Markdown-Crawler: 一款强大的网页爬虫与Markdown转换工具
 Ray
Ray🚀 Markdown-Crawler简介
Markdown-Crawler是由开发者Paul Pierre创建的一款功能强大的网页爬虫工具。它采用多线程技术,能够高效地爬取网站内容,并将每个页面转换为Markdown格式的文件。这个工具的主要目标是简化大型语言模型(LLM)在文档处理和解析方面的工作,尤其适用于RAG(检索增强生成)等场景。
Markdown格式本身具有易读性强、结构清晰的特点,同时文件体积相对较小。这使得Markdown-Crawler在保留文档结构的同时,能够生成便于人类阅读和机器处理的输出文件。
✨ 主要特性
Markdown-Crawler拥有许多令人印象深刻的功能:
- 🧵 多线程支持,大幅提升爬取速度
- ⏯️ 断点续爬功能,可从上次停止的地方继续
- ⏬ 可设置最大爬取深度
- 📄 支持表格、图片等复杂元素的转换
- ✅ 自动验证URL、HTML和文件路径
- ⚙️ 可配置有效的基础路径或域名列表
- 🍲 使用BeautifulSoup解析HTML
- 🪵 详细的日志记录选项
- 👩💻 即用型命令行界面
这些特性使Markdown-Crawler成为一个灵活且强大的工具,能够满足各种网页爬取和转换需求。
🏗️ 应用场景
Markdown-Crawler的应用范围相当广泛,以下是一些典型的使用场景:
-
RAG(检索增强生成):这是该工具的主要用例。它可以将大型文档标准化,并按标题、段落或句子进行分块,为RAG模型提供高质量的输入数据。
-
LLM微调:可以用来创建大规模的Markdown文件语料库,作为微调过程的第一步。随后可以利用GPT-3.5-turbo或Mistral-7B等模型从中提取问答对。
-
智能代理知识库构建:结合autogen等工具,可以为专家系统代理构建知识库。例如,如果需�要重建某个视频游戏或电影的知识体系,可以使用Markdown-Crawler生成相应的专家知识库。
-
智能代理/LLM工具:用于在线RAG学习,使聊天机器人能够持续学习。可以结合搜索引擎结果,爬取并索引排名靠前的网页内容。
-
文档管理系统:可以用于将大型网站或知识库转换为易于管理和搜索的Markdown文件集合。
