MultiBench:多模态表示学习的多尺度基准测试套件
 Ray
RayMultiBench:多模态表示学习的多尺度基准测试套件
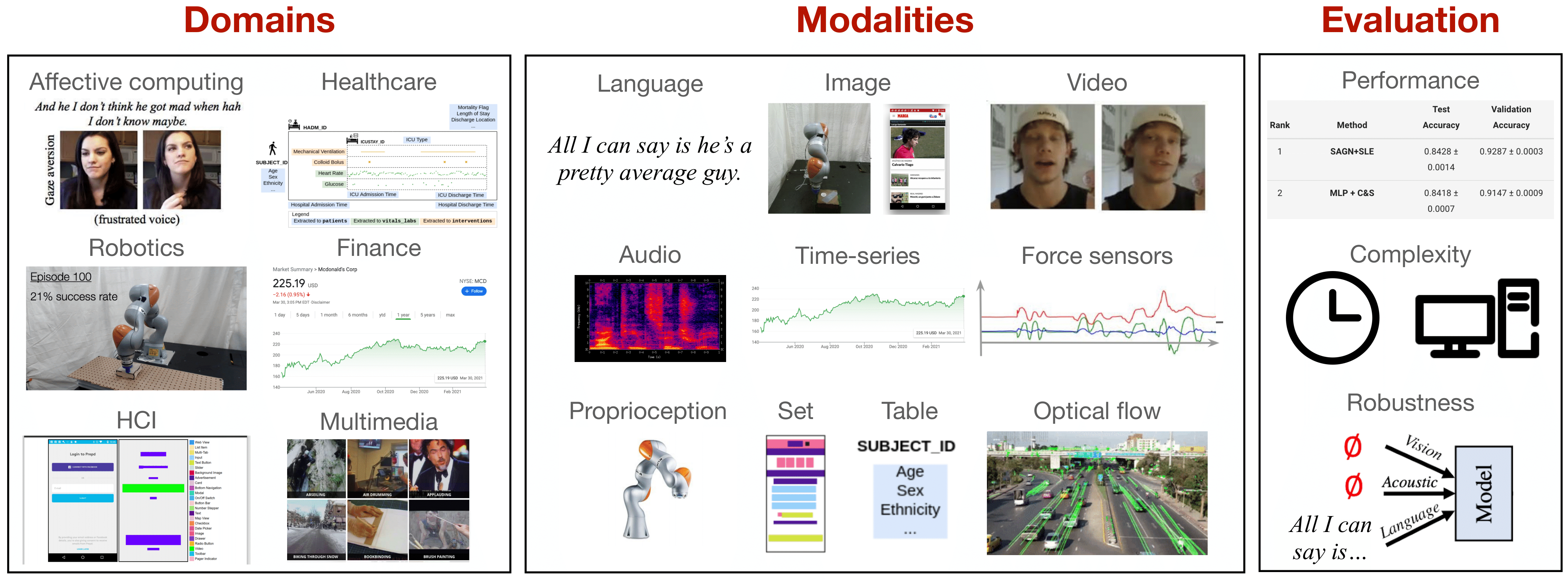
多模态表示学习是一个具有挑战性但至关重要的研究领域,涉及整合来自多个异构数据源的信息。它在多媒体、情感计算、机器人学、金融、人机交互和医疗保健等众多实际应用中发挥着关键作用。然而,多模态研究一直面临资源有限的问题,难以深入研究(1)跨领域和模态的泛化能力,(2)训练和推理过程中的复杂性,以及(3)对噪声和缺失模态的鲁棒性。
为了加速对未充分研究的模态和任务的进展,同时确保实际应用的鲁棒性,研究人员发布了MultiBench,这是一个系统化的大规模多模态学习基准测试套件,涵盖15个数据集、10种模态、20个预测任务和6个研究领域。MultiBench提供了一个自动化的端到端机器学习管道,简化和标准化了数据加载、实验设置和模型评估过程。为了反映实际需求,MultiBench旨在全面评估(1)跨领域和模态的性能,(2)训练和推理过程中的复杂性,以及(3)对噪声和缺失模态的鲁棒性。
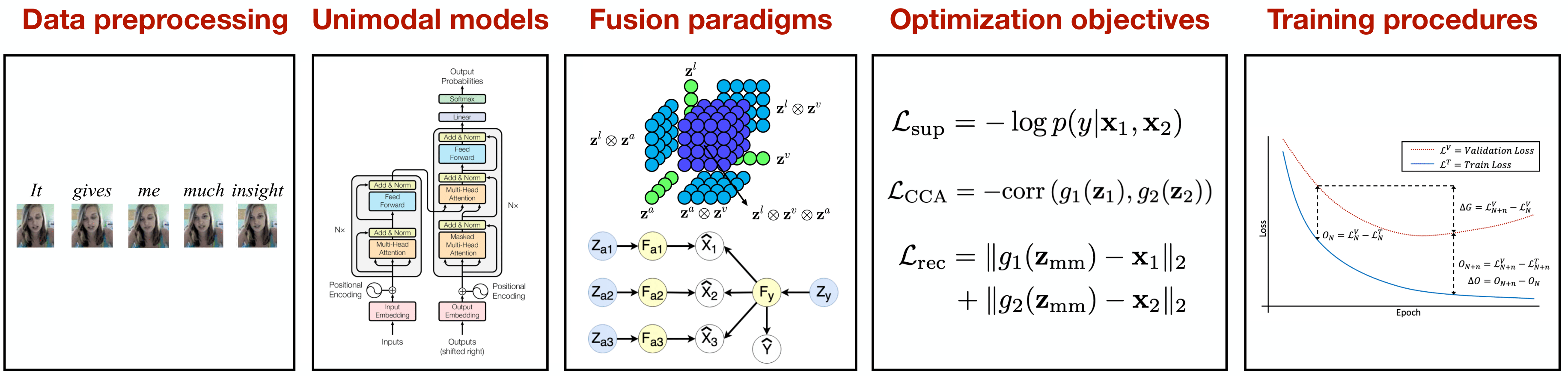
为了配合MultiBench,研究人员还提供了MultiZoo,这是20种核心多模态学习方法的标准化实现,统一了融合范式、优化目标和训练方法等创新。MultiZoo以模块化的方式实现这些方法,以便新研究人员易于使用,方法可组合,结果可复现。
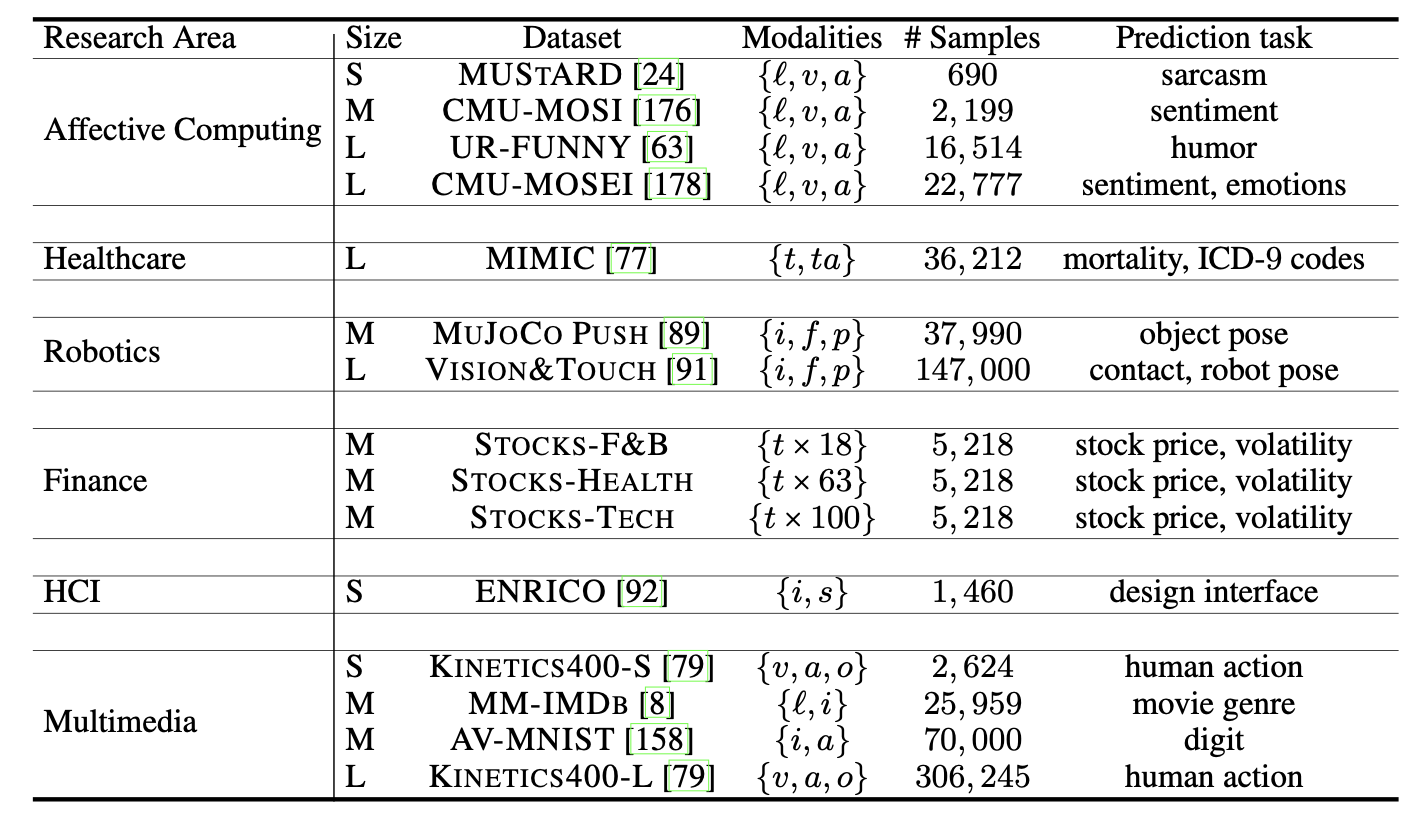
MultiBench支持的数据集
MultiBench目前支持以下数据集:
- 情感计算:MUStARD、CMU-MOSI、UR-FUNNY、CMU-MOSEI
- 医疗保健:MIMIC
- 机器人学:MuJoCo Push、Vision & Touch
- 金融:Stocks-food、Stocks-health、Stocks-tech
- 人机交互:ENRICO
- 多媒体:AV-MNIST、MM-IMDb、Kinetics-S、Kinetics-L
- RTFM环境
要添加新的数据集,可以按以下步骤进行:
- 进入datasets/目录
- 如果适当,添加一个新文件夹
- 编写一个包含get_dataloader函数的Python文件,该函数返回包含预处理数据的3个数据加载器(分别用于训练、验证和测试数据)的元组。请参考现有示例(如avmnist:datasets/avmnist/get_data.py)
- 进入examples/目录,按照现有示例编写一个示例训练Python文件
- 检查调用数据加载器并运行简单训练脚本是否正常工作
支持的算法
MultiBench支持以下类型的算法:
- 单模态模型:MLP、GRU、LeNet、CNN、LSTM、Transformer、FCN、Random Forest、ResNet等(参见unimodals/)
- 融合范式:早期/晚期融合、NL-gate、张量融合、乘法交互、低秩张量融合等(参见fusions/)
