d5/9922bbcc-021c-4f73-b591-5e8348c50081.svg"></a> <a href="https://opencollective.com/brainjs/sponsor/9/website" target="_blank"><img src="https://yellow-cdn.veclightyear.com/835a84d5/62278327-3f46-45c3-b9c0-82560e67d74c.svg"></a>
编辑推荐精选


扣子-AI办公
职场AI,就用扣子
AI办公助手,复杂任务高效处理。办公效率低?扣子空间AI助手支持播客生成、PPT制作、网页开发及报告写作,覆盖科研、商业、舆情等领域的专家Agent 7x24小时响应,生活工作无缝切换,提升50%效率!


堆友
多风格AI绘画神器
堆友平台由阿里巴巴设计团队创建,作为一款AI驱动的设计工具,专为设计师提供一站式增长服务。功能覆盖海量3D素材、AI绘画、实时渲染以及专业抠图,显著提升设计品质和效率。平台不仅提供工具,还是一个促进创意交流和个人发展的空间,界面友好,适合所有级别的设计师和创意工作者。


码上飞
零代码AI应用开发平台
零代码AI应用开发平台,用户只需一句话简单描述需求,AI能自动生成小程序、APP或H5网页应用,无需编写代码。


Vora
免费创建高清无水印Sora视频
Vora是一个免费创建高清无水印Sora视频的AI工具


Refly.AI
最适�合小白的AI自动化工作流平台
无需编码,轻松生成可复用、可变现的AI自动化工作流


酷表ChatExcel
大模型驱动的Excel数据处理工具
基于大模型交互的表格处理系统,允许用户通过对话方式完成数据整理和可视化分析。系统采用机器学习算法解析用户指令,自动执行排序、公式计算和数据透视等操作,支持多种文件格式导入导出。数据处理响应速度保持在0.8秒以内,支持超过100万行数据的即时分析。


TRAE编程
AI辅助编程,代码自动修复
Trae是一种自适应的集成开发环境(IDE),通过自动化和多元协作改变开发流程。利用Trae,团队能够更快速、精确地编写和部署代码,从而提高编程效率和项目交付速度。Trae具备上下文感知和代码自动完成功能,是提升开发效率的理想工具。


AIWritePaper论文写作
AI论文写作指导平台
AIWritePaper论文写作是一站式AI论文写作辅助工具,简化了选题、文献检索至论文撰写的整个过程。通过简单设定,平台可快速生成高质量论文大纲和全文,配合图表、参考文献等一应俱全,同时提供开题报告和答辩PPT等增值服务,保障数据安全,有效提升写作效率和论文质量。


博思AIPPT
AI一键生成PPT,��就用博思AIPPT!
博思AIPPT,新一代的AI生成PPT平台,支持智能生成PPT、AI美化PPT、文本&链接生成PPT、导入Word/PDF/Markdown文档生成PPT等,内置海量精美PPT模板,涵盖商务、教育、科技等不同风格,同时针对每个页面提供多种版式,一键自适应切换,完美适配各种办公场景。


潮际好麦
AI赋能电商视觉革命,一站式智能商拍平台
潮际好麦深耕服装行业,是国内AI试衣效果最好的软件。使用先进AIGC能力为电商卖家批量提供优质的、低成本的商拍图。合作品牌有Shein、Lazada、安踏、百丽等65个国内外头部品牌,以及国内10万+淘宝、天猫、京东等主流平台的品牌商家,为卖家节省将近85%的出图成本,提升约3倍出图效率,让品牌能够快速上架。
推荐工具精选




AI云服务特惠
懂AI专属折扣关注微信公众号
最新AI工具、AI资讯
独家AI资源、AI项目落地

微信扫一扫关注公众号