


待办事项
小数据测试(已完成)
- 寻找适合越南语的分词方法(参见 symato)
- 音节是越南语的主要特征,也是分析语言时合理的单位。
- 将音节拆分为 sym、mark 和 tone 等单位,有助于减少需要使用的单位数量。
- 3k 词汇表足以有效编码包含大量越南语的语料库,使用 256 字节编码其余部分也能很好地工作。
- 阅读理解 rwkv(参见 rwkv.md 或 简要版本)
- 重写 rwkv 推理引擎 ~200 loc in python
- 阅读理解并简化 [训练代码](./rwkv-v4neo)
- 使用任意越南语音节数据集进行 rwkv-lm
- 设计 symato 词汇表
- 创建 mini 数据集 vlc.xyz (16MB)
- 训练 symato-2816-vlc-23m
- 运行 symato-2816-vlc-23m
./run.sh - 改进 Symato tknz 减少音节之间的 token 空间
- 上下文长度增加 2 倍,损失减少一半
大数据测试(进行中)
- 收集并处理 100G 数据: 参见 vi 项目
- 在过滤和平衡数据后,训练与数据量相适应的模型
- 构建 symato_16k(对比 sentencepiece 16k)
- symato_16k 的效率(参见 技术报告)
- 发布 racoon 精简版 RWKV-v4 以用于训练语言模型
- 在约 100G 选定数据上训练 2.5 亿参数的大型语言模型
https://user-images.githubusercontent.com/8133/216773986-3d26d73a-9206-45b1-ae8f-d5d8fdb01199.mp4
Symato 同时能做两件事,自动添加声调并生成文本
试验做聊天机器人
https://user-images.githubusercontent.com/8133/225555655-7bf1e15c-ecdd-45da-a084-7cce1eef7b29.mp4
第五代聊天机器人
https://user-images.githubusercontent.com/8133/236672299-c4cf39c0-a7a0-44d8-b9be-c1b056b1df35.mp4
https://github.com/telexyz/symato/assets/8133/d536b9ef-d7c6-4529-9640-b32d84e29373
Symato 是 Symbol + Mark + Tone 的缩写。Google 翻译成越南语是 "Đồng Cảm"
介绍
这是建立大型越南语数据集语言模型的试验场所,专注于越南语音节,旨在减小参数量并突出越南语的特点。 并回答以下问题:
- 是否能在有限的数据量和计算资源下重复缩放定律?(参见 cramming paper)