- 优化目标:(默认:分类任务使用CrossEntropyLoss,回归任务使用MSELoss)、ELBO、加权重建损失、CCA损失、对比损失等(参见objective_functions/)
- 训练结构:监督学习(支持早期融合、晚期融合、MVAE、MFM等)、Gradient Blend、架构搜索等(参见training_structures/)
要添加新算法,可以按以下步骤进行:
- 确定要添加到哪个子文件夹:
- unimodals/:单模态架构
- fusions/:多模态融合架构
- objective_functions/:除监督训练损失外的目标函数(如VAE损失、对比损失)
- training_structures/:不包括目标函数的训练算法(如平衡泛化、架构搜索外部RL循环)
- 参考examples/目录,按照现有示例编写一个示例训练Python文件
- 检查调用添加的函数并运行简单训练脚本是否正常工作
- 确保新模块通过注释充分说明其输入和输出格式�和形状
开放征集研究领域、数据集、任务、算法和评估
MultiBench欢迎通过新的研究领域、数据集、任务、算法和评估方法来做出贡献。请参考上述部分了解添加新数据集和算法的说明,如果您希望添加特定的数据集或算法,请提交pull request。研究人员计划将MultiBench作为未来研讨会、竞赛和学术课程的主题 - 敬请关注即将发布的参与邀请!
实验
MultiBench提供了多个领域的实验示例,包括情感计算、医疗保健、机器人学、金融、人机交互和多媒体。以下是一些实验示例:
情感计算
研究人员发布了处理后的数据集:sarcasm、mosi、mosei和humor。原始数据集也可以在MultimodalSDK(MOSI和MOSEI)、MUStARD和UR-FUNNY公开获取。可以使用datasets/affect/get_data.py获取处理后的数据,注意sarcasm指MUStARD,humor指UR-FUNNY。
examples/affect/目录下有几个运行情感数据集的示例脚本。例如,要使用简单的晚期融合运行情感数据集,首先可以使用:
traindata, validdata, test_robust = get_dataloader('/home/pliang/multibench/affect/pack/mosi/mosi_raw.pkl', data_type='mosi')
或者,如果不想使用打包数据,并期望具有相同最大序列长度的数据,请使用max_pad和max_seq_len选项,并记得在train和test函数中设置is_packed=False:
traindata, validdata, testdata = get_dataloader('/home/pliang/multibench/affect/pack/mosi/mosi_raw.pkl', data_type='mosi', max_pad=True, max_seq_len=50)
然后执行:
python3 examples/affect/affect_late_fusion.py
医疗保健
