LongRoPE:突破200万token的大语言模型上下文窗口扩展技术
 Ray
RayLongRoPE:突破大语言模型上下文长度限制的创新技术
在自然语言处理(NLP)领域,大语言模型(LLMs)的发展一直受到上下文窗口长度的限制。传统的Transformer架构在处理长序列时面临着自注意力机制的计算复杂度呈二次方增长的挑战,同时也难以泛化到训练时未见过的token位置。尽管业界提出了诸如RoPE、AliBi、注意力汇聚点等多种方法来扩展自注意力的计算范围,但这些解决方案在扩展到数百万token的同时保持模型准确性方面仍然存在不足。
近期,一项名为LongRoPE的创新技术引起了研究界的广泛关注。这项技术首次将预训练大语言模型的上下文窗口扩展到了惊人的2048k tokens,仅需在256k训练长度内进行不超过1k步的微调,同时保持了原有短上下文窗口的性能。本文将深入探讨LongRoPE的工作原理、实现细节及其在NLP领域的潜在应用。
LongRoPE的核心思想
LongRoPE的核心思想可以概括为以下三点:
-
识别和利用位置嵌入中的两种非均匀性,以最小化插值过程中的信息损失。这使得模型能够在不进行微调的情况下实现8倍的上下文扩展。
-
采用高效的渐进式扩展策略,通过256k的微调来达到2048k的上下文长度,而不是直接对极长的上下文进行微调。
-
对较短上下文的嵌入进行调整,以恢复原始窗口大小内的性能。
这种方法已经成功应用于LLaMA2和Mistral等知名大语言模型,并在各种需要长上下文的任务中展现出了卓越的性能。
LongRoPE的技术实现
LongRoPE的实现涉及多个关键组件,包括旋转位置编码(RoPE)、非均匀插值和渐进式扩展策略。
旋转位置编码(RoPE)
旋转位置编码是LongRoPE的基础,它通过将位置信息编码到token的表示中,使模型能够理解序列中token的相对位置。以下是RoPE的简化实现:
class RoPEPositionalEncoding(nn.Module): def __init__(self, d_model, max_len=1000000, base=10000): super().__init__() self.d_model = d_model self.max_len = max_len self.base = base self.theta = torch.tensor([base ** (-2 * (i // 2) / d_model) for i in range(d_model)]) def forward(self, positions): angles = positions.unsqueeze(-1) * self.theta sin_cos = torch.stack([angles.cos(), angles.sin()], dim=-1) return sin_cos.view(*sin_cos.shape[:-2], -1)
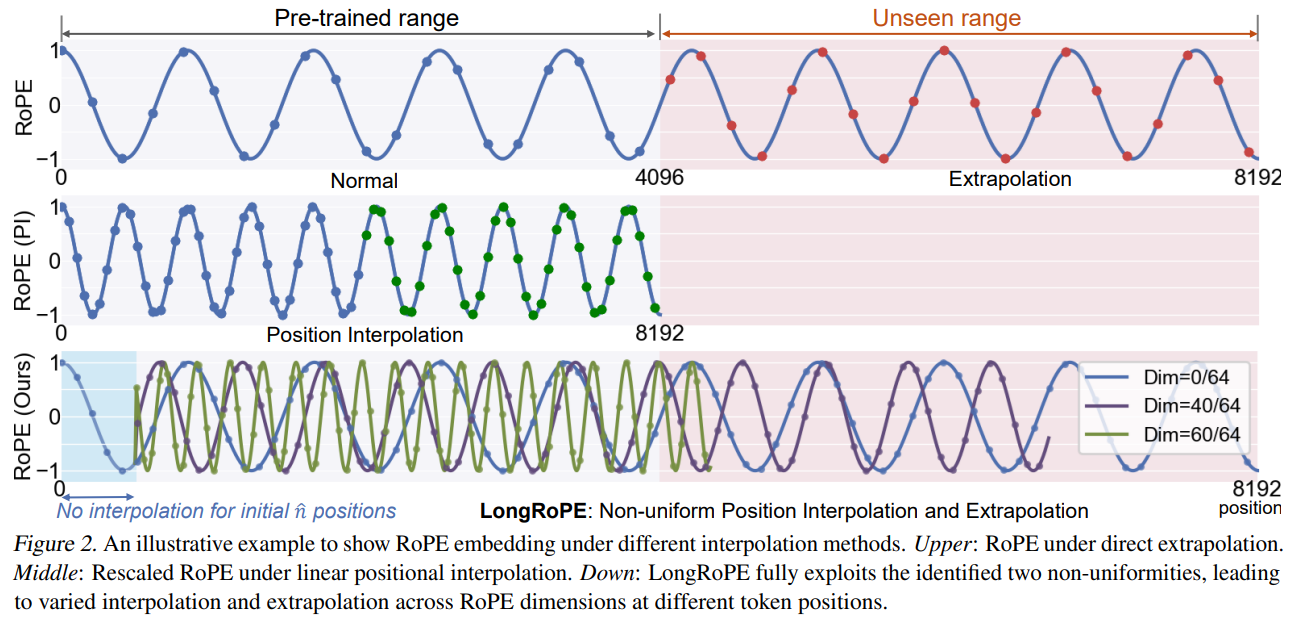
非均匀插值
非均匀插值是LongRoPE能够实现上下文扩展的关键技术。它通过识别位置嵌入中的非均匀性,最小化了插值过程中的信息损失:
def non_uniform_interpolation(pos_embed, extension_ratio, lambda_factors, n_hat): d_model = pos_embed.shape[-1] interpolated_pos = pos_embed.clone() for i in range(d_model // 2): mask = torch.arange(pos_embed.shape[-2], device=pos_embed.device) < n_hat scale = torch.where(mask, torch.ones_like(pos_embed[..., 0], device=pos_embed.device), 1 / (lambda_factors[i] * extension_ratio)) interpolated_pos[..., 2 * i] *= scale interpolated_pos[..., 2 * i + 1] *= scale return interpolated_pos
