ExLlamaV2: 高效的本地大语言模型推理库
 Ray
RayExLlamaV2简介
ExLlamaV2是一个专为在现代消费级GPU上本地运行大语言模型(LLM)而设计的高效推理库。它是ExLlama项目的升级版本,旨在提供更快速、更节省内存的LLM推理体验。
主要特点
- 支持4位GPTQ量化模型
- 动态批处理与智能提示缓存
- K/V缓存去重优化
- 简化的API设计
- 支持Flash Attention 2.5.7+的分页注意力机制
ExLlamaV2的官方推荐后端服务器是TabbyAPI。TabbyAPI提供了与OpenAI兼容的API,可用于本地或远程推理,并支持HuggingFace模型下载、嵌入模型支持以及HF Jinja2聊天模板等扩展功能。
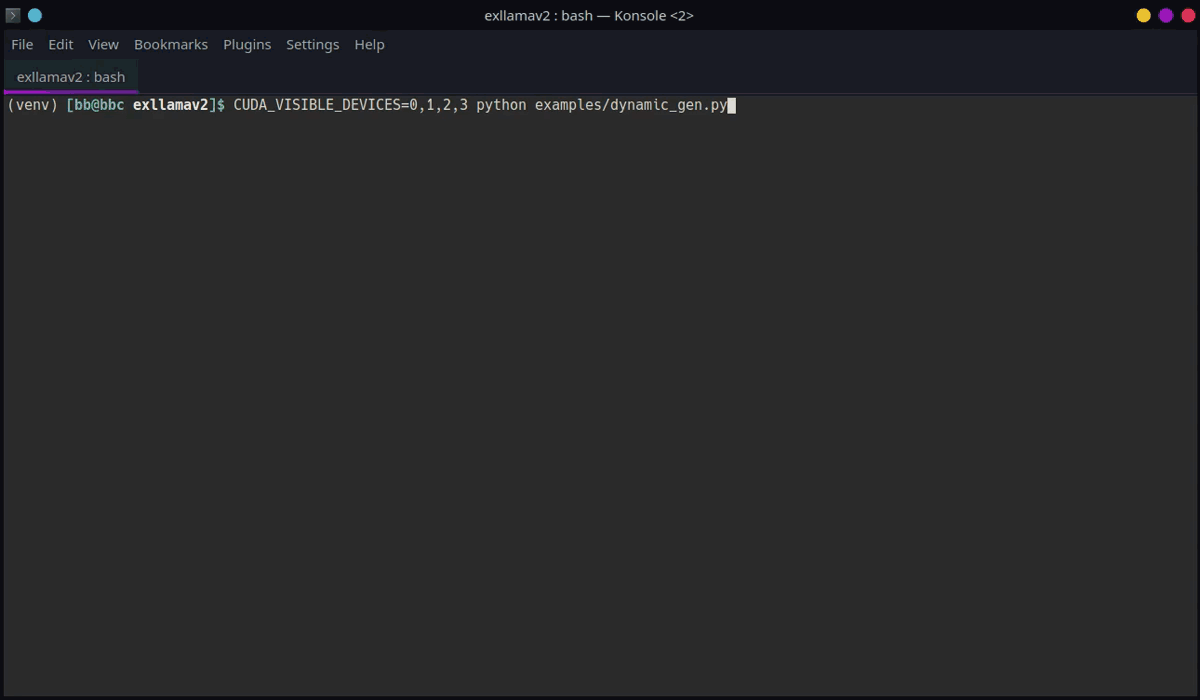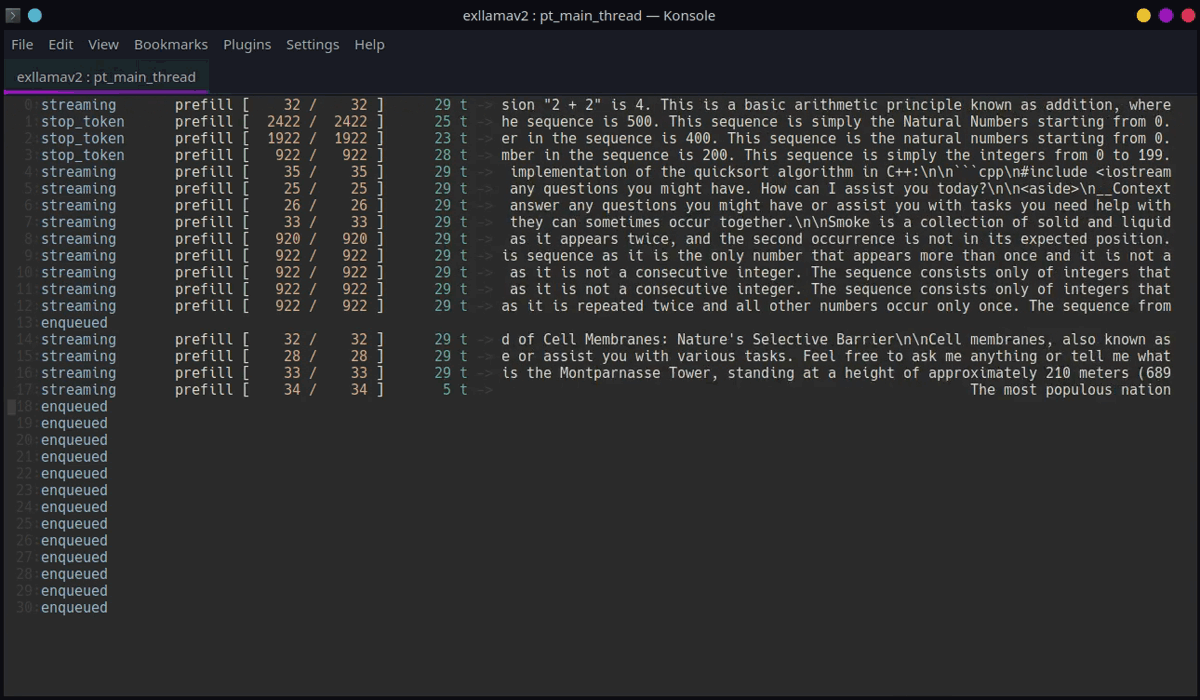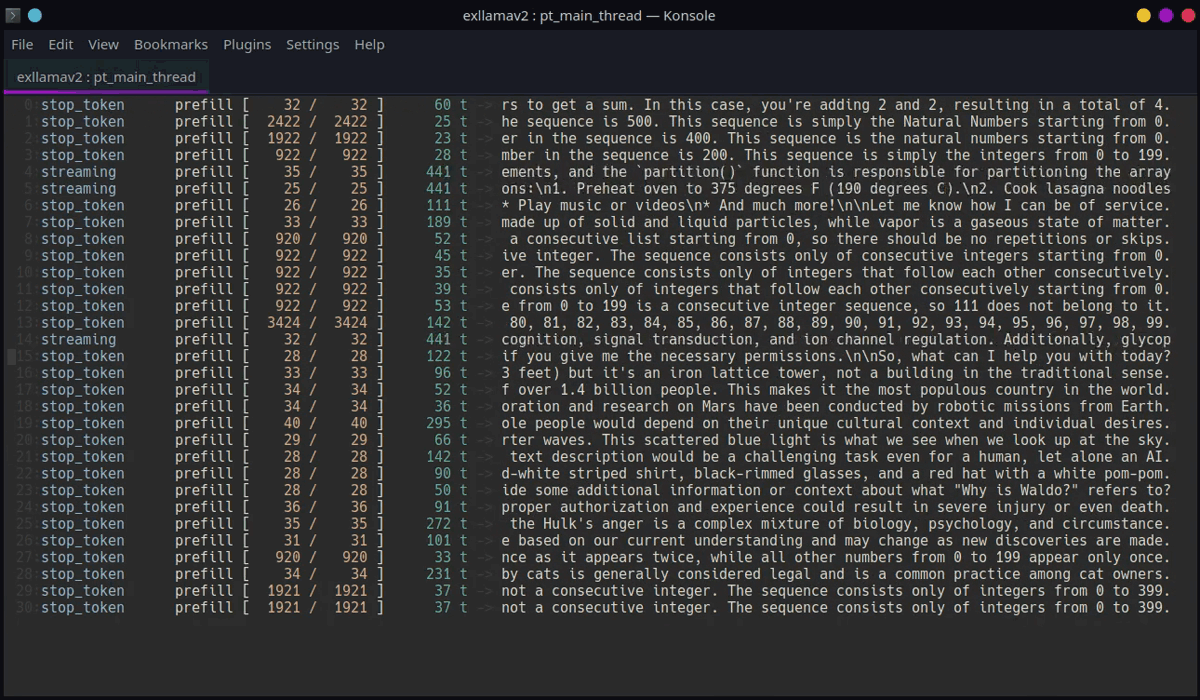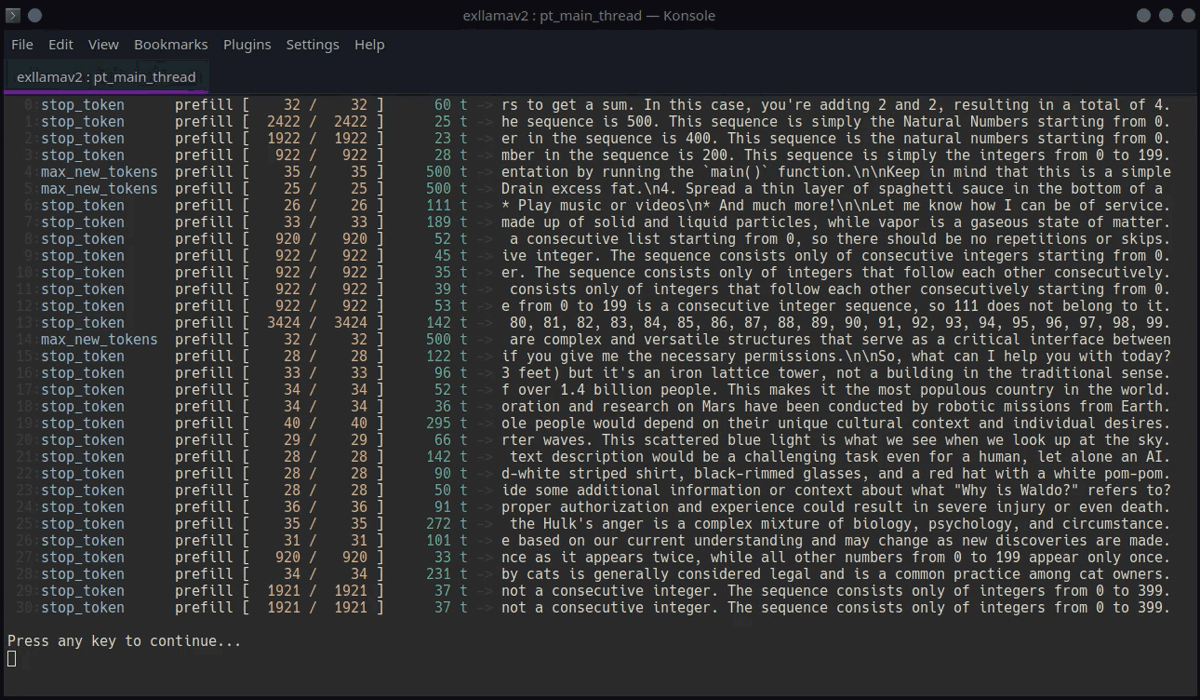
动态生成器
ExLlamaV2的动态生成器是其核心组件之一,它支持所有推理、采样和推测解码功能,并将它们整合到一个统一的API中。动态生成器的主要特点包括:
- 单次生成:
output = generator.generate(prompt = "Hello, my name is", max_new_tokens = 200)
- 批量生成:
outputs = generator.generate( prompt = [ "Hello, my name is", "Once upon a time,", "Large language models are", ], max_new_tokens = 200 )
- 使用
asyncio的流式生成:
job = ExLlamaV2DynamicJobAsync( generator, input_ids = tokenizer.encode("You can lead a horse to water"), banned_strings = ["make it drink"], gen_settings = ExLlamaV2Sampler.Settings.greedy(), max_new_tokens = 200 ) async for result in job: text = result.get("text", "") print(text, end = "")
这些功能使得ExLlamaV2能够灵活地应对各种生成任务,从简单的单句生成到复杂的批量处理和流式输出。
性能表现
ExLlamaV2在性能方面表现出色。以下是一些基准测试结果,展示了不同模型在RTX 4090和RTX 3090Ti上的表现:
| 模型 | 模式 | 大小 | grpsz | act | 3090Ti | 4090 |
|---|---|---|---|---|---|---|
| Llama | GPTQ | 7B | 128 | no | 181 t/s | 205 t/s |
| Llama | GPTQ | 13B | 128 | no | 110 t/s | 114 t/s |
| Llama | GPTQ | 33B | 128 | yes | 44 t/s | 48 t/s |
| OpenLlama | GPTQ | 3B | 128 | yes | 259 t/s | 296 t/s |
| CodeLlama | EXL2 4.0 bpw | 34B | - | - | 44 t/s | 50 t/s |
| Llama2 | EXL2 3.0 bpw | 7B | - | - | 217 t/s | 257 t/s |