MIMIC数据集的访问受到限制。要获取此数据集的预处理版本,请按照这里的说明获取必要的凭据。获得凭据后,请发送电子邮件至yiweilyu@umich.edu,提供凭据证明并索要预处理的"im.pk"文件。
获得"im.pk"文件后,可以通过调用examples/mimic/get_data.py中的get_dataloader函数来获取此数据集的数据加载器。get_dataloader函数有2个输入:第一个指定要执行的任务(-1表示死亡率任务,1表示icd9 10-19任务,7表示ic9 70-79任务)。输入模态将是静态(大小为5的向量)和时间序列(形状为24x30)。
examples/healthcare/目录下有几个运行MIMIC�的示例脚本。例如,要使用低秩张量融合运行MIMIC,执行:
python3 examples/healthcare/mimic_low_rank_tensor.py
机器人学
Vision & Touch
对于Vision and Touch数据集,dataset/robotics/文件夹中包含下载数据集的脚本(download_data.sh)。下载数据后,使用dataset/robotics/data_loader.py访问预处理的数据加载器。请注意,此数据集只有训练集和验证集,因此输出将是2个数据加载器的元组而不是3个。默认任务是Contact,但可以通过将"output='ee_yaw_next'"作为参数传递给get_data函数来获取End Effector任务的数据加载器。
有关此数据集的更详细信息,请参阅原始repo。
examples/robotics/目录下有几个运行Vision and Touch的示例脚本。例如,要在Contact任务上使用低秩张量融合运行Vision and Touch,执行:
python3 examples/robotics/LRTF.py
MuJoCo Push (Gentle Push)
MuJoCo Push实验的代码位于examples/gentle_push目录下。每种模型类型在此目录下都有自己的Python文件,可以直接执行以运行实验。
例如,要运行晚期融合模型:
python examples/gentle_push/LF.py
这也会在第一次运行时将数据集下载到datasets/gentle_push/cache。由于原始数据集托管在Google Drive上,有时自动下载可能会因各种原因失败。在Colab上运行可以解决这个问题。此外,您可以手动下载这些文件并将它们放在正确的位置:
- 下载gentle_push_10.hdf5到
datasets/gentle_push/cache/1qmBCfsAGu8eew-CQFmV1svodl9VJa6fX-gentle_push_10.hdf5。 - 下载gentle_push_300.hdf5到
datasets/gentle_push/cache/18dr1z0N__yFiP_DAKxy-Hs9Vy_AsaW6Q-gentle_push_300.hdf5。 - 下载gentle_push_1000.hdf5到
