


Fast-Bert



新功能 - 文本分类训练的学习率查找器(感谢借鉴自https://github.com/davidtvs/pytorch-lr-finder)
支持LAMB优化器以加快训练速度。 请参阅https://arxiv.org/abs/1904.00962了解LAMB优化器的相关论文。
支持BERT和XLNet进行多类和多标签文本分类。
Fast-Bert是一个深度学习库,允许开发人员和数据科学家训练和部署基于BERT和XLNet的模型,用于自然语言处理任务,从文本分类开始。
Fast-Bert的工作建立在优秀的Hugging Face BERT PyTorch库提供的坚实基础之上,并受到fast.ai的启发,致力于使最先进的深度学习技术为广大机器学习从业者所用。
使用Fast-Bert,您将能够:
-
在自定义数据集上训练(更准确地说是微调)BERT、RoBERTa和XLNet文本分类模型。
-
调整模型超参数,如轮数、学习率、批量大小、优化器调度等。
-
保存和部署训练好的模型进行推理(包括在AWS Sagemaker上)。
Fast-Bert将支持以下多类和多标签文本分类,��并且将来还会支持其他NLU任务,如命名实体识别、问答和自定义语料库微调。
-
BERT(来自Google),随论文BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding发布,作者为Jacob Devlin、Ming-Wei Chang、Kenton Lee和Kristina Toutanova。
-
XLNet(来自Google/CMU),随论文XLNet: Generalized Autoregressive Pretraining for Language Understanding发布,作者为Zhilin Yang*、Zihang Dai*、Yiming Yang、Jaime Carbonell、Ruslan Salakhutdinov、Quoc V. Le。
-
RoBERTa(来自Facebook),一种经过稳健优化的BERT预训练方法,作者为Yinhan Liu、Myle Ott、Naman Goyal、Jingfei Du等。
-
DistilBERT(来自HuggingFace),随博客文章Smaller, faster, cheaper, lighter: Introducing DistilBERT, a distilled version of BERT发布,作者为Victor Sanh、Lysandre Debut和Thomas Wolf。
安装
本仓库在Python 3.6+上测试通过。
使用pip安装
可以通过pip安装PyTorch-Transformers,如下所示:
pip install fast-bert
从源代码安装
克隆仓库并运行:
pip install [--editable] .
或
pip install git+https://github.com/kaushaltrivedi/fast-bert.git
您还需要安装NVIDIA Apex。
git clone https://github.com/NVIDIA/apex cd apex pip install -v --no-cache-dir --global-option="--cpp_ext" --global-option="--cuda_ext" ./
使用方法
文本分类
1. 创建DataBunch对象
DataBunch对象接收训练、验证和测试CSV文件,并将数据转换为BERT、RoBERTa、DistilBERT或XLNet的内部表示。该对象还会根据设备配置、批量大小和最大序列长度实例化正确的数据加载器。
from fast_bert.data_cls import BertDataBunch databunch = BertDataBunch(DATA_PATH, LABEL_PATH, tokenizer='bert-base-uncased', train_file='train.csv', val_file='val.csv', label_file='labels.csv', text_col='text', label_col='label', batch_size_per_gpu=16, max_seq_length=512, multi_gpu=True, multi_label=False, model_type='bert')
train.csv和val.csv的文件格式
| 索引 | 文本 | 标签 |
|---|---|---|
| 0 | 浏览其他评论时,我很惊讶没有人警告潜在观众租这部垃圾片会遇到什么。首先,我租这部电影时以为它是一部制作精良的印第安纳·琼斯仿制品。 | 负面 |
| 1 | 我已经看了前17集,这部动画简直太棒了!自《新世纪福音战士》以来,我还没有对一部动画如此感兴趣过。这部作品实际上是根据一个成人游戏改编的,我不确定以前是否有过这样的先例。我没有玩过这个游戏,但据说动画很忠实于原作。 | 正面 |
| 2 | 这部电影无疑是一部黑暗、写实的杰作。我可能有些偏见,因为种族隔离时代一直是我所关心的主题。 | 正面 |