| Llama2 | EXL2 4.0 bpw | 7B | - | - | 185 t/s | 211 t/s |
| Llama2 | EXL2 5.0 bpw | 7B | - | - | 164 t/s | 179 t/s |
| Llama2 | EXL2 2.5 bpw | 70B | - | - | 33 t/s | 38 t/s |
| TinyLlama | EXL2 3.0 bpw | 1.1B | - | - | 656 t/s | 770 t/s |
| TinyLlama | EXL2 4.0 bpw | 1.1B | - | - | 602 t/s | 700 t/s |
这些结果显示,ExLlamaV2在各种模型和配置下都能实现优秀的推理速度,特别是在高端GPU如RTX 4090上表现更为出色。
安装和使用
要安装ExLlamaV2,你需要先确保满足以下依赖:
- Python 3.9或更新版本
- PyTorch (测试过2.0.1和2.1.0的cu118版本)
- CUDA工具包
- 其他必要的Python库(可通过requirements.txt安装)
安装步骤:
- 克隆仓库:
git clone https://github.com/turboderp/exllamav2 cd exllamav2
- 安装依赖:
pip install -r requirements.txt pip install .
- 运行测试:
python test_inference.py -m <path_to_model> -p "Once upon a time,"
对于多GPU推理,可以添加--gpu_split auto标志。
ExLlamaV2还提供了一个简单的控制台聊天机器人,可以通过以下命令运行:
python examples/chat.py -m <path_to_model> -mode llama -gs auto