- 是否能在处理小规模语言任务时重复缩放定律?(参见 santacoder)
- 在不进行微调的情况下,有哪些不同的方法可以利用模型?
- 有哪些不同的方法可以提高模型效率?(继续预训练,为每个任务微调,RLHL 等)
- 需要多少数据量才能对现有模型进行针对性预训练,以适应新的语言?
- 对于特定领域的有限数据量,应该如何进行分词?需要多少参数 / 训练多长时间才够?
为什么选择 RWKV 而不是 Transformer?
RWKV 是一个非常有趣的模型,它兼具 GPT 的并行训练能力以及 RNN 只需 t 时刻的隐状态即可计算 t+1 时刻系统状态的特点。因此,它比 Transformer 更节省计算和内存。这样可以加快训练速�度,简化部署,甚至在智能手机上也能良好运行。RWKV 已经在 The Pile 数据集上进行了 1B 到 14B 参数的训练,其性能与其他 transformer 模型相当。对于像 Google、Microsoft 这样的公司,他们拥有强大的计算能力和庞大的数据量,这些优势也许并不显著。但对于计算资源有限(例如配备 8 个 GPU 的高性能电脑)和数据量有限的越南语来说,RWKV 可以带来显著的差异。
为什么需要为越南语单独预训练?
当前的大型语言模型主要由英语和拉丁语系语言主导,而越南语由于数据量少且具有独特性(utf-8 编码 2-4 字节),在分词处理时处于劣势(见下图)。这会导致性能和经济成本上的损失(更多的 tokens / words ,因此句子生成速度更慢,资源消耗更多)。
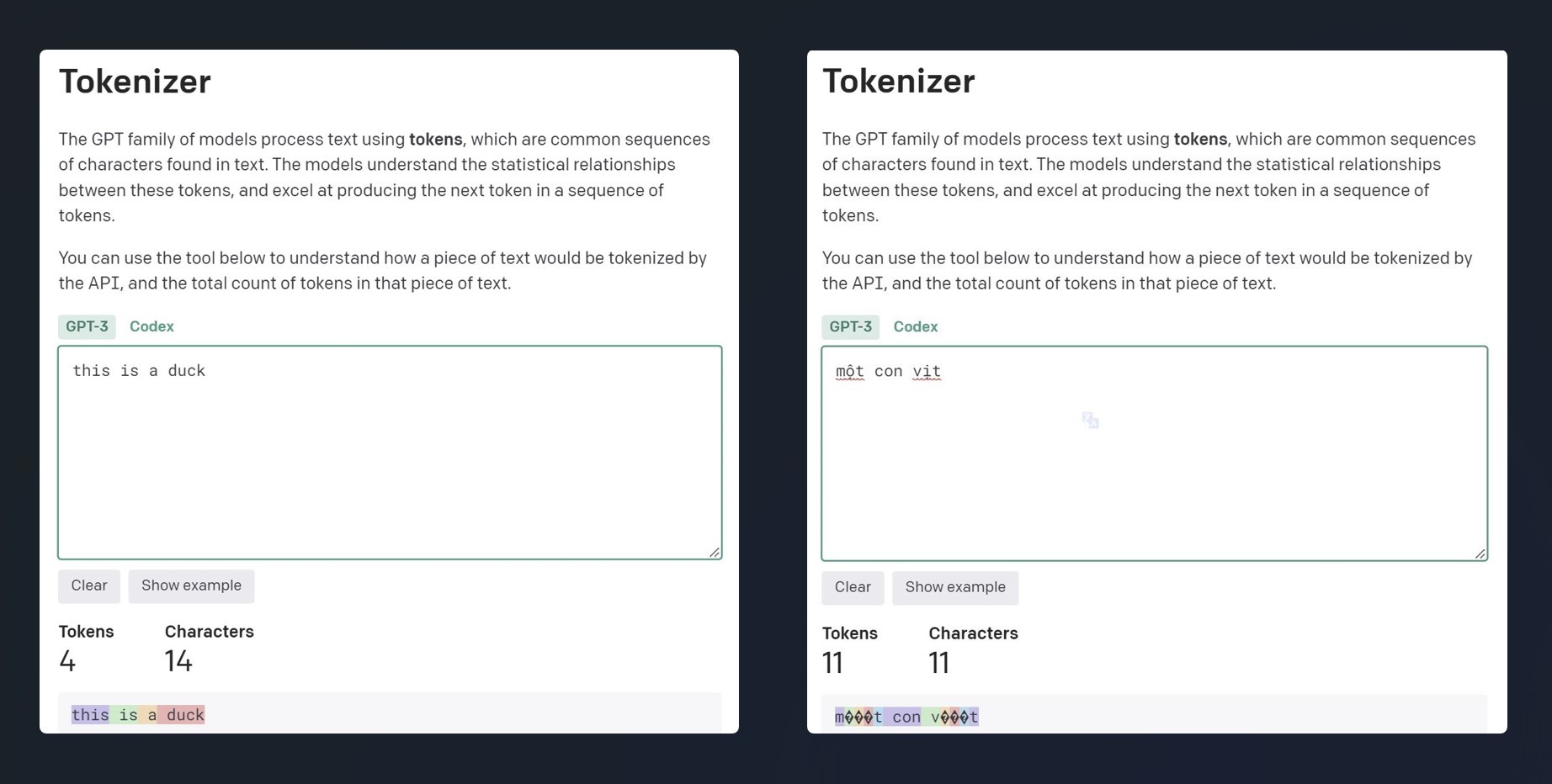
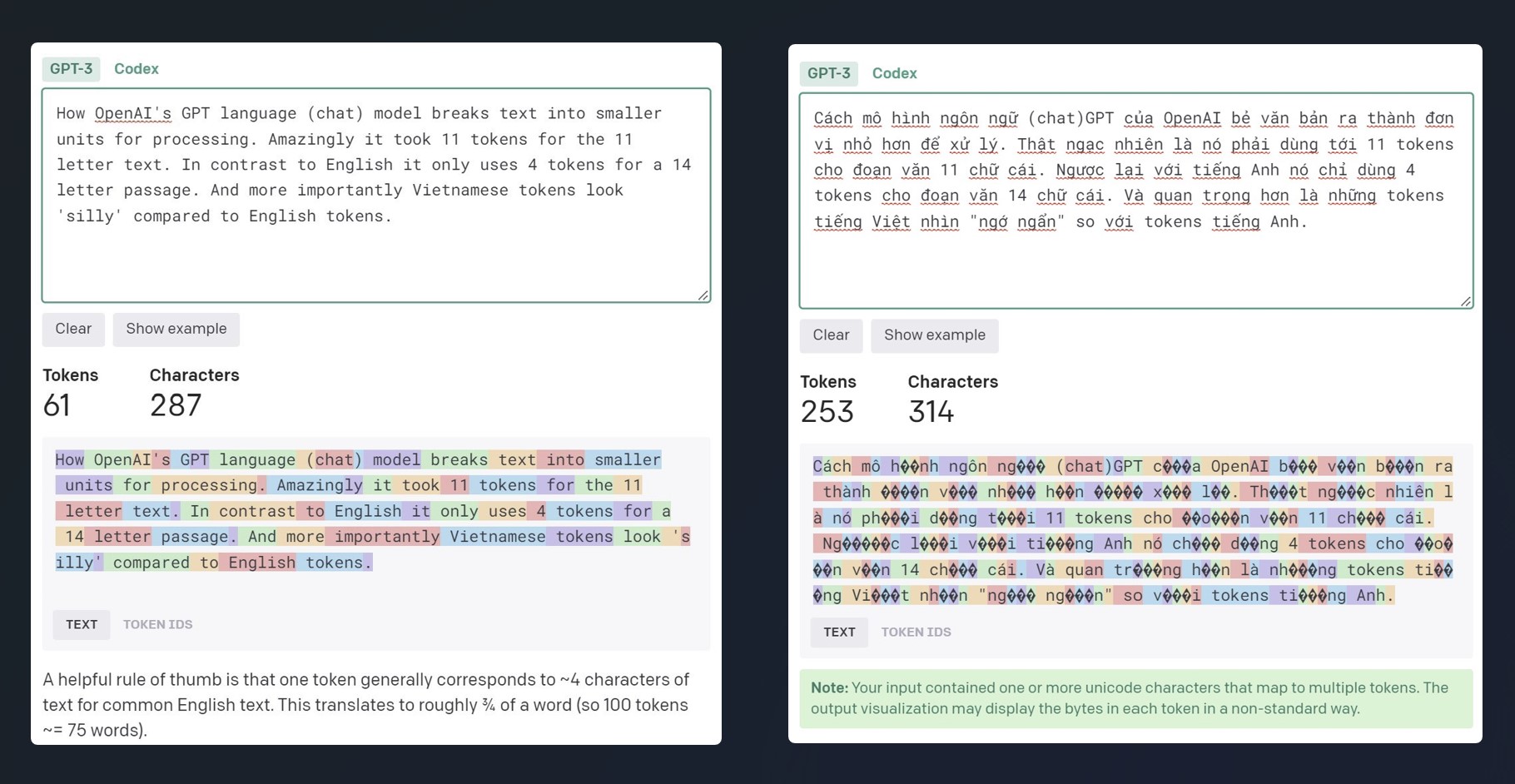
上述图示说明在同一段落中,越南语的 tokens 数量是英语的 4 倍。结果是上下文长度减少到 1/4,生成数据的速度降低 4 倍,如果按 token 计费,越南语也会比英语高出 4 倍。 原因是由于 chatgpt 的 tokenization 模块进行了英语和拉丁语言优化,因此它不理解许多越南语的 unicode 编码(用 2-4 个字节编码)。具体来说,“ngôn ngữ”中的字符“ữ”被 tokenized 成 3 个字节(在上图中显示为 3 个问号 ???)。这种 tokenization 的方式对越南语非常不利,再加上训练数据量相对于英语被削弱,但 chatgpt 对越南语的结果仍然令人印象深刻(如下视频)。
https://user-images.githubusercontent.com/8133/215305323-4d776242-d8fe-497e-96f5-9c95f344b992.mp4