如果列名与通常的text和labels不同,你需要在databunch的text_col和label_col参数中提供这些名称。
labels.csv将包含所有唯一标签的列表。在这种情况下,文件将包含:
正面 负面
对于多标签分类,labels.csv将包含所有可能的标签:
有毒
严重有毒
淫秽
威胁
侮辱
仇恨身份
文件train.csv将为每个标签包含一列,每列的值为0或1。别忘了在BertDataBunch中将multi_label=True用于多标签分类。
| id | 文本 | 有毒 | 严重有毒 | 淫秽 | 威胁 | 侮辱 | 仇恨身份 |
|---|---|---|---|---|---|---|---|
| 0 | 为什么我的用户名Hardcore Metallica Fan下的编辑被撤销了? | 0 | 0 | 0 | 0 | 0 | 0 |
| 0 | 我会搞垮你 | 1 | 0 | 0 | 1 | 0 | 0 |
label_col将是标签列名的列表。在这种情况下,它将是:
['有毒','严重有毒','淫秽','威胁','侮辱','仇恨身份']
分词器
你可以创建一个分词器对象并将其传递给DataBunch,或者将模型名称作为分词器传递,DataBunch将自动下载并实例化适当的分词器对象。
例如,要使用XLNet base cased模型,将分词器参数设置为'xlnet-base-cased'。DataBunch将自动下载并实例化XLNetTokenizer,其词汇表用于xlnet-base-cased模型。
模型类型
Fast-Bert支持基于XLNet、RoBERTa和BERT的分类模型。将模型类型参数值设置为**'bert'、roberta或'xlnet'**,以初始化适当的databunch对象。
2. 创建学习器对象
BertLearner是将所有内容整合在一起的"学习器"对象。它封装了模型生命周期的关键逻辑,如训练、验证和推理。
学习器对象将使用前面创建的databunch作为输入,同时还有一些其他参数,如预训练模型的位置、FP16训练、多GPU和多标签选项。
学习器类包含训练循环、验证循环、优化器策略和关键指标计算的逻辑。这有助于开发人员专注于自定义用例,而不必担心这些重复性活动。
同时,学习器对象具有足够的灵活性,可以通过使用灵活的参数或通过创建BertLearner的子类并重新定义相关方法来进行自定义。
from fast_bert.learner_cls import BertLearner from fast_bert.metrics import accuracy import logging logger = logging.getLogger() device_cuda = torch.device("cuda") metrics = [{'name': 'accuracy', 'function': accuracy}] learner = BertLearner.from_pretrained_model( databunch, pretrained_path='bert-base-uncased', metrics=metrics, device=device_cuda, logger=logger, output_dir=OUTPUT_DIR, finetuned_wgts_path=None, warmup_steps=500, multi_gpu=True, is_fp16=True, multi_label=False, logging_steps=50)
| 参数 | 描述 |
|---|---|
| databunch | 之前创建的Databunch对象 |
| pretrained_path | 预训练模型文件所在目录的路径,或预训练模型的名称,如bert-base-uncased、xlnet-large-cased等 |
| metrics | 希望模型在验证集上计算的指标函数列表,如accuracy、beta等 |
| device | torch.device类型,可以是_cuda_或_cpu_ |
| logger | logger对象 |
| output_dir | 模型保存训练产物、分词器词汇表和tensorboard文件的目录 |
| finetuned_wgts_path | 提供微调后的语言模型的位置(实验性功能) |
| warmup_steps | 调度器的训练预热步数 |
| multi_gpu | 是否有多个GPU可用,例如在AWS p3.8xlarge实例上运行时 |
| is_fp16 | 是否使用FP16训练 |
| multi_label | 是否为多标签分类 |
| logging_steps | 计算tensorboard指标的步数间隔。设为0可禁用tensorboard日志记录。将此值设置得过低会降低训练速度,因为每次记录指标时都会评估模型 |
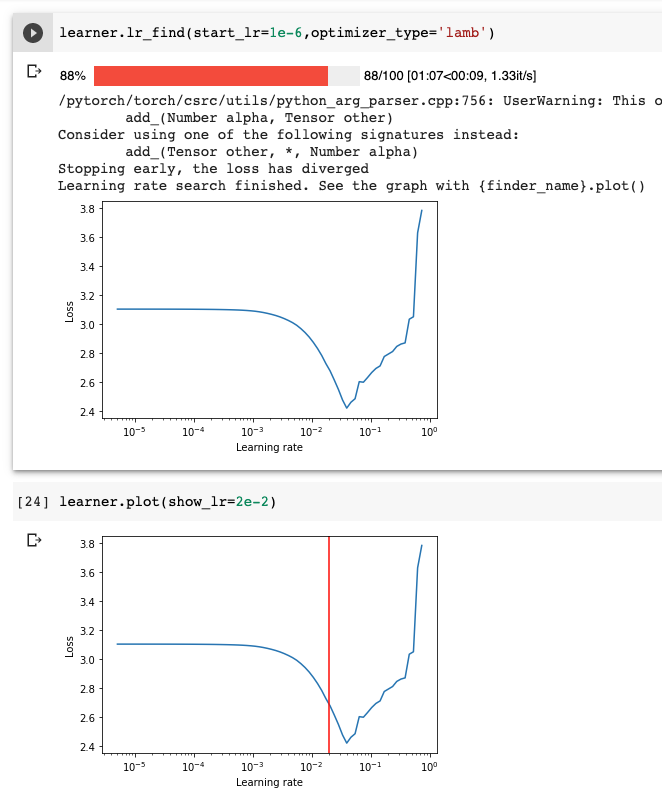
3. 找到最佳学习率
学习率是模型训练最重要的超参数之一。我们已经整合了Leslie Smith提出并后来被fastai库采用的学习率查找器。
learner.lr_find(start_lr=1e-5,optimizer_type='lamb')
这段代码大量借鉴自David Silva的pytorch-lr-finder库。