datasets/gentle_push/cache/1JTgmq1KPRK9HYi8BgvljKg5MPqT_N4cR-gentle_push_1000.hdf5。
金融
金融实验的代码位于examples/finance目录下。每种模型类型在此目录下都有自己的Python文件。每个文件接受两个参数,--input-stocks和--target-stock。例如,要在论文中基准测试的股票上运行简单的晚期融合:
python examples/finance/stocks_late_fusion.py --input-stocks 'MCD SBUX HSY HRL' --target-stock 'MCD'
python examples/finance/stocks_late_fusion.py --input-stocks 'AAPL MSFT AMZN INTC AMD MSI' --target-stock 'MSFT'
python examples/finance/stocks_late_fusion.py --input-stocks 'MRK WST CVS MCK ABT UNH TFX' --target-stock 'UNH'
您可以指定任意股票进行下载。数据加载器将自动为您下载数据。如果股票不覆盖datasets/stocks/get_data.py中定义的日期范围,可以指定不同的日期范围。
对于单模态实验,运行stocks_early_fusion.py,将相同的股票传递给--input-stocks和--target-stock。
以下是论文中概述的每个类别下的完整股票列表:
- F&B (18): CAG CMG CPB DPZ DRI GIS HRL HSY K KHC LW MCD MDLZ MKC SBUX SJM TSN YUM
- Health (63): ABT ABBV ABMD A ALXN ALGN ABC AMGN ANTM BAX BDX BIO BIIB BSX BMY CAH CTLT CNC CERN CI COO CVS DHR DVA XRAY DXCM EW GILD HCA HSIC HOLX HUM IDXX ILMN INCY ISRG IQV JNJ LH LLY MCK MDT MRK MTD PKI PRGO PFE DGX REGN RMD STE SYK TFX TMO UNH UHS VAR VRTX VTRS WAT WST ZBH ZTS
- Tech (100): AAPL ACN ADBE ADI ADP ADSK AKAM AMAT AMD ANET ANSS APH ATVI AVGO BR CDNS CDW CHTR CMCSA CRM CSCO CTSH CTXS DIS DISCA DISCK DISH DXC EA ENPH FB FFIV FIS FISV FLIR FLT FOX FOXA FTNT GLW GOOG GOOGL GPN HPE HPQ IBM INTC INTU IPG IPGP IT JKHY JNPR KEYS KLAC LRCX LUMN LYV MA MCHP MPWR MSFT MSI MU MXIM N
编辑推荐精选