-
内容分析:通过将网页内容转换为结构化的Markdown格式,便于进行后续的文本分析和数据挖掘工作。
-
离线阅读:可以将喜欢的网站内容爬取并转换为Markdown,方便在没有网络的环境下阅读。
🚀 快速上手
要开始使用Markdown-Crawler,您可以通过以下几种方式:
- 通过pip安装:
pip install markdown-crawler
- 使用命令行界面:
markdown-crawler -t 5 -d 3 -b ./markdown https://en.wikipedia.org/wiki/Morty_Smith
这个命令会使用5个线程,爬取深度为3,并将结果保存在./markdown目录下。
- 在Python代码中使用:
from markdown_crawler import md_crawl url = 'https://en.wikipedia.org/wiki/Morty_Smith' md_crawl(url, max_depth=3, num_threads=5, base_path='markdown')
⚙️ 配置选项
Markdown-Crawler提供了多种配置选项,使用户能够根据具体需求自定义爬取行为:
max_depth:设置最大爬取深度num_threads:指定使用的线程数base_path:设置Markdown文件的保存路径valid_paths:指定有效的相对URL路径列表target_content:使用CSS选择器指定要爬取的HTML元素is_domain_match:是否只爬取同一域名下的页面is_base_path_match:是否包含不以基础URL开头的同域名页面is_debug:是否启用详细日志输出
这些选项可以通过命令行参数或在代码中直接设置。
🛠️ 技术实现
Markdown-Crawler主要依赖以下Python库:
- BeautifulSoup4:用于解析HTML
- requests:处理HTTP请求
- markdownify:将HTML转换为Markdown格式
工具的核心逻辑包括:
- 使用requests库发送HTTP请求获取网页内容
- 利用BeautifulSoup解析HTML结构
- 通过markdownify将HTML转换为Markdown格式