4. 训练模型
learner.fit(epochs=6, lr=6e-5, validate=True, # 每个epoch后评估模型 schedule_type="warmup_cosine", optimizer_type="lamb")
Fast-Bert现在支持LAMB优化器。由于训练速度的原因,我们将LAMB设置为默认优化器。您可以通过将optimizer_type设置为'adamw'来切换回AdamW。
5. 保存训练好的模型产物
learner.save_model()
模型产物将被保存在提供给learner对象的output_dir/'model_out'路径中。以下文件将被保存:
| 文件名 | 描述 |
|---|---|
| pytorch_model.bin | 训练好的模型权重 |
| spiece.model | 句子分词器词汇表(用于xlnet模型) |
| vocab.txt | 词块分词器词汇表(用于bert模型) |
| special_tokens_map.json | 特殊标记映射 |
| config.json | 模型配置 |
| added_tokens.json | 新增标记列表 |
由于所有模型产物都存储在同一文件夹中,您可以通过将pretrained_path指向此位置来实例化learner对象以运行推理。
6. 模型推理
如果您已经有一个带有训练好模型的Learner对象实例,只需在learner对象上调用predict_batch方法,传入文本数据列表:
texts = ['我真的很喜欢Netflix的原创电影', '这部电影不值得一看'] predictions = learner.predict_batch(texts)
如果您有持久化的训练模型,只想在该训练模型上运行推理逻辑,请使用第二种方法,即predictor对象。
from fast_bert.prediction import BertClassificationPredictor MODEL_PATH = OUTPUT_DIR/'model_out' predictor = BertClassificationPredictor( model_path=MODEL_PATH, label_path=LABEL_PATH, # labels.csv文件的位置 multi_label=False, model_type='xlnet', do_lower_case=False, device=None) # 设置自定义torch.device,如果可用则默认为cuda # 单个预测 single_prediction = predictor.predict("只需为这段文本给我结果") # 批量预测 texts = [ "这是第一段文本", "这是第二段文本" ] multiple_predictions = predictor.predict_batch(texts)
语言模型微调
�在自定义数据集上使用基于BERT的模型的一个有用方法是首先对自定义数据集微调语言模型任务,这是fast.ai的ULMFit所采用的方法。这个想法是从一个预训练模型开始,然后在自定义数据集的原始文本上进一步训练模型。我们将使用掩码语言模型任务来微调语言模型。
本节将描述如何使用FastBert来微调语言模型。
1. 导入必要的库
必要的对象存储在带有'_lm'后缀的文件中。
# 语言模型Databunch from fast_bert.data_lm import BertLMDataBunch # 语言模型learner from fast_bert.learner_lm import BertLMLearner from pathlib import Path from box import Box
2. 定义参数并设置数据路径
# Box是一个很好的包装器,用于从JSON字典创建对象 args = Box({ "seed": 42, "task_name": 'imdb_reviews_lm', "model_name": 'roberta-base', "model_type": 'roberta', "train_batch_size": 16, "learning_rate": 4e-5, "num_train_epochs": 20, "fp16": True, "fp16_opt_level": "O2", "warmup_steps": 1000, "logging_steps": 0, "max_seq_length": 512, "multi_gpu": True if torch.cuda.device_count() > 1 else False }) DATA_PATH = Path('../lm_data/') LOG_PATH = Path('../logs') MODEL_PATH = Path('../lm_model_{}/'.format(args.model_type)) DATA_PATH.mkdir(exist_ok=True) MODEL_PATH.mkdir(exist_ok=True) LOG_PATH.mkdir(exist_ok=True)
3. 创建DataBunch对象
