




EasyVtuber
把买皮的钱拿去买张3080吧!
本项目fork自 https://github.com/GunwooHan/EasyVtuber 为解决面部捕捉质量问题,又反向移植了原版demo https://github.com/pkhungurn/talking-head-anime-2-demo 中关于ifacialmocap的iOS面部捕捉逻辑 并且省略了ifacialmocap PC端,通过UDP直连方式使iOS面部捕捉刷新率达到最高60fps,解决了面部捕捉刷新率的瓶颈 最后,为EasyVtuber中使用的OBS虚拟摄像头方案增加配套的Shader支持,解锁RGBA输出能力,无需绿幕背景即可直接使用
要求
硬件
- 支持FaceID的iPhone(使用ifacialmocap软件,需购买,需要稳定的WIFI连接)或网络摄像头(使用OpenCV)
- 支持PyTorch CUDA的NVIDIA显卡(参考:TUF RTX3080 默认频率 40FPS 80%占用)
软件
- 本方案在Windows 10上测试可用
- Python>=3.8
- OBS或Unity Capture(虚拟摄像头方案)
- Photoshop或其他图片处理软件
- 科学上网方案,理解英文网站和错误提示的能力
安装(嵌入式Python版本)
bin文件夹内是基于Python 3.10.5的Win64嵌入式版构建的轻量化运行环境 对于只想体验这个库的用户,推荐使用这种安装方式。
下载ZIP并解压或克隆本仓库
点击Download ZIP下载并解压,或使用git克隆该仓库到你能找到的位置。
完整展开venv需要约5.5G硬盘空间。
下载预训练模型
使用00B快捷方式�或以下链接下载模型文件
https://github.com/pkhungurn/talking-head-anime-3-demo#download-the-models
从原仓库下载(this Dropbox link)的压缩文件
解压到data/models文件夹中,与placeholder.txt同级
正确的目录结构为:
+ models
- separable_float
- separable_half
- standard_float
- standard_half
- placeholder.txt
如不确定是否解压到正确位置,可使用00.检查并补齐必需文件.bat
构建运行环境
运行适合你所在地区的01A.构建运行环境(默认源).bat或01B.构建运行环境(国内源).bat
此脚本会使用pip在bin目录下安装所有必要的依赖
两个脚本可互相替代,且支持从中断处继续
如遇网络相关错误,直接关闭控制台,调整网络后重新运行即可
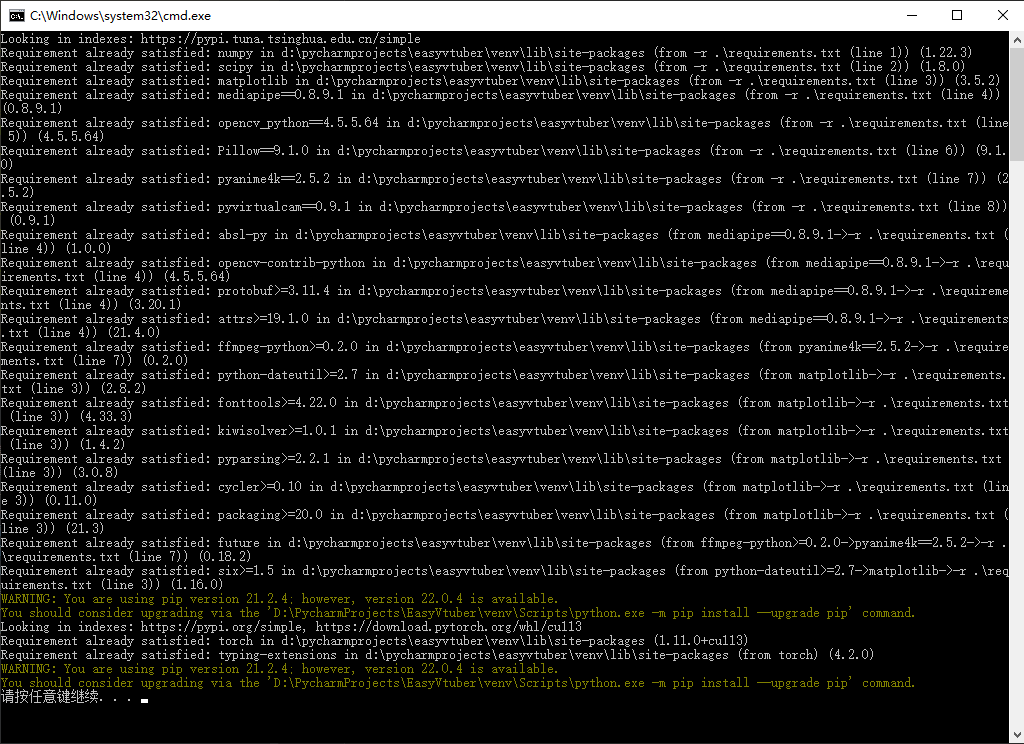 完全安装完成后再次运行脚本的输出如图所示。通常情况下,安装过程中没有红字就表示成功完成。
完全安装完成后再次运行脚本的输出如图所示。通常情况下,安装过程中没有红字就表示成功完成。
使用启动器测试结果
运行02B启动器(调试输出).bat
直接点击界面底部的Save & Launch
如果看到弹出的OpenCV输出窗口,则安装成功完成
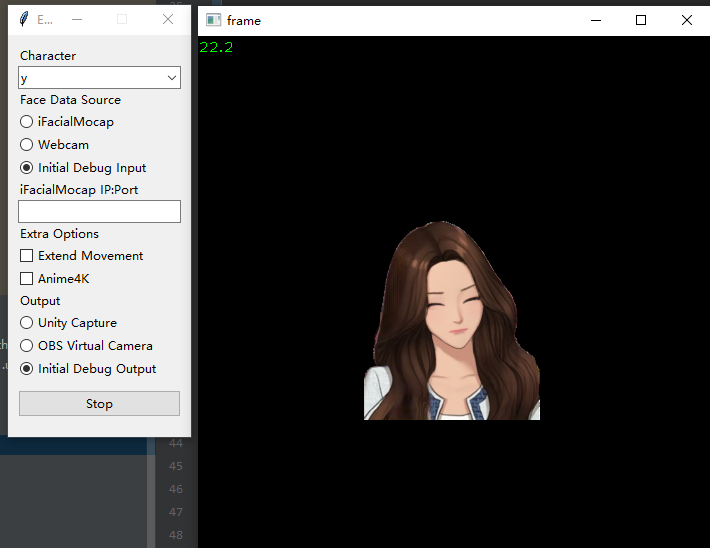
配置输入输出设备
成功进行调试输出后,请参考后续的输入输出设备部分进行进一步配置以输出到OBS。
安装(Venv版本)
如果你仍需使用之前的Venv方案,请参考以下步骤