- 使用多线程技术并行处理多个页面
- 实现断点续爬功能,保存爬取进度
- 提供灵活的配置选项,适应不同的爬取需求
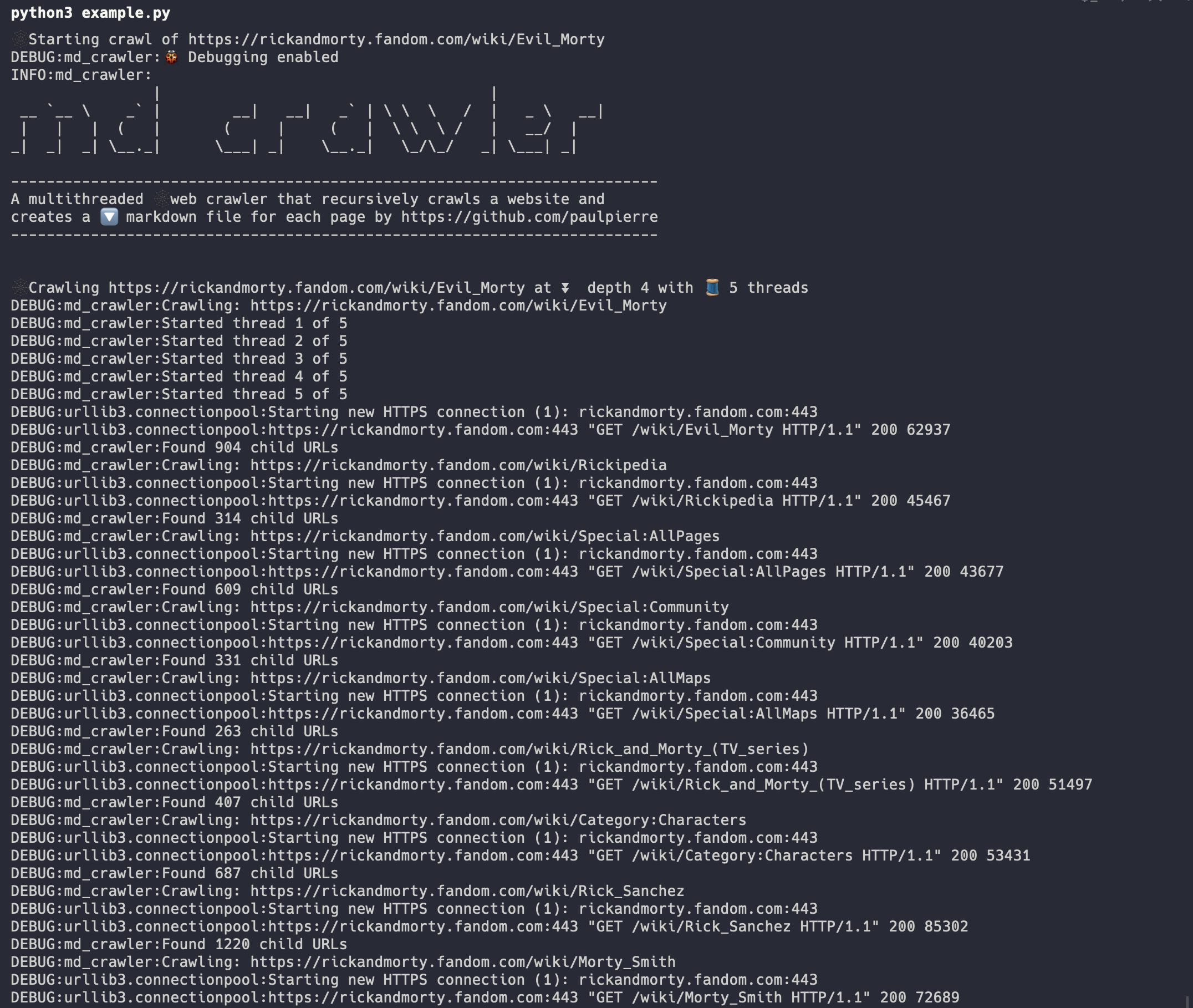
📊 性能与效果
Markdown-Crawler的多线程设计显著提高了爬取效率。以下是一个实际使用的例子:
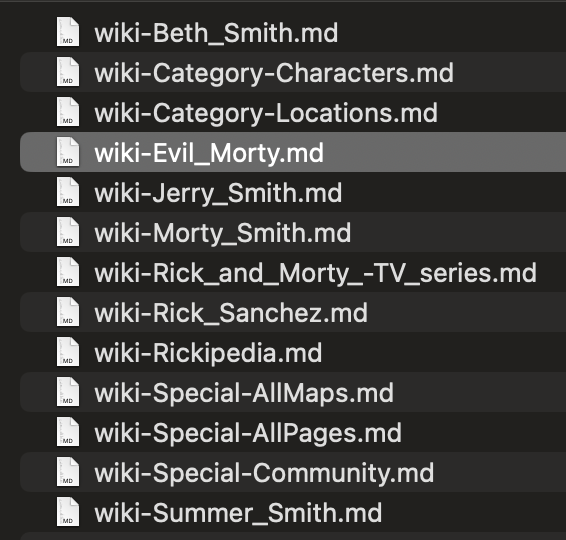
可以看到,工具能够快速生成大量的Markdown文件,每个文件对应一个网页。
转换后的Markdown内容保留了原始HTML的结构和格式:
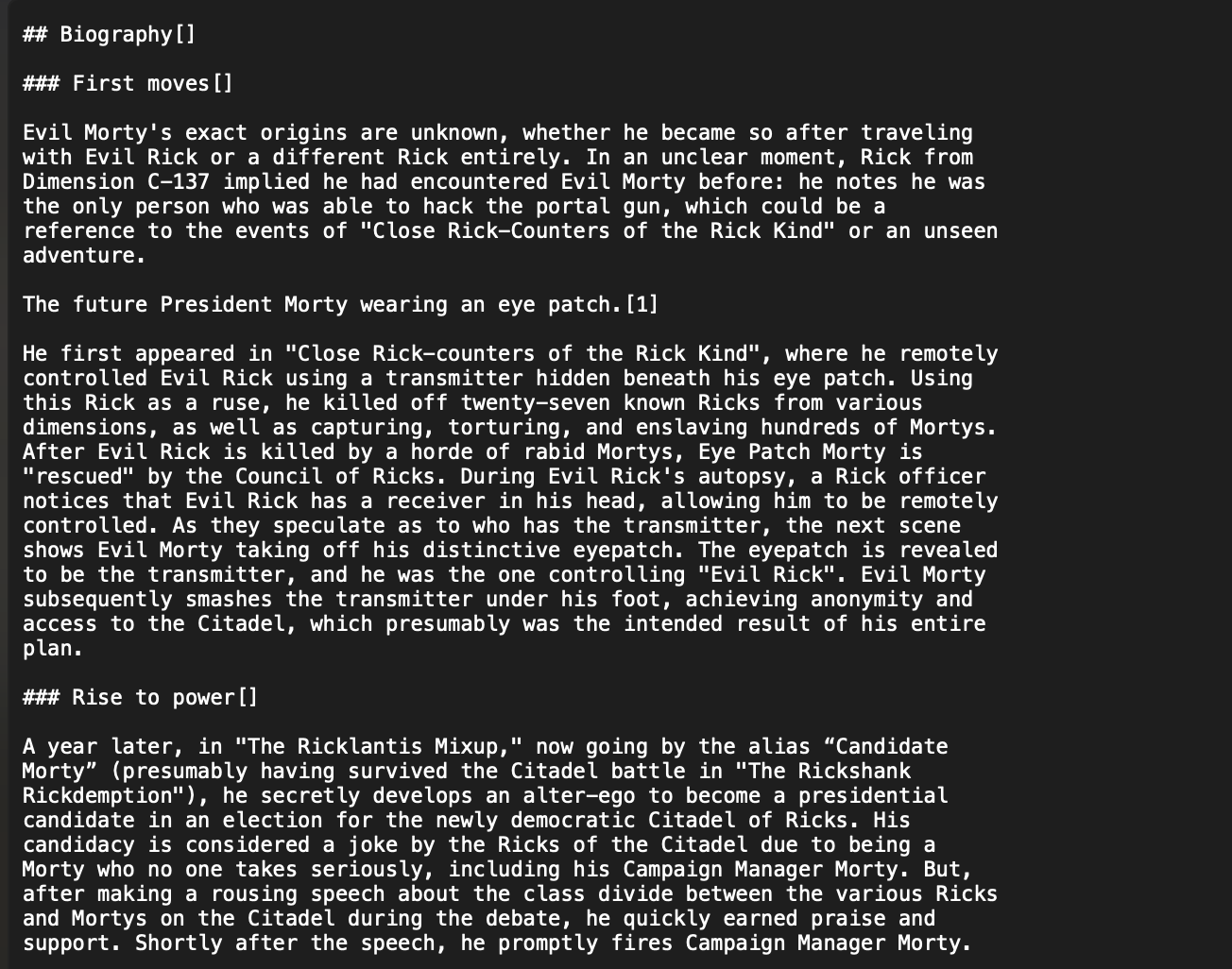
这种格式既便于人类阅读,也适合机器处理,为后续的NLP任务提供了理想的输入。
🤝 社区贡献
Markdown-Crawler是一个开源项目,欢迎社区成员参与贡献。如果您在使用过程中遇到任何问题,可以在GitHub上提出issue或提交PR。开发者Paul Pierre也欢迎通过Twitter/X进行交流。
- 在Twitter / X上关注作者
- 在Github上为项目点星
📜 许可证
Markdown-Crawler采用MIT许可证,这意味着您可以自由地使用、修改和分发这个工具,但需要保留原始的版权和许可声明。
值得一提的是,Markdown-Crawler使用了Matthew Tretter开发的markdownify库。该库的源代码可以在这里找到,同样采用MIT许可证。
🔮 未来展望
随着大语言模型和RAG技术的不断发展,Markdown-Crawler这样的工具将在数据预处理和知识提取方面发挥越来越重要的作用。未来,我们可以期待看到:
- 更智能的内容提取算法,能够更准确地识别和保留关键信息
- 与各种LLM平台的深度集成,实现端到端的知识获取和应用流程
- 支持更多格式的输出,如JSON-LD等结构化数据格式
- 增强的多语言支持,使工具能够处理更广泛的国际化内容
- 集成自然语言理解功能,自动生成内容摘要和关键词提取
总之,Markdown-Crawler为大规模网页内容的结构化处理提供了一个强大而灵活的解决方案。无论是在学术研究、商业应用还是个人项目中,它都能成为处理和转换网页内容的得力助手。
编辑推荐精选