扣子-AI办公
职场AI,就用扣子
AI办公助手,复杂任务高效处理。办公效率低?扣子空间AI助手支持播客生成、PPT制作、网页开发及报告写作,覆盖科研、商业、舆情等领域的专家Agent 7x24小时响应,生活工作无缝切换,提升50%效率!


堆友
多风格AI绘画神器
堆友平台由阿里巴巴设计团队创建,作为一款AI驱动的设计工具,专为设计师提供一站式增长服务。功能覆盖海量3D素材、AI绘画、实时渲染以及专业抠图,显著提升设计品质和效率。平台不仅提供工具,还是一个促进创意交流和个人发展的空间,界面友好,适合所有级别的设计师和创意工作者。


码上飞
零代码AI应用开发平台
零代码AI应用开发平台,用户只需一句话简单描述需求,AI能自动生成小程序、APP或H5网页应用,无需编写代码。


Vora
免费创建高清无水印Sora视频
Vora是一个免费创建高清无水印Sora视频的AI工具


Refly.AI
最适合小白的AI自动化工作流平台
无需编码,轻松生成可复用、可变现的AI自动化工作流


酷表ChatExcel
大模型驱动的Excel数据处理工具
基于大模型交互的表格处理系统,允许用户通过对话方式完成数据整理和可视化分析。系统采用机器学习算法解析用户指令,自动执行排序、公式计算和数据透视等操作,支持多种文件格式导入导出。数据处理响应速度保持在0.8秒以内,支持超过100万行数据的即时分析。


TRAE编程
AI辅助编程,代码自动修复
Trae是一种自适应的集成开发环境(IDE),通过自动化和多元协作改变开发流程。利用Trae,团队能够更快速、精确地编写和部署代码,从而提高编程效率和项目交付速度。Trae具备上下文感知和代码自动完成功能,是提升开发效率的理想工具。


AIWritePaper论文写作
AI论文写作指导平台
AIWritePaper论文写作是一站式AI论文写作辅助工具,简化了选题、文献检索至论文撰写的整个过程。通过简单设定,平台可快速生成高质量论文大纲和全文,配合图表、参考文献等一应俱全,同时提供开题报告和答辩PPT等增值服务,保障数据安全,有效提升写作效率和论文质量。


博思AIPPT
AI一键生成PPT,就用博思AIPPT!
博思AIPPT,新一代的AI生成PPT平台,支持智能生成PPT、AI美化PPT、文本&链接生成PPT、导入Word/PDF/Markdown文档生成PPT等,内置海量精美PPT模板,涵盖商务、教育、科技等不同风格,同时针对每个页面提供多种版式,一键自适应切换,完美适配各种办公场景。


潮际好麦
AI赋能电商视觉革命,一站式智能商拍平台
潮际好麦深耕服装行业,是国内AI试衣效果最好的软件。使用先进AIGC能力为电商卖家批量提供优质的、低成本的商拍图。合作品牌有Shein、Lazada、安踏、百丽等65个国内外头部品牌,以及国内10万+淘宝、天猫、京东等主流平台的品牌商家,为卖家节省将近85%的出图成本,提升约3倍出图效率,让品牌能够快速上架。
推荐工具精选




AI云服务特惠
懂AI专属折扣关注微信公众号
最新AI工具、AI资讯
独家AI资源、AI项目落地

微信扫一扫关注公众号