BertLMDataBunch类包含一个静态方法'from_raw_corpus',该方法将接收原始文本列表并为语言模型学习器创建DataBunch。
该方法首先会通过删除HTML标签、多余空格等来预处理文本列表,然后创建lm_train.txt和lm_val.txt文件。这些文件将用于训练和评估语言模型微调任务。
下一步是对文本进行特征化处理。文本将被分词、数字化,并分割成512个token的块(包括特殊token)。
databunch_lm = BertLMDataBunch.from_raw_corpus( data_dir=DATA_PATH, text_list=texts, tokenizer=args.model_name, batch_size_per_gpu=args.train_batch_size, max_seq_length=args.max_seq_length, multi_gpu=args.multi_gpu, model_type=args.model_type, logger=logger)
由于这一步可能会根据自定义数据集文本的大小而耗费一些时间,特征化后的数据将被缓存在data_dir/lm_cache文件夹中的pickle文件里。
下次,您可能想直接实例化DataBunch对象,而不是使用from_raw_corpus方法,如下所示:
databunch_lm = BertLMDataBunch( data_dir=DATA_PATH, tokenizer=args.model_name, batch_size_per_gpu=args.train_batch_size, max_seq_length=args.max_seq_length, multi_gpu=args.multi_gpu, model_type=args.model_type, logger=logger)
4. 创建LM Learner对象
BertLearner是将所有内容整合在一起的"学习器"对象。它封装了模型生命周期的关键逻辑,如训练、验证和推理。
学习器对象将接收之前创建的databunch作为输入,以及其他一些参数,如预训练模型的位置、FP16训练、多GPU和多标签选项。
学习器类包含训练循环、验证循环和优化器策略的逻辑。这有助于开发人员专注于他们的自定义用例,而不必担心这些重复性活动。
同时,学习器对象足够灵活,可以通过使用灵活的参数或通过创建BertLearner的子类并重新定义相关方法来进行自定义。
learner = BertLMLearner.from_pretrained_model( dataBunch=databunch_lm, pretrained_path=args.model_name, output_dir=MODEL_PATH, metrics=[], device=device, logger=logger, multi_gpu=args.multi_gpu, logging_steps=args.logging_steps, fp16_opt_level=args.fp16_opt_level)
5. 训练模型
learner.fit(epochs=6, lr=6e-5, validate=True, # 在每个epoch后评估模型 schedule_type="warmup_cosine", optimizer_type="lamb")
Fast-Bert现在支持LAMB优化器。由于训练速度的原因,我们将LAMB设置为默认优化器。您可以通过将optimizer_type设置为'adamw'来切换回AdamW。
6. 保存训练好的模型
learner.save_model()
模型文件将被保存在提供给学习器对象的output_dir/'model_out'路径中。以下文件将被保存:
| 文件名 | 描述 |
|---|---|
| pytorch_model.bin | 训练好的模型权重 |
| spiece.model | 句子分词器词汇表(用于xlnet模型�) |
| vocab.txt | 词片分词器词汇表(用于bert模型) |
| special_tokens_map.json | 特殊token映射 |
| config.json | 模型配置 |
| added_tokens.json | 新增token列表 |
pytorch_model.bin包含了微调后的权重,您可以通过finetuned_wgts_path参数将分类任务学习器对象指向这个文件。
Amazon Sagemaker支持
这个库的目的是让您能够训练和部署生产级别的模型。由于transformer模型需要昂贵的GPU来训练,我已经添加了在AWS SageMaker上训练和部署模型的支持。
该存储库包含了在Amazon SageMaker中构建基于BERT的分类模型的Docker镜像和代码。 请参考我的博客使用FastBert和Amazon SageMaker训练和部署强大的基于BERT的NLP模型,该博客详细解释了如何将SageMaker与FastBert结合使用。
引用
如果您在已发表或开源项目中使用本工作,请提及此库和HuggingFace的pytorch-transformers库,并附上本仓库的链接。
同时还请引用我关于这个主题的博客文章:
编辑推荐精选