下载ZIP并解压或克隆本仓库
点击Download ZIP下载并解压,或使用git克隆该仓库到你能找到的位置。
完整展开venv需��要约5.5G硬盘空间。
创建虚拟环境
此处假设你已正确安装Python,如不会安装请使用前文的嵌入式方案
在项目目录下运行python -m venv venv创建虚拟环境
切换到虚拟环境
之后的操作都需在虚拟环境中进行,辨别方式为命令行前会有(venv)标识
在控制台运行venv\Scripts\activate.bat切换到刚创建的虚拟环境
之后你的python、pip等操作都将在虚拟环境中执行
安装依赖
在虚拟环境中执行以下命令
pip install -r .\requirements.txt
pip install torch --extra-index-url https://download.pytorch.org/whl/cu113
运行启动器
在虚拟环境中执行以下命令
python launcher.py
安装(Conda版本)
克隆本仓库
克隆完成后,如直接用PyCharm打开,暂不要配置Python解释器。
Python和Anaconda环境
本项目使用Anaconda进行包管理
首先前往 https://www.anaconda.com/ 安装Anaconda
启动Anaconda Prompt控制台
国内用户建议此时切换到清华源(pip和conda都要更换,尤其是conda的PyTorch Channel,PyTorch本体太大了)
然后运行 conda env create -f env_conda.yaml 一键安装所有依赖
如遇报错(通常是网络问题),删除配置了一半的环境,运行conda clean --all清除下载缓存,调整配置后重试
安装完成后,在PyCharm中打开本项目,点击右下角解释器菜单,选择Add Interpreter...->Conda Environment->Existing environment
选择你电脑上的conda.exe和刚创建的talking-head-anime-2-demo环境中的python.exe
点击OK,依赖全部亮起即可
下载预训练模型
https://github.com/pkhungurn/talking-head-anime-3-demo#download-the-models
从原仓库下载(this Dropbox link)的压缩文件
解压到data/models文件夹中,与placeholder.txt同级
正确的目录结构为:
+ models
- separable_float
- separable_half
- standard_float
- standard_half
- placeholder.txt
运行启动器
在Conda环境中执行以下命令
python launcher.py
输入输出设备
OBS虚拟摄像头
目前更推荐这个方案,UnityCapture存在未查明的性能瓶颈
如果你选择自己进行抠像,你可以直接输出到OBS。如果你需要RGBA支持,则需要额外使用一个着色器。
下载并安装StreamFX https://github.com/Xaymar/obs-StreamFX 下载着色器(感谢树根的协助)https://github.com/shugen002/shader/blob/master/merge%20alpha2.hlsl
之后,使用--alpha_split参数运行

