从零开始构建大语言模型:深入理解LLM原理与实现
 Ray
Ray从零开始构建大语言模型:深入理解LLM原理与实现
大语言模型(Large Language Models, LLMs)作为人工智能领域的前沿技术,正在深刻改变我们与计算机交互的方式。然而,对于许多人来说,LLM的内部工作原理仍然是一个黑盒。本文将带领读者从零开始,一步步构建类似ChatGPT的大语言模型,深入理解其背后的原理和实现细节。
为什么要从零构建LLM?
在人工智能快速发展的今天,我们已经可以轻松使用各种成熟的LLM API。那么,为什么还要花时间从头构建LLM呢?主要有以下几个原因:
-
深入理解原理:通过亲自实现每一个组件,我们可以真正理解LLM的工作机制,而不仅仅停留在表面使用层面。
-
定制化需求:了解LLM的内部结构,可以根据特定需求进行定制和优化。
-
创新的基础:只有深入理解现有技术,才能在此基础上进行创新。
-
教育价值:对于AI领域的学习者和研究者来说,这是一个极具教育意义的过程。
LLM的基础知识
在开始构建之前,我们需要了解一些LLM的基础知识:
-
词嵌入(Word Embedding):将文本中的词转换为密集的向量表示。
-
注意力机制(Attention Mechanism):允许模型在处理序列数据时"关注"输入的不同部分。
-
Transformer架构:目前最流行的LLM架构,基于自注意力机制。
-
预训练与微调:大规模预训练后,针对特定任务进行微调的范式。
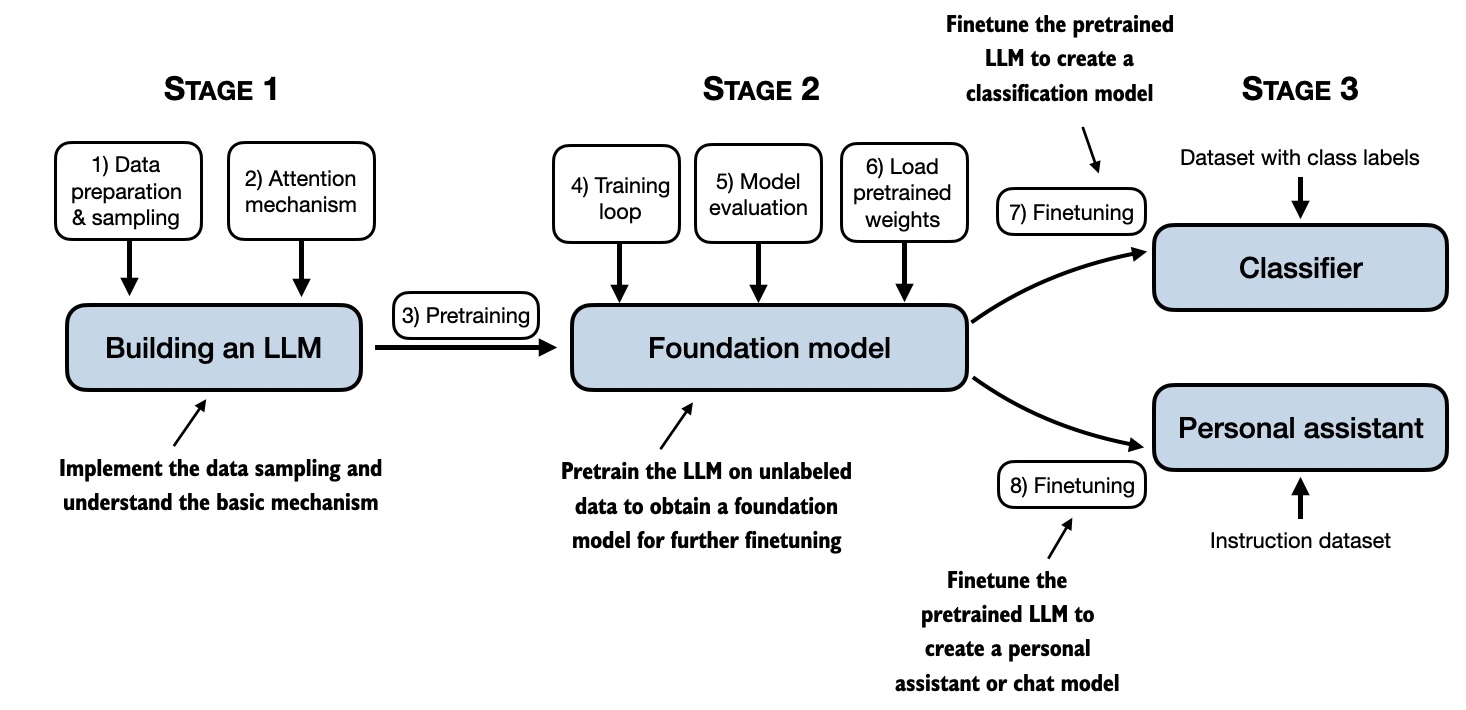
从零构建LLM的步骤
现在,让我们一步步实现一个简化版的LLM:
1. 数据预处理
首先,我们需要准备训练数据。这包括文本清洗、分词和编码等步骤。以下是一个简单的示例:
import torch from torchtext.data.utils import get_tokenizer # 初始化分词器 tokenizer = get_tokenizer('basic_english') # 示例文本 text = "Hello, world! This is a sample text." # 分词 tokens = tokenizer(text) # 创建词汇表 vocab = set(tokens) word_to_idx = {word: i for i, word in enumerate(vocab)} # 将文本转换为索引序列 indexed_text = [word_to_idx[token] for token in tokens] print(indexed_text)
2. 实现注意力机制
注意力机制是LLM的核心组件之一。以下是一个简化版的自注意力实现:
import torch import torch.nn as nn class SelfAttention(nn.Module): def __init__(self, embed_size, heads): super(SelfAttention, self).__init__() self.embed_size = embed_size self.heads = heads self.head_dim = embed_size // heads self.values = nn.Linear(self.head_dim, self.head_dim, bias=False) self.keys = nn.Linear(self.head_dim, self.head_dim, bias=False) self.queries = nn.Linear(self.head_dim, self.head_dim, bias=False) self.fc_out = nn.Linear(heads * self.head_dim, embed_size) def forward(self, values, keys, query, mask): N = query.shape[0] value_len, key_len, query_len = values.shape[1], keys.shape[1], query.shape[1] # Split embedding into self.heads pieces values = values.reshape(N, value_len, self.heads, self.head_dim) keys = keys.reshape(N, key_len, self.heads, self.head_dim) queries = query.reshape(N, query_len, self.heads, self.head_dim) values = self.values(values) keys = self.keys(keys) queries = self.queries(queries) # Scaled dot-product attention energy = torch.einsum("nqhd,nkhd->nhqk", [queries, keys]) if mask is not None: energy = energy.masked_fill(mask == 0, float("-1e20")) attention = torch.softmax(energy / (self.embed_size ** (1/2)), dim=3) out = torch.einsum("nhql,nlhd->nqhd", [attention, values]).reshape( N, query_len, self.heads * self.head_dim ) out = self.fc_out(out) return out
3. 构建Transformer块
Transformer块是LLM的基本构建单元,包含自注意力层和前馈神经网络:
class TransformerBlock(nn.Module): def __init__(self, embed_size, heads, dropout, forward_expansion): super(TransformerBlock, self).__init__() self.attention = SelfAttention(embed_size, heads) self.norm1 = nn.LayerNorm(embed_size) self.norm2 = nn.LayerNorm(embed_size) self.feed_forward = nn.Sequential( nn.Linear(embed_size, forward_expansion * embed_size), nn.ReLU(), nn.Linear(forward_expansion * embed_size, embed_size), ) self.dropout = nn.Dropout(dropout) def forward(self, value, key, query, mask): attention = self.attention(value, key, query, mask) x = self.dropout(self.norm1(attention + query)) forward = self.feed_forward(x) out = self.dropout(self.norm2(forward + x)) return out
4. 实现完整的Transformer模型
现在,我们可以将所有组件组合成一个完整的Transformer模型:
class Transformer(nn.Module): def __init__(self, src_vocab_size, embed_size, num_layers, heads, device, forward_expansion, dropout, max_length): super(Transformer, self).__init__() self.embed_size = embed_size self.device = device self.word_embedding = nn.Embedding(src_vocab_size, embed_size) self.position_embedding = nn.Embedding(max_length, embed_size) self.layers = nn.ModuleList( [ TransformerBlock(embed_size, heads, dropout=dropout, forward_expansion=forward_expansion) for _ in range(num_layers) ] ) self.fc_out = nn.Linear(embed_size, src_vocab_size) self.dropout = nn.Dropout(dropout) def forward(self, x, mask): N, seq_length = x.shape positions = torch.arange(0, seq_length).expand(N, seq_length).to(self.device) out = self.dropout((self.word_embedding(x) + self.position_embedding(positions))) for layer in self.layers: out = layer(out, out, out, mask) out = self.fc_out(out) return out
5. 训练模型
有了模型架构,接下来就是训练过程:
# 初始化模型 model = Transformer( src_vocab_size=len(vocab), embed_size=256, num_layers=6, heads=8, device="cuda" if torch.cuda.is_available() else "cpu", forward_expansion=4, dropout=0.1, max_length=100 ).to(device) # 定义损失��函数和优化器 criterion = nn.CrossEntropyLoss() optimizer = torch.optim.Adam(model.parameters(), lr=0.0001) # 训练循环 for epoch in range(num_epochs): for batch in dataloader: input_ids, labels = batch input_ids, labels = input_ids.to(device), labels.to(device) outputs = model(input_ids, mask=None) loss = criterion(outputs.view(-1, len(vocab)), labels.view(-1)) optimizer.zero_grad() loss.backward() optimizer.step() print(f"Epoch {epoch+1}/{num_epochs}, Loss: {loss.item():.4f}")
进阶主题
在掌握了基础实现后,我们可以探索一些进阶主题:
-
预训练技术:如何在大规模无标签数据上进行预训练。
-
微调策略:针对特定任务的微调方法。
-
模型压缩:如何在保持性能的同时减小模型大小。
-
多模态融合:将文本与图像、音频等其他模态结合。
-
伦理考量:讨论LLM可能带来的伦理问题及其解决方案。
结语
从零开始构建LLM是一个充满挑战但极具收获�的过程。通过亲自实现每一个组件,我们不仅能深入理解LLM的工作原理,还能为未来的AI创新奠定坚实基础。随着技术的不断发展,LLM必将在更多领域发挥重要作用。让我们继续探索,共同推动AI技术的进步!
本文为读者提供了从零构建LLM的全面指南,从基础知识到实际代码实现,再到进阶主题的探讨。希望这篇文章能激发更多人对LLM技术的兴趣,并为AI领域的学习和研究提供有价值的参考。让我们一起在这个充满可能性的领域中不断探索和创新!
编辑推荐精选