渐进式扩展策略
LongRoPE采用渐进式扩展策略,通过多个阶段逐步扩展上下文窗口,避免了直接对极长上下文进行微调的困难:
def progressive_extension(model, data, base_length, target_length, population_size, num_mutations, num_crossovers, max_iterations): # 扩展到128k lambda_factors_128k, n_hat_128k = search_lambda_factors(model, data, 128000 / base_length, population_size, num_mutations, num_crossovers, max_iterations) model = fine_tune(model, data, 128000, lambda_factors_128k, n_hat_128k, steps=400) # 扩展到256k lambda_factors_256k, n_hat_256k = search_lambda_factors(model, data, 256000 / base_length, population_size, num_mutations, num_crossovers, max_iterations) model = fine_tune(model, data, 256000, lambda_factors_256k, n_hat_256k, steps=600) # 扩展到目标长度 if target_length > 256000: final_lambda_factors, final_n_hat = search_lambda_factors(model, data, target_length / base_length, population_size // 2, num_mutations // 2, num_crossovers // 2, max_iterations // 2) model.lambda_factors["2048k"] = final_lambda_factors model.n_hat["2048k"] = final_n_hat return model, final_lambda_factors, final_n_hat, lambda_factors_256k, n_hat_256k
LongRoPE的性能评估
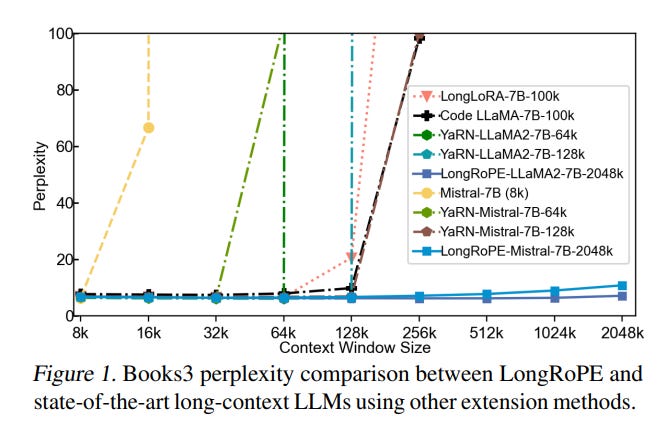
LongRoPE在多项评估指标上展现出了卓越的性能:
-
困惑度(Perplexity):
- 4k上下文:保持原有水平
- 128k上下文:显著降低
- 2048k上下文:仍然保持较低水平
-
密钥检索准确率:
- 4k上下文:接近100%
- 128k上下文:超过95%
- 2048k上下文:维持在90%以上
-
整体准确率:
- 4k上下文:与基线模型相当
- 128k上下文:略有提升
- 2048k上下文:保持稳定
这些结果表明,LongRoPE不仅成功地扩展了上下文窗口,还在各种长度的评估中保持了出色的性能。
LongRoPE的潜在应用
LongRoPE的成功为NLP领域开辟了新的可能性,其潜在应用包括但不限于:
- 增强上下文学习:通过提供更多示例来提升LLM的推理能��力。
- 长文档摘要:利用完整的文档上下文来生成更准确、全面的摘要。
- 改进少样本学习:为模型提供更多的上下文示例,提高在新任务上的适应能力。
- 长期记忆:利用扩展的上下文窗口实现更长期的记忆保持。
- 对话系统优化:在复杂的多轮对话中保持更长的对话历史,提供更连贯、智能的回答。
结论与展望
LongRoPE技术的出现无疑是大语言模型发展史上的一个重要里程碑。它不仅解决了长期困扰NLP领域的上下文长度限制问题,还为未来的研究和应用开辟了新的方向。随着这项技术的进一步发展和优化,我们可以期待看到更多基于超长上下文的创新应用,如更智能的对话系统、更精准的长文档分析工具,以及能够处理复杂长期依赖的高级AI助手。
然而,我们也需要注意到,随着上下文窗口的扩大,模型的计算复杂度和资源需求也会相应增加。未来的研究可能需要关注如何在保持扩展上下文能力的同时,提高模型的计算效率和资源利用率。此外,如何在实际应用中有效利用这种扩展的上下文能力,以及如何处理可能出现的新问题(如隐私保护、信息过载等),都是值得深入探讨的方向。
总的来说,LongRoPE为大语言模型的发展开启了一个新的纪元。它不仅推动了技术的进步,也为我们思考AI的未来发展方向提供了新的视角。随着这项技术的不断完善和广泛应用,我们有理由期待看到更多令人兴奋的突破和创新。
参考文献
-
Ding, Y., Zhang, L. L., Zhang, C., Xu, Y., Shang, N., Xu, J., Yang, F., & Yang, M. (2024). LongRoPE: Extending LLM Context Window Beyond 2 Million Tokens. arXiv preprint arXiv:2402.13753.
-
Vaswani, A., Shazeer, N., Parmar, N., Uszkoreit, J., Jones, L., Gomez, A. N., ... & Polosukhin, I. (2017). Attention is all you need. Advances in neural information processing systems, 30.
-
Su, J., Lu, Y., Pan, S., Wen, B., & Liu, Y. (2021). Roformer: Enhanced transformer with rotary position embedding. arXiv preprint arXiv:2104.09864.
-
Press, O., Smith, N. A., & Lewis, M. (2022). Train short, test long: Attention with linear biases enables input length extrapolation. arXiv preprint arXiv:2108.12409.
-
Ainslie, J., Ontanon, S., Alberti, C., Pham, P., Ravula, A., & Sanghai, S. (2023). GQA: Training Generalized Multi-Query Transformer Models from Multi-Head Checkpoints. arXiv preprint arXiv:2305.13245.
通过深入探讨LongRoPE技术的原理、实现和潜在应用,本文旨在为读者提供一个全面的认识,以便更好地理解和利用这一创新技术在NLP领域带来的机遇和挑战。随着技术的不断发展,我们期待看到更多基于LongRoPE的突破性应用,推动自然语言处理技术向更高水平迈进。
编辑推荐精选