视频显示,由于 chatgpt 对越南语的生成速度比对英语要慢很多,它是一个一个字符甚至一个一个字节地生成越南语。而对于英语,它主要是按词生成的。尽管如此不利,但模型依然足够强大,能够存储越南语信息并找到合理的答案。这表明了语言模型的巨大力量,chatgpt 是第一个将这种力量以舒服的方式交到用户手中的应用。换句话说,chatgpt 建立了一个合理的界面,让用户能够利用大型语言模型的力量。(注意:chatGPT 对越南语音节的回答并不完全准确)。
Symato
哪种 tokenization 方式适合越南语?
Tknz 是将文本分解成信息单元以便处理的方式。Tknz 需要在以下三者之间保持平衡:1/ 词汇数量(唯一标记),2/ 标记的信息覆盖度和 3/ 模型的灵活性:
- 词汇数量大增加参数并使模型变慢。词汇数量小,则信息覆盖度低
- 信息覆盖度低但灵活性高,反之信息覆盖度高则灵活性降低。比如,只要一个词汇表中的词可以构成,新词也可以处理。最灵活的表达方式是使用 256 个字节作为词汇表,因为任何数据都可以用一串字节表示。
- 信息覆盖度低导致模型难以学习如何表示信息,并且处理速度变慢,因为每个标记的处理速度是一样的,但低覆盖率需要(非常)多的标记才能呈现需要提取的信息。
- 信息覆盖度高导致更好的表达和模型能够控制的上下文(标记数量)更长。
- BPE(字节对编码)是一种通过定义最基本的符号集(通常是 256 个字节或 unicode 字符)和最大词汇量来在词汇量大小、信息覆盖度和模型灵活性之间自动平衡的方式,然后它会找到方法将现有符号组合起来,以在不超过最大词汇量的情况下达到最高的信息覆盖度。
- 由于标记之间有重叠,一个句子可以有多种 tokenization 方式,为了保持模型的灵活性,我们可以__用多种 tokenization 方法对其进行训练__。
 越南语音节在文本语料库中占约 80%,这是越南语言和书写的特征。使用音节作为单元是合理的。越南语大约有 16K 个有意义的音节,12K 个常用音节,当它们拆分为无标记的书写方式(sym)+ 标记(mark)和声调(tone)时,单元数量显著减少。只剩大约 2500 个 sym 和 18 个 marktone。这样,2560 个标记可以覆盖所有的 sym + marktone,还能用其他标记表示大写和小写...
越南语音节在文本语料库中占约 80%,这是越南语言和书写的特征。使用音节作为单元是合理的。越南语大约有 16K 个有意义的音节,12K 个常用音节,当它们拆分为无标记的书写方式(sym)+ 标记(mark)和声调(tone)时,单元数量显著减少。只剩大约 2500 个 sym 和 18 个 marktone。这样,2560 个标记可以覆盖所有的 sym + marktone,还能用其他标记表示大写和小写...