集成和API
ExLlamaV2可以与多种前端和API集成:
- TabbyAPI: 基于FastAPI的服务器,提供OpenAI风格的Web API。
- ExUI: 简单的独立单用户Web UI,直接服务ExLlamaV2实例。
- text-generation-webui: 通过exllamav2和exllamav2_HF加载器支持ExLlamaV2。
- lollms-webui: 通过exllamav2绑定支持ExLlamaV2。
EXL2量化
ExLlamaV2引入了新的"EXL2"格式,这是一种基于与GPTQ相同优化方法的量化技术。EXL2支持2、3、4、5、6和8位量化,并允许在模型内混合不同的量化级别,以实现2到8位之间的任意平均比特率。
这种灵活的量化方案使得Llama2 70B模型能够在单个24 GB GPU上运行,同时保持2048个token的上下文,并在每个权重平均2.55位的情况下产生连贯且基本稳定的输出。13B模型可以在8 GB的VRAM内以2.65位运行,尽管目前它们都不使用GQA,这实际上将上下文大小限制在2048。
社区和资源
ExLlamaV2项目有一个活跃的社区,提供了许多资源和支持:
- Discord社区: https://discord.gg/NSFwVuCjRq
- HuggingFace模型仓库:
这些资源为用户提供了丰富的预训练模型和社区支持,有助于更好地利用ExLlamaV2的功能。
结语
ExLlamaV2代表了本地LLM推理的一个重要进步。通过其高效的内存使用、灵活的量化方案和优化的性能,它为研究人员、开发者和AI爱好者提供了一个强大的工具,使他们能够在消费级硬件上运行大型语言模型。随着项目的不断发展和社区的贡献,我们可以期待看到更多创新应用和性能提升。无论是用于个人实验、研究项目还是商业应用,ExLlamaV2都为本地AI推理开辟了新的可能性。
编辑推荐精选