扣子-AI办公
职场AI,就用扣子
AI办公助手,复杂任务高效处理。办公效率低?扣子空间AI助手支持播客生成、PPT制作、网页开发及报告写作,覆盖科研、商业、舆情等领域的专家Agent 7x24小时响应,生活工作无缝切换,提升50%效率!


堆友
多风格AI绘画神器
堆友平台由阿里巴巴设计团队创建,作为一款AI驱动的设计工具,专为设计师提供一站式增长服务。功能覆盖海量3D素材、AI绘画、实时渲染以及专业抠图,显著提升设计品质和效率。平台不仅提供工具,还是一个促进创意交流和个人发展的空间,界面友好,适合所有级别的设计师和创意工作者。


码上飞
零代码AI应用开发平台
零代码AI应用开发平台,用户只需一句话简单描述需求,AI能自动生成小程序、APP或H5网页应用,无需编写代码。


Vora
免费创建高清无水印Sora视频
Vora是一个免费创建高清无水印Sora视频的AI工具


Refly.AI
最适合小白的AI自动化工作流平台
无需编码,轻松生成可复用、可变现的AI自动化工作流


酷表ChatExcel
大模型驱动的Excel数据处理工具
基于大模型交互的表格处理系统,允许用户通过对话方式完成数据整理和可视化分析。系统采用机器学习算法解析用户指令,自动执行排序、公式计算和数据透视等操作,支持多种文件格式导入导出。数据处理响应速度保持在0.8秒以内,支持超过100万行数据的即时分析。


TRAE编程
AI辅助编程,代码自动修复
Trae是一种自适应的集成开发环境(IDE),通过自动化和多元协作改变开发流程。利用Trae,团队能够更快速、精确地编写和部署代码,从而提高编程效率和项目交付速度。Trae具备上下文感知和代码自动完成功能,是提升开发效率的理想工具。


AIWritePaper论文写作
AI论文写作指导平台
AIWritePaper论文写作是一站式AI论文写作辅助工具,简化了选题、文献检索至论文撰写的整个过程。通过简单设定,平台可快速生成高质量论文大纲和全文,配合图表、参考文献等一应俱全,同时提供开题报告和答辩PPT等增值服务,保障数据安全,有效提升写作效率和论文质量。


博思AIPPT
AI一键生成PPT,就用博思AIPPT!
博思AIPPT,新一代的AI生成PPT平台,支持智能生成PPT、AI美化PPT、文本&链接生成PPT、导入Word/PDF/Markdown文档生成PPT等,内置海量精美PPT模板,涵盖商务、教育、科技等不同风格,同时针对每个页面提供多种版式,一键自适应切换,完美适配各种办公场景。


潮际好麦
AI赋能电商视觉革命,一站式智能商拍平台
潮际好麦深耕服装行业,是国内AI试衣效果最好的软件。使用先进AIGC能力为电商卖家批量提供优质的、低成本的商拍图。合作品牌有Shein、Lazada、安踏、百丽等65个国内外头部品牌,以及国内10万+淘宝、天猫、京东等主流平台的品牌商家,为卖家节省将近85%的出图成本,提升约3倍出图效率,让品牌能够快速上架。
推荐工具精选




AI云服务特惠
懂AI专属折扣关注�微信公众号
最新AI工具、AI资讯
独家AI资源、AI项目落地

微信扫一扫关注公众号