音述AI
全球首个AI音乐社区
音述AI是全球首个AI音乐社区,致力让每个人都能用音乐表达自我。音述AI提供零门槛AI创作工具,独创GETI法则帮助用户精准定义音乐风格,AI润色功能支持自动优化作品质感。音述AI支持交流讨论、二次创作与价值变现。针对中文用户的语言习惯与文化背景进行专门优化,支持国风融合、C-pop等本土音乐标签,让技术更好地承载人文表达。


QoderWork
阿里Qoder团队推出的桌面端AI智能体
QoderWork 是阿里推出的本地优先桌面 AI 智能体,适配 macOS14+/Windows10+,以自然语言交互实现文件管理、数据分析、AI 视觉生成、浏览器自动化等办公任务,自主拆解执行复杂工作流,数据本地运行零上传,技能市场可无限扩展,是高效的 Agentic 生产力办公助手。


lynote.ai
一站式搞定所有学习需求
不再被海量信息淹没,开始真正理解知识。Lynote 可摘要 YouTube 视频、PDF、文章等内容。即时创建笔记,检测 AI 内容并下载资料,将您的学习效率提升 10 倍。


AniShort
为AI短剧协作而生
专为AI短剧协作而生的AniShort正式发布,深度重构AI短剧全流程生产模式,整合创意策划、制作执行、实时协作、在线审片、资产复用等全链路功能,独创无限画布、双轨并行工业化工作流与Ani智能体助手,集成多款主流AI大模型,破解素材零散、版本混乱、沟通低效等行业痛点,助力3人团队效率提升800%,打造标准化、可追溯的AI短剧量产体系,是AI短剧团队协同创作、提升制作效率的核心工具。


seedancetwo2.0
能听懂你表达的视频模型
Seedance two是基于seedance2.0的中国大模型,支持图像、视频、音频、文本四种模态输入,表达方式更丰富,生成也更可控。


nano-banana纳米香蕉中文站
国内直接访问,限时3折
输入简单文字,生成想要的图片,纳米香蕉中文站基于 Google 模型的 AI 图片生成网站,支持文字生图、图生图。官网价格限时3折活动


扣子-AI办公
职场AI,就用扣子
AI办公助手,复杂任务高效处理。办公效率低?扣子空间AI助手支持播客生成、PPT制作、网页开发及报告写作,覆盖科研、商业、舆情等领域的专家Agent 7x24小时响应,生活工作无缝切换,提升50%效率!


堆友
多风格AI绘画神器
堆友平台由阿里巴巴设计团队创建,作为一款AI驱动的设计工具,专为设计师提供一站式增长服务。功能覆盖海量3D素材、AI绘画、实时渲染以及专业抠图,显著提升设计品质和效率。平台不仅提供工具,还是一个促进创意交流和个人发展的空间,界面友好,适合所有级别的设计师和创意工作者。


码上飞
零代码AI应用开发平台
零代码AI应用开发平台,用户只需一句话简单描述需求,AI能自动生成小程序、APP或H5网页应用,无需编写代码。


Vora
免费创建高清无水印Sora视频
Vora是一个免费创建高清无水印Sora视频的AI工具
推荐工具精选





AI云服务特惠
懂AI专属折扣关注微信公众号
最新AI工具、AI资讯
独家AI资源、AI项目落地

微信扫一扫关注公众号