你会看到这样的输出画面,透明通道单独使用灰度方式发送了
然后对OBS中的视频采集设备添加滤镜-着色器-选择你下载的merge alpha2.hlsl-关闭
这样透明通道就应用回左边的图像了
你可能需要手动调整一下裁剪把右侧的无用画面切掉
(如果看不到着色器滤镜,那可能是StreamFX没安装好或者OBS不是最新版)
UnityCapture
如果需要使用透明通道输出,参考 https://github.com/schellingb/UnityCapture#installation 安装好UnityCapture 只需要正常完成Install.bat的安装,在OBS里能看到对应的设备(Unity Video Capture)就行
在OBS添加完摄像��头后,还需要手动配置一次摄像头属性才能支持ARGB
右键属性-取消激活-分辨率类型自定义-分辨率512x512(与--output_size参数一致)-视频格式ARGB-激活
iFacialMocap
https://www.ifacialmocap.com/download/ 你很可能需要购买正式版(非广告,只是试用版时长不太够) 购买前请确认自己的设备是否支持 不需要下载PC软件,只需安装iOS端的软件即可,连接信息通过参数传入Python
OpenSeeFace
https://github.com/emilianavt/OpenSeeFace/releases
直接下载最新版本的Release包并解压
然后进入解压目录的Binary文件夹
右键编辑run.bat,在倒数第二行运行facetracker的命令后加上--model 4,切换到模型4可以实现眨眼
facetracker -c %cameraNum% -F %fps% -D %dcaps% -v 3 -P 1 --discard-after 0 --scan-every 0 --no-3d-adapt 1 --max-feature-updates 900 --model 4(仅供参考)
然后保存并双击run.bat运行,按照提示选择摄像头、分辨率、帧率,如果捕获正常,你应该能看到输出画面
最后在启动器中选择OpenSeeFace输入,或添加启动参数--osf 127.0.0.1:11573即可接入OpenSeeFace
运行
完整的运行命令python main.py --output_webcam unitycapture --ifm 192.168.31.182:49983 --character test1L2 --extend_movement 1 --output_size 512x512
| 参数名 | 值类型 | 说明 |
|---|---|---|
| --character | 字符串 | character目录下的输入图像文件名,不需要带扩展名 |
| --debug | 无 | 打开OpenCV预览窗口输出渲染结果,如果没有任何输出配置,该参数默认生效 |
| --input | 字符串 | 不使用iOS面捕时,传入要使用的摄像头设备名称,默认为设备0,有ifm参数时无效 |
| --ifm | 字符串 | 使用iOS面捕时,传入设备的IP:端口号,如192.168.31.182:49983 |
| --output_webcam | 字符串 | 可用值为obs或unitycapture,选择对应的输出种类,不传则不输出到摄像头 |
| --extend_movement | 浮点数 | 使用iOS面捕返回的头部位置,对模型输出图像进一步进行移动和旋转,使得上半身可动<br>传入的数值表示移动倍率(建议值为1) |
| --output_size | 字符串 | 格式为256x256,必须是4的倍数。<br>增大它并不会让图像更清晰,但配合extend_movement会增大可动范围 |
编辑推荐精选