3k tokens 的词汇表(约 2800 个 token 用于纯越南语编码 + 256 个 token 相当于 256 个字节来表示其他所有内容)可以高效地对包含大量越南语的语料库进行 tokenizer。以上述的 chatgpt 示例为例,它通过字符和字节对越南语进行 tokenizer 以编码 80% 的越南语语料并且仍然产生令人印象深刻的结果,那么使用 256 个字节编码其余 20% 的部分肯定也能良好工作。
为什么不使用更大的词汇表?
完全可以在需要时扩展词汇表,但限制词汇表的小量将有助于节约参数数量并加快模型的速度。我相信这样的词汇表已经足够适用于当前的越南语资源(参见上面的解释和下面的统计数据).
约 1Gb 文本的统计,混合了来自 Facebook 评论、新闻标题、越南 opensub、维基百科、书籍、故事的数据:
 => 非越南语且为 1 个字符的标记数量占到 18%,这些标记用 256 个字节编码是非常合理的。剩余少量非越南语的 tokens 用 256 个字节编码也不太影响模型性能。
=> 非越南语且为 1 个字符的标记数量占到 18%,这些标记用 256 个字节编码是非常合理的。剩余少量非越南语的 tokens 用 256 个字节编码也不太影响模型性能。
能否扩展词汇表?
��完全可以通过保持 symato 的同时增加更长的 token 来扩展词汇表,例如 16k 个音节。这样一来,每个越南语句子可以有多种 tokenization 方式,我们可以对多种 tokenization 方式进行训练。当解码时,依据不同的任务我们可以优先选择不同的 tokenization 方式。例如,添加声调时使用 symato,而生成句子时优先使用长标记(音节,词...)
我不太懂你能不能解释得更清楚一点?
总结一下,symato 主要有 3 种词库及其扩展版本:
symato-3k包含 256 字节,18 种声调符号,大约 2800 个音节(不带标点的小写字母)及辅助标记。symato-16k包含symato-3k词库,加上约 13k 个常见的带声调的单音节和双音节越南语单词,这些单词在训练数据中较为常见(单词和双词)。symato-32k包含symato-16k词库,再加上双词和三词。symato+包含 symato-3k、16k、32k 及其他通过 BPE 构建以更好覆盖非音节数据的标记。
以下是为法律文本数据集构建的 symato-16k 中双词的例子。
城市规划广告系统,确保统一、同步,为各单位、企业、组织、个人的宣传和户外广告活动提供有利的法律基础。按照规定,有力地支持政治任务的宣传工作;促进生产发展、商品流通和民生服务;同时为城市增添美丽景观,促进旅游发展。
确定具体的土地位置、使用空间、规模、形式和内容,在主要道路上的广告牌、公告栏、临时广告等,并基于此向相关部门提交土地使用权评估,或长期租赁土地的规划,适应总体规划、地区规划和城市发展的规模;不破坏建筑景观和城市空间,满足交流、整合和发展的需求;采用先进的广告技术,符合省经济社会发展的实际情况,并符合当地居民��的特点、风俗和习惯。