音述AI
全球首个AI音乐社区
音述AI是全球首个AI音乐社区,致力让每个人都能用音乐表达自我。音述AI提供零门槛AI创作工具,独创GETI法则帮助用户精准定义音乐风格,AI润色功能支持自动优化作品质感。音述AI支持交流讨论、二次创作与价值变现。针对中文用户的语言习惯与文化背景进行专门优化,支持国风融合、C-pop等本土音乐标签,让技术更好地承载人文表达。


QoderWork
阿里Qoder团队推出的桌面端AI智能体
QoderWork 是阿里推出的本地优先桌面 AI 智能体,适配 macOS14+/Windows10+,以自然语言交互实现文件管理、数据分析、AI 视觉生成、浏览器自动化等办公任务,自主拆解执行复杂工作流,数据本地运行零上传,技能市场可无限扩展,是高效的 Agentic 生产力办公助手。


lynote.ai
一站式搞定所有学习需求
不再被海量信息淹没,开始真正理解知识。Lynote 可摘要 YouTube 视频、PDF、文章等内容。即时创��建笔记,检测 AI 内容并下载资料,将您的学习效率提升 10 倍。


AniShort
为AI短剧协作而生
专为AI短剧协作而生的AniShort正式发布,深度重构AI短剧全流程生产模式,整合创意策划、制作执行、实时协作、在线审片、资产复用等全链路功能,独创无限画布、双轨并行工业化工作流与Ani智能体助手,集成多款主流AI大模型,破解素材零散、版本混乱、沟通低效等行业痛点,助力3人团队效率提升800%,打造标准化、可追溯的AI短剧量产体系,是AI短剧团队协同创作、提升制作效率的核心工具。


seedancetwo2.0
能听懂你表达的视频模型
Seedance two是基于seedance2.0的中国大模型,支持图像、视频、音频、文本四种模态输入,表达方式更丰富,生成也更可控。


nano-banana纳米香蕉中文站
国内直接访问,限时3折
输入简单文字,生成想要的图片,纳米香蕉中文站基于 Google 模型的 AI 图片生成网站,支持文字生图、图生图。官网价格限时3折活动


扣子-AI办公
职场AI,就用扣子
AI办公助手,复杂任务高效处理。办公效率低?扣子空间AI助手支持播客生成、PPT制作、网页开发及报告写作,覆盖科研、商业、舆情等领域的专家Agent 7x24小时响应,生活工作无缝切换,提升50%效率!


堆友
多风格AI绘画神器
堆友平台由阿里巴巴设计团队创建,作为一款AI驱动的设计工具,专为设计师提供一站式增长服务。功能覆盖海量3D素材、AI绘画、实时渲染以及专业抠图,显著提升设计品质和效率。平台不仅提供工具,还是一个促进创意交流和个人发展的空间,界面友好,适合所有级别的设计师和创意工作者。


码上飞
零代码AI应用开发平台
零代码AI应用开发平台,用户只需一句话简单描述需求,AI能自动生成小程序、APP或H5网页应用,无需编写代码。


Vora
免费创建高清无水印Sora视频
Vora是一个免费创建高清无水印Sora视频的AI工具
推荐工具精选





AI云服务特惠
懂AI专属折扣关注微信公众号
最新AI工具、AI资讯
独家AI资源、AI项目落地

微信扫一扫关注公众号