小云雀
字节旗下AI内容创作Agent
小云雀是字节跳动旗下剪映团队推出的AI内容创作Agent,主打”一句话打造一个爆款”的零门槛创作体验。用户只需输入一句指令,可自动生成15-60秒短视频、数字人口播视频、风格化海报等内容,支持200+可商用数字人形象和19种语言及方言。小云雀核心功能包括智能成片、AI设计、照片会说话、爆款复刻等,已接入豆包大模型、DeepSeek Chat及自研Seedance 2.0视频生成模型、Seedream 5.0图像生成模型。目前支持安卓APP和网页版,每日登录可领取120积分。适合自媒体创作者、电商营销人员、教育工作者及普通用户使用,近期因用户量激增,视频生成排队时长可达8小时。


豆包
字节跳动旗下 AI 智能助手
字节跳动旗下 AI 智能助手


Pixmax
一站式AI短剧创作平台
Pixmax专注打造下一代“ AI 视觉创作引擎”,整合行业顶尖 AI 大模型、工工业级精准控制及企业级协同管理功能,是全方位的 AI 内容创作平台。


GPT Plus|Pro充值
GPT充值
支持 ChatGPT Plus / Pro 充值服务,支付便捷,自动发货,售后可查。


GPT Image 2中文站
AI 图片生成平台
GPT Image 2 是面向用户的 AI 图片生成平台,支持文生图、图生图及多模型创意工作流。


Vecbase
你的AI Agent团队
Vecbase 是专为 AI 团队打造的智能工作空间,将数据管理、模型协作与知识沉淀整合于一处。算法、产品与业务在同一平台无缝协同,让从数据到 AI 应用的落地更快一步。


音述AI
全球首个AI音乐社区
音述AI是全球首个AI音乐社区,致力让每个人都能用音乐表达自我。音述AI提供零门槛AI创作工具,独创GETI法则帮助用户精准定义音乐风格,AI润色功能支持自动优化作品质感。音述AI支持交流讨论、二次创作与价值变现。针对中文用户的语言习惯与文化背景进行专门优化,支持国风融合、C-pop等本土音乐标签,让技术更好地承载人文表达。


QoderWork
阿里Qoder团队推出的桌面端AI智能体
QoderWork 是阿里推出的本地优先桌面 AI 智能体,适配 macOS14+/Windows10+,以自然语言交互实现文件管理、数据分析、AI 视觉生成、浏览器自动化等办公任务,自主拆解执行复杂工作流,数据本地运行零上传,技能市场可无限扩展,是高效的 Agentic 生产力办公助手。


lynote.ai
一站式搞定所有学习需求
不再被海量信息淹没,开始真正理解知识。Lynote 可摘要 YouTube 视频、PDF、文章等内容。即时创建笔记,检测 AI 内容并下载资料,将您的学习效率提升 10 倍。


AniShort
为AI短剧协作而生
专为AI短剧协作而生的AniShort正式发布,深度重构AI短剧全流程生产模式,整合创意策划、制作执行、实时协作、在线审片、资产复用��等全链路功能,独创无限画布、双轨并行工业化工作流与Ani智能体助手,集成多款主流AI大模型,破解素材零散、版本混乱、沟通低效等行业痛点,助力3人团队效率提升800%,打造标准化、可追溯的AI短剧量产体系,是AI短剧团队协同创作、提升制作效率的核心工具。
推荐工具精选






AI云服务特惠
懂AI专属折扣关注微信公众号
最新AI工具、AI资讯
独家AI资源、AI项目落地

微信扫一扫关注公众号