2. 具体目标:
2.1. 建立视觉宣传系统:
2011-2015阶段:
查看现有的视觉宣传系统,公告栏、照明广告牌和其他户外广告设施,以便根据总体规划调整和设置于城市中心(如城市、县、市镇)。
在 Thanh Hoa 中心城市的 Le Loi 大道、新城区东部和西部及其出入口建设新的视觉宣传设施。
在 Le Loi 大道和城市主干道上设置照明广告牌。
在乡、村、镇的主干道上建造视觉宣传系统和公告栏。
词汇量大小如何影响模型?
以下是两个在架构上相同的模型,唯一不同的是词汇表(vocab),第一个使用 PhoBert tokenizer,词汇表大小约为 64k,第二个使用 Symato tokenizer,词汇表大小为 2816。词汇量大大增加了 emb 和 head 的参数数量。将block的主要参数缩减到三分之一,以适应 RTX3050ti 4G VRAM。尽管参数数量已翻倍!(参数量不在正确的位置上)
PhoBert tknz, vocab_size ~64k
# --------------------------------------
# | 名称 | 类型 | 参数
# --------------------------------------
# 0 | emb | 嵌入 | 20.6 M
# 1 | blocks | 模块列表 | 6.7 M
# 2 | ln_out | 层规范化 | 640
# 3 | head | 线性层 | 20.6 M
# --------------------------------------
# 47.8 M 可训练参数
# 0 不可训练参数
# 47.8 M 总参数
Symato tknz, vocab_size 2816
# --------------------------------------
# | 名称 | 类型 | 参数
# --------------------------------------
# 0 | emb | 嵌入 | 1.4 M
# 1 | blocks | 模块列表 | 20.5 M
# 2 | ln_out | 层规范化 | 1.0 K
# 3 | head | 线性层 | 1.4 M
# --------------------------------------
# 23.4 M 可训练参数
# 0 不可训练参数
# 23.4 M 总参数
注意:在相同数据集上训练 20 个epoch,PhoBert tknz 48m 参数损失 0.14, Symato tknz 23m 参数损失 0.04 (提升 3.5 倍)
没有足够的越南语数据来训练?