音述AI
全球首个AI音乐社区
音述AI是全球首个AI音乐社区,致力让每个人都能用音乐表达自我。音述AI提供零门槛AI创作工具,独创GETI法则帮助用户精准定义音乐风格,AI润色功能支持自动优化作品质感。音述AI支持交流讨论、二次创作与价值变现。针对中文用户的语言习惯与文化背景进行专门优化,支持国风融合、C-pop等本土音乐标签,让技术更好地承载人文表达。


QoderWork
阿里Qoder团队推出的桌面端AI智能体
QoderWork 是阿里推出的本地优先桌面 AI 智能体,适配 macOS14+/Windows10+,以自然语言交互实现文件管理、数据分析、AI 视觉生成、浏览器自动化等办公任务,自主拆解执行复杂工作流,数据本地运行零上传,技能市场可无限扩展,是高效的 Agentic 生产力办公助手。


lynote.ai
一站式搞定所有学习需求
不再被海量信息淹没,开始真正理解知识。Lynote 可摘要 YouTube 视频、PDF、文章等内容。即时创建笔记,检测 AI 内容并下载资料,将您的学习效率提升 10 倍。


AniShort
为AI短剧协作而生
专为AI短剧协作而生的AniShort正式发布,深度重构AI短剧全流程生产模式,整合创意策划、制作执行、实时协作、在线审片、资产复用等全链路功能,独创无限画布、双轨并行工业化工作流与Ani智能体助手,集成多款主流AI大模型,破解素材零散、版本混乱、沟通低效等行业痛点,助力3人团队效率提升800%,打造标准化、可追溯的AI短剧量产体系,是AI短剧团队协同创作、提升制作效率的核心工具。


seedancetwo2.0
能听懂你表达的视频模型
Seedance two是基于seedance2.0的中国大模型,支持图像、视频、音频、文本四种模态输入,表达方式更丰富,生成也更可控。


nano-banana纳米香蕉中文站
国内直接访问,限时3折
输入简单文字,生成想要的图片,纳米香蕉中文站基于 Google 模型的 AI 图片生成网站,支持文字生图、图生图。官网价格限时3折活动


扣子-AI办公
职场AI,就用扣子
AI办公助手,复杂任务高效处理。办公效率低?扣子空间AI助手支持播客生成、PPT制作、网页开发及报告写作,覆盖科研、商业、舆情等领域的专家Agent 7x24小时响应,生活工作无缝切换,提升50%效率!


堆友
多风格AI绘画神器
堆友平台由阿里巴巴设计团队创建,作为一款AI驱动的设计工具,专为设计师提供一站式增长服务。功能覆盖海量3D素材、AI绘画、实时渲染以及专业抠图,显著提升设计品质和效率。平台不仅提供工具,还是一个促进创意交流和个人发展的空间,界面友好,适合所有级别的设计师和创意工作者。


码上飞
零代码AI应用开发平台
零代码AI应用开发平台,用户只需一句话简单描述需求,AI能自动生成小程序、APP或H5网页应用,无需编写代码。


Vora
免费创建高清无水印Sora视频
Vora是一个免费创建高清无水印Sora视频的AI工具
推荐工具精选





AI云服务特惠
懂AI专属折扣关注微信公众号
最新AI工具、AI资讯
独家AI资源、AI项目落地

微信扫一扫关注公众号