音述AI
全球首个AI音乐社区
音述AI是全球首个AI音乐社区,致力让每个人都能用音乐表达自我。音述AI提供零门槛AI创作工具,独创GETI法则帮助用户精准定义音乐风格,AI润色功能支持自动优化作品质感。音述AI支持交流讨论、二次创作与价值变现。针对中文用户的语言习惯与文化背景进行专门优化,支持国风融合、C-pop等本土音乐标签,让技术更好地承载人文表达。


lynote.ai
一站式搞定所有学习需求
不再被海量信息淹没,开始真正理解知识。Lynote 可摘要 YouTube 视频、PDF、文章等内容。即时创建笔记,检测 AI 内容并下载资料,将您的学习效率提升 10 倍。


AniShort
为AI短剧协作而生
专为AI短剧协作而生的AniShort正式发布,深度重构AI短剧全流程�生产模式,整合创意策划、制作执行、实时协作、在线审片、资产复用等全链路功能,独创无限画布、双轨并行工业化工作流与Ani智能体助手,集成多款主流AI大模型,破解素材零散、版本混乱、沟通低效等行业痛点,助力3人团队效率提升800%,打造标准化、可追溯的AI短剧量产体系,是AI短剧团队协同创作、提升制作效率的核心工具。


seedancetwo2.0
能听懂你表达的视频模型
Seedance two是基于seedance2.0的中国大模型,支持图像、视频、音频、文本四种模态输入,表达方式更丰富,生成也更可控。


nano-banana纳米香蕉中文站
国内直接访问,限时3折
输入简单文字,生成想要的图片,纳米香蕉中文站基于 Google 模型的 AI 图片生成网站,支持文字生图、图生图。官网价格限时3折活动


扣子-AI办公
职场AI,就用扣子
AI办公助手,复杂任务高效处理。办公效率低?扣子空间AI助手支持播客生成、PPT制作、网页开发及报告写作,覆盖科研、商业、舆情等领域的专家Agent 7x24小时响应,生活工作无缝切换,提升50%效率!


堆友
多风格AI绘画神器
堆友平台由阿里巴巴设计团队创建,作为一款AI驱动的设计工具,专为设计师提供一站式增长服务。功能覆盖海量3D素材、AI绘画、实时渲染以及专业抠图,显著提升设计品质和效率。平台不仅提供工具,还是一个促进创意交流和个人发展的空间,界面友好,适合所有级别的设计师和创意工作者。


码上飞
零代码AI应用开发平台
零代码AI应用开发平台,用户只需一句话简单描述需求,AI能自动生成小程序、APP或H5网页应用,无需编写代码。


Vora
免费创建高清无水印Sora视频
Vora是一个免费创建高清无水印Sora视频的AI工具


Refly.AI
最适合小白的AI自动化工作流平台
无需编码,轻松生成可复用、可变现的AI自动化工作流
推荐工具精选





AI云服务特惠
懂AI专属折扣关注微信公众号
最新AI工具、AI资讯
独家AI资源、AI项目落地

微信扫一扫关注公众号