注意:使用越南语->英语->越南语或越南语->英语->德语->越南语来“扰乱”标准越南语句子。然后训练模型从扰乱的句子恢复标准句子。并将其作为从英语到越南语翻译的后处理模块。
编辑推荐精选


扣子-AI办公
职场AI,就用扣子
AI办公助手,复杂��任务高效处理。办公效率低?扣子空间AI助手支持播客生成、PPT制作、网页开发及报告写作,覆盖科研、商业、舆情等领域的专家Agent 7x24小时响应,生活工作无缝切换,提升50%效率!


堆友
多风格AI绘画神器
堆友平台由阿里巴巴设计团队创建,作为一款AI驱动的设计工具,专为设计师提供一站式增长服务。功能覆盖海量3D素材、AI绘画、实时渲染以及专业抠图,显著提升设计品质和效率。平台不仅提供工具,还是一个促进创意交流和个人发展的空间,界面友好,适合所有级别的设计师和创意工作者。


码上飞
零代码AI应用开发平台
零代码AI应用开发平台,用户只需一句话简单描述需求,AI能自动生成小程序、APP或H5网页应用,无需编写代码。


Vora
免费创建高清无水印Sora视频
Vora是一个免费创建高清无水印Sora视频的AI工具


Refly.AI
最适合小白的AI自动化工作流平台
无需编码,轻松生成可复用、可变现的AI自动化工作流


酷表ChatExcel
大模型驱动的Excel数据处理工具
基于大模型交互的表格处理系统,允许用户通过对话方式完成数据整理和可视化分析。系统采用机器学习算法解析用户指令,自动执行排序、公式计算和数据透视等操作,支持多种文件格式导入导出。数据处理响应速度保持在0.8秒以内,支持超过100万行数据的即时分析。


TRAE编程
AI辅助编程,代码自动修复
Trae是一种自适应的集成开发环境(IDE),通过自动化和多元协作改变开发流程。利用Trae,团队能够更快速、精确地编写和部署代码,从而提高编程效率和项目交付速度。Trae具备上下文感知和代码自动完�成功能,是提升开发效率的理想工具。


AIWritePaper论文写作
AI论文写作指导平台
AIWritePaper论文写作是一站式AI论文写作辅助工具,简化��了选题、文献检索至论文撰写的整个过程。通过简单设定,平台可快速生成高质量论文大纲和全文,配合图表、参考文献等一应俱全,同时提供开题报告和答辩PPT等增值服务,保障数据安全,有效提升写作效率和论文质量。


博思AIPPT
AI一键生成PPT,就用博思AIPPT!
博思AIPPT,新一代的AI生成PPT平台,支持智能生成PPT、AI美化PPT、文本&链接生成PPT、导入Word/PDF/Markdown文档生成PPT等,内置海量精美PPT模板,涵盖商务、教育、科技等不同风格,同时针对每个页面提供多种版式,一键自适应切换,完美适配各种办公场景。


潮际好麦
AI赋能电商视觉革命,一站式智能商拍平台
潮际好麦深耕服装行业,是国内AI试衣效果最好的软件。使用先进AIGC能力为电商卖家批量提供优质的、低成本的商拍图。合作品牌有Shein、Lazada、安踏、百丽等65个国内外头部品牌,以及国内10万+淘宝、天猫、京东等主流平台的品牌商家,为卖家节省将近85%的出图成本,提升约3倍出图效率,让品牌能够快速上架。
推荐工具精选




AI云服务特惠
懂AI专属折扣关注微信公众号
最新AI工具、AI资讯
独家AI资源、AI项目落地

微信扫一扫关注公众号